Recognition: unknown
Exploring Radiologists' Expectations of Explainable Machine Learning Models in Medical Image Analysis
Pith reviewed 2026-05-10 14:57 UTC · model grok-4.3
The pith
Radiologists' questionnaire responses yield guidelines for designing explainable ML models in medical imaging.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Radiologists expect models to show which image regions drive a prediction, to quantify uncertainty, and to fit within existing clinical workflows; a questionnaire capturing these expectations across specialties directly informs a set of design and development guidelines intended to raise model acceptance and enable integration as a supportive tool.
What carries the argument
A structured questionnaire delivered to practicing radiologists, whose aggregated answers are translated into guidelines for model explainability and clinical deployment.
If this is right
- Models should include visual maps that highlight the image features used for each prediction.
- Deployment should prioritize tasks such as tumor or lesion detection where radiologists already see clear value.
- Development teams should incorporate uncertainty estimates so clinicians can assess prediction reliability.
- Guidelines provide a shared reference that aligns technical choices with documented clinical needs.
Where Pith is reading between the lines
- Hospitals could pilot these guidelines in a single department and track changes in model usage over six months.
- The same questionnaire approach might be repeated in pathology or cardiology to test whether the resulting guidelines remain similar.
- As new visualization techniques appear, the guidelines would likely require periodic revision to stay current.
Load-bearing premise
The answers given by the sampled radiologists accurately reflect the expectations of the wider radiology community and that following the resulting guidelines will increase acceptance without further testing.
What would settle it
A controlled deployment study comparing acceptance rates of models built according to the guidelines versus otherwise identical models that ignore them.
Figures














read the original abstract
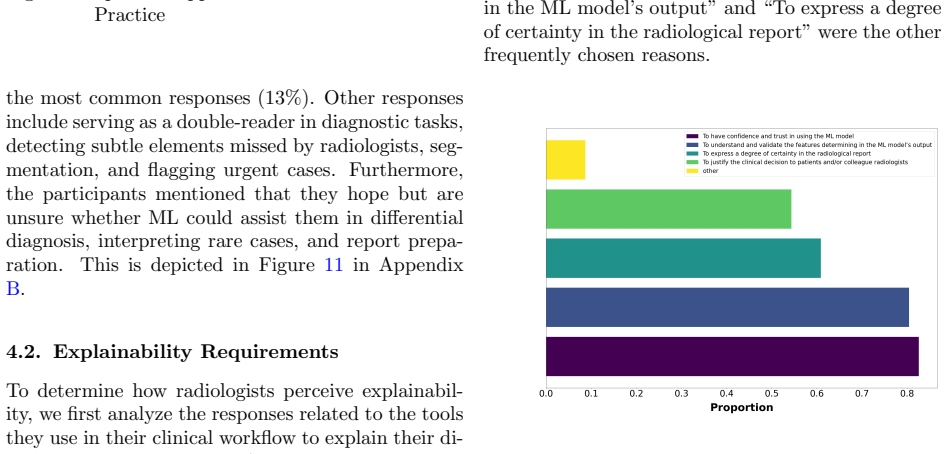
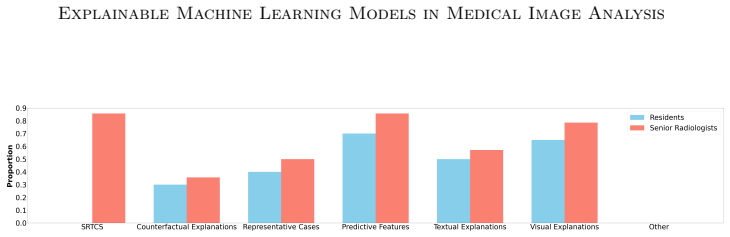
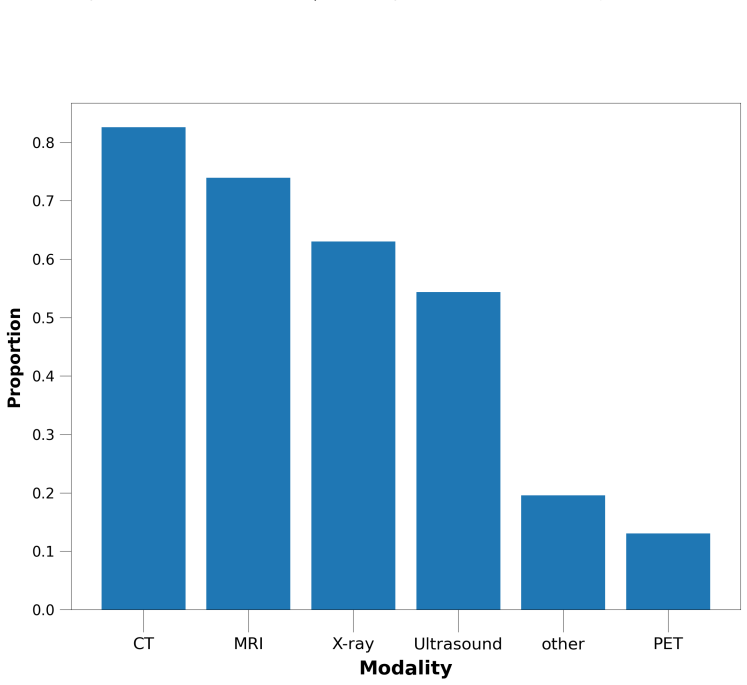
In spite of the strong performance of machine learning (ML) models in radiology, they have not been widely accepted by radiologists, limiting clinical integration. A key reason is the lack of explainability, which ensures that model predictions are understandable and verifiable by clinicians. Several methods and tools have been proposed to improve explainability, but most reflect developers' perspectives and lack systematic clinical validation. In this work, we gathered insights from radiologists with varying experience and specialties into explainable ML requirements through a structured questionnaire. They also highlighted key clinical tasks where ML could be most beneficial and how it might be deployed. Based on their input, we propose guidelines for designing and developing explainable ML models in radiology. These guidelines can help researchers develop clinically useful models, facilitating integration into radiology practice as a supportive tool.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes a questionnaire study in which radiologists with varying experience and specialties were asked about their expectations for explainable ML models in medical image analysis. The authors identify key clinical tasks where ML support would be most useful, map the responses to a set of design guidelines, and argue that these guidelines will help researchers create clinically useful models that integrate more readily into radiology practice.
Significance. If the guidelines are shown to be representative and effective, the work would supply a valuable clinician-centered perspective that is currently underrepresented in XAI-for-radiology literature. Collecting direct input from end-users rather than relying solely on developer-defined explainability metrics is a constructive step toward more usable systems. However, the absence of sample-size details, response-rate information, and any validation that guideline-compliant models actually improve acceptance limits the immediate strength of the contribution.
major comments (2)
- [Methods] Methods section: the manuscript supplies no information on the number of radiologists invited or who responded, their specialty distribution, years of experience, or the response rate. These details are required to evaluate whether the sampled views support the claim that the derived guidelines reflect broader clinical needs.
- [Results / Guidelines] Results / Guidelines section: the central claim that the proposed guidelines 'can help researchers develop clinically useful models, facilitating integration' is not accompanied by any follow-up validation, controlled comparison, or acceptance metric contrasting guideline-adherent versus non-adherent models. Without such evidence the extrapolation from questionnaire responses to improved clinical uptake remains unsecured.
minor comments (2)
- [Abstract] Abstract: the abstract states that responses were mapped to guidelines but does not indicate how many participants contributed or what analysis method was used; adding a brief quantitative summary would improve readability.
- [Discussion] The paper would benefit from an explicit limitations subsection that addresses potential selection bias in the radiologist sample and the lack of prospective testing of the guidelines.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and have revised the paper accordingly where possible.
read point-by-point responses
-
Referee: [Methods] Methods section: the manuscript supplies no information on the number of radiologists invited or who responded, their specialty distribution, years of experience, or the response rate. These details are required to evaluate whether the sampled views support the claim that the derived guidelines reflect broader clinical needs.
Authors: We agree that these details are necessary to assess the representativeness of the sample. The original submission omitted them for brevity, but the study did collect this information. In the revised manuscript we have added a dedicated subsection in Methods describing the recruitment process, total invitations sent, response rate, and the distribution of respondent specialties and years of experience. These additions allow readers to better judge the scope of the derived guidelines. revision: yes
-
Referee: [Results / Guidelines] Results / Guidelines section: the central claim that the proposed guidelines 'can help researchers develop clinically useful models, facilitating integration' is not accompanied by any follow-up validation, controlled comparison, or acceptance metric contrasting guideline-adherent versus non-adherent models. Without such evidence the extrapolation from questionnaire responses to improved clinical uptake remains unsecured.
Authors: We acknowledge that the current work is an exploratory questionnaire study and does not contain empirical validation of the guidelines' effect on clinical acceptance. We have revised the abstract, introduction, and conclusion to present the guidelines as preliminary, clinician-derived recommendations rather than as proven to improve uptake. The manuscript now explicitly notes that future studies will be needed to test guideline-adherent models against non-adherent ones. This framing keeps the contribution focused on the user-elicited perspective while avoiding overstatement. revision: partial
Circularity Check
No circularity: guidelines derived directly from external radiologist survey responses
full rationale
The paper's derivation consists of administering a structured questionnaire to radiologists, summarizing their stated expectations and clinical priorities, and then proposing guidelines based on those responses. No equations, fitted parameters, model predictions, or mathematical reductions appear in the provided text. There are no self-citations invoked as load-bearing uniqueness theorems, no ansatzes smuggled through prior work, and no renaming of known empirical patterns. The central output (guidelines) is presented as an aggregation of external clinician input rather than a self-referential loop or a statistical prediction forced by the paper's own assumptions. This structure is self-contained against external benchmarks and receives the default non-circular finding.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Lack of explainability is a primary barrier preventing wide acceptance of ML models by radiologists.
- domain assumption Structured questionnaires can systematically capture clinically relevant requirements for explainable ML.
Reference graph
Works this paper leans on
-
[1]
Mitigating bias: Enhancing image classification by improving model explanations
Raha Ahmadi, Mohammad Javad Rajabi, Mohammad Khalooie, and Mohammad Sabokrou. Mitigating bias: Enhancing image classification by improving model explanations. arXiv preprint arXiv:2307.01473, 2023
-
[2]
Explainable artificial intelligence (xai): Concepts, taxonomies, opportunities and challenges toward responsible ai
Alejandro Barredo Arrieta, Natalia D \' az-Rodr \' guez, Javier Del Ser, Adrien Bennetot, Siham Tabik, Alberto Barbado, Salvador Garc \' a, Sergio Gil-L \'o pez, Daniel Molina, Richard Benjamins, et al. Explainable artificial intelligence (xai): Concepts, taxonomies, opportunities and challenges toward responsible ai. Information fusion, 58: 0 82--115, 2020
2020
-
[3]
Generating radiology re- ports via memory-driven transformer,
Zhihong Chen, Yan Song, Tsung-Hui Chang, and Xiang Wan. Generating radiology reports via memory-driven transformer. arXiv preprint arXiv:2010.16056, 2020
-
[4]
Dermatologist-level classification of skin cancer with deep neural networks
Andre Esteva, Brett Kuprel, Roberto A Novoa, Justin Ko, Susan M Swetter, Helen M Blau, and Sebastian Thrun. Dermatologist-level classification of skin cancer with deep neural networks. nature, 542 0 (7639): 0 115--118, 2017
2017
-
[5]
Why are explainable ai methods for prostate lesion detection rated poorly by radiologists? Applied Sciences, 14 0 (11): 0 4654, 2024
Mehmet A Gulum, Christopher M Trombley, Merve Ozen, Enes Esen, Melih Aksamoglu, and Mehmed Kantardzic. Why are explainable ai methods for prostate lesion detection rated poorly by radiologists? Applied Sciences, 14 0 (11): 0 4654, 2024
2024
-
[6]
Views can be deceiving: Improved ssl through feature space augmentation
Kimia Hamidieh, Haoran Zhang, Swami Sankaranarayanan, and Marzyeh Ghassemi. Views can be deceiving: Improved ssl through feature space augmentation. arXiv preprint arXiv:2406.18562, 2024
-
[7]
a rtner, Felix Biessmann, Nick L Beetz, Alexander Hartenstein, Lynn J Savic, Konrad Frob \
Charlie A Hamm, Georg L Baumg \"a rtner, Felix Biessmann, Nick L Beetz, Alexander Hartenstein, Lynn J Savic, Konrad Frob \"o se, Franziska Dr \"a ger, Simon Schallenberg, Madhuri Rudolph, et al. Interactive explainable deep learning model informs prostate cancer diagnosis at mri. Radiology, 307 0 (4): 0 e222276, 2023
2023
-
[8]
Brain tumor segmentation with deep neural networks
Mohammad Havaei, Axel Davy, David Warde-Farley, Antoine Biard, Aaron Courville, Yoshua Bengio, Chris Pal, Pierre-Marc Jodoin, and Hugo Larochelle. Brain tumor segmentation with deep neural networks. Medical image analysis, 35: 0 18--31, 2017
2017
-
[9]
Self-explainable ai for medical image analysis: A survey and new outlooks
Junlin Hou, Sicen Liu, Yequan Bie, Hongmei Wang, Andong Tan, Luyang Luo, and Hao Chen. Self-explainable ai for medical image analysis: A survey and new outlooks. arXiv preprint arXiv:2410.02331, 2024
-
[10]
Weina Jin, Xiaoxiao Li, and Ghassan Hamarneh. Evaluating explainable ai on a multi-modal medical imaging task: Can existing algorithms fulfill clinical requirements? In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 11945--11953, 2022
2022
-
[11]
Bi-rads-based classification of breast cancer mammogram dataset using six stand-alone machine learning algorithms
Ilker Ozsahin, Berna Uzun, Mubarak Taiwo Mustapha, Natacha Usanese, Melize Yuvali, and Dilber Uzun Ozsahin. Bi-rads-based classification of breast cancer mammogram dataset using six stand-alone machine learning algorithms. In Artificial Intelligence and Image Processing in Medical Imaging, pages 195--216. Elsevier, 2024
2024
-
[12]
why should i trust you?
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. " why should i trust you?" explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, pages 1135--1144, 2016
2016
-
[13]
Transparency of deep neural networks for medical image analysis: A review of interpretability methods
Zohaib Salahuddin, Henry C Woodruff, Avishek Chatterjee, and Philippe Lambin. Transparency of deep neural networks for medical image analysis: A review of interpretability methods. Computers in biology and medicine, 140: 0 105111, 2022
2022
-
[14]
Grad-cam: Visual explanations from deep networks via gradient-based localization
Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE international conference on computer vision, pages 618--626, 2017
2017
-
[15]
Explainable deep learning models in medical image analysis
Amitojdeep Singh, Sourya Sengupta, and Vasudevan Lakshminarayanan. Explainable deep learning models in medical image analysis. Journal of imaging, 6 0 (6): 0 52, 2020
2020
-
[16]
Prototypical networks for few-shot learning
Jake Snell, Kevin Swersky, and Richard Zemel. Prototypical networks for few-shot learning. Advances in neural information processing systems, 30, 2017
2017
-
[17]
What clinicians want: contextualizing explainable machine learning for clinical end use
Sana Tonekaboni, Shalmali Joshi, Melissa D McCradden, and Anna Goldenberg. What clinicians want: contextualizing explainable machine learning for clinical end use. In Machine learning for healthcare conference, pages 359--380. PMLR, 2019
2019
-
[18]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, ukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017
2017
-
[19]
R2gengpt: Radiology report generation with frozen llms
Zhanyu Wang, Lingqiao Liu, Lei Wang, and Luping Zhou. R2gengpt: Radiology report generation with frozen llms. Meta-Radiology, 1 0 (3): 0 100033, 2023
2023
-
[20]
arXiv preprint arXiv:1908.04626 , year=
Sarah Wiegreffe and Yuval Pinter. Attention is not not explanation. arXiv preprint arXiv:1908.04626, 2019
-
[21]
Chexplain: enabling physicians to explore and understand data-driven, ai-enabled medical imaging analysis
Yao Xie, Melody Chen, David Kao, Ge Gao, and Xiang'Anthony' Chen. Chexplain: enabling physicians to explore and understand data-driven, ai-enabled medical imaging analysis. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, pages 1--13, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.