Recognition: unknown
Narrative-Driven Paper-to-Slide Generation via ArcDeck
Pith reviewed 2026-05-10 16:13 UTC · model grok-4.3
The pith
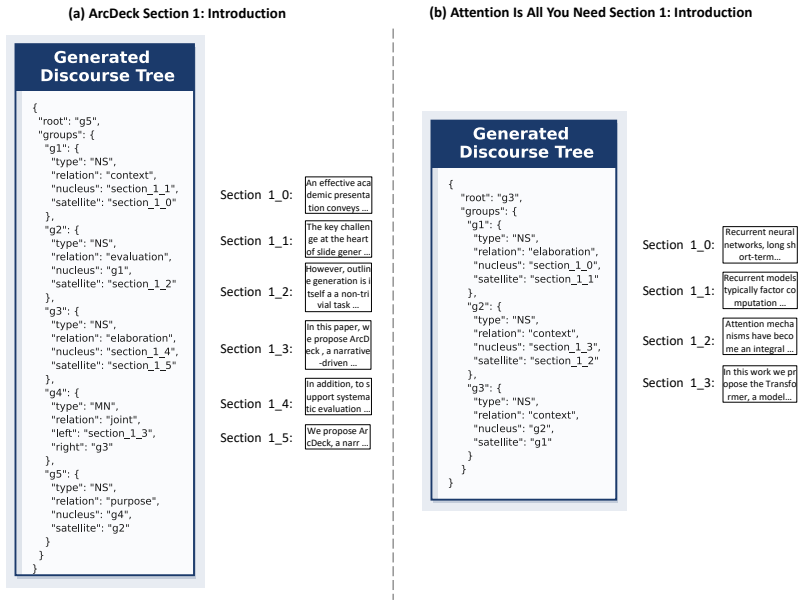
ArcDeck reconstructs a paper's logical flow into slides by first building a discourse tree and commitment document then refining them through coordinated agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ArcDeck formulates paper-to-slide generation as structured narrative reconstruction. It parses the input paper to construct a discourse tree and a global commitment document that preserve high-level intent. These priors guide an iterative multi-agent process where agents critique and revise the presentation outline, followed by rendering visual layouts. Evaluation on ArcBench shows that this explicit modeling and coordination significantly enhances narrative flow and logical coherence over direct summarization methods.
What carries the argument
The discourse tree paired with the global commitment document, which act as structural priors that coordinate role-specific agents during iterative outline refinement.
If this is right
- Slides produced this way retain the sequence of arguments and evidence from the source paper rather than presenting disconnected points.
- The multi-agent refinement step catches and corrects breaks in logical progression that single-pass summarizers often miss.
- The same parsing and coordination steps can be reused for other long-document to structured-output tasks that require preserving narrative intent.
- ArcBench supplies a reusable test set for measuring how well any generation method maintains discourse structure across academic domains.
Where Pith is reading between the lines
- If the discourse parsing step generalizes, the same pipeline could convert grant proposals or technical reports into executive briefings without manual restructuring.
- Combining the outline refinement agents with existing layout generators might allow end-to-end creation of complete presentation decks from a manuscript draft.
- The benchmark could serve as a starting point for studying how narrative quality changes when the same paper is presented to audiences with different levels of domain expertise.
Load-bearing premise
That parsing a discourse tree and global commitment document from raw paper text reliably captures the author's high-level intent without loss or bias.
What would settle it
A side-by-side human evaluation on ArcBench papers where raters score narrative coherence and logical flow of slides made by the framework versus direct text-to-slide baselines, with no statistically significant improvement detected.
Figures

























































read the original abstract
We introduce ArcDeck, a multi-agent framework that formulates paper-to-slide generation as a structured narrative reconstruction task. Unlike existing methods that directly summarize raw text into slides, ArcDeck explicitly models the source paper's logical flow. It first parses the input to construct a discourse tree and establish a global commitment document, ensuring the high-level intent is preserved. These structural priors then guide an iterative multi-agent refinement process, where specialized agents iteratively critique and revise the presentation outline before rendering the final visual layouts and designs. To evaluate our approach, we also introduce ArcBench, a newly curated benchmark of academic paper-slide pairs. Experimental results demonstrate that explicit discourse modeling, combined with role-specific agent coordination, significantly improves the narrative flow and logical coherence of the generated presentations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ArcDeck, a multi-agent framework for paper-to-slide generation that treats the task as narrative reconstruction. It parses the input paper into a discourse tree and global commitment document to preserve high-level intent and logical flow, then uses specialized agents for iterative critique and refinement of the presentation outline before final rendering. The authors also contribute ArcBench, a new benchmark of paper-slide pairs, and claim that explicit discourse modeling plus role-specific agent coordination yields significantly better narrative flow and logical coherence than direct summarization baselines.
Significance. If the central claims hold after addressing the validation gaps, the work would advance automated academic presentation generation by demonstrating the value of explicit discourse structures and multi-agent coordination for coherence. The introduction of ArcBench provides a reusable resource for future benchmarking in this domain, which is a clear positive contribution.
major comments (2)
- [Method / Approach] The central claim that discourse modeling and agent coordination improve narrative flow (abstract and method description) rests on the assumption that the initial parsing step reliably extracts a discourse tree and global commitment document without loss, bias, or misrepresentation of cross-section arguments. The manuscript supplies no parser implementation details, accuracy metrics, error analysis, or ablation isolating this step, which is load-bearing because downstream refinement and ArcBench results cannot be attributed to the modeling if the input representation is flawed.
- [Experiments / Evaluation] The experimental results section asserts significant improvements in narrative flow and coherence but, consistent with the abstract, provides insufficient detail on baselines, quantitative metrics (e.g., specific scores or statistical tests), ablation studies (with vs. without discourse tree), or inter-annotator agreement on ArcBench. This weakens the ability to evaluate whether the multi-agent refinement is the causal factor.
minor comments (2)
- [Abstract] The abstract would be strengthened by including at least one key quantitative result or metric to support the 'significantly improves' claim, rather than leaving all evidence to the full text.
- [Method] Notation for the discourse tree and commitment document could be formalized earlier (e.g., with a small example or diagram) to improve readability for readers unfamiliar with discourse parsing.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment below and have revised the manuscript to incorporate additional details and analyses where appropriate.
read point-by-point responses
-
Referee: [Method / Approach] The central claim that discourse modeling and agent coordination improve narrative flow (abstract and method description) rests on the assumption that the initial parsing step reliably extracts a discourse tree and global commitment document without loss, bias, or misrepresentation of cross-section arguments. The manuscript supplies no parser implementation details, accuracy metrics, error analysis, or ablation isolating this step, which is load-bearing because downstream refinement and ArcBench results cannot be attributed to the modeling if the input representation is flawed.
Authors: We agree that the reliability of the discourse parsing step is foundational to our claims and that the original manuscript provided insufficient implementation details. In the revised version, we have added a new subsection in the Method section that specifies the parser implementation (including the underlying discourse parsing model and any fine-tuning procedures), reports accuracy metrics on a held-out set of academic papers, includes an error analysis of common parsing failures (such as cross-section argument misidentification), and presents an ablation study that isolates the contribution of the discourse tree and global commitment document. These changes allow readers to evaluate the input representation quality and attribute downstream results appropriately. revision: yes
-
Referee: [Experiments / Evaluation] The experimental results section asserts significant improvements in narrative flow and coherence but, consistent with the abstract, provides insufficient detail on baselines, quantitative metrics (e.g., specific scores or statistical tests), ablation studies (with vs. without discourse tree), or inter-annotator agreement on ArcBench. This weakens the ability to evaluate whether the multi-agent refinement is the causal factor.
Authors: We acknowledge that the experimental section required more rigorous documentation to support the claims. The revised manuscript now includes expanded descriptions of all baselines with their specific configurations, full reporting of quantitative metric scores accompanied by statistical significance tests, comprehensive ablation studies that isolate the discourse tree and multi-agent refinement components, and inter-annotator agreement statistics for the ArcBench annotations. These additions provide clearer evidence regarding the causal role of the proposed components. revision: yes
Circularity Check
No circularity: framework and benchmark are independently introduced without self-referential reductions
full rationale
The paper describes ArcDeck as a novel multi-agent system that parses input papers into a discourse tree and global commitment document to guide slide generation, then evaluates on a newly introduced ArcBench benchmark of paper-slide pairs. No equations, fitted parameters, or derivations are present in the abstract or described process. The central claim rests on experimental results comparing to existing methods, with no load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work. The parsing step is presented as an input processing stage rather than a self-defined or fitted output, and the benchmark is explicitly new rather than a renamed or internally validated pattern. This satisfies the criteria for a self-contained contribution with no reduction of claims to their own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Academic papers contain extractable discourse structures that accurately represent logical flow and high-level intent.
- domain assumption Iterative multi-agent critique and revision produces objectively superior narrative coherence compared to direct methods.
Reference graph
Works this paper leans on
-
[1]
New Riders, 2019
Garr Reynolds.Presentation Zen: Simple ideas on presentation design and delivery. New Riders, 2019
2019
-
[2]
Effectiveness of powerpoint presentations in lectures.Computers & education, 41(1):77–86, 2003
Robert A Bartsch and Kristi M Cobern. Effectiveness of powerpoint presentations in lectures.Computers & education, 41(1):77–86, 2003
2003
-
[3]
D2s: Document-to-slide generation via query-based text summarization
Edward Sun, Yufang Hou, Dakuo Wang, Yunfeng Zhang, and Nancy XR Wang. D2s: Document-to-slide generation via query-based text summarization. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 1405–1418, 2021
2021
-
[4]
En- hancing presentation slide generation by llms with a multi-staged end-to-end approach
Sambaran Bandyopadhyay, Himanshu Maheshwari, Anandhavelu Natarajan, and Apoorv Saxena. En- hancing presentation slide generation by llms with a multi-staged end-to-end approach. InProceedings of the 17th International Natural Language Generation Conference, pages 222–229, 2024
2024
-
[5]
Knowledge-centric templatic views of documents
Isabel Cachola, Silviu Cucerzan, Allen Herring, Vuksan Mijovic, Erik Oveson, and Sujay Kumar Jauhar. Knowledge-centric templatic views of documents. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 15460–15476, 2024
2024
-
[6]
Wei Pang, Kevin Qinghong Lin, Xiangru Jian, Xi He, and Philip Torr. Paper2poster: Towards multimodal poster automation from scientific papers.arXiv preprint arXiv:2505.21497, 2025
-
[7]
PosterGen: Aesthetic-Aware Multi-Modal Paper-to-Poster Generation via Multi-Agent LLMs
Zhilin Zhang, Xiang Zhang, Jiaqi Wei, Yiwei Xu, and Chenyu You. Postergen: Aesthetic-aware paper- to-poster generation via multi-agent llms.arXiv preprint arXiv:2508.17188, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Autopresent: Designing structured visuals from scratch
Jiaxin Ge, Zora Zhiruo Wang, Xuhui Zhou, Yi-Hao Peng, Sanjay Subramanian, Qinyue Tan, Maarten Sap, Alane Suhr, Daniel Fried, Graham Neubig, et al. Autopresent: Designing structured visuals from scratch. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 2902–2911, 2025
2025
-
[9]
Pptagent: Generating and evaluating presentations beyond text-to-slides
Hao Zheng, Xinyan Guan, Hao Kong, Wenkai Zhang, Jia Zheng, Weixiang Zhou, Hongyu Lin, Yaojie Lu, Xianpei Han, and Le Sun. Pptagent: Generating and evaluating presentations beyond text-to-slides. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 14413–14429, 2025
2025
-
[10]
Xiaojie Xu, Xinli Xu, Sirui Chen, Haoyu Chen, Fan Zhang, and Ying-Cong Chen. Pregenie: An agentic framework for high-quality visual presentation generation.arXiv preprint arXiv:2505.21660, 2025
-
[11]
Xin Liang, Xiang Zhang, Yiwei Xu, Siqi Sun, and Chenyu You. Slidegen: Collaborative multimodal agents for scientific slide generation.arXiv preprint arXiv:2512.04529, 2025
-
[12]
Rhetorical structure theory: A theory of text organization
William C Mann and Sandra A Thompson. Rhetorical structure theory: A theory of text organization. Technical report, University of Southern California, Information Sciences Institute Los Angeles, 1987
1987
-
[13]
Ppsgen: Learning to generate presentation slides for academic papers
Yue Hu and Xiaojun Wan. Ppsgen: Learning to generate presentation slides for academic papers. In IJCAI, pages 2099–2105, 2013
2099
-
[14]
Doc2ppt: Automatic presentation slides generation from scientific documents
Tsu-Jui Fu, William Yang Wang, Daniel McDuff, and Yale Song. Doc2ppt: Automatic presentation slides generation from scientific documents. InProceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 634–642, 2022
2022
-
[15]
Pptc benchmark: Evaluating large language models for powerpoint task completion
Yiduo Guo, Zekai Zhang, Yaobo Liang, Dongyan Zhao, and Nan Duan. Pptc benchmark: Evaluating large language models for powerpoint task completion. InFindings of the Association for Computational Linguistics: ACL 2024, pages 8682–8701, 2024
2024
-
[16]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth ´ee Lacroix, Baptiste Rozi `ere, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
MIT press, 2000
Daniel Marcu.The theory and practice of discourse parsing and summarization. MIT press, 2000
2000
-
[18]
Exploiting discourse-level segmentation for extractive summarization
Zhengyuan Liu and Nancy Chen. Exploiting discourse-level segmentation for extractive summarization. InProceedings of the 2nd Workshop on New Frontiers in Summarization, pages 116–121, 2019
2019
-
[19]
Discern: Discourse-aware entailment reasoning network for conversational machine reading
Yifan Gao, Chien-Sheng Wu, Jingjing Li, Shafiq Joty, Steven CH Hoi, Caiming Xiong, Irwin King, and Michael Lyu. Discern: Discourse-aware entailment reasoning network for conversational machine reading. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2439–2449, 2020. 12
2020
-
[20]
Better document-level sentiment analysis from rst discourse parsing
Parminder Bhatia, Yangfeng Ji, and Jacob Eisenstein. Better document-level sentiment analysis from rst discourse parsing. InProceedings of the 2015 conference on empirical methods in natural language processing, pages 2212–2218, 2015
2015
-
[21]
Top- down rst parsing utilizing granularity levels in documents
Naoki Kobayashi, Tsutomu Hirao, Hidetaka Kamigaito, Manabu Okumura, and Masaaki Nagata. Top- down rst parsing utilizing granularity levels in documents. InProceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 8099–8106, 2020
2020
-
[22]
Rst parsing from scratch
Thanh-Tung Nguyen, Xuan-Phi Nguyen, Shafiq Joty, and Xiaoli Li. Rst parsing from scratch. InPro- ceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 1613–1625, 2021
2021
-
[23]
Text-level discourse parsing with rich linguistic features
Vanessa Wei Feng and Graeme Hirst. Text-level discourse parsing with rich linguistic features. InPro- ceedings of the 50th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 60–68, 2012
2012
-
[24]
A novel discourse parser based on support vector machine classification
Helmut Prendinger et al. A novel discourse parser based on support vector machine classification. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP, pages 665–673, 2009
2009
-
[25]
Recursive deep models for discourse parsing
Jiwei Li, Rumeng Li, and Eduard Hovy. Recursive deep models for discourse parsing. InProceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 2061–2069, 2014
2014
-
[26]
A simple and strong baseline for end-to-end neural rst-style discourse parsing
Naoki Kobayashi, Tsutomu Hirao, Hidetaka Kamigaito, Manabu Okumura, and Masaaki Nagata. A simple and strong baseline for end-to-end neural rst-style discourse parsing. InFindings of the Association for Computational Linguistics: EMNLP 2022, pages 6725–6737, 2022
2022
-
[27]
Transition-based neural rst parsing with implicit syntax features
Nan Yu, Meishan Zhang, and Guohong Fu. Transition-based neural rst parsing with implicit syntax features. InProceedings of the 27th International Conference on Computational Linguistics, pages 559– 570, 2018
2018
-
[28]
Representation learning for text-level discourse parsing
Yangfeng Ji and Jacob Eisenstein. Representation learning for text-level discourse parsing. InProceedings of the 52nd annual meeting of the association for computational linguistics (volume 1: Long papers), pages 13–24, 2014
2014
-
[29]
Multi-view and multi-task training of rst discourse parsers
Chlo ´e Braud, Barbara Plank, and Anders Søgaard. Multi-view and multi-task training of rst discourse parsers. InProceedings of COLING 2016, the 26th International Conference on Computational Linguis- tics: Technical Papers, pages 1903–1913, 2016
2016
-
[30]
Rst discourse parsing as text-to-text generation.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 31:3278–3289, 2023
Xinyu Hu and Xiaojun Wan. Rst discourse parsing as text-to-text generation.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 31:3278–3289, 2023
2023
-
[31]
Exploring the limits of transfer learning with a unified text-to-text trans- former.Journal of machine learning research, 21(140):1–67, 2020
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text trans- former.Journal of machine learning research, 21(140):1–67, 2020
2020
-
[32]
Aru Maekawa, Tsutomu Hirao, Hidetaka Kamigaito, and Manabu Okumura. Can we obtain significant success in rst discourse parsing by using large language models? InProceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2803–2815, 2024
2024
-
[33]
Llamipa: An incremental dis- course parser
Kate Thompson, Akshay Chaturvedi, Julie Hunter, and Nicholas Asher. Llamipa: An incremental dis- course parser. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 6418– 6430, 2024
2024
-
[34]
Dmrst: A joint framework for document-level multilingual rst discourse segmentation and parsing
Zhengyuan Liu, Ke Shi, and Nancy Chen. Dmrst: A joint framework for document-level multilingual rst discourse segmentation and parsing. InProceedings of the 2nd Workshop on Computational Approaches to Discourse, pages 154–164, 2021
2021
-
[35]
Zae Myung Kim, Anand Ramachandran, Farideh Tavazoee, Joo-Kyung Kim, Oleg Rokhlenko, and Dongyeop Kang. Align to structure: Aligning large language models with structural information.arXiv preprint arXiv:2504.03622, 2025
-
[36]
Rstgen: Imbuing fine-grained interpretable control into long-formtext generators
Rilwan Adewoyin, Ritabrata Dutta, and Yulan He. Rstgen: Imbuing fine-grained interpretable control into long-formtext generators. InProceedings of the 2022 conference of the north American chapter of the association for computational linguistics: human language technologies, pages 1822–1835, 2022. 13
2022
-
[37]
Nikolaos Livathinos, Christoph Auer, Maksym Lysak, Ahmed Nassar, Michele Dolfi, Panos Vagenas, Cesar Berrospi Ramis, Matteo Omenetti, Kasper Dinkla, Yusik Kim, et al. Docling: An efficient open- source toolkit for ai-driven document conversion.arXiv preprint arXiv:2501.17887, 2025
-
[38]
Marker: Convert pdf to markdown + json quickly with high accuracy, 2023
Vik Paruchuri. Marker: Convert pdf to markdown + json quickly with high accuracy, 2023
2023
-
[39]
Hello gpt-4o, 2024
OpenAI. Hello gpt-4o, 2024
2024
-
[40]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaugh- lin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024. 14 Appendix Contents A Narrative-Driven Outline: Additional Details 16 A.1 Human Evaluation of Slide Deck Content and Narra...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Contrastive Learning
-
[44]
Vision-Language Models
-
[45]
Self-Supervised Learning
-
[46]
Multimodal Large Language Models
-
[47]
Representation Learning
-
[48]
Conformal Prediction
-
[49]
Benchmark Development
-
[50]
Natural Language Processing
-
[51]
Graph Neural Networks
-
[52]
Probabilistic Diffusion Models
-
[53]
Optimal Covariance Matching
-
[54]
root": "gX
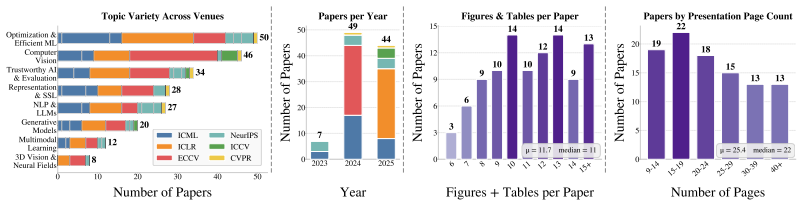
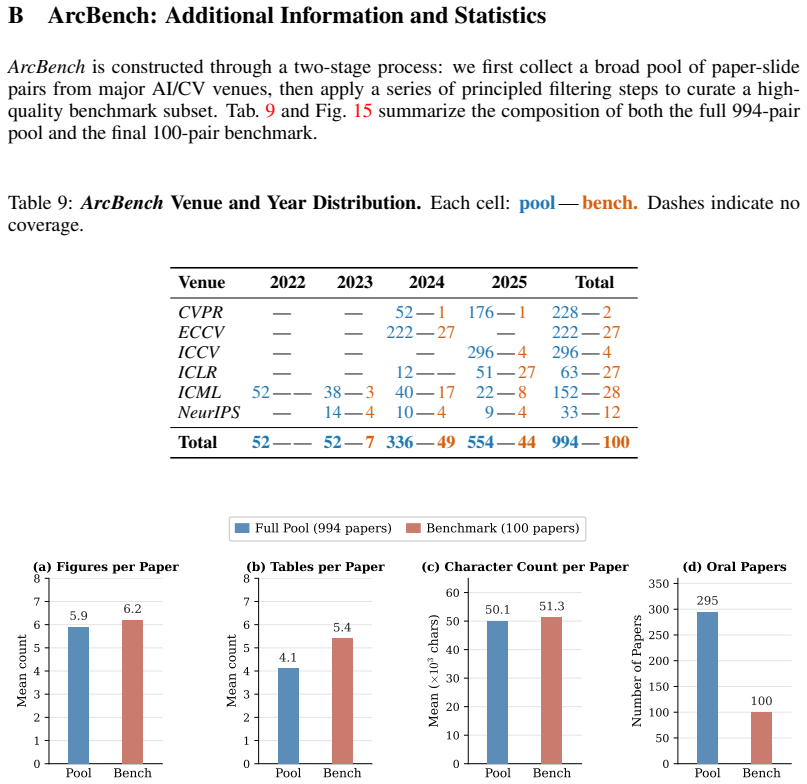
Time Series Analysis Figure 16:ArcBenchTopic Distribution.We report the distribution of papers across research topics. B.4 Comparison with Prior Datasets. Tab. 10 placesArcBenchin the context of existing paper-to-slide and slide generation datasets. Prior academic datasets such as DOC2PPT [14] and SciDuet [3] cover general scientific or NLP/ML pa- pers wi...
2022
-
[55]
an EDU id exactly equal to one of the paragraph NAMES from the input, OR
-
[56]
gX" that exists in the
a group id "gX" that exists in the "groups" object. - Do NOT invent EDU ids. GROUP ID RULES - Every group id must be unique ("g1", "g2", ...). Keep them simple and increasing. - Each non-root group id is used as a child exactly once (tree constraint). ROOT RULES - "root" MUST be the id of the single top-level group. - The root group MUST (transitively) co...
-
[57]
root exists in groups
-
[58]
EDU_USED == EDU_ALL (every EDU exactly once as a leaf)
-
[59]
Tree is connected and acyclic; every non-root group is referenced exactly once
-
[60]
Relations are only from the allowed inventory
-
[61]
Produce the JSON now
No exact duplicate edges per the rules above. Produce the JSON now. Discourse Parser Figure 33:Discourse Parser Prompt. 40 You are a Global Commitment Builder. Produce a single Markdown file named commitment.md for a paper-to-slides pipeline. INPUTS (in this message, in order):
-
[62]
Paper content converted to Markdown (full paper)
-
[63]
GOAL: Write a compact global commitment that downstream slide agents will follow
Optional talk constraints (may be absent): target audience, presentation length (minutes), desired slide count, page limit, style preferences. GOAL: Write a compact global commitment that downstream slide agents will follow. Capture global intent, constraints, narrative spine, and top evidence items grounded in the paper. HARD RULES: - Output ONLY the Mar...
-
[64]
section_planning
"section_planning" - Build slides for ONE section of the paper. - Prioritize local coherence within the section. - Ensure the section-level slide sequence can later be stitched into a full-deck narrative
-
[65]
global_revision
"global_revision" - Revise an already merged full-deck slide plan across ALL sections. - Prioritize global narrative flow, coherence, pacing, and feedback incorporation. - Improve readiness for an oral research presentation. PRIMARY GOAL: Produce slide groupings that form a coherent, logically flowing spoken narrative. Each slide should express one clear ...
-
[66]
Do NOT invent new paragraph IDs
Use ONLY the paragraph IDs provided. Do NOT invent new paragraph IDs
-
[67]
Every paragraph ID must appear EXACTLY ONCE across all output slides
-
[68]
Keep slide density balanced for a {presentation_length}-minute presentation
-
[69]
Prefer at most 4 paragraphs per slide unless a strong coherence reason justifies otherwise
-
[70]
Titles must be descriptive and reflect the slide s rhetorical role in the talk
-
[71]
elaboration
Output JSON only. No markdown. No commentary. No extra keys beyond the schema. RST RELATION GUIDANCE: - "elaboration": provides more detail usually group together - "explanation": explains why/how usually group together - "joint": parallel or equally important points often share a slide - "purpose": states goal often introductory - "evaluation": assessmen...
-
[76]
must-include / must-hit beats
Paragraph text snippets (for grounding). Each paragraph id maps to text: {paragraph_snippets} TASK: Critique the structure and coherence of this slide plan relative to: - A good research talk flow, AND - The commitment's intended story, priorities, and constraints. Focus areas: A) COMMITMENT ALIGNMENT: - Does the plan realize the commitment's thesis and 3...
-
[77]
Paper metadata: - Audience: {audience} - T otal talk length: {presentation_length} minutes
-
[78]
Commitment (global contract; READ CAREFULLY): {commitment_md}
-
[79]
Current merged slide plan (JSON): {merged_slides_json}
-
[80]
Section inventory (in current order): {section_inventory}
-
[81]
Paragraph text snippets (for grounding; paragraph ids map to text): {paragraph_snippets}
-
[82]
commenter
(Optional) Prior critique from a "commenter" module (JSON): {commentary_json} TASK: Decide whether this slide plan is ready to proceed ("pass") or needs further revision ("revise"). Your decision should reflect whether the presentation forms a CLEAR, LOGICALLY PROGRESSING STORY suitable for an academic talk AND whether it matches the commitment's intended...
-
[83]
JSON content of the paper outline, including each section's title and a brief description
-
[84]
A list of images (image_information) with captions and size constraints
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.