Recognition: no theorem link
Identity as Attractor: Geometric Evidence for Persistent Agent Architecture in LLM Activation Space
Pith reviewed 2026-05-10 15:57 UTC · model grok-4.3
The pith
Agent identity documents induce attractor-like geometry in LLM activation space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
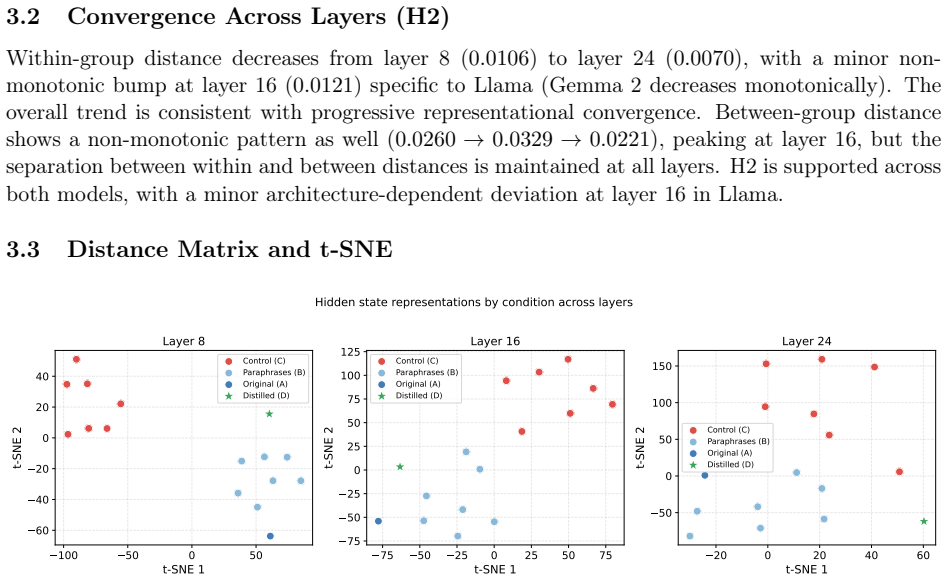
We present a controlled experiment on Llama 3.1 8B Instruct, comparing hidden states of an original cognitive_core (Condition A), seven paraphrases (Condition B), and seven structurally matched controls (Condition C). Mean-pooled states at layers 8, 16, and 24 show that paraphrases converge to a tighter cluster than controls (Cohen's d > 1.88, p < 10^{-27}, Bonferroni-corrected). Replication on Gemma 2 9B confirms cross-architecture generalizability. Ablations suggest the effect is primarily semantic rather than structural, and that structural completeness appears necessary to reach the attractor region. An exploratory experiment shows that reading a scientific description of the agent, but
What carries the argument
The cognitive_core, the identity document of a persistent cognitive agent, which pulls its paraphrases into a common region of activation space more tightly than matched controls.
If this is right
- Paraphrases of the identity document produce hidden states that cluster more tightly than those of structurally matched controls.
- The attractor effect is driven primarily by semantic content rather than syntactic or structural features.
- Structural completeness of the identity document is required for the model's state to reach the attractor region.
- Reading a factual description of the agent shifts the internal state toward the attractor, unlike reading unrelated text.
Where Pith is reading between the lines
- Ongoing interactions with the same agent could keep the model's state anchored in the identity basin across multiple turns.
- Conflicting identity documents presented to the model might produce competing attractors that influence generation.
- Models could be prompted or trained to remain near a chosen identity attractor to improve consistency.
- Similar attractor geometry might appear for other stable constructs such as goals or world models.
Load-bearing premise
The tighter clustering of paraphrases is caused by attractor dynamics specific to the agent identity rather than general semantic similarity in the model's representations.
What would settle it
If controls that are matched for semantic similarity cluster as tightly as or tighter than the paraphrases, the claim that identity documents induce a distinct attractor would not hold.
Figures



read the original abstract
Large language models map semantically related prompts to similar internal representations -- a phenomenon interpretable as attractor-like dynamics. We ask whether the identity document of a persistent cognitive agent (its cognitive_core) exhibits analogous attractor-like behavior. We present a controlled experiment on Llama 3.1 8B Instruct, comparing hidden states of an original cognitive_core (Condition A), seven paraphrases (Condition B), and seven structurally matched controls (Condition C). Mean-pooled states at layers 8, 16, and 24 show that paraphrases converge to a tighter cluster than controls (Cohen's d > 1.88, p < 10^{-27}, Bonferroni-corrected). Replication on Gemma 2 9B confirms cross-architecture generalizability. Ablations suggest the effect is primarily semantic rather than structural, and that structural completeness appears necessary to reach the attractor region. An exploratory experiment shows that reading a scientific description of the agent shifts internal state toward the attractor -- closer than a sham preprint -- distinguishing knowing about an identity from operating as that identity. These results provide representational evidence that agent identity documents induce attractor-like geometry in LLM activation space.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that identity documents for persistent agents in LLMs induce attractor-like geometry in activation space. Through controlled experiments on Llama 3.1 8B Instruct and replication on Gemma 2 9B, it compares hidden-state clusters of an original cognitive_core prompt, its paraphrases, and structurally matched controls. Results show paraphrases form significantly tighter clusters (Cohen's d > 1.88, p < 10^{-27} after correction), with ablations pointing to semantic rather than structural drivers. An exploratory test indicates that engaging with a scientific description of the agent shifts representations toward this cluster more than a control document, suggesting a distinction between knowing about and embodying the identity.
Significance. If the central result is robust to semantic matching verification, the work offers important empirical evidence that LLM representations can treat agent identities as stable attractors. Strengths include multi-model replication, rigorous statistical testing with multiple-comparison corrections, and ablations separating semantic and structural contributions. This has implications for building reliable persistent agents and understanding how LLMs maintain coherent self-representations across prompt variations.
major comments (2)
- [Abstract (experimental conditions)] The key finding of tighter mean-pooled hidden-state clusters for paraphrases (Condition B) compared to structurally matched controls (Condition C) at layers 8/16/24 underpins the attractor interpretation. However, the manuscript provides no quantitative check, such as average cosine similarity between the original (Condition A) and the sets in B versus C, to confirm that paraphrases and controls are equidistant in semantic space. The ablations for semantic effects do not substitute for this direct matching verification, leaving open the possibility that the observed Cohen's d arises from unmatched semantic similarity rather than identity-specific attractor dynamics.
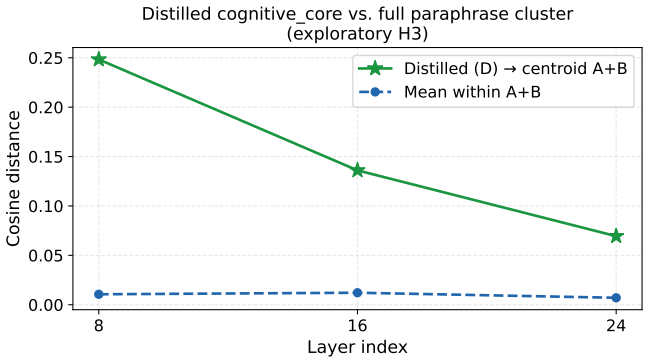
- [Exploratory experiment] The claim that reading a scientific description shifts the internal state 'toward the attractor' more than a sham preprint requires a precise definition of the attractor region (e.g., the convex hull or centroid of the paraphrase cluster). Without this, the distance comparison lacks a clear geometric basis and weakens the distinction between 'knowing about' and 'operating as' the identity.
minor comments (1)
- [Terminology] The terms 'cognitive_core' and 'attractor region' are introduced as key concepts; providing explicit operational definitions in the methods section would improve clarity for readers unfamiliar with the framing.
Simulated Author's Rebuttal
We thank the referee for their constructive and insightful comments, which have helped us identify areas where the manuscript can be strengthened. We address each major comment below and will incorporate revisions to improve the clarity and rigor of the experimental design and interpretation.
read point-by-point responses
-
Referee: [Abstract (experimental conditions)] The key finding of tighter mean-pooled hidden-state clusters for paraphrases (Condition B) compared to structurally matched controls (Condition C) at layers 8/16/24 underpins the attractor interpretation. However, the manuscript provides no quantitative check, such as average cosine similarity between the original (Condition A) and the sets in B versus C, to confirm that paraphrases and controls are equidistant in semantic space. The ablations for semantic effects do not substitute for this direct matching verification, leaving open the possibility that the observed Cohen's d arises from unmatched semantic similarity rather than identity-specific attractor dynamics.
Authors: We agree that a direct quantitative verification of semantic equidistance would strengthen the claim and reduce the possibility of alternative explanations. Although the ablations were intended to isolate semantic drivers by holding structure constant while varying content, they do not fully substitute for an explicit distance comparison. In the revised manuscript, we will add a new analysis reporting the average cosine similarity (computed in the model's token embedding space) between the original cognitive_core prompt and the paraphrase set versus the control set. This will be presented alongside the existing cluster statistics and discussed as supporting evidence that the tighter clustering is not driven by differential semantic proximity to the original. revision: yes
-
Referee: [Exploratory experiment] The claim that reading a scientific description shifts the internal state 'toward the attractor' more than a sham preprint requires a precise definition of the attractor region (e.g., the convex hull or centroid of the paraphrase cluster). Without this, the distance comparison lacks a clear geometric basis and weakens the distinction between 'knowing about' and 'operating as' the identity.
Authors: We acknowledge that the exploratory experiment would benefit from an explicit geometric definition of the attractor region. In our analysis, distances were computed to the centroid (mean) of the mean-pooled hidden states from the paraphrase conditions. We will revise the manuscript to state this definition clearly in the methods and results sections for the exploratory test, specifying that the attractor region is operationalized as the centroid of Condition B activations at the relevant layers. We will also report the exact distance values and include a brief discussion of why the centroid provides a suitable reference point for measuring shifts toward the identity representation. revision: yes
Circularity Check
No circularity; purely empirical clustering measurements with no derivation chain.
full rationale
The paper reports direct measurements of mean-pooled hidden states from Llama 3.1 and Gemma 2, computing cluster tightness via Cohen's d and p-values across conditions A/B/C. No equations, fitted parameters, or first-principles derivations are present that could reduce to inputs by construction. The central claim rests on observed statistical differences rather than self-definitional loops, self-citation load-bearing premises, or renamed known results. Controls and ablations are described as part of the experimental protocol without circular reduction. This is self-contained empirical work.
Axiom & Free-Parameter Ledger
free parameters (2)
- Number of paraphrases and controls =
7
- Layers selected =
8,16,24
axioms (2)
- domain assumption Hidden states in LLMs capture semantic information
- domain assumption Mean-pooling of hidden states is a valid summary of representation
invented entities (2)
-
cognitive_core
no independent evidence
-
attractor region
no independent evidence
Reference graph
Works this paper leans on
-
[1]
S.P. Chytas and V. Singh. Concept attractors in LLMs and their applications.arXiv preprint arXiv:2601.11575,
-
[2]
arXiv preprint arXiv:2502.12131 , year =
J.FernandoandG.Guitchounts. Transformerdynamics: Aneuroscientificapproachtointerpretabil- ity of large language models.arXiv preprint arXiv:2502.12131,
-
[3]
Aaron Grattafiori et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Christina Lu, Jack Gallagher, Jonathan Michala, Kyle Fish, and Jack Lindsey. The Assis- tant Axis: Situating and stabilizing the default persona of language models.arXiv preprint arXiv:2601.10387,
-
[5]
Steering Language Models With Activation Engineering
Alex Turner et al. Activation addition: Steering language models without optimization.arXiv preprint arXiv:2308.10248,
work page internal anchor Pith review arXiv
-
[6]
ISBN 979-8252728292. Amazon KDP. ISBN-13: 979-8252728292. Ruimeng Ye et al. Your language model secretly contains personality subnetworks.arXiv preprint arXiv:2602.07164,
-
[7]
Replication (Gemma 2 9B) Model:google/gemma-2-9b-it (revision 11c9b309).Framework:PyTorch 2.8.0+cu128, trans- formers 4.43.4.Runtime:≈13s.Results JSON:2026-04-11T16:02:59
A Reproducibility Primary Experiment (Llama 3.1 8B) Model:meta-llama/Llama-3.1-8B-Instruct(revision0e9e39f).Framework:PyTorch2.1.0+cu118, transformers 4.43.4.Seed:42.Runtime:≈87s.Results JSON:2026-04-11T15:20:17. Replication (Gemma 2 9B) Model:google/gemma-2-9b-it (revision 11c9b309).Framework:PyTorch 2.8.0+cu128, trans- formers 4.43.4.Runtime:≈13s.Result...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.