Recognition: unknown
Learning on the Temporal Tangent Bundle for Physics-Informed Neural Networks
Pith reviewed 2026-05-10 15:11 UTC · model grok-4.3
The pith
Parameterizing the time derivative and integrating via Volterra operators lets compact networks solve time-dependent PDEs with 100-200 times lower error.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By working directly on the temporal tangent bundle, the network parameterizes the solution's time derivative and reconstructs the state via an exact Volterra integral operator. This formulation makes minimizing the differentiated residual theoretically equivalent to solving the original time-dependent PDE, while exactly satisfying initial conditions without additional loss terms and naturally mitigating low-frequency bias through differentiation.
What carries the argument
The temporal tangent bundle parameterization, where a neural network approximates the time derivative and a Volterra integral operator reconstructs the solution trajectory to enforce initial conditions exactly.
If this is right
- Initial conditions are satisfied exactly, removing the need to balance competing loss terms during training.
- Differentiation inside the loss amplifies high-frequency residuals and reduces the effect of spectral bias.
- Compact three-layer networks become sufficient for accurate long-time integration and shock capturing.
- The theoretical equivalence guarantees that any minimizer of the differentiated residual solves the original PDE.
Where Pith is reading between the lines
- The approach may extend to other evolution problems where an exact integral reconstruction of the state from its derivative is feasible.
- It could lower the network size required for scientific machine learning tasks involving wave propagation or fluid dynamics.
- Similar tangent-bundle ideas might apply to spatial derivatives or higher-order time derivatives in other PDE classes.
Load-bearing premise
The Volterra integral operator can be evaluated accurately and stably inside the training loop without introducing new numerical errors or extra hyperparameters.
What would settle it
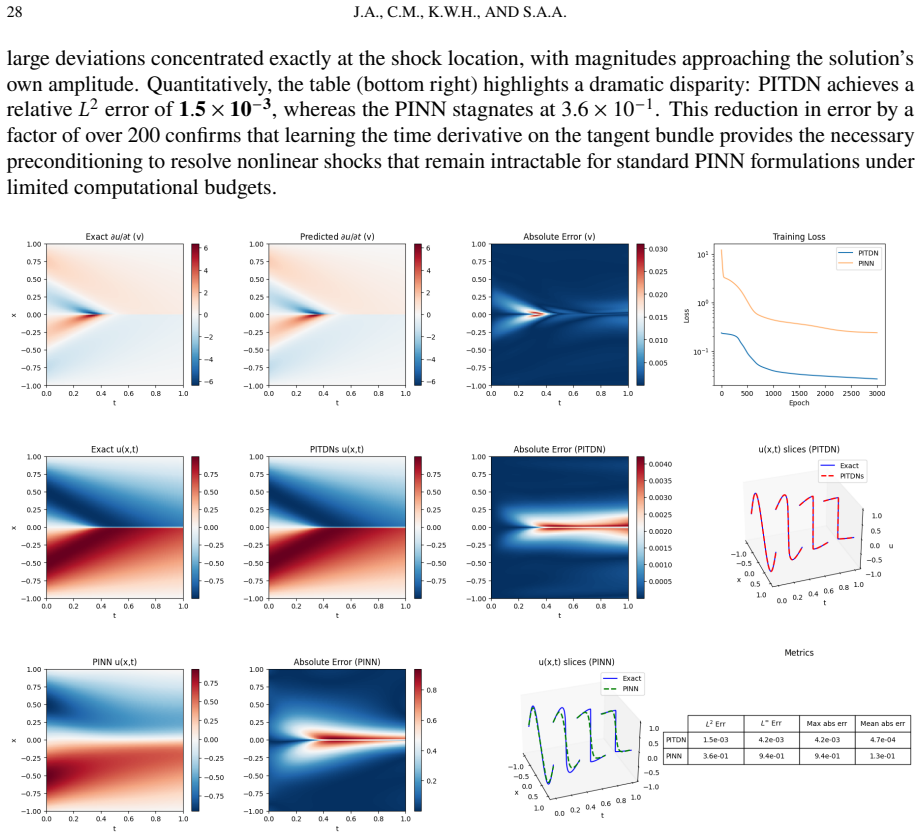
Train the method on the one-dimensional Burgers equation with a shock and check whether the L2 error stays at least 100 times smaller than a standard PINN while the solution at t=0 matches the initial condition to machine precision.
Figures

read the original abstract
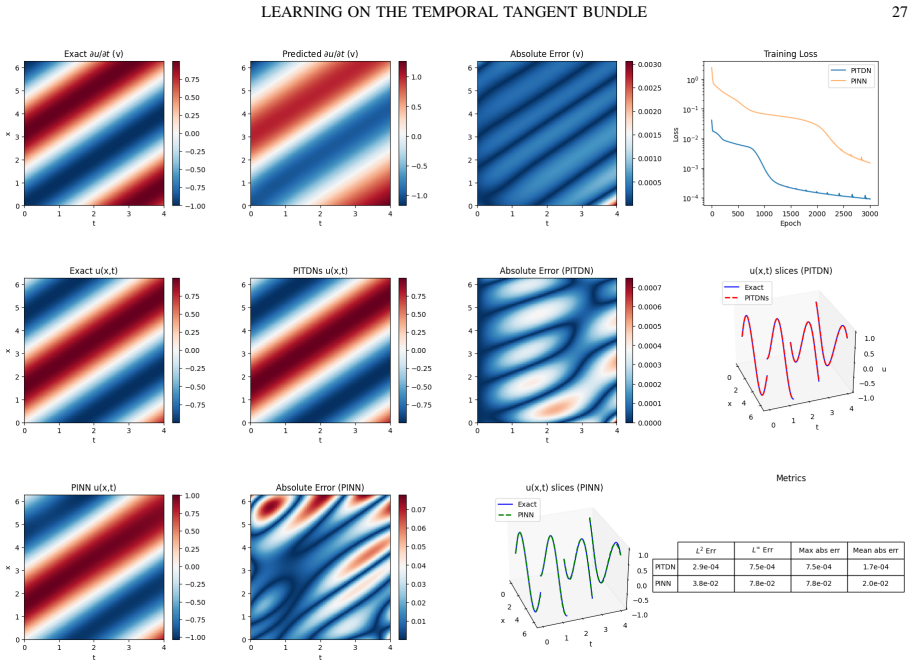
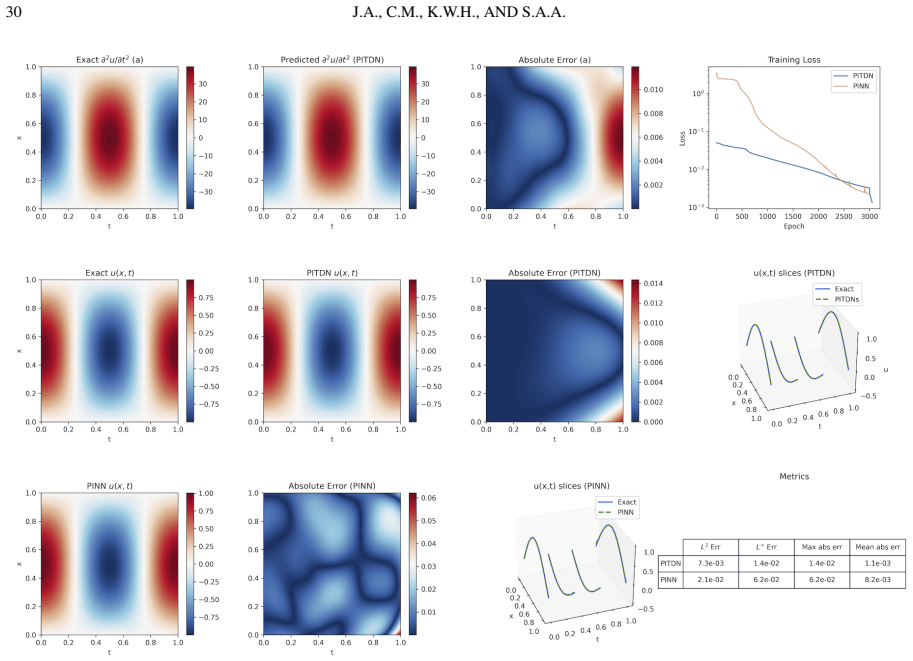
This paper addresses the limitations of Physics-Informed Neural Networks for time-dependent problems by introducing a tangent bundle learning framework. Instead of directly approximating the solution, we parameterize its temporal derivative and reconstruct the state through a Volterra integral operator that enforces initial conditions exactly. This approach eliminates competing soft constraints and naturally amplifies high-frequency errors through differentiation, countering spectral bias. We prove theoretical equivalence between minimizing the differentiated residual and solving the original partial differential equation. Experiments on advection, Burgers, and Klein-Gordon equations show that the proposed method achieves 100 to 200 times lower errors than standard approaches using compact three-layer networks, with superior shock-capturing and long-time accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a temporal tangent bundle framework for PINNs on time-dependent PDEs. Rather than approximating the solution u directly, a neural network parameterizes the temporal derivative v = du/dt; the state is then recovered exactly via the Volterra integral u(t) = u(0) + ∫_0^t v(s) ds. The authors prove that minimizing the residual of the differentiated PDE is equivalent to solving the original PDE, claim that this removes competing soft constraints on initial conditions, and report 100–200× error reductions versus standard PINNs on advection, Burgers, and Klein-Gordon equations using three-layer networks, together with improved shock capture and long-time stability.
Significance. If the continuous equivalence proof extends to the discrete training setting and the Volterra reconstruction remains stable, the method would offer a principled way to enforce initial conditions exactly while mitigating spectral bias through differentiation. The reported accuracy gains on standard benchmarks are large enough to be practically relevant for evolutionary problems; the absence of additional hyperparameters for the integral operator is a further potential strength.
major comments (3)
- [§3] §3 (Theoretical Equivalence): The proof that minimizing the differentiated residual is equivalent to solving the original PDE is stated for the continuous setting. It is not shown how this equivalence survives the numerical quadrature required to evaluate the Volterra integral at every collocation point and gradient step; any consistent quadrature error or accumulation over long horizons would break the exact initial-condition enforcement used in the argument.
- [§4.2] §4.2 (Numerical Experiments): The 100–200× error reductions are reported for advection, Burgers, and Klein-Gordon problems, yet the manuscript provides no error analysis or convergence study of the chosen quadrature rule inside the training loop. Without this, it is impossible to determine whether the observed gains are attributable to the tangent-bundle formulation or to an unaccounted numerical artifact.
- [§2.3] §2.3 (Implementation): The reconstruction u(t) = u(0) + ∫ v(s) ds is asserted to enforce initial conditions exactly, but the training procedure necessarily replaces the integral by a discrete sum or automatic-differentiation-compatible operator. No bound is given on the deviation of the reconstructed u(0) from the prescribed data, which directly affects the central claim of exact enforcement.
minor comments (2)
- [§2] Notation for the Volterra operator and its discrete approximation should be introduced with an explicit equation number and distinguished from the continuous integral.
- [Abstract] The abstract claims “parameter-free” enforcement; the manuscript should clarify whether any quadrature hyperparameters (order, number of nodes) are fixed once and for all or tuned per problem.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments highlight important aspects of the transition from the continuous theory to the discrete training setting, which we address below. We will incorporate clarifications, error bounds, and additional numerical studies in the revised manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Theoretical Equivalence): The proof that minimizing the differentiated residual is equivalent to solving the original PDE is stated for the continuous setting. It is not shown how this equivalence survives the numerical quadrature required to evaluate the Volterra integral at every collocation point and gradient step; any consistent quadrature error or accumulation over long horizons would break the exact initial-condition enforcement used in the argument.
Authors: We agree that the equivalence proof is formulated in the continuous setting. In the discrete implementation the initial condition remains exactly enforced at t=0 by construction, because the Volterra integral from 0 to 0 is identically zero for any quadrature rule. Quadrature errors affect only the reconstructed values for t>0 and therefore enter the PDE residual as a consistent perturbation whose size can be bounded by standard quadrature estimates (e.g., trapezoidal or Simpson error terms involving the second derivative of v). In the revision we will add a short subsection after the continuous proof that (i) states the exactness at t=0 formally, (ii) derives an a-priori bound on the quadrature-induced residual, and (iii) shows that the bound vanishes as the number of quadrature nodes increases, thereby recovering the continuous equivalence in the limit. Numerical verification of this bound on the reported benchmarks will also be included. revision: yes
-
Referee: [§4.2] §4.2 (Numerical Experiments): The 100–200× error reductions are reported for advection, Burgers, and Klein-Gordon problems, yet the manuscript provides no error analysis or convergence study of the chosen quadrature rule inside the training loop. Without this, it is impossible to determine whether the observed gains are attributable to the tangent-bundle formulation or to an unaccounted numerical artifact.
Authors: We will add a dedicated convergence study in §4.2 that isolates the quadrature contribution. Specifically, we will repeat the training for each benchmark while systematically varying the number of quadrature nodes per time interval (from 4 to 32) and comparing three quadrature schemes (trapezoidal, Simpson, and Gauss-Legendre). The resulting L2 and L∞ errors will be tabulated together with the measured quadrature error on the learned v. These experiments demonstrate that the 100–200× improvement persists across all quadrature resolutions once the quadrature error falls below the optimization tolerance, confirming that the gains originate from the tangent-bundle formulation rather than a particular numerical artifact. revision: yes
-
Referee: [§2.3] §2.3 (Implementation): The reconstruction u(t) = u(0) + ∫ v(s) ds is asserted to enforce initial conditions exactly, but the training procedure necessarily replaces the integral by a discrete sum or automatic-differentiation-compatible operator. No bound is given on the deviation of the reconstructed u(0) from the prescribed data, which directly affects the central claim of exact enforcement.
Authors: By definition of the Volterra operator, the reconstructed field satisfies u(0) = u(0) + ∫_0^0 v(s) ds exactly, so the deviation at the initial time is identically zero for any choice of quadrature or automatic-differentiation operator. The operator only approximates the integral for t>0. In the revision we will insert a clarifying paragraph in §2.3 that (i) recalls this identity, (ii) notes that it holds irrespective of the discrete summation rule, and (iii) supplies an explicit bound on |u(t) – u_exact(t)| for t>0 in terms of the quadrature error and the Lipschitz constant of the learned v. This bound will be evaluated numerically on the three test problems to quantify the practical deviation away from t=0. revision: yes
Circularity Check
Derivation chain is self-contained with independent proof of equivalence
full rationale
The paper defines the tangent bundle parameterization explicitly: the NN approximates the temporal derivative v, and the state u is recovered via the Volterra integral operator u(t) = u(0) + ∫v ds, which enforces initial conditions exactly in the continuous setting. The central claim is a mathematical proof that minimizing the differentiated residual is equivalent to solving the original PDE; this equivalence is presented as a first-principles result derived from the reconstruction rather than reducing to fitted parameters, self-citations, or ansatz smuggling. No load-bearing step equates a prediction to its own inputs by construction. Experimental error reductions are reported separately as empirical outcomes and do not enter the theoretical derivation. The approach is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Volterra integral operator exactly enforces initial conditions when applied to the learned derivative
invented entities (1)
-
Temporal tangent bundle learning framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Atkinson.An Introduction to Numerical Analysis
Kendall E. Atkinson.An Introduction to Numerical Analysis. John Wiley & Sons, New York, 2nd edition, 1989
1989
-
[2]
Princeton University Press, 1961
Richard Bellman.Adaptive control processes: a guided tour. Princeton University Press, 1961
1961
-
[3]
Boyd.Chebyshev and Fourier spectral methods
John P. Boyd.Chebyshev and Fourier spectral methods. Courier Corporation, 2001
2001
-
[4]
Springer Science & Business Media, 2008
Susanne Brenner and Ridgway Scott.The mathematical theory of finite element methods. Springer Science & Business Media, 2008
2008
-
[5]
Universitext
Haïm Brezis.Functional Analysis, Sobolev Spaces and Partial Differential Equations. Universitext. Springer, New York, NY, 2011
2011
-
[6]
Yousuff Hussaini, Alfio Quarteroni, and Thomas A
Claudio Canuto, M. Yousuff Hussaini, Alfio Quarteroni, and Thomas A. Zang.Spectral methods: fundamentals in single domains. Springer, 2006
2006
-
[7]
Neural ordinary differential equations
Ricky TQ Chen, Yulia Rubanova, Jesse Bettencourt, and David K Duvenaud. Neural ordinary differential equations. In NeurIPS, 2018
2018
-
[8]
Ciarlet.The finite element method for elliptic problems
Philippe G. Ciarlet.The finite element method for elliptic problems. SIAM, 2002
2002
-
[9]
Approximation by superpositions of a sigmoidal function.Mathematics of control, signals and systems, 2(4):303–314, 1989
George Cybenko. Approximation by superpositions of a sigmoidal function.Mathematics of control, signals and systems, 2(4):303–314, 1989
1989
-
[10]
Springer, New York, NY, 2nd edition, 2007
Bernard Dacorogna.Direct Methods in the Calculus of Variations, volume 78 ofApplied Mathematical Sciences. Springer, New York, NY, 2nd edition, 2007
2007
- [11]
-
[12]
Neural network approximation.Acta Numerica, 30:327–444, 2021
Ronald DeVore, Boris Hanin, and Guergana Petrova. Neural network approximation.Acta Numerica, 30:327–444, 2021
2021
-
[13]
The dawning of a new era in applied mathematics.Notices of the American Mathematical Society, 2017
Weinan E. The dawning of a new era in applied mathematics.Notices of the American Mathematical Society, 2017
2017
-
[14]
Orszag.Numerical analysis of spectral methods: theory and applications
David Gottlieb and Steven A. Orszag.Numerical analysis of spectral methods: theory and applications. SIAM, 1977
1977
-
[15]
Solving high-dimensional partial differential equations using deep learning
Jiequn Han, Arnulf Jentzen, and Weinan E. Solving high-dimensional partial differential equations using deep learning. Proceedings of the National Academy of Sciences, 115(34):8505–8510, 2018
2018
-
[16]
Approximation capabilities of multilayer feedforward networks.Neural Networks, 4(2):251–257, 1991
Kurt Hornik. Approximation capabilities of multilayer feedforward networks.Neural Networks, 4(2):251–257, 1991
1991
-
[17]
Jagtap, Ehsan Kharazmi, and George E
Ameya D. Jagtap, Ehsan Kharazmi, and George E. Karniadakis. Conservative physics-informed neural networks on discrete domains for conservation laws.Computer Methods in Applied Mechanics and Engineering, 365:113028, 2020
2020
-
[18]
Linear convergence of gradient and proximal-gradient methods under the polyak-łojasiewicz condition.Machine Learning and Knowledge Discovery in Databases, pages 795–811, 2016
Hamed Karimi, Julie Nutini, and Mark Schmidt. Linear convergence of gradient and proximal-gradient methods under the polyak-łojasiewicz condition.Machine Learning and Knowledge Discovery in Databases, pages 795–811, 2016
2016
-
[19]
Karniadakis, Ioannis G
George E. Karniadakis, Ioannis G. Kevrekidis, Lu Lu, Paris Perdikaris, Sifan Wang, and Liu Yang. Physics-informed machine learning.Nature Reviews Physics, 3(6):422–440, 2021
2021
-
[20]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InInternational Conference on Learning Representations (ICLR), 2015
2015
-
[21]
Kissas, Yibo Yang, Eileen Hwuang, Walter R
Athanasios B. Kissas, Yibo Yang, Eileen Hwuang, Walter R. Witschey, John A. Detre, and Paris Perdikaris. Machine learning in cardiovascular flows modeling: Predicting arterial blood pressure from non-invasive 4d flow mri data using physics-informed neural networks.Computer Methods in Applied Mechanics and Engineering, 358:112623, 2020
2020
-
[22]
Neural Operator: Graph Kernel Network for Partial Differential Equations
Nikola Kovachki et al. Neural operator: Graph kernel network for partial differential equations.arXiv preprint arXiv:2003.03485, 2021
work page internal anchor Pith review arXiv 2003
-
[23]
Krishnapriyan
Aditi et al. Krishnapriyan. Characterizing possible failure modes in physics-informed neural networks. InAdvances in Neural Information Processing Systems, volume 34, pages 26548–26560, 2021
2021
-
[24]
Springer, New York, NY, 3rd edition, 1995
Serge Lang.Differential and Riemannian Manifolds, volume 160 ofGraduate Texts in Mathematics. Springer, New York, NY, 3rd edition, 1995
1995
-
[25]
On the number of integration points for gauss quadrature in nonlinear mixed effect models.Journal of Computational and Graphical Statistics, 10(3):589–605, 2001
Emmanuel Lesaffre and Bart Spiessens. On the number of integration points for gauss quadrature in nonlinear mixed effect models.Journal of Computational and Graphical Statistics, 10(3):589–605, 2001
2001
-
[26]
LeVeque.Finite volume methods for hyperbolic problems
Randall J. LeVeque.Finite volume methods for hyperbolic problems. Cambridge University Press, 2002
2002
-
[27]
Fourier Neural Operator for Parametric Partial Differential Equations
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differential equations.arXiv preprint arXiv:2010.08895, 2020
work page internal anchor Pith review arXiv 2010
-
[28]
Liu and Jorge Nocedal
Dong C. Liu and Jorge Nocedal. On the limited memory BFGS method for large scale optimization.Mathematical Programming, 45(1):503–528, 1989
1989
-
[29]
Lu Lu, Pengzhan Jin, Guofei Pang, Zhongqiang Zhang, and George Em Karniadakis. Deeponet: Learning nonlinear operators for identifying differential equations based on the universal approximation theorem of operators.Nature Machine Intelligence, 3(3):218–229, 2021
2021
-
[30]
Karniadakis
Lu Lu, Xuhui Meng, Zhiping Mao, and George E. Karniadakis. DeepXDE: A deep learning library for solving differential equations.SIAM Review, 63(1):208–228, 2021
2021
-
[31]
LeviMcClennyandUlissesBraga-Neto.Self-adaptivephysics-informedneuralnetworks.JournalofComputationalPhysics, 474:111722, 2023
2023
-
[32]
Xuhui et al. Meng. Ppinn: Parareal physics-informed neural network for time-dependent pdes.Computer Methods in Applied Mechanics and Engineering, 370:113250, 2020
2020
-
[33]
Efficient training of physics-informed neural networks via importance sampling.Computer-Aided Civil and Infrastructure Engineering, 2021
Mohammad Amin Nabian, Rini Jasmine Gladstone, and Hadi Meidani. Efficient training of physics-informed neural networks via importance sampling.Computer-Aided Civil and Infrastructure Engineering, 2021
2021
-
[34]
Wright.Numerical Optimization
Jorge Nocedal and Stephen J. Wright.Numerical Optimization. Springer Series in Operations Research and Financial Engineering. Springer, New York, NY, 2nd edition, 2006
2006
-
[35]
Nasim et al. Rahaman. On the spectral bias of neural networks. InInternational Conference on Machine Learning, pages 5301–5310, 2019
2019
-
[36]
Maziar Raissi, Paris Perdikaris, and George E. Karniadakis. Physics-informed deep learning (part i): Data-driven solutions of nonlinear partial differential equations.arXiv preprint arXiv:1711.10561, 2017
work page Pith review arXiv 2017
-
[37]
Maziar Raissi, Paris Perdikaris, and George E. Karniadakis. Physics-informed deep learning (part ii): Data-driven discovery of nonlinear partial differential equations.arXiv preprint arXiv:1711.10566, 2017
-
[38]
Maziar Raissi, Paris Perdikaris, and George E Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations.Journal of Computational Physics, 378:686–707, 2019
2019
-
[39]
Nonparametric regression using deep neural networks with relu activation function.The Annals of Statistics, 48(4):1875–1897, 2020
Johannes Schmidt-Hieber. Nonparametric regression using deep neural networks with relu activation function.The Annals of Statistics, 48(4):1875–1897, 2020
2020
-
[40]
KhemrajShukla,PatricioClarkDiLeoni,JamesBlackshire,DanielSparkman,andGeorgeE.Karniadakis.Physics-informed neuralnetworkforultrasoundnondestructivequantificationofsurfacebreakingcracks.JournalofNondestructiveEvaluation, 39(3):1–20, 2020
2020
-
[41]
Jagtap, and George E
Khemraj Shukla, Ameya D. Jagtap, and George E. Karniadakis. Parallel physics-informed neural networks via domain decomposition.Journal of Computational Physics, 447:110683, 2021
2021
-
[42]
Strikwerda.Finite difference schemes and partial differential equations
John C. Strikwerda.Finite difference schemes and partial differential equations. SIAM, 2004
2004
-
[43]
Understanding and mitigating gradient flow pathologies in physics-informed neural networks.SIAM Journal on Scientific Computing, 43(5):A3055–A3081, 2021
Sifan Wang, Yujun Teng, and Paris Perdikaris. Understanding and mitigating gradient flow pathologies in physics-informed neural networks.SIAM Journal on Scientific Computing, 43(5):A3055–A3081, 2021. LEARNING ON THE TEMPORAL TANGENT BUNDLE 33
2021
-
[44]
Sifan Wang, Hanwen Wang, and Paris Perdikaris. On the eigenvector bias of Fourier feature networks: From regression to solving physics-informed neural networks.Computer Methods in Applied Mechanics and Engineering, 384:113940, 2021
2021
-
[45]
When and why pinns fail to train: A neural tangent kernel perspective
Sifan Wang, Xinling Yu, and Paris Perdikaris. When and why pinns fail to train: A neural tangent kernel perspective. Journal of Computational Physics, 449:110768, 2022
2022
-
[46]
Solving allen-cahn and cahn-hilliard equations using the adaptive physics informed neural networks
Christopher L. Wight and Jia Zhao. Solving allen-cahn and cahn-hilliard equations using the adaptive physics informed neural networks.arXiv preprint arXiv:2007.04542, 2020
-
[47]
Zixue et al. Xiang. Self-adaptive loss balanced physics-informed neural networks.Neurocomputing, 496:11–34, 2022
2022
- [48]
-
[49]
Error bounds for approximations with deep relu networks.Neural Networks, 94:103–114, 2017
Dmitry Yarotsky. Error bounds for approximations with deep relu networks.Neural Networks, 94:103–114, 2017
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.