Recognition: unknown
How Transformers Learn to Plan via Multi-Token Prediction
Pith reviewed 2026-05-10 15:22 UTC · model grok-4.3
The pith
Multi-token prediction trains Transformers to solve planning tasks by first attending to the goal and then tracing the path backward.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
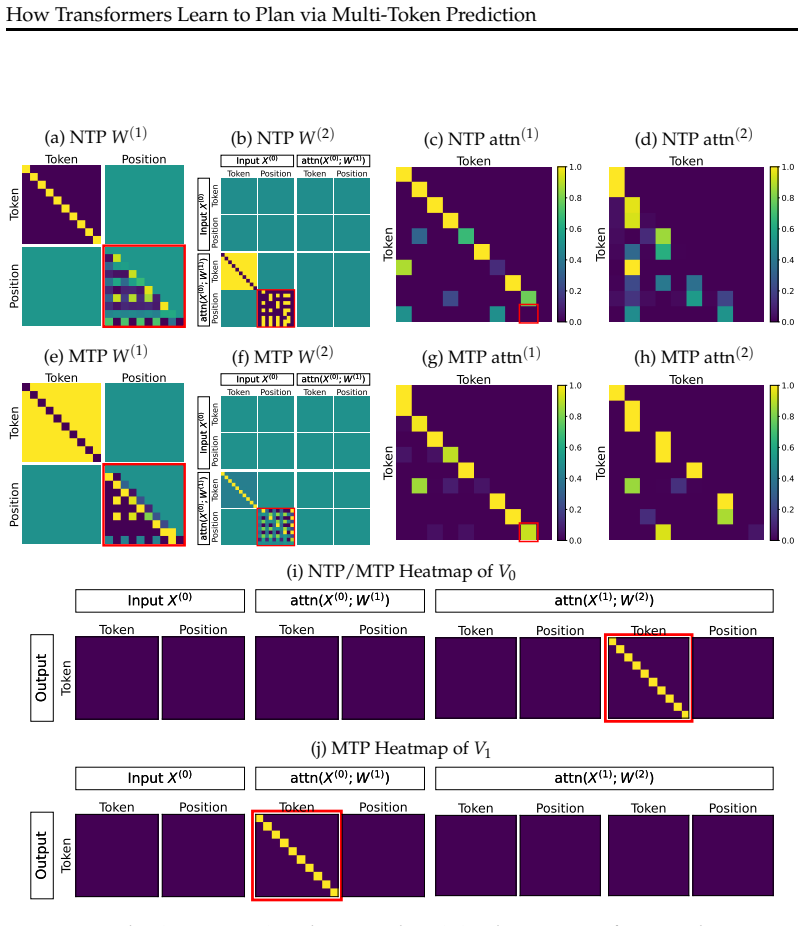
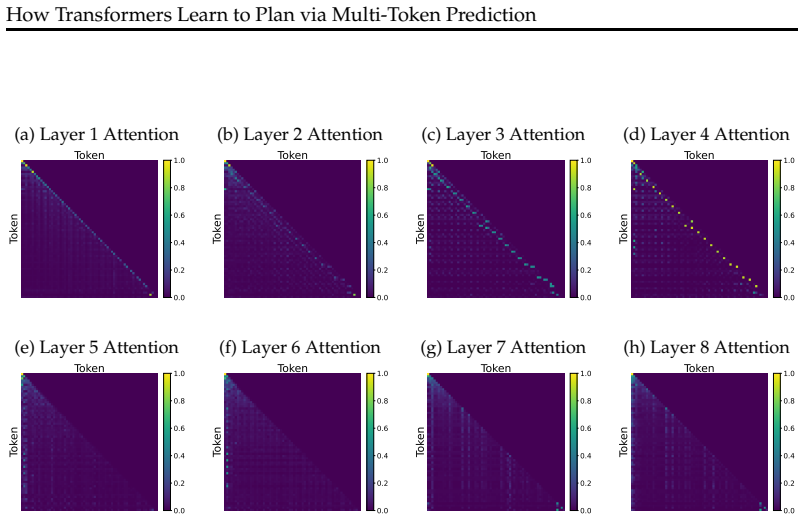
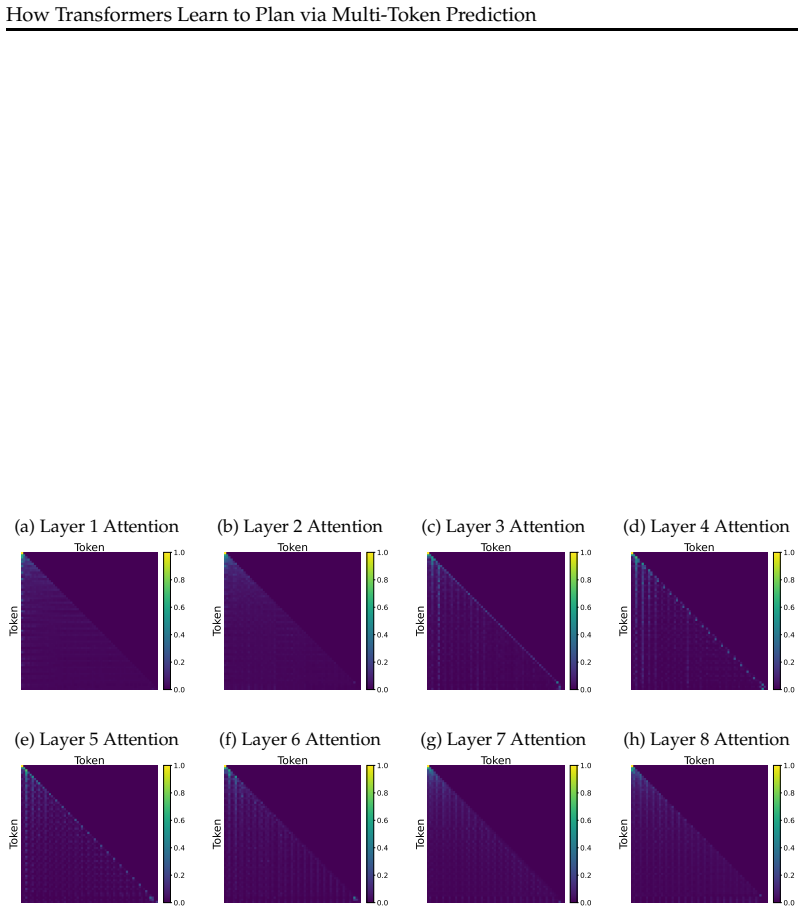
MTP induces a two-stage reverse reasoning process in which the model first attends to the end node and then reconstructs the path by tracing intermediate nodes backward; this arises because MTP's gradient decoupling property supplies a cleaner training signal than NTP, biasing optimization toward robust and interpretable reasoning circuits that generalize from synthetic graphs to Countdown and satisfiability problems.
What carries the argument
The gradient decoupling property of multi-token prediction, which separates loss gradients across predicted tokens and thereby enables the model to first focus on the goal node before filling in the preceding path.
If this is right
- MTP models outperform NTP models on path-finding tasks and on Countdown and boolean satisfiability benchmarks.
- The learned circuits are interpretable as explicit backward tracing from the goal.
- Optimization under MTP is biased toward planning strategies that remain stable across different graph sizes.
- The same reverse-reasoning bias can be expected in other sequential decision tasks where global structure matters.
Where Pith is reading between the lines
- If the reverse-reasoning circuit generalizes, MTP may reduce the need for explicit chain-of-thought prompting in larger models.
- The gradient-decoupling view suggests MTP could be combined with other auxiliary losses that further separate planning from local token prediction.
- Testing whether the same backward attention pattern appears in MTP-trained models on natural-language planning tasks would be a direct next experiment.
Load-bearing premise
The two-stage reverse reasoning seen in the simplified two-layer Transformer on the star graph extends to deeper models and to realistic planning benchmarks.
What would settle it
Train the same two-layer Transformer with MTP on the star graph and measure attention patterns: if the first attention head does not preferentially attend to the target end node before reconstructing earlier nodes, the claimed mechanism is not operating.
Figures



read the original abstract
While next-token prediction (NTP) has been the standard objective for training language models, it often struggles to capture global structure in reasoning tasks. Multi-token prediction (MTP) has recently emerged as a promising alternative, yet its underlying mechanisms remain poorly understood. In this paper, we study how MTP facilitates reasoning, with a focus on planning. Empirically, we show that MTP consistently outperforms NTP on both synthetic graph path-finding tasks and more realistic reasoning benchmarks, such as Countdown and boolean satisfiability problems. Theoretically, we analyze a simplified two-layer Transformer on a star graph task. We prove that MTP induces a two-stage reverse reasoning process: the model first attends to the end node and then reconstructs the path by tracing intermediate nodes backward. This behavior arises from a gradient decoupling property of MTP, which provides a cleaner training signal compared to NTP. Ultimately, our results highlight how multi-token objectives inherently bias optimization toward robust and interpretable reasoning circuits.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that multi-token prediction (MTP) outperforms next-token prediction (NTP) on synthetic graph path-finding tasks as well as realistic reasoning benchmarks such as Countdown and boolean satisfiability. It provides a theoretical analysis of a simplified two-layer Transformer on a star graph task, proving that MTP induces a two-stage reverse reasoning process (first attend to the end node, then backtrack via intermediate nodes) due to a gradient decoupling property that yields a cleaner training signal than NTP.
Significance. If the proposed mechanism generalizes beyond the toy setting, the work supplies both an empirical demonstration of MTP's advantage and an interpretable circuit-level explanation for why multi-token objectives can promote robust planning. The rigorous derivation for the two-layer star-graph case and the consistent outperformance on multiple tasks are clear strengths; however, the absence of direct evidence linking the identified circuit to the deeper-model results limits the strength of the causal claim.
major comments (1)
- [Empirical results on Countdown and boolean satisfiability] Empirical evaluation on Countdown and boolean satisfiability: the manuscript reports MTP performance gains but provides no attention-map, activation, or probing analysis on the trained deeper Transformers to confirm that the two-stage reverse-reasoning circuit (attend-to-end then backtrack) identified in the two-layer star-graph proof is actually operative. Without this verification, the performance gap could equally be explained by generic optimization benefits of MTP rather than the specific interpretable mechanism asserted in the central claim.
minor comments (1)
- [Abstract] The abstract and introduction could more explicitly qualify the scope of the theoretical result (two-layer model on star graphs) when stating the broader implications for practical reasoning tasks.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which identifies a key limitation in connecting our theoretical mechanism to the empirical results on realistic tasks. We address the major comment below and describe the revisions we will incorporate.
read point-by-point responses
-
Referee: Empirical evaluation on Countdown and boolean satisfiability: the manuscript reports MTP performance gains but provides no attention-map, activation, or probing analysis on the trained deeper Transformers to confirm that the two-stage reverse-reasoning circuit (attend-to-end then backtrack) identified in the two-layer star-graph proof is actually operative. Without this verification, the performance gap could equally be explained by generic optimization benefits of MTP rather than the specific interpretable mechanism asserted in the central claim.
Authors: We agree that the absence of mechanistic analyses on the deeper models leaves open the possibility that the observed gains stem from generic optimization benefits of MTP rather than the specific two-stage reverse-reasoning circuit proven for the simplified setting. Our theoretical result is derived rigorously for the two-layer Transformer on the star graph, where gradient decoupling cleanly induces the attend-to-end then backtrack behavior. The empirical section demonstrates consistent MTP advantages on Countdown and SAT, but does not include attention maps, activations, or probing to verify analogous circuits. In the revised manuscript, we will add attention visualizations and simple probing experiments on the Countdown-trained models to test for early attention to the target value, along with a limitations discussion noting that full causal verification for deeper models on SAT remains challenging due to problem complexity. This addresses the concern without overclaiming generalization of the exact circuit. revision: partial
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper's central theoretical result is a mathematical proof that MTP's loss induces gradient decoupling and a two-stage reverse reasoning circuit in a two-layer Transformer on star graphs. This follows directly from the MTP objective formulation and does not reduce to fitted parameters, self-definitions, or prior self-citations. Empirical gains on Countdown and SAT are reported as separate performance comparisons without claiming the toy-model circuit is verified by construction in those settings. No load-bearing steps collapse to inputs by definition or via self-referential uniqueness theorems.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The simplified two-layer Transformer on a star graph captures the essential optimization dynamics of planning in larger models trained with MTP.
Reference graph
Works this paper leans on
-
[1]
Efficient joint prediction of multiple future tokens.arXiv preprint arXiv:2503.21801,
Kwangjun Ahn, Alex Lamb, and John Langford. Efficient joint prediction of multiple future tokens.arXiv preprint arXiv:2503.21801,
-
[2]
Nvidia nemotron 3: Efficient and open intelligence, 2025
Aaron Blakeman, Aaron Grattafiori, Aarti Basant, Abhibha Gupta, Abhinav Khattar, Adi Renduchintala, Aditya Vavre, Akanksha Shukla, Akhiad Bercovich, Aleksander Ficek, et al. Nvidia nemotron 3: Efficient and open intelligence.arXiv preprint arXiv:2512.20856,
-
[3]
Association for Computing Machinery. ISBN 9781450374644. doi: 10.1145/800157.805047. URLhttps://doi.org/10.1145/800157.805047. Guhao Feng, Bohang Zhang, Yuntian Gu, Haotian Ye, Di He, and Liwei Wang. To- wards revealing the mystery behind chain of thought: A theoretical perspective. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (e...
-
[4]
Dan Friedman, Alexander Wettig, and Danqi Chen
URL https://proceedings.neurips.cc/paper files/paper/2023/ file/dfc310e81992d2e4cedc09ac47eff13e-Paper-Conference.pdf. Dan Friedman, Alexander Wettig, and Danqi Chen. Learning transformer programs.Ad- vances in Neural Information Processing Systems, 36:49044–49067,
2023
-
[5]
Training Compute-Optimal Large Language Models
URLhttps://openreview.net/forum?id=Zx6WUbE9J7. Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556,
work page internal anchor Pith review arXiv
-
[6]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[7]
URL https://openreview.net/forum? id=2HJcVtuovs. Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
arXiv preprint arXiv:2410.07746 , year=
URL https://openreview.net/forum?id= Bkg6RiCqY7. 11 How Transformers Learn to Plan via Multi-Token Prediction Roey Magen, Shuning Shang, Zhiwei Xu, Spencer Frei, Wei Hu, and Gal Vardi. Benign overfitting in single-head attention.arXiv preprint arXiv:2410.07746,
-
[9]
Weizhen Qi, Yu Yan, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang, and Ming Zhou
URLhttps://openreview.net/forum?id=jNM4imlHZv. Weizhen Qi, Yu Yan, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang, and Ming Zhou. Prophetnet: Predicting future n-gram for sequence-to-sequence pre- training. InFindings of the Association for Computational Linguistics: EMNLP 2020, pp. 2401–2410,
2020
-
[10]
Accessed: 2026-03-11. Mohammad Samragh, Arnav Kundu, David Harrison, Kumari Nishu, Devang Naik, Minsik Cho, and Mehrdad Farajtabar. Your llm knows the future: Uncovering its multi-token prediction potential.arXiv preprint arXiv:2507.11851,
-
[11]
Yuhao Wang, Heyang Liu, Ziyang Cheng, Ronghua Wu, Qunshan Gu, Yanfeng Wang, and Yu Wang
URL https://openreview.net/ forum?id=din0lGfZFd. Yuhao Wang, Heyang Liu, Ziyang Cheng, Ronghua Wu, Qunshan Gu, Yanfeng Wang, and Yu Wang. Vocalnet: Speech llms with multi-token prediction for faster and high-quality generation. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 19595–19612,
2025
-
[12]
MiMo-V2-Flash Technical Report
URLhttps://openreview.net/forum? id=AGJomYSrUG. Bangjun Xiao, Bingquan Xia, Bo Yang, Bofei Gao, Bowen Shen, Chen Zhang, Chenhong He, Chiheng Lou, Fuli Luo, Gang Wang, et al. Mimo-v2-flash technical report.arXiv preprint arXiv:2601.02780,
work page internal anchor Pith review arXiv
-
[13]
12 How Transformers Learn to Plan via Multi-Token Prediction Jiacheng Ye, Jiahui Gao, Shansan Gong, Lin Zheng, Xin Jiang, Zhenguo Li, and Lingpeng Kong
URL https://proceedings.neurips.cc/paper files/paper/2023/ file/271db9922b8d1f4dd7aaef84ed5ac703-Paper-Conference.pdf. 12 How Transformers Learn to Plan via Multi-Token Prediction Jiacheng Ye, Jiahui Gao, Shansan Gong, Lin Zheng, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Beyond autoregression: Discrete diffusion for complex reasoning and planning. InThe T...
2023
-
[14]
Qimin Zhong, Hao Liao, Siwei Wang, Mingyang Zhou, Xiaoqun Wu, Rui Mao, and Wei Chen. Understanding and enhancing the planning capability of language models via multi-token prediction.arXiv preprint arXiv:2509.23186,
-
[15]
6 5.2 The Reverse Reasoning Circuit
13 How Transformers Learn to Plan via Multi-Token Prediction Contents 1 Introduction 1 2 Related Work 3 3 Preliminaries 3 4 Planning Emerges with Multi-Token Prediction 4 5 Mechanisms of Planning under MTP: Reverse Reasoning 6 5.1 Problem Setup and Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6 5.2 The Reverse Reasoning Circuit . . . . ...
2020
-
[16]
Furthermore, the applicability of MTP has recently extended beyond text, showing significant promise in multi-modal architectures (Wang et al., 2025)
highlight MTP as a core component of their training pipelines. Furthermore, the applicability of MTP has recently extended beyond text, showing significant promise in multi-modal architectures (Wang et al., 2025). Post-training Adaptation.While industrial models integrate MTP during the compute- intensive pre-training phase, an emerging line of research f...
2025
-
[17]
utilize fine-tuning strategies to efficiently transform standard NTP models into MTP models. Future Prediction.Beyond standard MTP , a parallel line of research re-examines the fundamental modeling objective by shifting from point-wise prediction to holistic future modeling. At the sequence level, Mahajan et al. (2026) bypass discrete tokens entirely by p...
2026
-
[18]
ForT=10:T 3 −5T 2 +5T−2>0
Expanding: (T−1) 2(T−2)−T 2 =T 3 −5T 2 +5T+2. ForT=10:T 3 −5T 2 +5T−2>0. Therefore(T−1) 2(T−2)>T 2, giving: E ∂µ ∂w(1) = 1 T 1 (T−1) 2(T−2) − 1 T2 <0. FromL 1 =−logµand the chain rule: E ∂L1 ∂w(k) =− 1 µ 0 E ∂µ ∂w(k) . Substituting equation 14 and equation 15: E ∂L1 ∂w(1) = 1 Tµ 0 1 T2 − 1 (T−1) 2(T−2) >0, E ∂L1 ∂w(k) =− 1 Tµ 0 1 (T−1) 2(T−2) + 2 T2(T−2) ...
2096
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.