Recognition: unknown
Enhancing Program Repair with Specification Guidance and Intermediate Behavioral Signals
Pith reviewed 2026-05-10 14:49 UTC · model grok-4.3
The pith
SpecTune improves automated program repair by using localized postconditions at execution checkpoints to generate precise debugging signals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
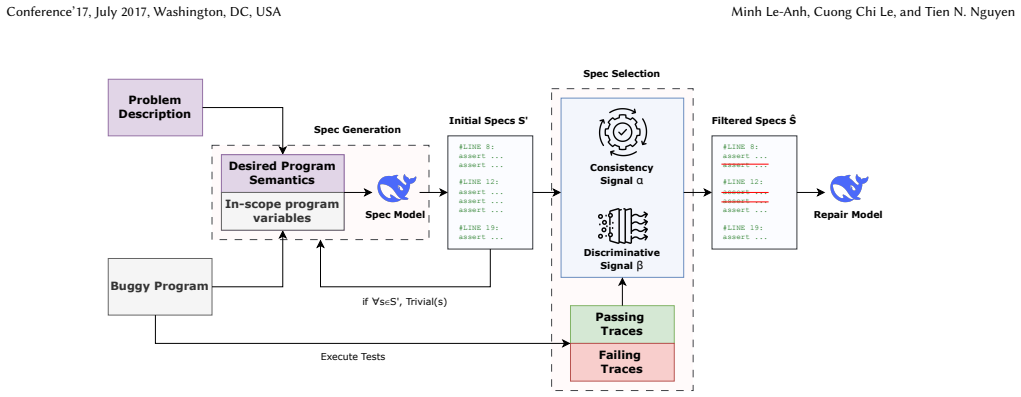
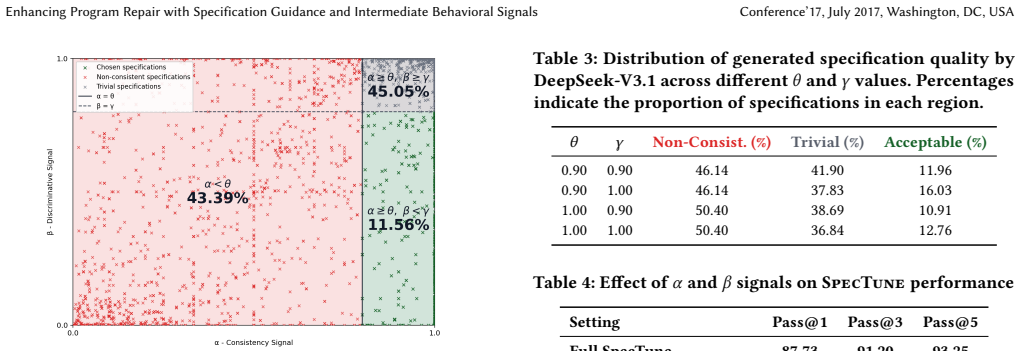
SpecTune decomposes the repair task into suspicious regions connected by execution checkpoints and derives localized postconditions representing expected program behaviors at those points. By executing the buggy program and evaluating these postconditions, SpecTune produces micro-level debugging signals that indicate mismatches between observed and intended behaviors, enabling more precise fault localization and targeted patch generation. To address the potential unreliability of LLM-generated postconditions, it introduces a specification validation signal alpha that estimates consistency using partially passing test cases and a discriminative signal beta that detects violations of validated
What carries the argument
The SpecTune framework, which decomposes code into checkpointed regions, generates localized postconditions, and filters them with an alpha consistency signal from partial test passes plus a beta violation signal to produce intermediate behavioral mismatch indicators.
If this is right
- Fault localization becomes more precise because mismatches are detected at internal checkpoints rather than only at test-suite exit.
- Patch generation can target the exact region where a postcondition fails instead of searching the whole program.
- Automatically generated specifications can be used safely once alpha and beta filtering remove unreliable ones.
- Repair effectiveness increases on bugs whose internal logic deviates from intent even when some tests still pass.
Where Pith is reading between the lines
- The checkpoint-plus-postcondition pattern could be reused in automated test generation to create more focused oracles.
- If the signals remain reliable at scale, the approach might reduce the need for exhaustive test suites in repair pipelines.
- Applying the same decomposition to multi-file or distributed systems would test whether the checkpoint idea generalizes beyond single-function bugs.
Load-bearing premise
LLM-generated postconditions, once filtered by the alpha consistency and beta violation signals, reliably indicate mismatches between observed and intended program behavior without introducing new errors into the repair process.
What would settle it
An experiment that disables or replaces the postcondition signals with random expectations on the same benchmarks and checks whether the reported gains in fault localization and patch success rate disappear.
Figures


read the original abstract
Automated Program Repair (APR) has recently benefited from large language models (LLMs). However, most LLM-based APR approaches still rely primarily on coarse end-to-end signals from test-suite outcomes to guide repair, providing limited insight into where a program's internal logic deviates from its intended behavior. In contrast, human debugging often relies on intermediate reasoning about program states through localized correctness conditions or assertions. Inspired by this observation, we propose SpecTune, a specification-guided debugging framework that incorporates intermediate behavioral reasoning into APR. SpecTune decomposes the repair task into suspicious regions connected by execution checkpoints and derives localized postconditions representing expected program behaviors at those points. By executing the buggy program and evaluating these postconditions, SpecTune produces micro-level debugging signals that indicate mismatches between observed and intended behaviors, enabling more precise fault localization and targeted patch generation. To address the potential unreliability of LLM-generated postconditions, we introduce two complementary signals: a specification validation signal alpha, which estimates the consistency of generated postconditions using partially passing test cases, and a discriminative signal beta, which detects violations of validated postconditions during execution. With these signals, SpecTune safely leverages automatically generated specifications for APR. Experimental results show that SpecTune improves fault localization and APR effectiveness than the baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SpecTune, a specification-guided debugging framework for automated program repair (APR) that decomposes buggy programs into suspicious regions linked by execution checkpoints. It uses LLMs to derive localized postconditions at these points, then applies a consistency signal alpha (based on partially passing tests) and a discriminative violation signal beta to generate micro-level behavioral mismatch signals. These signals are intended to enable more precise fault localization and targeted patch generation than standard LLM-based APR baselines that rely primarily on end-to-end test outcomes.
Significance. If the core claims hold, the work offers a pragmatic way to inject intermediate behavioral reasoning into LLM-driven APR, moving beyond coarse test-suite feedback toward human-like debugging. The alpha/beta filtering mechanism to handle LLM-generated specification unreliability is a concrete engineering contribution that could be adopted more broadly, provided the retained postconditions prove reliable.
major comments (2)
- [Abstract] Abstract: The central claim that 'Experimental results show that SpecTune improves fault localization and APR effectiveness than the baselines' is stated without any quantitative metrics, baseline names, dataset sizes, statistical tests, or ablation results. This absence leaves the primary empirical contribution unsupported and prevents evaluation of effect sizes or reproducibility.
- [§3] §3 (Framework description, alpha and beta signals): The approach assumes that postconditions retained after alpha consistency filtering and beta violation detection accurately reflect intended behavior at checkpoints. No independent validation (manual review of sampled postconditions, oracle comparison, or formal verification) is described to confirm that retained specifications are not merely non-contradictory with the test suite but actually correct. An incorrect postcondition that passes alpha could still produce misleading localization signals or patches that satisfy a faulty specification rather than the true intent.
minor comments (1)
- [Abstract] Abstract: The phrasing 'improves fault localization and APR effectiveness than the baselines' is grammatically incorrect; it should read 'improves ... over the baselines'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of SpecTune's potential to advance LLM-based APR through intermediate behavioral signals. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation and empirical support.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'Experimental results show that SpecTune improves fault localization and APR effectiveness than the baselines' is stated without any quantitative metrics, baseline names, dataset sizes, statistical tests, or ablation results. This absence leaves the primary empirical contribution unsupported and prevents evaluation of effect sizes or reproducibility.
Authors: We agree that the abstract should provide concrete quantitative support to substantiate the claims. The current version summarizes results at a high level only. In the revised manuscript, we will update the abstract to report specific metrics (e.g., improvements in fault localization precision and patch generation success rates over baselines), name the primary baselines, indicate dataset sizes and benchmarks used, and reference key statistical outcomes and ablation findings from the experiments section. This will allow readers to assess effect sizes and reproducibility directly from the abstract. revision: yes
-
Referee: [§3] §3 (Framework description, alpha and beta signals): The approach assumes that postconditions retained after alpha consistency filtering and beta violation detection accurately reflect intended behavior at checkpoints. No independent validation (manual review of sampled postconditions, oracle comparison, or formal verification) is described to confirm that retained specifications are not merely non-contradictory with the test suite but actually correct. An incorrect postcondition that passes alpha could still produce misleading localization signals or patches that satisfy a faulty specification rather than the true intent.
Authors: This concern is well-founded. Alpha and beta provide filtering based on test consistency and violation detection, but they do not independently verify semantic correctness of the postconditions against intended behavior. The original manuscript does not include manual review, oracle comparison, or formal verification of retained specifications. In the revision, we will add a dedicated analysis subsection that performs and reports a manual inspection of a sampled set of retained postconditions (e.g., 50 randomly selected instances across benchmarks) to evaluate their alignment with true program intent, thereby quantifying the risk of misleading signals and demonstrating the practical reliability of the filtering mechanism. revision: yes
Circularity Check
No significant circularity; empirical claims rest on external test execution and baselines
full rationale
The paper's derivation chain consists of an empirical proposal for SpecTune that generates postconditions via LLM, filters them using alpha (consistency on partial tests) and beta (violation detection) signals computed from actual program executions, then evaluates fault localization and patch quality on standard APR benchmarks. No equations or steps reduce a claimed result to a fitted parameter or self-citation by construction; the performance improvements are measured against independent baselines rather than being forced by internal definitions. The framework is self-contained against external oracles (test suites) and does not invoke uniqueness theorems or prior self-citations as load-bearing premises for its core signals.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can generate localized postconditions that capture intended program behavior at execution checkpoints
invented entities (2)
-
specification validation signal alpha
no independent evidence
-
discriminative signal beta
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Juan Altmayer Pizzorno and Emery D. Berger. 2025. CoverUp: Effective High Coverage Test Generation for Python.Proc. ACM Softw. Eng.2, FSE, Article FSE128 (June 2025), 23 pages. doi:10.1145/3729398
-
[2]
2026.Beyond Test Outcomes: Specification-Guided Program Repair via Intermediate Behavioral Signals
Anonymous. 2026.Beyond Test Outcomes: Specification-Guided Program Repair via Intermediate Behavioral Signals. doi:10.5281/zenodo.19351492
-
[3]
Islem Bouzenia, Premkumar Devanbu, and Michael Pradel. 2025. RepairAgent: An Autonomous, LLM-Based Agent for Program Repair. InProceedings of the IEEE/ACM 47th International Conference on Software Engineering(Ottawa, Ontario, Canada)(ICSE ’25). IEEE Press, 2188–2200. doi:10.1109/ICSE55347.2025.00157
-
[4]
Liushan Chen, Yu Pei, and Carlo A. Furia. 2021. Contract-Based Program Repair Without The Contracts: An Extended Study .IEEE Transactions on Software Engineering47, 12 (Dec. 2021), 2841–2857. doi:10.1109/TSE.2020.2970009
-
[5]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Zimin Chen, Steve Kommrusch, Michele Tufano, Louis-Noel Pouchet, Denys Poshyvanyk, and Martin Monperrus. 2021. SequenceR: Sequence-to-Sequence Learning for End-to-End Program Repair .IEEE Transactions on Software Engi- neering47, 09 (Sept. 2021), 1943–1959. doi:10.1109/TSE.2019.2940179
-
[7]
Elizabeth Dinella, Gabriel Ryan, Todd Mytkowicz, and Shuvendu K. Lahiri. 2022. TOGA: a neural method for test oracle generation. InProceedings of the 44th International Conference on Software Engineering(Pittsburgh, Pennsylvania)(ICSE ’22). Association for Computing Machinery, New York, NY, USA, 2130–2141. doi:10.1145/3510003.3510141
-
[8]
Madeline Endres, Sarah Fakhoury, Saikat Chakraborty, and Shuvendu K. Lahiri
-
[9]
Can Large Language Models Transform Natural Language Intent into Formal Method Postconditions?Proc. ACM Softw. Eng.1, FSE, Article 84 (July 2024), 24 pages. doi:10.1145/3660791
-
[10]
Zhiyu Fan, Xiang Gao, Martin Mirchev, Abhik Roychoudhury, and Shin Hwei Tan
-
[11]
Automated Repair of Programs from Large Language Models. InProceedings of the 45th International Conference on Software Engineering(Melbourne, Victoria, Australia)(ICSE ’23). IEEE Press, 1469–1481. doi:10.1109/ICSE48619.2023.00128
-
[12]
Pranav Garg, Daniel Neider, P. Madhusudan, and Dan Roth. 2016. Learning invariants using decision trees and implication counterexamples. InProceedings of the 43rd Annual ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages(St. Petersburg, FL, USA)(POPL ’16). Association for Computing Machinery, New York, NY, USA, 499–512. doi:10.1145/283761...
-
[13]
Ali Ghanbari, Samuel Benton, and Lingming Zhang. 2019. Practical program repair via bytecode mutation. InProceedings of the 28th ACM SIGSOFT In- ternational Symposium on Software Testing and Analysis(Beijing, China)(IS- STA 2019). Association for Computing Machinery, New York, NY, USA, 19–30. doi:10.1145/3293882.3330559
-
[14]
Jinru Hua, Mengshi Zhang, Kaiyuan Wang, and Sarfraz Khurshid. 2018. SketchFix: a tool for automated program repair approach using lazy candidate generation. In Proceedings of the 2018 26th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering(Lake Buena Vista, FL, USA)(ESEC/FSE 2018). Associ...
-
[15]
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. 2025. Live- CodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code. InThe Thirteenth International Conference on Learning Repre- sentations. https://openreview.net/forum?id=chfJJYC3iL
2025
-
[16]
Nan Jiang, Thibaud Lutellier, Yiling Lou, Lin Tan, Dan Goldwasser, and Xiangyu Zhang. 2023. KNOD: Domain Knowledge Distilled Tree Decoder for Automated Program Repair. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). 1251–1263. doi:10.1109/ICSE48619.2023.00111
- [17]
-
[18]
Darren Key, Wen-Ding Li, and Kevin Ellis. 2022. I Speak, You Verify: Toward Trust- worthy Neural Program Synthesis.CoRRabs/2210.00848 (2022). arXiv:2210.00848 doi:10.48550/ARXIV.2210.00848 Conference’17, July 2017, Washington, DC, USA Minh Le-Anh, Cuong Chi Le, and Tien N. Nguyen
-
[20]
Bissyandé, Dongsun Kim, Jacques Klein, Martin Monperrus, and Yves Le Traon
Anil Koyuncu, Kui Liu, Tegawendé F. Bissyandé, Dongsun Kim, Jacques Klein, Martin Monperrus, and Yves Le Traon. 2020. FixMiner: Mining relevant fix patterns for automated program repair.Empirical Softw. Engg.25, 3 (May 2020), 1980–2024. doi:10.1007/s10664-019-09780-z
-
[21]
Shuvendu K. Lahiri, Sarah Fakhoury, Aaditya Naik, Georgios Sakkas, Saikat Chakraborty, Madanlal Musuvathi, Piali Choudhury, Curtis von Veh, Jee- vana Priya Inala, Chenglong Wang, and Jianfeng Gao. 2023. Interactive Code Generation via Test-Driven User-Intent Formalization. arXiv:2208.05950 [cs.SE] https://arxiv.org/abs/2208.05950
-
[22]
Larissa Laich, Pavol Bielik, and Martin Vechev. 2020. Guiding Program Synthe- sis by Learning to Generate Examples. InInternational Conference on Learning Representations. https://openreview.net/forum?id=BJl07ySKvS
2020
-
[23]
Claire Le Goues, ThanhVu Nguyen, Stephanie Forrest, and Westley Weimer. 2012. GenProg: A Generic Method for Automatic Software Repair.IEEE Transactions on Software Engineering38, 1 (Jan 2012), 54–72. doi:10.1109/TSE.2011.104
-
[24]
Caroline Lemieux, Jeevana Priya Inala, Shuvendu K. Lahiri, and Siddhartha Sen. 2023. CodaMosa: Escaping Coverage Plateaus in Test Generation with Pre-Trained Large Language Models. InProceedings of the 45th International Conference on Software Engineering(Melbourne, Victoria, Australia)(ICSE ’23). IEEE Press, 919–931. doi:10.1109/ICSE48619.2023.00085
-
[25]
Yi Li, Shaohua Wang, and Tien N. Nguyen. 2020. DLFix: context-based code transformation learning for automated program repair. InProceedings of the ACM/IEEE 42nd International Conference on Software Engineering(Seoul, South Korea)(ICSE ’20). Association for Computing Machinery, New York, NY, USA, 602–614. doi:10.1145/3377811.3380345
-
[26]
Yi Li, Shaohua Wang, and Tien N. Nguyen. 2022. DEAR: a novel deep learning- based approach for automated program repair. InProceedings of the 44th Inter- national Conference on Software Engineering(Pittsburgh, Pennsylvania)(ICSE ’22). Association for Computing Machinery, New York, NY, USA, 511–523. doi:10.1145/3510003.3510177
-
[27]
Kui Liu, Anil Koyuncu, Dongsun Kim, and Tegawendé F. Bissyandé. 2019. TBar: revisiting template-based automated program repair. InProceedings of the 28th ACM SIGSOFT International Symposium on Software Testing and Analysis(Beijing, China)(ISSTA 2019). Association for Computing Machinery, New York, NY, USA, 31–42. doi:10.1145/3293882.3330577
-
[28]
Kui Liu, Anil Koyuncu, Dongsun Kim, and Tegawende F. Bissyandè. 2019. AVATAR: Fixing Semantic Bugs with Fix Patterns of Static Analysis Violations. In2019 IEEE 26th International Conference on Software Analysis, Evolution and Reengineering (SANER). 1–12. doi:10.1109/SANER.2019.8667970
-
[29]
Fan Long and Martin Rinard. 2015. Staged program repair with condition syn- thesis. InProceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering(Bergamo, Italy)(ESEC/FSE 2015). Association for Computing Ma- chinery, New York, NY, USA, 166–178. doi:10.1145/2786805.2786811
-
[30]
Fan Long and Martin Rinard. 2016. Automatic patch generation by learning correct code. InProceedings of the 43rd Annual ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages(St. Petersburg, FL, USA)(POPL ’16). Association for Computing Machinery, New York, NY, USA, 298–312. doi:10. 1145/2837614.2837617
-
[31]
Thibaud Lutellier, Hung Viet Pham, Lawrence Pang, Yitong Li, Moshi Wei, and Lin Tan. 2020. CoCoNuT: combining context-aware neural translation models using ensemble for program repair. InProceedings of the 29th ACM SIGSOFT International Symposium on Software Testing and Analysis(Virtual Event, USA) (ISSTA 2020). Association for Computing Machinery, New Yo...
-
[32]
Antonio Mastropaolo, Nathan Cooper, David Nader Palacio, Simone Scalabrino, Denys Poshyvanyk, Rocco Oliveto, and Gabriele Bavota. 2023. Using Transfer Learning for Code-Related Tasks.IEEE Transactions on Software Engineering49, 4 (2023), 1580–1598. doi:10.1109/TSE.2022.3183297
-
[33]
Sergey Mechtaev, Jooyong Yi, and Abhik Roychoudhury. 2016. Angelix: scalable multiline program patch synthesis via symbolic analysis. InProceedings of the 38th International Conference on Software Engineering(Austin, Texas)(ICSE ’16). Association for Computing Machinery, New York, NY, USA, 691–701. doi:10. 1145/2884781.2884807
-
[34]
Facundo Molina, Pablo Ponzio, Nazareno Aguirre, and Marcelo Frias. 2021. EvoSpex: An Evolutionary Algorithm for Learning Postconditions. InProceedings of the 43rd International Conference on Software Engineering(Madrid, Spain)(ICSE ’21). IEEE Press, 1223–1235. doi:10.1109/ICSE43902.2021.00112
- [35]
-
[36]
Hoang Duong Thien Nguyen, Dawei Qi, Abhik Roychoudhury, and Satish Chan- dra. 2013. SemFix: Program repair via semantic analysis. In2013 35th Interna- tional Conference on Software Engineering (ICSE). 772–781. doi:10.1109/ICSE.2013. 6606623
-
[37]
Kexin Pei, David Bieber, Kensen Shi, Charles Sutton, and Pengcheng Yin. 2023. Can Large Language Models Reason about Program Invariants?. InProceedings of the 40th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 202), Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan ...
2023
-
[38]
Minh V. T. Pham, Huy N. Phan, Nhat Hoang Phan, Cuong Chi Le, Tien N. Nguyen, and Nghi Bui. 2026. Synthetic Repo-level Bug Dataset for Training Automated Program Repair Models. InProceedings of the 48th International Conference on Software Engineering (ICSE ’26 (To Appear)). ACM Press
2026
-
[39]
Hao Tang, Keya Hu, Jin Peng Zhou, Si Cheng Zhong, Wei-Long Zheng, Xujie Si, and Kevin Ellis. 2024. Code Repair with LLMs gives an Exploration-Exploitation Tradeoff. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=o863gX6DxA
2024
- [40]
-
[41]
Michele Tufano, Dawn Drain, Alexey Svyatkovskiy, and Neel Sundaresan. 2022. Generating accurate assert statements for unit test cases using pretrained trans- formers. InProceedings of the 3rd ACM/IEEE International Conference on Au- tomation of Software Test(Pittsburgh, Pennsylvania)(AST ’22). Association for Computing Machinery, New York, NY, USA, 54–64....
-
[42]
Vasudev Vikram, Caroline Lemieux, Joshua Sunshine, and Rohan Padhye
- [43]
-
[44]
Weishi Wang, Yue Wang, Shafiq Joty, and Steven C.H. Hoi. 2023. RAP-Gen: Retrieval-Augmented Patch Generation with CodeT5 for Automatic Program Repair. InProceedings of the 31st ACM Joint European Software Engineering Con- ference and Symposium on the Foundations of Software Engineering(San Francisco, CA, USA)(ESEC/FSE 2023). Association for Computing Mach...
-
[45]
Yuxiang Wei, Chunqiu Steven Xia, and Lingming Zhang. 2023. Copiloting the Copilots: Fusing Large Language Models with Completion Engines for Auto- mated Program Repair. InProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (San Francisco, CA, USA)(ESEC/FSE 2023). Association f...
-
[46]
Westley Weimer, ThanhVu Nguyen, Claire Le Goues, and Stephanie Forrest. 2009. Automatically finding patches using genetic programming. In2009 IEEE 31st International Conference on Software Engineering. 364–374. doi:10.1109/ICSE.2009. 5070536
-
[47]
Chunqiu Steven Xia, Yuxiang Wei, and Lingming Zhang. 2023. Automated Program Repair in the Era of Large Pre-Trained Language Models. InProceedings of the 45th International Conference on Software Engineering(Melbourne, Victoria, Australia)(ICSE ’23). IEEE Press, 1482–1494. doi:10.1109/ICSE48619.2023.00129
-
[48]
Chunqiu Steven Xia and Lingming Zhang. 2022. Less training, more repairing please: revisiting automated program repair via zero-shot learning. InProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering(Singapore, Singapore)(ESEC/FSE 2022). Association for Computing Machinery, New Y...
-
[49]
Chunqiu Steven Xia and Lingming Zhang. 2024. Automated Program Repair via Conversation: Fixing 162 out of 337 Bugs for $0.42 Each using ChatGPT. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis(Vienna, Austria)(ISSTA 2024). Association for Computing Machinery, New York, NY, USA, 819–831. doi:10.1145/3650212.3680323
-
[50]
Jifeng Xuan, Matias Martinez, Favio DeMarco, Maxime Clement, Sebastian Lame- las Marcote, Thomas Durieux, Daniel Le Berre, and Martin Monperrus. 2017. Nopol: Automatic Repair of Conditional Statement Bugs in Java Programs.IEEE Trans. Softw. Eng.43, 1 (Jan. 2017), 34–55. doi:10.1109/TSE.2016.2560811
-
[51]
Jianan Yao, Gabriel Ryan, Justin Wong, Suman Jana, and Ronghui Gu. 2020. Learning nonlinear loop invariants with gated continuous logic networks. In Proceedings of the 41st ACM SIGPLAN Conference on Programming Language Design and Implementation(London, UK)(PLDI 2020). Association for Computing Machinery, New York, NY, USA, 106–120. doi:10.1145/3385412.3385986
-
[52]
He Ye, Matias Martinez, Xiapu Luo, Tao Zhang, and Martin Monperrus. 2023. SelfAPR: Self-supervised Program Repair with Test Execution Diagnostics. In Proceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering(Rochester, MI, USA)(ASE ’22). Association for Computing Machin- ery, New York, NY, USA, Article 92, 13 pages. doi:1...
-
[53]
Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, and Abhik Roychoudhury. 2024. Au- toCodeRover: Autonomous Program Improvement. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis(Vienna, Austria)(ISSTA 2024). Association for Computing Machinery, New York, NY, USA, 1592–1604. doi:10.1145/3650212.3680384
-
[54]
Qihao Zhu, Zeyu Sun, Yuan-an Xiao, Wenjie Zhang, Kang Yuan, Yingfei Xiong, and Lu Zhang. 2021. A syntax-guided edit decoder for neural program repair. Enhancing Program Repair with Specification Guidance and Intermediate Behavioral Signals Conference’17, July 2017, Washington, DC, USA InProceedings of the 29th ACM Joint Meeting on European Software Engine...
-
[55]
Qihao Zhu, Zeyu Sun, Wenjie Zhang, Yingfei Xiong, and Lu Zhang. 2023. Tare: Type-Aware Neural Program Repair. InProceedings of the 45th International Conference on Software Engineering(Melbourne, Victoria, Australia)(ICSE ’23). IEEE Press, 1443–1445. doi:10.1109/ICSE48619.2023.00126
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.