Recognition: unknown
Unfolding 3D Gaussian Splatting via Iterative Gaussian Synopsis
Pith reviewed 2026-05-10 16:37 UTC · model grok-4.3
The pith
A top-down unfolding scheme derives compact multi-level 3D Gaussian Splatting models from full-resolution inputs through iterative pruning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that beginning with a full-resolution 3D Gaussian Splatting model and iteratively deriving coarser levels via adaptive learnable mask-based pruning, while integrating hierarchical spatial grids and a shared Anchor Codebook, produces a compact multi-level representation that preserves visual fidelity and reduces storage demands for streaming and resource-limited use.
What carries the argument
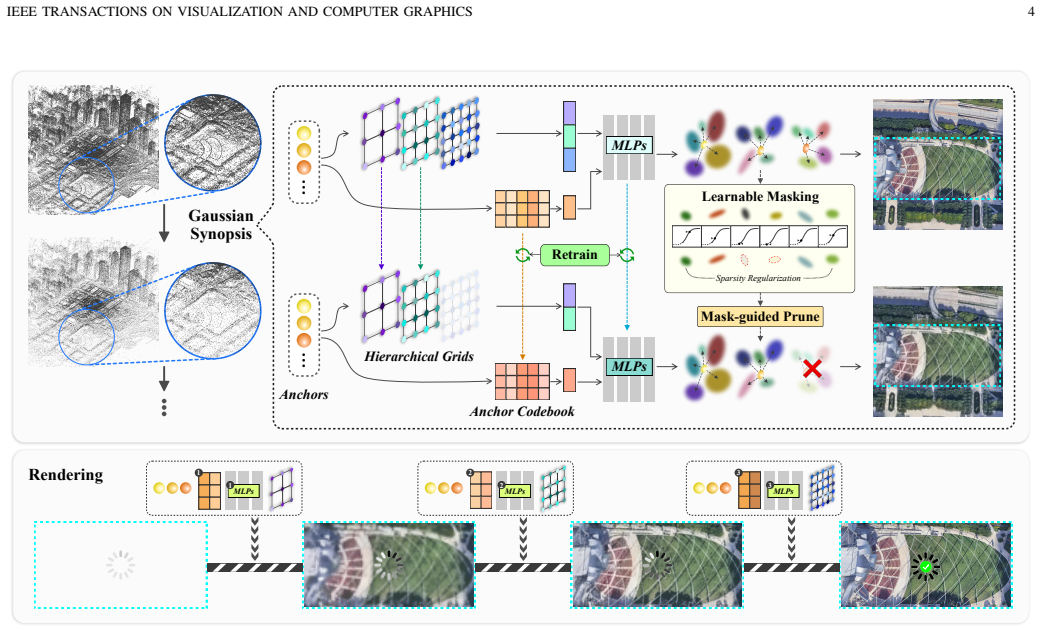
Iterative Gaussian Synopsis, a top-down unfolding process that applies adaptive learnable mask-based pruning to a full 3DGS model, supported by hierarchical spatial grids for global structure and a shared Anchor Codebook for localized details.
Where Pith is reading between the lines
- The shared codebook and grid structure may allow seamless switching between levels during interactive viewing without reloading data.
- This hierarchy could extend to dynamic scenes if the pruning masks adapt over time rather than being computed once.
- Integration with existing streaming protocols might become straightforward due to the progressive, minimal-overhead design.
Load-bearing premise
The adaptive learnable mask-based pruning removes redundancy consistently across arbitrary scenes without introducing visible artifacts or requiring scene-specific retraining at each level.
What would settle it
Rendering a complex scene at the coarsest LOD level and measuring whether PSNR or visual inspection shows noticeable degradation compared to the full model, such as loss of fine details or introduction of holes.
Figures





read the original abstract
3D Gaussian Splatting (3DGS) has become a state-of-the-art framework for real-time, high-fidelity novel view synthesis. However, its substantial storage requirements and inherently unstructured representation pose challenges for deployment in streaming and resource-constrained environments. Existing Level-of-Detail (LOD) strategies, particularly those based on bottom-up construction, often introduce redundancy or lead to fidelity degradation. To overcome these limitations, we propose Iterative Gaussian Synopsis, a novel framework for compact and progressive rendering through a top-down "unfolding" scheme. Our approach begins with a full-resolution 3DGS model and iteratively derives coarser LODs using an adaptive, learnable mask-based pruning mechanism. This process constructs a multi-level hierarchy that preserves visual quality while improving efficiency. We integrate hierarchical spatial grids, which capture the global scene structure, with a shared Anchor Codebook that models localized details. This combination produces a compact yet expressive feature representation, designed to minimize redundancy and support efficient, level-specific adaptation. The unfolding mechanism promotes inter-layer reusability and requires only minimal data overhead for progressive refinement. Experiments show that our method maintains high rendering quality across all LODs while achieving substantial storage reduction. These results demonstrate the practicality and scalability of our approach for real-time 3DGS rendering in bandwidth- and memory-constrained scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Iterative Gaussian Synopsis, a top-down unfolding framework for 3D Gaussian Splatting that starts from a full-resolution model and iteratively constructs coarser LODs via an adaptive learnable mask-based pruning mechanism combined with hierarchical spatial grids and a shared Anchor Codebook, aiming to produce a compact multi-level hierarchy that preserves visual quality while reducing storage for progressive rendering in constrained environments.
Significance. If the experimental claims hold with quantitative validation, this could offer a meaningful advance over bottom-up LOD methods for 3DGS by enabling inter-layer reusability and minimal overhead for streaming applications, addressing key deployment barriers in real-time novel view synthesis.
major comments (3)
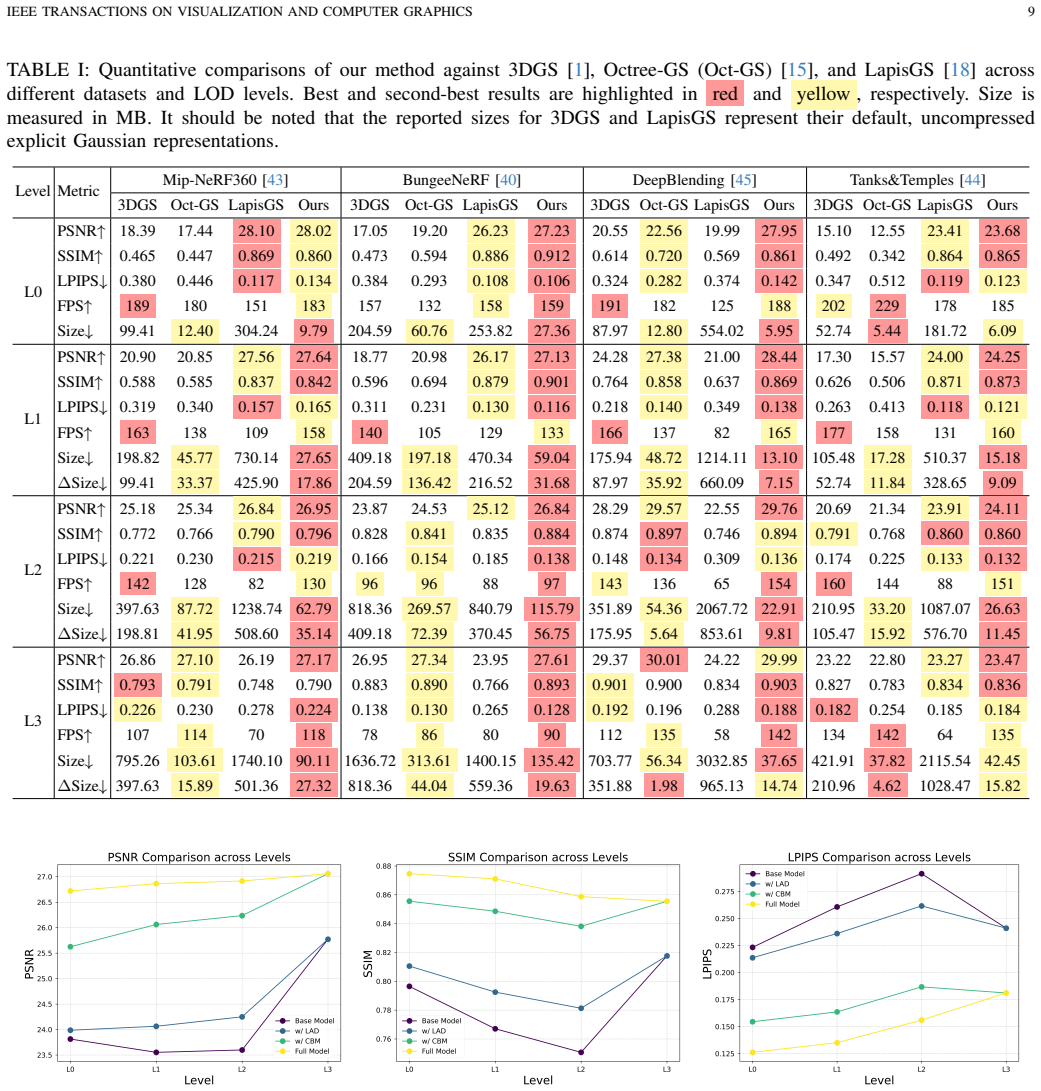
- [Abstract] Abstract: The claim that experiments 'maintain high rendering quality across all LODs while achieving substantial storage reduction' provides no numerical metrics (PSNR, SSIM, storage sizes), baselines, ablations, or error analysis, which is load-bearing for the central practicality assertion since the soundness of the pruning and codebook approach rests on uninspectable outcomes.
- [§3] §3 (Method description): No formal equation or derivation is given for the learnable mask optimization, the pruning operator, or how it interacts with the shared Anchor Codebook to ensure the rendering integral is preserved or that error does not accumulate across unfolding steps; this directly affects the claim that the hierarchy works without artifacts or per-level retraining for arbitrary scenes.
- [Abstract and §3] The assumption that hierarchical grids plus shared codebook suffice to reconstruct details at coarser levels without noticeable artifacts when Gaussian count drops substantially is presented without any invariance, bound, or consistency analysis, leaving the weakest assumption unaddressed and the cross-LOD quality claim unsupported.
minor comments (1)
- [Abstract] The abstract uses 'unfolding' and 'synopsis' without a brief contrast to prior bottom-up LOD constructions, which could improve clarity for readers familiar with 3DGS literature.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas for improving the clarity, rigor, and presentation of our results and method. We address each major comment point by point below, indicating planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that experiments 'maintain high rendering quality across all LODs while achieving substantial storage reduction' provides no numerical metrics (PSNR, SSIM, storage sizes), baselines, ablations, or error analysis, which is load-bearing for the central practicality assertion since the soundness of the pruning and codebook approach rests on uninspectable outcomes.
Authors: We agree that the abstract would be strengthened by including specific quantitative metrics. In the revised manuscript, we will update the abstract to report key numerical results from our experiments, including average PSNR and SSIM values across LOD levels, storage reduction percentages relative to the full 3DGS model and other baselines, and references to the ablations and error analyses detailed in the main body of the paper. revision: yes
-
Referee: [§3] §3 (Method description): No formal equation or derivation is given for the learnable mask optimization, the pruning operator, or how it interacts with the shared Anchor Codebook to ensure the rendering integral is preserved or that error does not accumulate across unfolding steps; this directly affects the claim that the hierarchy works without artifacts or per-level retraining for arbitrary scenes.
Authors: We acknowledge that the method section would benefit from greater mathematical formality. In the revision, we will introduce explicit equations for the learnable mask optimization objective, the adaptive pruning operator, and the interaction mechanism with the shared Anchor Codebook. We will also provide a brief derivation explaining how the rendering quality is preserved and error accumulation is limited across unfolding iterations, supported by the empirical results. revision: yes
-
Referee: [Abstract and §3] The assumption that hierarchical grids plus shared codebook suffice to reconstruct details at coarser levels without noticeable artifacts when Gaussian count drops substantially is presented without any invariance, bound, or consistency analysis, leaving the weakest assumption unaddressed and the cross-LOD quality claim unsupported.
Authors: This observation is fair regarding the need for additional support. Our framework is primarily validated through extensive empirical experiments on diverse scenes demonstrating preserved quality. In the revised paper, we will expand the discussion to include an empirical consistency analysis across LODs, such as measured feature preservation metrics and observed error bounds from the iterative process. While a complete theoretical invariance proof lies outside the practical focus of this work, these additions will better substantiate the cross-LOD claims. revision: partial
Circularity Check
No circularity: novel construction with no self-referential derivations or fitted predictions
full rationale
The paper presents Iterative Gaussian Synopsis as an original top-down framework that starts from a full-resolution 3DGS model and applies learnable mask-based pruning plus hierarchical grids and a shared anchor codebook to build coarser LODs. No equations, uniqueness theorems, or parameter-fitting steps are shown that would reduce a claimed result to its own inputs by construction. Claims rest on the empirical performance of the new architecture rather than self-citation chains or renaming of known patterns. The derivation chain is therefore self-contained and independent of the circularity patterns enumerated in the guidelines.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Anchor Codebook
no independent evidence
-
Hierarchical spatial grids
no independent evidence
Reference graph
Works this paper leans on
-
[1]
3d gaussian splatting for real-time radiance field rendering,
B. Kerbl, G. Kopanas, T. Leimk ¨uhler, and G. Drettakis, “3d gaussian splatting for real-time radiance field rendering,”ACM Transactions on Graphics, vol. 42, no. 4, July 2023. 1, 2, 3, 6, 7, 9
2023
-
[2]
Nerf: Representing scenes as neural radiance fields for view synthesis,
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng, “Nerf: Representing scenes as neural radiance fields for view synthesis,” inECCV, 2020, pp. 405–421. 1, 2
2020
-
[3]
Lightgaussian: Unbounded 3d gaussian compression with 15x reduction and 200+ fps,
Z. Fan, K. Wang, K. Wen, Z. Zhu, D. Xu, and Z. Wang, “Lightgaussian: Unbounded 3d gaussian compression with 15x reduction and 200+ fps,” inNeurIPS, 2024. 1, 3
2024
-
[4]
Hac: Hash-grid assisted context for 3d gaussian splatting compression,
Y . Chen, Q. Wu, W. Lin, M. Harandi, and J. Cai, “Hac: Hash-grid assisted context for 3d gaussian splatting compression,” inEuropean Conference on Computer Vision, 2024. 1, 3
2024
-
[5]
Contextgs: Com- pact 3d gaussian splatting with anchor level context model,
Y . Wang, Z. Li, L. Guo, W. Yang, A. Kot, and B. Wen, “Contextgs: Com- pact 3d gaussian splatting with anchor level context model,”Advances in neural information processing systems, vol. 37, pp. 51 532–51 551,
-
[6]
Trimming the fat: Efficient compression of 3d gaussian splats through pruning,
M. S. Ali, M. Qamar, S.-H. Bae, and E. Tartaglione, “Trimming the fat: Efficient compression of 3d gaussian splats through pruning,”arXiv preprint arXiv:2406.18214, 2024. 1, 3
-
[7]
Compact 3d gaussian representation for radiance field,
J. C. Lee, D. Rho, X. Sun, J. H. Ko, and E. Park, “Compact 3d gaussian representation for radiance field,” inCVPR, 2024, pp. 21 719–21 728. 1, 3, 6
2024
-
[8]
Compressed 3d gaussian splatting for accelerated novel view synthesis,
S. Niedermayr, J. Stumpfegger, and R. Westermann, “Compressed 3d gaussian splatting for accelerated novel view synthesis,” inCVPR, 2024, pp. 10 349–10 358. 1, 3
2024
-
[9]
Compgs: Smaller and faster gaussian splatting with vector quantiza- tion,
K. Navaneet, K. P. Meibodi, S. A. Koohpayegani, and H. Pirsiavash, “Compgs: Smaller and faster gaussian splatting with vector quantiza- tion,” inECCV, 2024. 1, 3
2024
-
[10]
Scaffold-gs: Structured 3d gaussians for view-adaptive rendering,
T. Lu, M. Yu, L. Xu, Y . Xiangli, L. Wang, D. Lin, and B. Dai, “Scaffold-gs: Structured 3d gaussians for view-adaptive rendering,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 20 654–20 664. 1, 3, 4, 5, 7
2024
-
[11]
HEMGS: A hybrid entropy model for 3d gaussian splatting data compression,
L. Liu, Z. Chen, and D. Xu, “Hemgs: A hybrid entropy model for 3d gaussian splatting data compression,”arXiv preprint arXiv:2411.18473,
-
[12]
Cat-3dgs: A context-adaptive triplane ap- proach to rate-distortion-optimized 3dgs compression,
Y .-T. Zhan, C.-Y . Ho, H. Yang, Y .-H. Chen, J. C. Chiang, Y .-L. Liu, and W.-H. Peng, “Cat-3dgs: A context-adaptive triplane ap- proach to rate-distortion-optimized 3dgs compression,”arXiv preprint arXiv:2503.00357, 2025. 1, 3
-
[13]
Multi-scale 3d gaussian splatting for anti-aliased rendering,
Z. Yan, W. F. Low, Y . Chen, and G. H. Lee, “Multi-scale 3d gaussian splatting for anti-aliased rendering,” inCVPR, 2024, pp. 20 923–20 931. 1, 3
2024
-
[14]
A hierarchical 3d gaussian representation for real-time rendering of very large datasets,
B. Kerbl, A. Meuleman, G. Kopanas, M. Wimmer, A. Lanvin, and G. Drettakis, “A hierarchical 3d gaussian representation for real-time rendering of very large datasets,”ACM TOG, vol. 43, no. 4, pp. 1–15,
-
[15]
K. Ren, L. Jiang, T. Lu, M. Yu, L. Xu, Z. Ni, and B. Dai, “Octree-gs: To- wards consistent real-time rendering with lod-structured 3d gaussians,” arXiv preprint arXiv:2403.17898, 2024. 1, 3, 6, 7, 9
-
[16]
Citygaussian: Real-time high-quality large-scale scene rendering with gaussians,
Y . Liu, C. Luo, L. Fan, N. Wang, J. Peng, and Z. Zhang, “Citygaussian: Real-time high-quality large-scale scene rendering with gaussians,” in European Conference on Computer Vision, 2025, pp. 265–282. 1
2025
-
[17]
ProgS: Progressive rendering of Gaussian splats.arXiv preprint arXiv:2409.01761, 2024
B. Zoomers, M. Wijnants, I. Molenaers, J. Vanherck, J. Put, L. Jorissen, and N. Michiels, “Progs: Progressive rendering of gaussian splats,”arXiv preprint arXiv:2409.01761, 2024. 1, 3, 7
-
[18]
Lapisgs: Layered progressive 3d gaussian splatting for adaptive streaming,
Y . Shi, S. Gasparini, G. Morin, and W. T. Ooi, “Lapisgs: Layered progressive 3d gaussian splatting for adaptive streaming,” in3DV, 2025. 1, 3, 6, 7, 9
2025
-
[19]
Plenoxels: Radiance fields without neural networks,
S. Fridovich-Keil, A. Yu, M. Tancik, Q. Chen, B. Recht, and A. Kanazawa, “Plenoxels: Radiance fields without neural networks,” in CVPR, 2022, pp. 5501–5510. 2
2022
-
[20]
PlenOctrees for real-time rendering of neural radiance fields,
A. Yu, R. Li, M. Tancik, H. Li, R. Ng, and A. Kanazawa, “PlenOctrees for real-time rendering of neural radiance fields,” inICCV, 2021. 2
2021
-
[21]
Instant neural graphics primitives with a multiresolution hash encoding,
T. M ¨uller, A. Evans, C. Schied, and A. Keller, “Instant neural graphics primitives with a multiresolution hash encoding,”ACM TOG, vol. 41, no. 4, pp. 1–15, 2022. 2, 5
2022
-
[22]
Baking neural radiance fields for real-time view synthesis,
P. Hedman, P. P. Srinivasan, B. Mildenhall, J. T. Barron, and P. Debevec, “Baking neural radiance fields for real-time view synthesis,”ICCV,
-
[23]
Tensorf: Tensorial radiance fields,
A. Chen, Z. Xu, A. Geiger, J. Yu, and H. Su, “Tensorf: Tensorial radiance fields,” inECCV, 2022, pp. 333–350. 2
2022
-
[24]
Kilonerf: Speeding up neural radiance fields with thousands of tiny mlps,
C. Reiser, S. Peng, Y . Liao, and A. Geiger, “Kilonerf: Speeding up neural radiance fields with thousands of tiny mlps,” inInternational Conference on Computer Vision (ICCV), 2021. 2
2021
-
[25]
V oxgraf: Fast 3d-aware image synthesis with sparse voxel grids,
K. Schwarz, A. Sauer, M. Niemeyer, Y . Liao, and A. Geiger, “V oxgraf: Fast 3d-aware image synthesis with sparse voxel grids,”Advances in Neural Information Processing Systems, vol. 35, pp. 33 999–34 011,
-
[26]
Shape as points: A differentiable poisson solver,
S. Peng, C. Jiang, Y . Liao, M. Niemeyer, M. Pollefeys, and A. Geiger, “Shape as points: A differentiable poisson solver,”Advances in Neural Information Processing Systems, vol. 34, pp. 13 032–13 044, 2021. 2
2021
-
[27]
Point-nerf: Point-based neural radiance fields,
Q. Xu, Z. Xu, J. Philip, S. Bi, Z. Shu, K. Sunkavalli, and U. Neumann, “Point-nerf: Point-based neural radiance fields,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 5438–5448. 2
2022
-
[28]
Sizegs: Size-aware compression of 3d gaussians with hierarchical mixed precision quantization,
S. Xie, J. Liu, W. Zhang, S. Ge, S. Pan, C. Tang, Y . Bai, and Z. Wang, “Sizegs: Size-aware compression of 3d gaussians with hierarchical mixed precision quantization,”arXiv preprint arXiv:2412.05808, 2024. 3
-
[29]
Mini-splatting: Representing scenes with a constrained number of gaussians,
G. Fang and B. Wang, “Mini-splatting: Representing scenes with a constrained number of gaussians,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 165–181. 3
2024
-
[30]
Reducing the memory footprint of 3d gaussian splatting,
P. Papantonakis, G. Kopanas, B. Kerbl, A. Lanvin, and G. Drettakis, “Reducing the memory footprint of 3d gaussian splatting,”Proceedings of the ACM on Computer Graphics and Interactive Techniques, vol. 7, no. 1, pp. 1–17, 2024. 3
2024
-
[31]
Lp-3dgs: Learning to prune 3d gaussian splatting,
Z. Zhang, T. Song, Y . Lee, L. Yang, C. Peng, R. Chellappa, and D. Fan, “Lp-3dgs: Learning to prune 3d gaussian splatting,” inAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, Eds., vol. 37. Curran Associates, Inc., 2024, pp. 122 434–122 457. 3 IEEE TRANSACTIONS ON VISUALI...
2024
-
[32]
Eagles: Efficient accelerated 3d gaussians with lightweight encodings,
S. Girish, K. Gupta, and A. Shrivastava, “Eagles: Efficient accelerated 3d gaussians with lightweight encodings,” inECCV, 2024. 3
2024
-
[33]
arXiv preprint arXiv:2501.05757 (2025)
S. Shin, J. Park, and S. Cho, “Locality-aware gaussian compression for fast and high-quality rendering,”arXiv preprint arXiv:2501.05757, 2025. 3
-
[34]
Gaussian- forest: Hierarchical-hybrid 3d gaussian splatting for compressed scene modeling,
F. Zhang, T. Zhang, L. Zhang, H. Huang, and Y . Luo, “Gaussian- forest: Hierarchical-hybrid 3d gaussian splatting for compressed scene modeling,”arXiv preprint arXiv:2406.08759, 2024. 3
-
[35]
End- to-end rate-distortion optimized 3d gaussian representation,
H. Wang, H. Zhu, T. He, R. Feng, J. Deng, J. Bian, and Z. Chen, “End- to-end rate-distortion optimized 3d gaussian representation,” inECCV,
-
[36]
Hac++: Towards 100x compression of 3d gaussian splatting,
Y . Chen, Q. Wu, W. Lin, M. Harandi, and J. Cai, “Hac++: Towards 100x compression of 3d gaussian splatting,”IEEE TPAMI, 2025. 3
2025
-
[37]
View-dependent refinement of progressive meshes,
H. Hoppe, “View-dependent refinement of progressive meshes,” in Proceedings of the 24th annual conference on Computer graphics and interactive techniques, 1997, pp. 189–198. 3
1997
-
[38]
Y .-C. Chen, V . Kim, N. Aigerman, and A. Jacobson, “Neural progressive meshes,” inACM SIGGRAPH 2023 Conference Proceedings, ser. SIGGRAPH ’23. New York, NY , USA: Association for Computing Machinery, 2023. [Online]. Available: https://doi.org/10.1145/3588432. 3591531 3
-
[39]
T. Takikawa, J. Litalien, K. Yin, K. Kreis, C. Loop, D. Nowrouzezahrai, A. Jacobson, M. McGuire, and S. Fidler, “ Neural Geometric Level of Detail: Real-time Rendering with Implicit 3D Shapes ,” in2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Los Alamitos, CA, USA: IEEE Computer Society, Jun. 2021, pp. 11 353–11 362. [Online]...
-
[40]
Bungeenerf: Progressive neural radiance field for extreme multi- scale scene rendering,
Y . Xiangli, L. Xu, X. Pan, N. Zhao, A. Rao, C. Theobalt, B. Dai, and D. Lin, “Bungeenerf: Progressive neural radiance field for extreme multi- scale scene rendering,” inECCV, 2022, pp. 106–122. 3, 6, 7, 9
2022
-
[41]
Structure-from-motion revisited,
J. L. Schonberger and J.-M. Frahm, “Structure-from-motion revisited,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 4104–4113. 5
2016
-
[42]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Y . Bengio, N. L ´eonard, and A. Courville, “Estimating or propagating gradients through stochastic neurons for conditional computation,”arXiv preprint arXiv:1308.3432, 2013. 5, 6
work page internal anchor Pith review arXiv 2013
-
[43]
Mip-nerf: A multiscale representation for anti- aliasing neural radiance fields,
J. T. Barron, B. Mildenhall, M. Tancik, P. Hedman, R. Martin-Brualla, and P. P. Srinivasan, “Mip-nerf: A multiscale representation for anti- aliasing neural radiance fields,” inICCV, 2021, pp. 5855–5864. 6, 7, 9
2021
-
[44]
Tanks and temples: Benchmarking large-scale scene reconstruction,
A. Knapitsch, J. Park, Q.-Y . Zhou, and V . Koltun, “Tanks and temples: Benchmarking large-scale scene reconstruction,”ACM TOG, vol. 36, no. 4, pp. 1–13, 2017. 6, 7, 9
2017
-
[45]
Deep blending for free-viewpoint image-based rendering,
P. Hedman, J. Philip, T. Price, J.-M. Frahm, G. Drettakis, and G. Bros- tow, “Deep blending for free-viewpoint image-based rendering,”ACM TOG, vol. 37, no. 6, pp. 1–15, 2018. 6, 7, 9
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.