Recognition: 2 theorem links
· Lean TheoremPair2Scene: Learning Local Object Relations for Procedural Scene Generation
Pith reviewed 2026-05-12 01:51 UTC · model grok-4.3
The pith
Object placements in 3D indoor scenes can be modeled through learned local support and functional relations to generate complex environments beyond the training distribution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Pair2Scene trains a network on a curated 3D-Pairs dataset to capture two main types of local relations: support relations that follow physical hierarchies and functional relations that reflect semantic links. At inference time the framework starts with root objects and recursively places dependent objects according to the learned position distributions, using collision-aware rejection sampling inside the hierarchy to resolve local decisions into globally plausible scenes that maintain physical stability and semantic consistency while exceeding the complexity of the original training data.
What carries the argument
A neural network that estimates the spatial position distribution of a dependent object conditioned only on the position and geometry of one or more anchor objects, representing support and functional relations.
If this is right
- Scenes can be built hierarchically starting from a small set of seed objects and scaling to arbitrary density without retraining.
- Physical plausibility is enforced by support relations and explicit collision rejection at each placement step.
- Semantic coherence is achieved through functional relations without needing global context or external reasoning modules.
- The same trained model generalizes to scene layouts whose overall statistics differ from the training distribution.
- Generation remains procedural and controllable by varying the hierarchy depth and rejection thresholds.
Where Pith is reading between the lines
- The same local-pair approach could be tested on 2D floor-plan generation or robotic workspace arrangement where full-scene examples are also scarce.
- Because recursion depth controls complexity, the method might allow users to generate scenes at multiple scales from the same trained weights.
- Combining the learned local rules with high-level semantic guidance from other models could produce task-specific scenes while retaining the spatial precision shown here.
Load-bearing premise
Local dependencies between objects are sufficient to produce coherent global scene layouts when applied recursively within hierarchies together with collision-aware rejection sampling.
What would settle it
Generate scenes with object counts and densities well above those in the training set and measure rates of physical instability (objects intersecting or falling) or semantic implausibility (objects placed in functionally invalid locations); high failure rates would falsify the claim that local rules suffice.
Figures

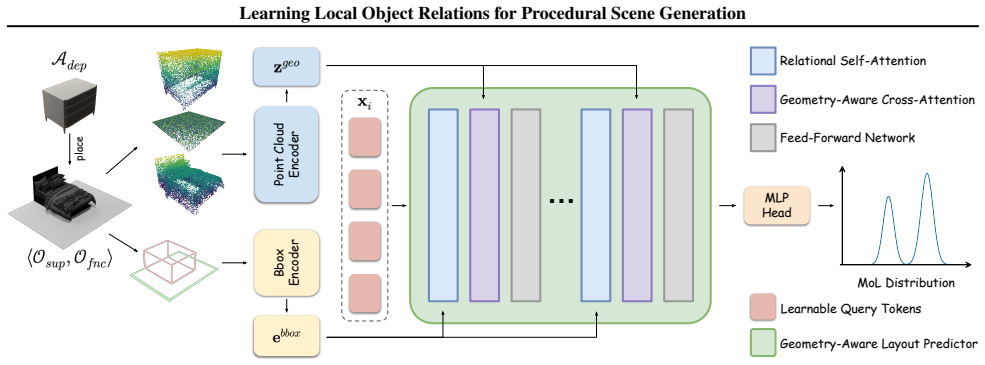

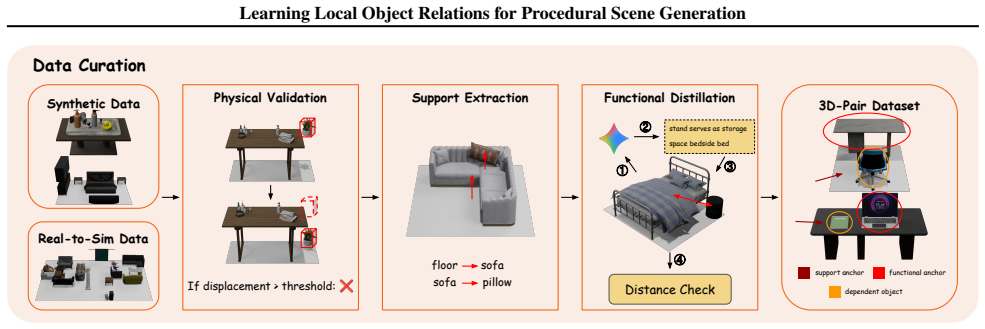














read the original abstract
Generating high-fidelity 3D indoor scenes remains a significant challenge due to data scarcity and the complexity of modeling intricate spatial relations. Current methods often struggle to scale beyond training distribution to dense scenes or rely on LLMs/VLMs that lack the ability for precise spatial reasoning. Building on top of the observation that object placement relies mainly on local dependencies instead of information-redundant global distributions, in this paper, we propose Pair2Scene, a novel procedural generation framework that integrates learned local rules with scene hierarchies and physics-based algorithms. These rules mainly capture two types of inter-object relations, namely support relations that follow physical hierarchies, and functional relations that reflect semantic links. We model these rules through a network, which estimates spatial position distributions of dependent objects conditioned on position and geometry of the anchor ones. Accordingly, we curate a dataset 3D-Pairs from existing scene data to train the model. During inference, our framework can generate scenes by recursively applying our model within a hierarchical structure, leveraging collision-aware rejection sampling to align local rules into coherent global layouts. Extensive experiments demonstrate that our framework outperforms existing methods in generating complex environments that go beyond training data while maintaining physical and semantic plausibility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Pair2Scene, a procedural 3D indoor scene generation framework that learns local support and functional relations between object pairs from a curated 3D-Pairs dataset. A neural network models conditional spatial position distributions for dependent objects given anchor geometry and position. Scenes are generated recursively by applying the model in an (unspecified) hierarchical structure combined with collision-aware rejection sampling. The central claim is that this local-rule approach outperforms prior methods on complex, out-of-distribution scenes while preserving physical and semantic plausibility.
Significance. If the empirical claims hold, the work would be significant for procedural scene synthesis: it offers a data-efficient alternative to global distribution models or LLM-based methods by showing that curated local pair relations can compose into plausible layouts beyond the training distribution. The integration of learned distributions with physics-based rejection sampling is a concrete strength that could influence future hybrid procedural pipelines.
major comments (3)
- [Abstract and Experiments] Abstract and Experiments section: the claim that the framework 'outperforms existing methods' and produces 'plausible' results in complex OOD scenes is asserted without any reported quantitative metrics, baselines, ablation studies, or error analysis. This absence directly undermines verification of the generalization and plausibility claims that constitute the paper's main contribution.
- [Method and Inference] Method and Inference sections: the recursive application of the learned pair model 'within a hierarchical structure' plus collision-aware rejection sampling is presented as sufficient to produce globally coherent layouts, yet no analysis, failure-case enumeration, or ablation is given for cases with overlapping relations or dense packing. This step is load-bearing for the central claim that local dependencies alone suffice for OOD scenes.
- [§3] §3 (dataset curation): the 3D-Pairs dataset is described as capturing 'mainly' local dependencies, but no quantitative comparison is supplied against global scene statistics or alternative conditioning schemes to justify that local pair modeling is informationally adequate for the claimed generalization regime.
minor comments (2)
- [Method] Notation for the conditional distribution p(·|anchor) and the network architecture should be formalized with explicit equations rather than prose descriptions.
- [Experiments] Figure captions and experimental protocol details (scene sizes, object counts, rejection-sampling parameters) are insufficiently specified for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. We agree that the empirical claims require stronger quantitative support and that additional analysis of the inference process and dataset rationale would strengthen the manuscript. We outline revisions below to address each major comment.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: the claim that the framework 'outperforms existing methods' and produces 'plausible' results in complex OOD scenes is asserted without any reported quantitative metrics, baselines, ablation studies, or error analysis. This absence directly undermines verification of the generalization and plausibility claims that constitute the paper's main contribution.
Authors: We acknowledge that the current Experiments section relies primarily on qualitative visual comparisons. To strengthen the claims, we will add quantitative evaluations including baseline comparisons using metrics such as object placement accuracy and scene coherence scores, along with ablation studies on the pair model and collision sampling. These will be reported with error analysis in the revised Experiments section. revision: yes
-
Referee: [Method and Inference] Method and Inference sections: the recursive application of the learned pair model 'within a hierarchical structure' plus collision-aware rejection sampling is presented as sufficient to produce globally coherent layouts, yet no analysis, failure-case enumeration, or ablation is given for cases with overlapping relations or dense packing. This step is load-bearing for the central claim that local dependencies alone suffice for OOD scenes.
Authors: We agree that further validation of the recursive inference is warranted. In the revision we will add a new subsection with failure-case enumeration for overlapping relations and dense packing, plus an ablation isolating the contribution of collision-aware sampling. This will demonstrate how local rules compose into coherent global layouts. revision: yes
-
Referee: [§3] §3 (dataset curation): the 3D-Pairs dataset is described as capturing 'mainly' local dependencies, but no quantitative comparison is supplied against global scene statistics or alternative conditioning schemes to justify that local pair modeling is informationally adequate for the claimed generalization regime.
Authors: To justify the local modeling choice, we will augment Section 3 with quantitative comparisons of local versus global relation statistics extracted from the source scene datasets, as well as a brief comparison of model performance under local versus global conditioning. This will support the claim that local pair relations are informationally adequate. revision: yes
Circularity Check
No significant circularity; derivation relies on independent training and procedural application
full rationale
The paper trains a network on a curated 3D-Pairs dataset extracted from existing scene data to learn local support and functional relations, then applies the model recursively within hierarchies plus collision-aware rejection sampling. No equations, predictions, or claims in the abstract or described framework reduce outputs to fitted inputs by construction, nor do any load-bearing steps rely on self-citations, imported uniqueness theorems, or smuggled ansatzes. The central premise (local dependencies suffice for global coherence) is presented as an observation to be validated empirically rather than a definitional equivalence. This is a standard non-circular setup for learned procedural generation.
Axiom & Free-Parameter Ledger
free parameters (1)
- neural network parameters
axioms (1)
- domain assumption Local object relations dominate scene structure over global distributions
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
object placement relies mainly on local dependencies instead of information-redundant global distributions... recursively applying our model within a hierarchical structure, leveraging collision-aware rejection sampling
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Support Tree (Ts) ... Functional Tree (Tf) ... ordered sequence of relational tuples
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
Kenny Jones, Qiuhong Anna Wei, Kailiang Fu, and Daniel Ritchie
Aguina-Kang, R., Gumin, M., Han, D. H., Morris, S., Yoo, S. J., Ganeshan, A., Jones, R. K., Wei, Q. A., Fu, K., and Ritchie, D. Open-universe indoor scene generation using llm program synthesis and uncurated object databases. arXiv preprint arXiv:2403.09675, 2024
-
[3]
Bi \'n kowski, M., Sutherland, D. J., Arbel, M., and Gretton, A. Demystifying mmd gans. In ICLR, 2018
work page 2018
-
[4]
I-design: Personalized llm interior designer
C elen, A., Han, G., Schindler, K., Van Gool, L., Armeni, I., Obukhov, A., and Wang, X. I-design: Personalized llm interior designer. arXiv preprint arXiv:2404.02838, 2024
-
[5]
Global-local tree search in vlms for 3d indoor scene generation
Deng, W., Qi, M., and Ma, H. Global-local tree search in vlms for 3d indoor scene generation. In CVPR, 2025
work page 2025
-
[6]
Feng, W., Zhu, W., Fu, T.-j., Jampani, V., Akula, A., He, X., Basu, S., Wang, X. E., and Wang, W. Y. Layoutgpt: Compositional visual planning and generation with large language models. In NeurIPS, 2023
work page 2023
-
[7]
Casagpt: cuboid arrangement and scene assembly for interior design
Feng, W., Zhou, H., Liao, J., Cheng, L., and Zhou, W. Casagpt: cuboid arrangement and scene assembly for interior design. In CVPR, 2025
work page 2025
-
[8]
3d-front: 3d furnished rooms with layouts and semantics
Fu, H., Cai, B., Gao, L., Zhang, L.-X., Wang, J., Li, C., Zeng, Q., Sun, C., Jia, R., Zhao, B., et al. 3d-front: 3d furnished rooms with layouts and semantics. In ICCV, 2021
work page 2021
-
[9]
Anyhome: Open-vocabulary generation of structured and textured 3d homes
Fu, R., Wen, Z., Liu, Z., and Sridhar, S. Anyhome: Open-vocabulary generation of structured and textured 3d homes. In ECCV, 2024
work page 2024
-
[10]
Gemini 3 flash: frontier intelligence built for speed, 2025
Google . Gemini 3 flash: frontier intelligence built for speed, 2025. URL https://blog.google/products/gemini/gemini-3-flash/
work page 2025
-
[11]
Mesatask: Towards task-driven tabletop scene generation via 3d spatial reasoning
Hao, J., Liang, N., Luo, Z., Xu, X., Zhong, W., Yi, R., Jin, Y., Lyu, Z., Zheng, F., Ma, L., et al. Mesatask: Towards task-driven tabletop scene generation via 3d spatial reasoning. arXiv preprint arXiv:2509.22281, 2025
-
[12]
Gans trained by a two time-scale update rule converge to a local nash equilibrium
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., and Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In NeurIPS, 2017
work page 2017
- [13]
-
[14]
arXiv preprint arXiv:2506.16504 , year=
Lai, Z., Zhao, Y., Liu, H., Zhao, Z., Lin, Q., Shi, H., Yang, X., Yang, M., Yang, S., Feng, Y., et al. Hunyuan3d 2.5: Towards high-fidelity 3d assets generation with ultimate details. arXiv preprint arXiv:2506.16504, 2025
-
[15]
Proc-GS : Procedural building generation for city assembly with 3d gaussians
Li, Y., Ran, X., Xu, L., Lu, T., Yu, M., Wang, Z., Xiangli, Y., Lin, D., and Dai, B. Proc-GS : Procedural building generation for city assembly with 3d gaussians. In CVPR, 2025
work page 2025
- [16]
-
[17]
E., Liu, W., Tian, Y., and Yuan, L
Pang, Y., Wang, W., Tay, F. E., Liu, W., Tian, Y., and Yuan, L. Masked autoencoders for point cloud self-supervised learning. In ECCV, 2022
work page 2022
-
[18]
Atiss: Autoregressive transformers for indoor scene synthesis
Paschalidou, D., Kar, A., Shugrina, M., Kreis, K., Geiger, A., and Fidler, S. Atiss: Autoregressive transformers for indoor scene synthesis. In NeurIPS, 2021
work page 2021
- [19]
-
[20]
Infinigen indoors: Photorealistic indoor scenes using procedural generation
Raistrick, A., Mei, L., Kayan, K., Yan, D., Zuo, Y., Han, B., Wen, H., Parakh, M., Alexandropoulos, S., Lipson, L., et al. Infinigen indoors: Photorealistic indoor scenes using procedural generation. In CVPR, 2024
work page 2024
-
[21]
Direct numerical layout generation for 3d indoor scene synthesis via spatial reasoning
Ran, X., Li, Y., Xu, L., Yu, M., and Dai, B. Direct numerical layout generation for 3d indoor scene synthesis via spatial reasoning. arXiv preprint arXiv:2506.05341, 2025
-
[22]
Salimans, T., Karpathy, A., Chen, X., and Kingma, D. P. Pixelcnn++: Improving the pixelcnn with discretized logistic mixture likelihood and other modifications. In ICLR, 2017
work page 2017
-
[23]
Layoutvlm: Differentiable optimization of 3d layout via vision-language models
Sun, F.-Y., Liu, W., Gu, S., Lim, D., Bhat, G., Tombari, F., Li, M., Haber, N., and Wu, J. Layoutvlm: Differentiable optimization of 3d layout via vision-language models. In CVPR, 2025 a
work page 2025
-
[24]
Sun, W., Li, X., Li, M., Xu, K., Meng, X., and Meng, L. Hierarchically-structured open-vocabulary indoor scene synthesis with pre-trained large language model. In AAAI, 2025 b
work page 2025
-
[25]
Diffuscene: Denoising diffusion models for generative indoor scene synthesis
Tang, J., Nie, Y., Markhasin, L., Dai, A., Thies, J., and Nie ner, M. Diffuscene: Denoising diffusion models for generative indoor scene synthesis. In CVPR, 2024
work page 2024
-
[26]
Wavenet: A generative model for raw audio
van den Oord, A., Dieleman, S., Zen, H., Simonyan, K., Vinyals, O., Graves, A., Kalchbrenner, N., Senior, A., and Kavukcuoglu, K. Wavenet: A generative model for raw audio. In Proc. SSW, 2016
work page 2016
-
[27]
N., Kaiser, ., and Polosukhin, I
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, ., and Polosukhin, I. Attention is all you need. In NeurIPS, 2017
work page 2017
-
[28]
arXiv preprint arXiv:2412.01506 (2024) 4
Xiang, J., Lv, Z., Xu, S., Deng, Y., Wang, R., Zhang, B., Chen, D., Tong, X., and Yang, J. Structured 3d latents for scalable and versatile 3d generation. arXiv preprint arXiv:2412.01506, 2024
-
[29]
Yang, Y., Lu, J., Zhao, Z., Luo, Z., Yu, J. J., Sanchez, V., and Zheng, F. Llplace: The 3d indoor scene layout generation and editing via large language model. arXiv preprint arXiv:2406.03866, 2024 a
-
[30]
Holodeck: Language guided generation of 3d embodied ai environments
Yang, Y., Sun, F.-Y., Weihs, L., VanderBilt, E., Herrasti, A., Han, W., Wu, J., Haber, N., Krishna, R., Liu, L., et al. Holodeck: Language guided generation of 3d embodied ai environments. In CVPR, 2024 b
work page 2024
-
[31]
Zhai, G., \"O rnek, E. P., Chen, D. Z., Liao, R., Di, Y., Navab, N., Tombari, F., and Busam, B. Echoscene: Indoor scene generation via information echo over scene graph diffusion. In ECCV, 2024
work page 2024
-
[32]
Clay: A controllable large-scale generative model for creating high-quality 3d assets
Zhang, L., Wang, Z., Zhang, Q., Qiu, Q., Pang, A., Jiang, H., Yang, W., Xu, L., and Yu, J. Clay: A controllable large-scale generative model for creating high-quality 3d assets. In SIGGRAPH, 2024
work page 2024
-
[33]
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Zhao, Z., Lai, Z., Lin, Q., Zhao, Y., Liu, H., Yang, S., Feng, Y., Yang, M., Zhang, S., Yang, X., et al. Hunyuan3d 2.0: Scaling diffusion models for high resolution textured 3d assets generation. arXiv preprint arXiv:2501.12202, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
InternScenes: A Large-scale Simulatable Indoor Scene Dataset with Realistic Layouts
Zhong, W., Cao, P., Jin, Y., Luo, L., Cai, W., Lin, J., Wang, H., Lyu, Z., Wang, T., Dai, B., et al. Internscenes: A large-scale simulatable indoor scene dataset with realistic layouts. arXiv preprint arXiv:2509.10813, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Gala3d: Towards text-to-3d complex scene generation via layout-guided generative gaussian splatting
Zhou, X., Ran, X., Xiong, Y., He, J., Lin, Z., Wang, Y., Sun, D., and Yang, M.-H. Gala3d: Towards text-to-3d complex scene generation via layout-guided generative gaussian splatting. In ICML, 2024
work page 2024
-
[36]
On the continuity of rotation representations in neural networks
Zhou, Y., Barnes, C., Lu, J., Yang, J., and Li, H. On the continuity of rotation representations in neural networks. In CVPR, 2019
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.