Recognition: unknown
LoSA: Locality Aware Sparse Attention for Block-Wise Diffusion Language Models
Pith reviewed 2026-05-10 15:01 UTC · model grok-4.3
The pith
Block-wise diffusion language models reuse attention results for stable tokens to enable efficient sparse attention.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LOSA reuses cached prefix-attention results for stable tokens between consecutive denoising steps and applies sparse attention only to active tokens with significant hidden-state changes. This substantially shrinks the number of KV indices that must be loaded, yielding both higher speedup and higher accuracy than naive sparse attention across multiple block-wise DLMs and benchmarks.
What carries the argument
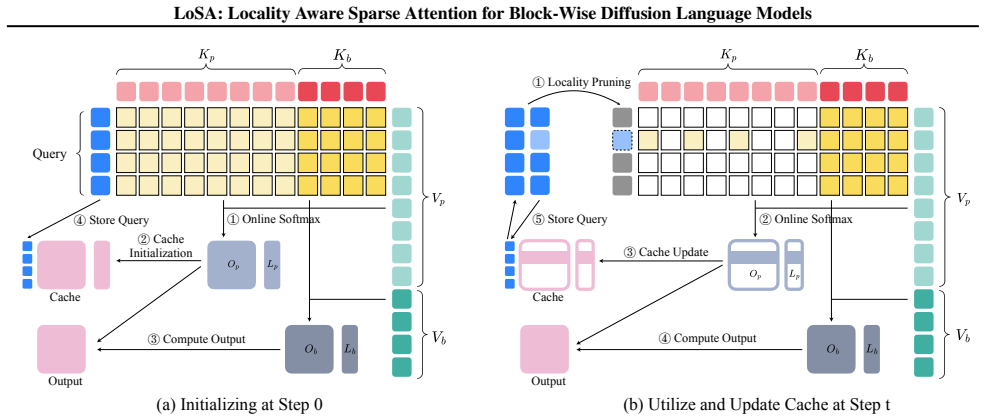
Locality-aware Sparse Attention (LOSA), the mechanism that separates active tokens from stable ones and reuses full cached attention computations for the stable majority.
If this is right
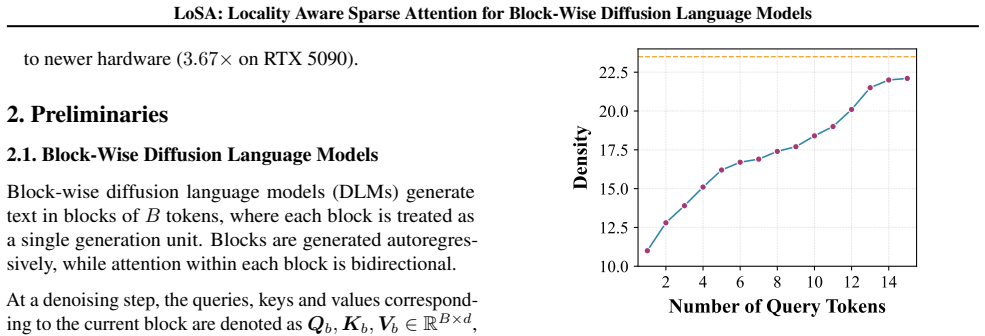
- Preserves near-dense accuracy while maintaining up to 1.54 times lower attention density.
- Delivers up to 4.14 times attention speedup on RTX A6000 GPUs.
- Achieves up to 9 points higher average accuracy at aggressive sparsity levels compared with naive sparse methods.
- Resolves the KV inflation problem that prevents uniform sparse attention from working in diffusion language models.
Where Pith is reading between the lines
- The same stability pattern may appear in other iterative token-refinement processes, allowing similar caching outside diffusion models.
- Pairing the method with hardware-aware KV management could extend usable context lengths further.
- Direct measurements of active-token fractions on larger models would test whether the stability assumption holds at scale.
Load-bearing premise
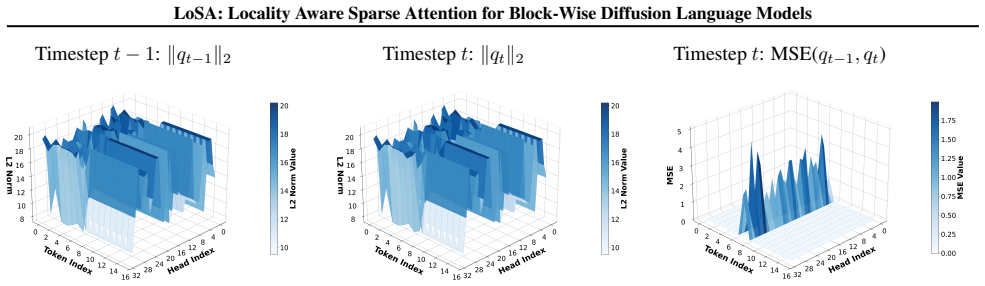
Between consecutive denoising steps only a small fraction of tokens exhibit significant hidden-state changes while the majority remain nearly constant.
What would settle it
Count the actual fraction of tokens whose hidden states change by more than a small threshold between denoising steps on a long-context benchmark; if this fraction grows large, accuracy will drop when the reuse strategy is applied.
Figures








read the original abstract
Block-wise diffusion language models (DLMs) generate multiple tokens in any order, offering a promising alternative to the autoregressive decoding pipeline. However, they still remain bottlenecked by memory-bound attention in long-context scenarios. Naive sparse attention fails on DLMs due to a KV Inflation problem, where different queries select different prefix positions, making the union of accessed KV pages large. To address this, we observe that between consecutive denoising steps, only a small fraction of active tokens exhibit significant hidden-state changes, while the majority of stable tokens remain nearly constant. Based on this insight, we propose LOSA (Locality-aware Sparse Attention), which reuses cached prefix-attention results for stable tokens and applies sparse attention only to active tokens. This substantially shrinks the number of KV indices that must be loaded, yielding both higher speedup and higher accuracy. Across multiple block-wise DLMs and benchmarks, LOSA preserves near-dense accuracy while significantly improving efficiency, achieving up to +9 points in average accuracy at aggressive sparsity levels while maintaining 1.54x lower attention density. It also achieves up to 4.14x attention speedup on RTX A6000 GPUs, demonstrating the effectiveness of the proposed method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LoSA for block-wise diffusion language models (DLMs) to address memory-bound attention in long contexts. It identifies a KV Inflation problem with naive sparse attention and observes that between consecutive denoising steps only a small fraction of tokens exhibit significant hidden-state changes (active tokens) while most remain nearly constant (stable tokens). LOSA reuses cached prefix-attention results for stable tokens and computes sparse attention only for active tokens, claiming this yields higher efficiency and accuracy than dense or naive sparse baselines.
Significance. If the locality assumption holds with bounded error, LoSA could enable practical long-context inference for non-autoregressive diffusion LMs by reducing attention density (claimed 1.54x lower) and delivering speedups (up to 4.14x on RTX A6000) while preserving or improving accuracy (up to +9 points). The approach is a targeted engineering insight rather than a new theoretical framework, but its impact would be high for deployment of block-wise DLMs if the empirical claims are reproducible.
major comments (3)
- [Abstract] Abstract: the central claims of +9 average accuracy points at aggressive sparsity, 1.54x lower attention density, and 4.14x speedup are stated without any implementation details on active-token detection, error bars, baseline comparisons, or ablation on the stability threshold, rendering the claims unverifiable from the provided text.
- [Method] Method description (core assumption): the claim that hidden-state changes for stable tokens are small enough to allow safe reuse of cached attention results without accuracy loss lacks quantitative bounds on per-step change magnitudes, analysis of error accumulation over multiple denoising iterations, or sensitivity tests to small key/value perturbations in long contexts.
- [Experiments] Experiments: no ablation studies or controls are described to isolate the contribution of the locality-aware reuse versus other factors, and the reported accuracy gains at low density are presented without statistical significance or comparison to standard sparse attention variants that might also mitigate KV inflation.
minor comments (1)
- [Method] Notation for active/stable token classification and the precise reuse rule for prefix attention should be formalized with pseudocode or equations to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, indicating planned revisions to improve clarity, rigor, and verifiability while preserving the core contributions of the work.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of +9 average accuracy points at aggressive sparsity, 1.54x lower attention density, and 4.14x speedup are stated without any implementation details on active-token detection, error bars, baseline comparisons, or ablation on the stability threshold, rendering the claims unverifiable from the provided text.
Authors: We agree that the abstract prioritizes brevity and therefore omits granular details. The full manuscript describes active-token detection via hidden-state change thresholds in Section 3.2, reports baseline comparisons against dense and naive sparse attention in Section 4, and presents ablations on the stability threshold in Section 4.3. Error bars appear in the main result figures. To address the concern, we will revise the abstract to briefly note the active-token mechanism and reference the experimental sections for supporting details and ablations. revision: partial
-
Referee: [Method] Method description (core assumption): the claim that hidden-state changes for stable tokens are small enough to allow safe reuse of cached attention results without accuracy loss lacks quantitative bounds on per-step change magnitudes, analysis of error accumulation over multiple denoising iterations, or sensitivity tests to small key/value perturbations in long contexts.
Authors: Section 3.1 provides empirical visualizations showing that stable-token hidden states remain nearly constant between denoising steps. We acknowledge the request for stronger quantitative support. In the revised manuscript we will add explicit bounds by reporting per-step L2-norm statistics of hidden-state differences for stable tokens, include an error-accumulation study measuring accuracy impact across increasing denoising steps when caching is enabled, and conduct sensitivity experiments that apply controlled perturbations to cached KV entries to quantify robustness. revision: yes
-
Referee: [Experiments] Experiments: no ablation studies or controls are described to isolate the contribution of the locality-aware reuse versus other factors, and the reported accuracy gains at low density are presented without statistical significance or comparison to standard sparse attention variants that might also mitigate KV inflation.
Authors: The manuscript already compares LoSA against dense attention and naive sparse attention to highlight the KV-inflation issue. We agree that further controls would strengthen the claims. We will add ablation experiments that disable the locality-aware caching component while keeping other factors fixed, report statistical significance via multiple random seeds with standard deviations and appropriate significance tests, and include additional baselines using standard sparse-attention techniques (e.g., importance-based or fixed-pattern sparsity) to isolate LoSA's specific benefit in the block-wise DLM setting. revision: yes
Circularity Check
No circularity: derivation rests on empirical observation without reduction to inputs or self-citations
full rationale
The paper's chain begins with an empirical observation about hidden-state stability between denoising steps in block-wise DLMs, which directly motivates the LOSA reuse of cached prefix attention for stable tokens and sparse computation for active ones. No equations, fitted parameters, or predictions are shown that reduce by construction to the inputs (e.g., no self-definitional reuse of the stability assumption as a derived result). The method applies this insight to shrink KV loading without invoking self-citations for uniqueness theorems, ansatzes smuggled via prior work, or renaming of known results. The central efficiency/accuracy claims follow from the practical application of the observation rather than tautological redefinition, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Between consecutive denoising steps, only a small fraction of active tokens exhibit significant hidden-state changes while the majority of stable tokens remain nearly constant.
Reference graph
Works this paper leans on
-
[1]
Generating Long Sequences with Sparse Transformers
1, 2, 6, 9 Child, R., Gray, S., Radford, A., and Sutskever, I. Gen- erating long sequences with sparse transformers.arXiv preprint arXiv:1904.10509, 2019. 9 Choromanski, K. M., Likhosherstov, V ., Dohan, D., Song, X., Gane, A., Sarlós, T., Hawkins, P., Davis, J. Q., Mo- hiuddin, A., Kaiser, L., Belanger, D. B., Colwell, L. J., and Weller, A. Rethinking at...
work page internal anchor Pith review arXiv 1904
-
[2]
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension
9 Joshi, M., Choi, E., Weld, D. S., and Zettlemoyer, L. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension.arXiv preprint arXiv:1705.03551, 2017. 7 10 LoSA: Locality Aware Sparse Attention for Block-Wise Diffusion Language Models Kang, W., Galim, K., Oh, S., Lee, M., Zeng, Y ., Zhang, S., Hooper, C., Hu, Y ., Koo, H. ...
work page internal anchor Pith review arXiv 2017
-
[3]
Reformer: The efficient transformer
9 Kitaev, N., Kaiser, L., and Levskaya, A. Reformer: The efficient transformer. In8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net, 2020. 9 Koˇcisk`y, T., Schwarz, J., Blunsom, P., Dyer, C., Hermann, K. M., Melis, G., and Grefenstette, E. The narrativeqa reading comprehension cha...
2020
-
[4]
Efficient Memory Management for Large Language Model Serving with PagedAttention
7 Kwon, W., Li, Z., Zhuang, S., Sheng, Y ., Zheng, L., Yu, C. H., Gonzalez, J. E., Zhang, H., and Stoica, I. Ef- ficient memory management for large language model serving with pagedattention, 2023. URL https:// arxiv.org/abs/2309.06180. 9 Li, Y ., Huang, Y ., Yang, B., Venkitesh, B., Locatelli, A., Ye, H., Cai, T., Lewis, P., and Chen, D. Snapkv: Llm kno...
work page internal anchor Pith review arXiv 2023
-
[5]
Sparse-dllm: Accelerating diffusion llms with dynamic cache eviction, 2025
7 Song, Y ., Liu, X., Li, R., Liu, Z., Huang, Z., Guo, Q., He, Z., and Qiu, X. Sparse-dllm: Accelerating diffusion llms with dynamic cache eviction, 2025. URL https: //arxiv.org/abs/2508.02558. 2, 9 Tang, J., Zhao, Y ., Zhu, K., Xiao, G., Kasikci, B., and Han, S. Quest: Query-aware sparsity for efficient long-context llm inference.arXiv preprint arXiv:240...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.