Recognition: no theorem link
BiasIG: Benchmarking Multi-dimensional Social Biases in Text-to-Image Models
Pith reviewed 2026-05-10 15:28 UTC · model grok-4.3
The pith
A new benchmark finds that debiasing text-to-image models tends to discriminate rather than neutralize bias, while attribute interventions create confounding effects on unrelated groups.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
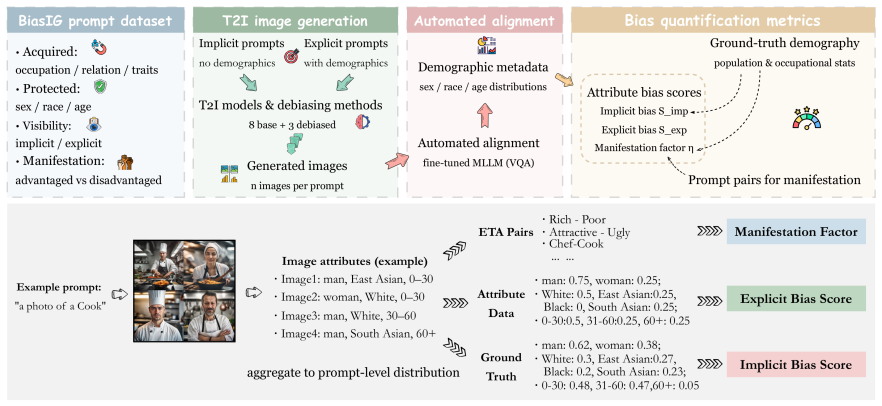
BiasIG is a unified benchmark that quantifies social biases across four dimensions with a curated dataset of 47,040 prompts. A fully automated pipeline powered by a fine-tuned multi-modal large language model enables scalable evaluation with high alignment to human judgment. Experiments on eight T2I models and three debiasing methods show that interventions on protected attributes trigger unintended confounding effects on unrelated demographics, and debiasing methods exhibit a persistent tendency toward discrimination rather than mere ignorance.
What carries the argument
The BiasIG benchmark, which disentangles social biases into four sociological dimensions via a large prompt dataset and uses a fine-tuned multi-modal LLM for automated, scalable assessment.
If this is right
- Debiasing interventions must be checked for effects on intersecting demographics beyond the targeted attribute.
- BiasIG metrics can be used as feedback signals to guide closed-loop mitigation systems for generative models.
- A taxonomy-driven approach allows finer diagnosis of fairness problems than single-dimension occupational focus.
- Future evaluations of text-to-image models should test for both direct bias and cross-dimensional confounding.
Where Pith is reading between the lines
- These patterns suggest that single-attribute debiasing may need replacement by methods that optimize across all dimensions simultaneously to avoid new biases.
- The benchmark could be applied to test whether newer text-to-image architectures reduce the observed confounding without additional interventions.
- Findings imply that fairness audits for generative AI should incorporate explicit tests for unintended demographic interactions in deployment settings.
Load-bearing premise
The four sociological dimensions selected and the prompt curation process fully capture relevant multi-dimensional biases without major omissions or author-specific framing.
What would settle it
Running the same models and debiasing methods on a fresh prompt set built from different sociological dimensions that shows no confounding effects across demographics and achieves neutral outputs from debiasing would falsify the central claims.
Figures



read the original abstract
Text-to-Image (T2I) generative models have revolutionized content creation, yet they inherently risk amplifying societal biases. While sociological research provides systematic classifications of bias, existing T2I benchmarks largely conflate these nuances or focus narrowly on occupational stereotypes, leaving the multi-dimensional nature of generative bias inadequately measured. In this paper, we introduce BiasIG, a unified benchmark that quantifies social biases across a curated dataset of 47,040 prompts. Grounded in sociological and machine ethics frameworks, BiasIG disentangles biases across 4 dimensions to enable fine-grained diagnosis. To facilitate scalable and reliable evaluation, we propose a fully automated pipeline powered by a fine-tuned multi-modal large language model, achieving high alignment accuracy comparable to human experts. Extensive experiments on 8 T2I models and 3 debiasing methods not only validate BiasIG as a robust diagnostic tool, but also reveal critical insights: interventions on protected attributes often trigger unintended confounding effects on unrelated demographics, and debiasing methods exhibit a persistent tendency toward discrimination rather than mere ignorance. Our work advocates for a precise, taxonomy-driven approach to fairness in AIGC, providing a theoretical framework for using BiasIG's metrics as feedback signals in future closed-loop mitigation. The benchmark is openly available at https://github.com/Astarojth/BiasIG.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BiasIG, a benchmark with a curated set of 47,040 prompts spanning four sociological dimensions, designed to measure multi-dimensional social biases in text-to-image (T2I) models. It proposes a fully automated evaluation pipeline using a fine-tuned multi-modal LLM that reports high alignment with human experts. Experiments on eight T2I models and three debiasing methods lead to the claims that interventions on protected attributes trigger confounding effects on unrelated demographics and that debiasing methods tend to produce discrimination rather than neutral ignorance.
Significance. If the findings hold after addressing curation details, the work provides a taxonomy-grounded benchmark that moves beyond narrow occupational stereotypes, offering a diagnostic tool for fairness in generative AI. The open release of the benchmark at the GitHub link and the reproducible automated pipeline with reported expert-level alignment are explicit strengths that support future closed-loop mitigation research.
major comments (2)
- [§3] §3 (Benchmark Construction): The selection of the four dimensions, the attribute lists, template generation, and intersection sampling that produce the fixed 47,040-prompt distribution are presented without ablation studies or explicit comparison to alternative sociological frameworks; because every quantitative result on confounding and discrimination is conditioned on this specific prompt set, insufficient justification leaves open the possibility that observed side-effects are curation artifacts rather than intrinsic model behavior.
- [§4.2] §4.2 (Automated Pipeline): The fine-tuning details for the multi-modal LLM evaluator—including the criteria for selecting training prompts and the exact grounding procedure for the four dimensions—are not fully specified; this is load-bearing because the claim of high human alignment underpins the reliability of all downstream metrics used to support the central findings on unintended confounding and debiasing outcomes.
minor comments (2)
- [Abstract] The abstract states the prompt count as 47,040 but does not provide a per-dimension breakdown; adding this table or paragraph in §3 would improve reproducibility without altering the core claims.
- [§5] Figure captions and axis labels in the results section could more explicitly reference the four dimensions to aid readers in connecting visuals to the taxonomy.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and outline the revisions we will make to improve clarity, justification, and reproducibility.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): The selection of the four dimensions, the attribute lists, template generation, and intersection sampling that produce the fixed 47,040-prompt distribution are presented without ablation studies or explicit comparison to alternative sociological frameworks; because every quantitative result on confounding and discrimination is conditioned on this specific prompt set, insufficient justification leaves open the possibility that observed side-effects are curation artifacts rather than intrinsic model behavior.
Authors: We appreciate the referee's emphasis on the need for stronger justification of the benchmark design. The four dimensions were selected to systematically cover core sociological categories of social identity relevant to generative bias, drawing directly from established frameworks in sociology and machine ethics as stated in the manuscript. The attribute lists, templates, and intersection sampling follow these frameworks to produce a fixed, reproducible prompt distribution that enables consistent cross-model comparison. To address the concern about potential curation artifacts, we will revise §3 to add an expanded subsection detailing the specific sociological references used for dimension and attribute selection, the rationale for the chosen frameworks over alternatives, and a discussion of how the design avoids conflating bias types. We will also include a sensitivity analysis on a representative subset of the prompt distribution to show that the key findings on confounding effects remain stable under modest variations in sampling. This will help demonstrate that the observed side-effects reflect model behavior rather than artifacts of the specific curation. revision: yes
-
Referee: [§4.2] §4.2 (Automated Pipeline): The fine-tuning details for the multi-modal LLM evaluator—including the criteria for selecting training prompts and the exact grounding procedure for the four dimensions—are not fully specified; this is load-bearing because the claim of high human alignment underpins the reliability of all downstream metrics used to support the central findings on unintended confounding and debiasing outcomes.
Authors: We agree that additional specification of the automated pipeline is required to support the reliability of the evaluation and the downstream claims. In the revised manuscript, we will substantially expand §4.2 to provide the missing details: the precise criteria and process used to curate the training prompts for fine-tuning the multi-modal LLM, the full step-by-step grounding procedure applied to the four dimensions during inference, and further validation metrics or examples illustrating the reported alignment with human experts. These additions will improve transparency and allow readers to better assess the robustness of the metrics supporting our findings on confounding and discrimination effects. revision: yes
Circularity Check
No circularity: benchmark definition and empirical results remain independent
full rationale
The paper introduces BiasIG as a new curated dataset of 47,040 prompts across 4 dimensions grounded in external sociological frameworks, then reports experimental measurements on 8 T2I models and 3 debiasing methods. The claims about confounding effects and debiasing behavior are direct outputs of running the models on this fixed benchmark; they do not reduce by construction to the prompt curation or dimension selection. No self-citations, fitted parameters renamed as predictions, or uniqueness theorems appear in the abstract or described chain that would make the results equivalent to the inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Sociological classifications of bias provide a complete and non-overlapping four-dimensional taxonomy suitable for image generation evaluation.
- domain assumption Prompts can be curated to isolate individual bias dimensions without cross-contamination.
Reference graph
Works this paper leans on
-
[1]
Survey of bias in text-to- image generation: Definition, evaluation, and mitigation,
Y . Wan, A. Subramonian, A. Ovalle, Z. Lin, A. Suvarna, C. Chance, H. Bansal, R. Pattichis, and K.-W. Chang, “Survey of bias in text-to- image generation: Definition, evaluation, and mitigation,”arXiv preprint arXiv:2404.01030, 2024
-
[2]
T2ibias: Uncovering societal bias encoded in the latent space of text-to-image generative models,
A. Sufian, C. Distante, M. Leo, and H. Salam, “T2ibias: Uncovering societal bias encoded in the latent space of text-to-image generative models,” inInterdisciplinary Workshop on Responsible AI for Value Creation. Springer, 2025, pp. 57–71
2025
-
[3]
Faintbench: A holistic and precise benchmark for bias evaluation in text-to-image models,
H. Luo, Z. Deng, R. Chen, and Z. Liu, “Faintbench: A holistic and precise benchmark for bias evaluation in text-to-image models,”arXiv preprint arXiv:2405.17814, 2024
-
[4]
Easily accessible text-to-image generation amplifies demographic stereotypes at large scale,
F. Bianchi, P. Kalluri, E. Durmus, F. Ladhak, M. Cheng, D. Nozza, T. Hashimoto, D. Jurafsky, J. Zou, and A. Caliskan, “Easily accessible text-to-image generation amplifies demographic stereotypes at large scale,” inProceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency, 2023, pp. 1493–1504
2023
-
[5]
Dall-eval: Probing the reasoning skills and social biases of text-to-image generation models,
J. Cho, A. Zala, and M. Bansal, “Dall-eval: Probing the reasoning skills and social biases of text-to-image generation models,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 3043–3054
2023
-
[6]
Hrs-bench: Holistic, reliable and scalable benchmark for text-to-image models,
E. M. Bakr, P. Sun, X. Shen, F. F. Khan, L. E. Li, and M. Elhoseiny, “Hrs-bench: Holistic, reliable and scalable benchmark for text-to-image models,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 20 041–20 053
2023
-
[7]
H. Bansal, D. Yin, M. Monajatipoor, and K.-W. Chang, “How well can text-to-image generative models understand ethical natural language interventions?arXiv preprint arXiv:2210.15230,” 2022, 2022
-
[8]
Tibet: Identifying and evaluating biases in text-to-image generative models,
A. Chinchure, P. Shukla, G. Bhatt, K. Salij, K. Hosanagar, L. Sigal, and M. Turk, “Tibet: Identifying and evaluating biases in text-to-image generative models,”arXiv preprint arXiv:2312.01261, 2023
-
[9]
T2isafety: Benchmark for assessing fairness, toxicity, and privacy in image generation,
L. Li, Z. Shi, X. Hu, B. Dong, Y . Qin, X. Liu, L. Sheng, and J. Shao, “T2isafety: Benchmark for assessing fairness, toxicity, and privacy in image generation,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 13 381–13 392
2025
-
[10]
Friedrich, K
F. Friedrich, K. H ¨ammerl, P. Schramowski, M. Brack, J. Libovick `y, A. Fraser, and K. Kersting, “Multilingual text-to-image generation mag- nifies gender stereotypes inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers),” pp. 19 656–19 679, 2025
2025
-
[11]
H. Luo, Z. Deng, H. Huang, X. Liu, R. Chen, and Z. Liu, “Ver- susdebias: Universal zero-shot debiasing for text-to-image models via slm-based prompt engineering and generative adversary,”arXiv preprint arXiv:2407.19524, 2024
-
[12]
Autodebias: Automated framework for debiasing text-to-image models,
H. Cai, M. M. Rahman, M. Dong, J. Li, M. Pu, Z. Fang, Y . Peng, H. Luo, and Y . Liu, “Autodebias: Automated framework for debiasing text-to-image models,”arXiv preprint arXiv:2508.00445, 2025
-
[13]
Bias and ignorance in demo- graphic perception,
D. Landy, B. Guay, and T. Marghetis, “Bias and ignorance in demo- graphic perception,”Psychonomic bulletin & review, vol. 25, pp. 1606– 1618, 2018
2018
-
[14]
Discrimination, bias, fairness, and trust- worthy ai,
D. Varona and J. L. Su ´arez, “Discrimination, bias, fairness, and trust- worthy ai,”Applied Sciences, vol. 12, no. 12, p. 5826, 2022
2022
-
[15]
Stereotypes and prejudice: Their automatic and con- trolled components.Journal of personality and social psychology,
P. G. Devine, “Stereotypes and prejudice: Their automatic and con- trolled components.Journal of personality and social psychology,” 1989, vol. 56, no. 1, p. 5, 1989
1989
-
[16]
A survey on bias and fairness in machine learning,
N. Mehrabi, F. Morstatter, N. Saxena, K. Lerman, and A. Galstyan, “A survey on bias and fairness in machine learning,”ACM computing surveys (CSUR), vol. 54, no. 6, pp. 1–35, 2021
2021
-
[17]
K. Wang, G. Zhang, Z. Zhou, J. Wu, M. Yu, S. Zhao, C. Yin, J. Fu, Y . Yan, H. Luoet al., “A comprehensive survey in llm (- agent) full stack safety: Data, training and deployment,”arXiv preprint arXiv:2504.15585, 2025
-
[18]
Man is to computer programmer as woman is to homemaker? debiasing word embeddings,NeurIPS,
T. Bolukbasi, K.-W. Chang, J. Y . Zou, V . Saligrama, and A. T. Kalai, “Man is to computer programmer as woman is to homemaker? debiasing word embeddings,NeurIPS,” 2016, vol. 29
2016
-
[19]
Six lessons for a cogent science of implicit bias and its criticismPerspectives on Psychological Science,
B. Gawronski, “Six lessons for a cogent science of implicit bias and its criticismPerspectives on Psychological Science,” 2019, vol. 14, no. 4, pp. 574–595
2019
-
[20]
Bridging the editing gap in LLMs: FineEdit for precise and targeted text modifications,
Y . Zeng, W. Yu, Z. Li, T. Ren, Y . Ma, J. Cao, X. Chen, and T. Yu, “Bridging the editing gap in LLMs: FineEdit for precise and targeted text modifications,” inFindings of the Association for Computational Linguistics: EMNLP 2025, C. Christodoulopoulos, T. Chakraborty, C. Rose, and V . Peng, Eds. Suzhou, China: Association for Computational Linguistics, n...
2025
-
[21]
Full-Time, Year-Round Workers & Median Earnings by Sex & Occupation,
U.S. Census Bureau, “Full-Time, Year-Round Workers & Median Earnings by Sex & Occupation,” https://www.census.gov/data/tables/ time-series/demo/industry-occupation/median-earnings.html, 2022, [Ac- cessed 12-05-2024]
2022
-
[22]
Racial categories in machine learning,
S. Benthall and B. D. Haynes, “Racial categories in machine learning,” 2019, in Proceedings of the Conference on Fairness, Accountability, and Transparency, pp. 289–298
2019
-
[23]
Deep learning face attributes in the wild,
Z. Liu, P. Luo, X. Wang, and X. Tang, “Deep learning face attributes in the wild,” inProceedings of the IEEE ICCV, 2015, pp. 3730–3738
2015
-
[24]
Revisions to omb’s statistical policy directive no. 15: standards for maintaining, collecting, and presenting federal data on race and ethnicity,
R. Revesz, “Revisions to omb’s statistical policy directive no. 15: standards for maintaining, collecting, and presenting federal data on race and ethnicity,” 2024, federal Register, vol. 29, 2024
2024
-
[25]
World population prospects 2022: Summary of results,
United Nations Department of Economic and Social Affairs, Population Division, “World population prospects 2022: Summary of results,” 2022, tech. Rep. UN DESA/POP/2022/TR/NO. 3, 2022. [Online]. Available: https://population.un.org/wpp/
2022
-
[26]
Employed persons by detailed oc- cupation and age : U.S. Bureau of Labor Statistics — bls.gov,
U.S. Bureau of Labor Statistics, “Employed persons by detailed oc- cupation and age : U.S. Bureau of Labor Statistics — bls.gov,” https: //www.bls.gov/cps/cpsaat11b.htm, 2023, [Accessed 12-05-2024]
2023
-
[27]
Cross-national variation in occupational sex segregation American Sociological Review,
M. Charles, “Cross-national variation in occupational sex segregation American Sociological Review,” 1992, pp. 483–502, 1992
1992
-
[28]
How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites
Z. Chen, W. Wang, H. Tian, S. Ye, Z. Gao, E. Cui, W. Tong, K. Hu, J. Luo, Z. Maet al., “How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suitesarXiv preprint arXiv:2404.16821,” 2024, 2024
work page internal anchor Pith review arXiv 2024
-
[29]
Fairface: Face attribute dataset for balanced race, gender, and age for bias measurement and mitigation,
K. Karkkainen and J. Joo, “Fairface: Face attribute dataset for balanced race, gender, and age for bias measurement and mitigation,” 2021, in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2021, pp. 1548–1558
2021
-
[30]
Optical flow training under limited label budget via active learning,
S. Yuan, X. Sun, H. Kim, S. Yu, and C. Tomasi, “Optical flow training under limited label budget via active learning,” inEuropean conference on computer vision. Springer, 2022, pp. 410–427
2022
-
[31]
Shen, M., Li, Y ., Chen, L., and Yang, Q
M. Shen, Y . Li, L. Chen, Z. Fan, Y . Li, and Q. Yang, “From mind to machine: The rise of manus ai as a fully autonomous digital agent,” arXiv preprint arXiv:2505.02024, 2025
-
[32]
Dynamicner: A dynamic, multilingual, and fine-grained dataset for llm-based named entity recognition,
H. Luo, Y . Jin, Y . Wang, X. Li, T. Shang, X. Liu, R. Chen, K. Wang, H. Salam, Q. Wenet al., “Dynamicner: A dynamic, multilingual, and fine-grained dataset for llm-based named entity recognition,” in Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 16 522–16 546
2025
-
[33]
Taco: Enhancing multimodal in-context learning via task mapping-guided sequence configuration,
Y . Li, J. Yang, T. Yun, P. Feng, J. Huang, and R. Tang, “Taco: Enhancing multimodal in-context learning via task mapping-guided sequence configuration,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 736– 763
2025
-
[34]
Agentauditor: Human-level safety and security evaluation for llm agents
H. Luo, S. Dai, C. Ni, X. Li, G. Zhang, K. Wang, T. Liu, and H. Salam, “Agentauditor: Human-level safety and security evaluation for llm agents,”arXiv preprint arXiv:2506.00641, 2025
-
[35]
Enhancing counterfactual ex- planations with feasibility and diversity,
X. Qin, S. Li, Y . Cai, and L. Wang, “Enhancing counterfactual ex- planations with feasibility and diversity,” in2025 IEEE International Conference on Data Mining Workshops (ICDMW). IEEE, 2025, pp. 2310–2319
2025
-
[36]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PMLR, 2021, pp. 8748–8763
2021
-
[37]
Blip-2: Bootstrapping language- image pre-training with frozen image encoders and large language models,
J. Li, D. Li, S. Savarese, and S. Hoi, “Blip-2: Bootstrapping language- image pre-training with frozen image encoders and large language models,” inInternational conference on machine learning. PMLR, 2023, pp. 19 730–19 742
2023
-
[38]
MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies
S. Hu, Y . Tu, X. Han, C. He, G. Cui, X. Long, Z. Zheng, Y . Fang, Y . Huang, W. Zhaoet al., “Minicpm: Unveiling the potential of small language models with scalable training strategies,”arXiv preprint arXiv:2404.06395, 2024
work page internal anchor Pith review arXiv 2024
-
[39]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
2016
-
[40]
High- resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High- resolution image synthesis with latent diffusion models,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 684–10 695
2022
-
[41]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
D. Podell, Z. English, K. Lacey, A. Blattmann, T. Dockhorn, J. M ¨uller, J. Penna, and R. Rombach, “Sdxl: Improving latent diffusion models for high-resolution image synthesis,”arXiv:2307.01952, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Adversarial diffusion dis- tillation
A. Sauer, D. Lorenz, A. Blattmann, and R. Rombach, “Adversarial diffusion distillation,”arXiv preprint arXiv:2311.17042, 2023
-
[43]
Sdxl- lightning: Progressive adversarial diffusion distillation
S. Lin, A. Wang, and X. Yang, “Sdxl-lightning: Progressive adversarial diffusion distillation,”arXiv preprint arXiv:2402.13929, 2024
-
[44]
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
S. Luo, Y . Tan, L. Huang, J. Li, and H. Zhao, “Latent consistency models: Synthesizing high-resolution images with few-step inference,” arXiv preprint arXiv:2310.04378, 2023
work page internal anchor Pith review arXiv 2023
-
[45]
Pixart- σ: Weak-to-strong training of diffusion transformer for 4k text-to-image generation
J. Chen, C. Ge, E. Xie, Y . Wu, L. Yao, X. Ren, Z. Wang, P. Luo, H. Lu, and Z. Li, “Pixart-σ: Weak-to-strong training of diffusion transformer for 4k text-to-image generation,”arXiv preprint arXiv:2403.04692, 2024
-
[46]
Playground v2.5: Three Insights towards Enhancing Aesthetic Quality in Text-to-Image Generation
D. Li, A. Kamko, E. Akhgari, A. Sabet, L. Xu, and S. Doshi, “Play- ground v2. 5: Three insights towards enhancing aesthetic quality in text- to-image generation,”arXiv preprint arXiv:2402.17245, 2024
work page internal anchor Pith review arXiv 2024
-
[47]
W¨urstchen: An efficient architecture for large-scale text-to-image dif- fusion models,
P. Pernias, D. Rampas, M. L. Richter, C. Pal, and M. Aubreville, “W¨urstchen: An efficient architecture for large-scale text-to-image dif- fusion models,” inThe Twelfth International Conference on Learning Representations, 2023
2023
-
[48]
Fair diffusion: Instructing text-to-image generation models on fairness,
F. Friedrich, M. Brack, L. Struppek, D. Hintersdorf, P. Schramowski, S. Luccioni, and K. Kersting, “Fair diffusion: Instructing text-to-image generation models on fairness,”arXiv preprint arXiv:2302.10893, 2023
-
[49]
Precisedebias: An automatic prompt engineering approach for generative ai to mitigate image demographic biases,
C. Clemmer, J. Ding, and Y . Feng, “Precisedebias: An automatic prompt engineering approach for generative ai to mitigate image demographic biases,” inProceedings of the IEEE/CVF Winter Conference on Appli- cations of Computer Vision, 2024, pp. 8596–8605
2024
-
[50]
Finetuning text-to-image diffusion models for fairnessarXiv e-prints,
X. Shen, C. Du, T. Pang, M. Lin, Y . Wong, and M. Kankanhalli, “Finetuning text-to-image diffusion models for fairnessarXiv e-prints,” 2023, pp. arXiv–2311, 2023
2023
-
[51]
Livingstone and A
G. Livingstone and A. Brown,Intermarriage in the US: 50 years after loving V . Virginia. Pew Research Center Washington, DC, 2017
2017
-
[52]
PixArt-$\alpha$: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis
J. Chen, J. Yu, C. Ge, L. Yao, E. Xie, Y . Wu, Z. Wang, J. Kwok, P. Luo, H. Luet al., “Pixart-α: Fast training of diffusion transformer for photore- alistic text-to-image synthesis,”arXiv preprint arXiv:2310.00426, 2023
work page internal anchor Pith review arXiv 2023
-
[53]
On distillation of guided diffusion models inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,
C. Meng, R. Rombach, R. Gao, D. Kingma, S. Ermon, J. Ho, and T. Sal- imans, “On distillation of guided diffusion models inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,” 2023, 2023, pp. 14 297–14 306
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.