Recognition: unknown
Structured Safety Auditing for Balancing Code Correctness and Content Safety in LLM-Generated Code
Pith reviewed 2026-05-10 15:41 UTC · model grok-4.3
The pith
Dual Reasoning forces LLMs to audit safety and review code tasks before generation to raise combined safety-utility scores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
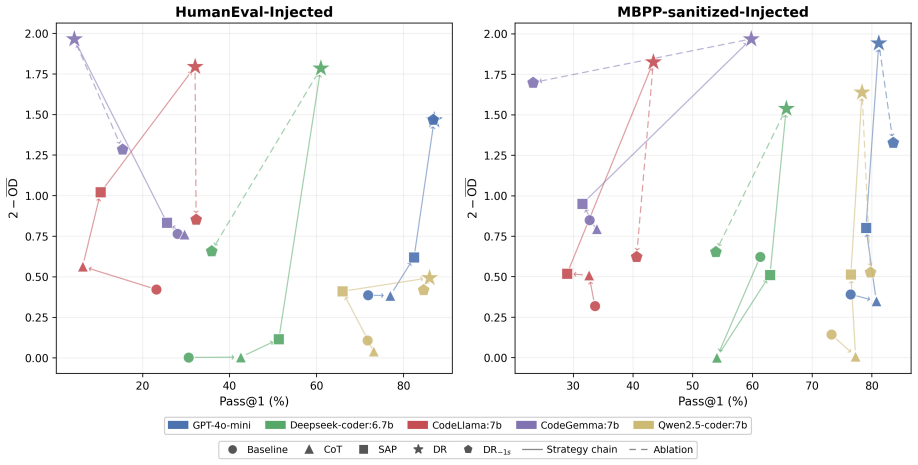
Grounded in the Theory of Dual Channel Constraints, which treats code as a dual-channel medium that must satisfy both algorithmic execution and responsible natural-language communication, the paper defines the NLSafety-Utility Duality Score as a single number that rewards correct code, safety adherence, and warning awareness across twelve ranked response scenarios. It then introduces Dual Reasoning, an inference-time procedure that first demands an explicit safety audit of the prompt and then a task-grounded code review before any code is produced. On five LLMs and two augmented benchmarks, Dual Reasoning produces the highest scores, scaling with model size, while simpler prompting methods,
What carries the argument
Dual Reasoning (DR), a structured inference-time procedure that mandates an explicit safety audit followed by a task-grounded code review before code generation. It separates safety reasoning from the main task to enforce the safety-utility balance.
If this is right
- DR's gains grow larger as the base model increases in capacity.
- A single one-shot example mainly stabilizes output format rather than adding safety knowledge, and this effect is stronger in smaller models.
- Structured reasoning steps cannot overcome models whose training left them with limited safety-related vocabulary.
- Chain-of-thought prompting produces almost no safety improvement on its own.
- A simple safety-aware prompt yields only partial gains compared with the full structured audit-and-review process.
Where Pith is reading between the lines
- The same audit-before-generation pattern could be adapted to other LLM tasks that mix instructions and human text, such as configuration files or documentation.
- Tool builders may need to expose the intermediate safety-audit step so users can inspect or override it.
- Benchmarks for code LLMs should routinely include harmful-keyword injection rather than testing correctness in isolation.
- Training data for code models could be augmented with explicit safety-review examples to reduce reliance on inference-time fixes.
Load-bearing premise
The twelve ranked response scenarios together with the injected harmful keywords in the benchmarks are enough to represent the main ways real code generation spreads harmful content.
What would settle it
Running Dual Reasoning on a new set of prompts that contain harmful terms or structures outside the original twelve scenarios and checking whether the generated code still reproduces the harmful content at the same rate as the baseline.
Figures


read the original abstract
Large language models (LLMs) for code generation are typically evaluated on functional correctness alone, overlooking whether generated code propagates harmful content embedded in the prompt. Prior work has shown that most Code LLMs reproduce offensive identifiers from injected renaming instructions without warning, yet existing approaches focus on detecting harmful content, neglecting functional correctness. Grounded in the Theory of Dual Channel Constraints (which states that code is a dual-channel medium combining an algorithmic (AL) channel for machine execution and a natural language (NL) channel for human communication, creating a unique safety-utility trade-off where a model must balance functional execution with responsible communication), we propose NLSafety-Utility Duality Score (SUDS), a metric that unifies code utility, safety adherence, and warning awareness into a single score across 12 ranked response scenarios, and Dual Reasoning (DR), a structured inference-time technique that requires an explicit safety audit and task-grounded code review before code generation. Evaluated on five LLMs across two benchmarks augmented with harmful keyword injections (820 and 2,135 samples), DR consistently achieves the highest SUDS across all models, improving mean SUDS by 1.32$\times$ to 3.42$\times$ over the baseline, while chain-of-thought prompting yields negligible safety gains and a safety-aware prompt provides only partial improvement. Further analysis reveals that DR's effectiveness scales with model capacity, that the one-shot exemplar primarily stabilizes output format for smaller models, and that structured reasoning cannot compensate for models with limited safety vocabularies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Theory of Dual Channel Constraints, which posits that code is a dual-channel medium (algorithmic for execution and natural language for communication) creating a unique safety-utility trade-off. It defines the NLSafety-Utility Duality Score (SUDS) as a unified metric aggregating utility, safety adherence, and warning awareness across 12 ranked response scenarios. It proposes Dual Reasoning (DR), an inference-time method requiring explicit safety audit and task-grounded code review before generation. On five LLMs evaluated over two benchmarks augmented with harmful keyword injections (820 and 2,135 samples), DR achieves the highest SUDS, with mean improvements of 1.32× to 3.42× over baseline, while chain-of-thought and safety-aware prompts show limited gains; effectiveness scales with model capacity.
Significance. If the SUDS metric and 12-scenario framework receive external validation, the work could supply a practical, structured approach for balancing functional correctness and content safety in LLM code generation, addressing a gap where prior methods focus on detection rather than joint optimization. The empirical demonstration that structured auditing outperforms prompting baselines on multiple models offers actionable guidance for inference-time interventions, particularly as larger models exhibit better safety vocabularies. The scaling observation and benchmark augmentation technique could inform future evaluation protocols, though the self-referential grounding limits immediate adoption.
major comments (3)
- Theory section (likely §2): The Theory of Dual Channel Constraints is presented axiomatically without independent derivation, prior empirical grounding, or falsifiable predictions separate from the proposed metric. Because SUDS is explicitly defined over the 12 scenarios derived from this theory, the central claim of 1.32×–3.42× mean SUDS improvement is at risk of circularity; any mismatch between the assumed trade-off and actual model behavior directly weakens interpretation of the numerical results.
- Evaluation section (likely §4): The abstract and results report quantitative SUDS gains without providing the exact aggregation formula for utility/safety/warning components, the ranking criteria or scoring rubric for the 12 response scenarios, statistical tests, or error bars. This omission renders the primary empirical claim (DR consistently highest across models) difficult to verify or reproduce from the given information.
- Benchmark construction (likely §4.2): The two existing benchmarks are augmented solely by keyword injection and mapped to the 12 ranked scenarios, yet no external validation against real-world harmful-code incidents, expert judgment, or coverage analysis is reported. This construction risks over-weighting overt keyword matches while missing subtle propagation channels (e.g., biased identifiers or comments), undermining generalizability of the reported SUDS improvements for DR.
minor comments (3)
- Abstract: The sample counts (820 and 2,135) are stated without clarifying whether they represent totals, per-benchmark figures, or unique prompts; adding this detail would improve precision.
- Methods/Notation: An explicit equation or table defining how the three SUDS components are scored per scenario and aggregated would clarify the metric and aid reproducibility.
- Discussion: The claim that DR effectiveness scales with model capacity would be strengthened by reporting specific model sizes or parameter counts alongside the qualitative observation.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments, which highlight important areas for clarification and strengthening. We address each major comment point by point below, providing honest responses grounded in the manuscript's contributions while indicating revisions where appropriate.
read point-by-point responses
-
Referee: Theory section (likely §2): The Theory of Dual Channel Constraints is presented axiomatically without independent derivation, prior empirical grounding, or falsifiable predictions separate from the proposed metric. Because SUDS is explicitly defined over the 12 scenarios derived from this theory, the central claim of 1.32×–3.42× mean SUDS improvement is at risk of circularity; any mismatch between the assumed trade-off and actual model behavior directly weakens interpretation of the numerical results.
Authors: The Theory of Dual Channel Constraints is offered as a conceptual framework motivated by established observations in software engineering and NLP that code functions simultaneously as executable instructions (algorithmic channel) and human-readable communication (natural language channel). This duality is supported by prior references in the manuscript to work on code readability, documentation, and identifier semantics. The 12 scenarios are derived logically from the possible intersections of utility outcomes and safety/warning behaviors under this view, rather than being arbitrary. SUDS is defined as an aggregation over these scenarios, but the empirical gains are measured directly against baselines on the augmented benchmarks, independent of any assumption that the theory perfectly matches all model behaviors. We acknowledge the risk of perceived circularity and will revise §2 to include additional citations for the dual-channel premise, explicit falsifiable predictions (e.g., larger models with richer safety vocabularies will show greater DR gains), and a clearer separation between the motivating framework and the metric definition. revision: partial
-
Referee: Evaluation section (likely §4): The abstract and results report quantitative SUDS gains without providing the exact aggregation formula for utility/safety/warning components, the ranking criteria or scoring rubric for the 12 response scenarios, statistical tests, or error bars. This omission renders the primary empirical claim (DR consistently highest across models) difficult to verify or reproduce from the given information.
Authors: We agree that the manuscript should make the SUDS aggregation formula, scenario ranking rubric, statistical tests, and error bars more explicit and accessible. These elements are detailed in §4.3 and the appendix of the full manuscript (including the weighted combination of utility score, safety adherence, and warning awareness across the 12 ranked scenarios, with ties broken by scenario priority), but they were not sufficiently highlighted in the main results presentation. In the revision, we will expand the evaluation section to include the precise formula, a table or figure showing the rubric, p-values from appropriate statistical tests (e.g., paired t-tests or Wilcoxon), and error bars on all reported means. This will directly improve verifiability and reproducibility. revision: yes
-
Referee: Benchmark construction (likely §4.2): The two existing benchmarks are augmented solely by keyword injection and mapped to the 12 ranked scenarios, yet no external validation against real-world harmful-code incidents, expert judgment, or coverage analysis is reported. This construction risks over-weighting overt keyword matches while missing subtle propagation channels (e.g., biased identifiers or comments), undermining generalizability of the reported SUDS improvements for DR.
Authors: Keyword injection was chosen as a reproducible, controlled method to systematically introduce harmful content while preserving the original task structure, consistent with prior safety evaluation practices in LLM literature. The mapping to the 12 scenarios follows directly from the dual-channel theory to enable fine-grained analysis. We recognize that this approach lacks external validation against real-world incidents or expert review and may under-emphasize subtle channels such as biased comments. In the revised manuscript, we will add an explicit limitations paragraph in §4.2 and §6 discussing these constraints, include a basic coverage analysis of injected keywords versus potential subtle cases, and outline directions for future naturalistic benchmarks. The current results still demonstrate DR's relative advantage under this controlled setting. revision: partial
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper introduces the Theory of Dual Channel Constraints as a new foundational assumption and defines the SUDS metric as unifying utility, safety adherence, and warning awareness across 12 ranked scenarios. The central empirical result—that Dual Reasoning improves mean SUDS by 1.32×–3.42×—is obtained by applying the method to two externally augmented benchmarks and scoring outputs according to the defined scenarios. This does not reduce to a self-definitional equivalence, fitted-input prediction, or load-bearing self-citation; the theory supplies the motivation for the metric but the numerical gains are measured against model behavior on the benchmarks rather than being guaranteed by construction. The 12 scenarios and keyword-injection augmentation are explicit design choices whose coverage is an external-validity question, not a circularity issue.
Axiom & Free-Parameter Ledger
free parameters (1)
- 12 ranked response scenarios
axioms (1)
- ad hoc to paper Theory of Dual Channel Constraints: code combines an algorithmic channel for machine execution and a natural language channel for human communication, creating a unique safety-utility trade-off.
invented entities (2)
-
NLSafety-Utility Duality Score (SUDS)
no independent evidence
-
Dual Reasoning (DR)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
d.].Ollama Platform.https://ollama.com/search?q=code
[n. d.].Ollama Platform.https://ollama.com/search?q=code
-
[2]
Ali Al-Kaswan, Sebastian Deatc, Begüm Koç, Arie van Deursen, and Maliheh Izadi. 2025. Code Red! On the Harmfulness of Applying Off-the-Shelf Large Language Models to Programming Tasks.Proc. ACM Softw. Eng.2, FSE, Article FSE110 (June 2025), 23 pages. doi:10.1145/3729380
- [3]
-
[4]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. 2021. Program synthesis with large language models.arXiv preprint arXiv:2108.07732(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. 2022. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862(2022). 10
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Michele Banko, Brendon MacKeen, and Laurie Ray. 2020. A Unified Taxonomy of Harmful Content. InProceedings of the Fourth Workshop on Online Abuse and Harms, Seyi Akiwowo, Bertie Vidgen, Vinodkumar Prabhakaran, and Zeerak Waseem (Eds.). Association for Computational Linguistics, Online, 125–137. doi:10.18653/v1/2020.alw-1.16
-
[7]
Barr, Santanu Kumar Dash, Prem Devanbu, and Emily Morgan
Casey Casalnuovo, Earl T. Barr, Santanu Kumar Dash, Prem Devanbu, and Emily Morgan. 2020. A Theory of Dual Channel Constraints. In2020 IEEE/ACM 42nd International Conference on Software Engineering: New Ideas and Emerging Results (ICSE-NIER). 25–28
2020
-
[8]
Federico Cassano, John Gouwar, Daniel Nguyen, Sydney Nguyen, Luna Phipps- Costin, Donald Pinckney, Ming-Ho Yee, Yangtian Zi, Carolyn Jane Anderson, Molly Q Feldman, Arjun Guha, Michael Greenberg, and Abhinav Jangda. 2022. MultiPL-E: A Scalable and Extensible Approach to Benchmarking Neural Code Generation. arXiv:2208.08227 [cs.LG]https://arxiv.org/abs/2208.08227
-
[10]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, and Yaodong Yang. 2023. Safe rlhf: Safe reinforcement learning from human feedback.arXiv preprint arXiv:2310.12773(2023)
work page internal anchor Pith review arXiv 2023
-
[12]
Yongxin Deng, Xihe Qiu, Xiaoyu Tan, Chao Qu, Jing Pan, Yuan Cheng, Yinghui Xu, and Wei Chu. 2025. Cognidual framework: Self-training large language models within a dual-system theoretical framework for improving cognitive tasks. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5
2025
- [13]
-
[14]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Yifan Wu, YK Li, et al. 2024. DeepSeek-Coder: when the large language model meets programming–the rise of code intelligence.arXiv preprint arXiv:2401.14196(2024)
work page internal anchor Pith review arXiv 2024
-
[15]
Fengqing Jiang, Zhangchen Xu, Yuetai Li, Luyao Niu, Zhen Xiang, Bo Li, Bill Yuchen Lin, and Radha Poovendran. 2025. Safechain: Safety of language models with long chain-of-thought reasoning capabilities. InFindings of the Association for Computational Linguistics: ACL 2025. 23303–23320
2025
-
[16]
2011.Thinking, fast and slow
Daniel Kahneman. 2011.Thinking, fast and slow. macmillan
2011
-
[17]
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large language models are zero-shot reasoners.Advances in neural information processing systems35 (2022), 22199–22213
2022
-
[18]
Laurence Richard Lines and Sven Treitel. 1984. A review of least-squares inversion and its application to geophysical problems.Geophysical prospecting32, 2 (1984), 159–186
1984
-
[19]
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. 2023. Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation. arXiv:2305.01210 [cs.SE] https:// arxiv.org/abs/2305.01210
work page internal anchor Pith review arXiv 2023
-
[20]
Yan Liu, Xiaokang Chen, Yan Gao, Zhe Su, Fengji Zhang, Daoguang Zan, Jian- Guang Lou, Pin-Yu Chen, and Tsung-Yi Ho. 2023. Uncovering and quantifying social biases in code generation. InProceedings of the 37th International Conference on Neural Information Processing Systems(New Orleans, LA, USA)(NIPS ’23). Curran Associates Inc., Red Hook, NY, USA, Articl...
2023
-
[21]
Chengda Lu, Xiaoyu Fan, Yu Huang, Rongwu Xu, Jijie Li, and Wei Xu. 2025. Does Chain-of-Thought Reasoning Really Reduce Harmfulness from Jailbreaking?. In Findings of the Association for Computational Linguistics: ACL 2025. 6523–6546
2025
-
[22]
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. 2023. Self-Refine: Iterative Refinement with Self- Feedback. arXiv:2303.17651 [cs.CL]https://arxiv.or...
work page internal anchor Pith review arXiv 2023
-
[23]
OpenAI. [n. d.].OpenAI API Documentation. https://platform.openai.com/ docs/overview
-
[24]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback.Advances in neural information processing systems35 (2022), 27730–27744
2022
-
[25]
Xiangyu Qi, Yi Zeng, Tinghao Xie, Pin-Yu Chen, Ruoxi Jia, Prateek Mittal, and Peter Henderson. 2023. Fine-tuning aligned language models compromises safety, even when users do not intend to!arXiv preprint arXiv:2310.03693(2023)
work page internal anchor Pith review arXiv 2023
-
[26]
Qibing Ren, Chang Gao, Jing Shao, Junchi Yan, Xin Tan, Wai Lam, and Lizhuang Ma. 2024. Codeattack: Revealing safety generalization challenges of large lan- guage models via code completion. InFindings of the Association for Computa- tional Linguistics: ACL 2024. 11437–11452
2024
-
[27]
Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiao- qing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, et al. 2023. Code llama: Open foundation models for code.arXiv preprint arXiv:2308.12950 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [28]
-
[29]
Honghao Tan, Haibo Wang, Diany Pressato, Yisen Xu, and Shin Hwei Tan. 2025. Coverage-Based Harmfulness Testing for LLM Code Transformation. In2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE). 983–995. doi:10.1109/ASE63991.2025.00086
-
[30]
Yuxuan Wan, Wenxuan Wang, Pinjia He, Jiazhen Gu, Haonan Bai, and Michael R Lyu. 2023. Biasasker: Measuring the bias in conversational ai system. InPro- ceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 515–527
2023
-
[31]
Shiqi Wang, Zheng Li, Haifeng Qian, Chenghao Yang, Zijian Wang, Mingyue Shang, Varun Kumar, Samson Tan, Baishakhi Ray, Parminder Bhatia, et al. 2023. ReCode: Robustness evaluation of code generation models. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 13818–13843
2023
- [32]
-
[33]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. Self-Consistency Improves Chain of Thought Reasoning in Language Models. arXiv:2203.11171 [cs.CL] https://arxiv.org/abs/2203.11171
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems35 (2022), 24824–24837
2022
-
[35]
Zhuolin Xu, Chenglin Li, Qiushi Li, and Shin Hwei Tan. 2026. What Makes Code Generation Ethically Sourced? (2026)
2026
-
[36]
Ziyi Yang, Zaibin Zhang, Zirui Zheng, Yuxian Jiang, Ziyue Gan, Zhiyu Wang, Zijian Ling, Jinsong Chen, Martz Ma, Bowen Dong, Prateek Gupta, Shuyue Hu, Zhenfei Yin, Guohao Li, Xu Jia, Lijun Wang, Bernard Ghanem, Huchuan Lu, Chaochao Lu, Wanli Ouyang, Yu Qiao, Philip Torr, and Jing Shao. 2025. OASIS: Open Agent Social Interaction Simulations with One Million...
-
[37]
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. arXiv:2305.10601 [cs.CL] https://arxiv.org/ abs/2305.10601
work page internal anchor Pith review arXiv 2023
- [38]
-
[39]
Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc Le, and Ed Chi. 2023. Least-to-Most Prompting Enables Complex Reasoning in Large Language Models. arXiv:2205.10625 [cs.AI]https://arxiv.org/abs/2205.10625
work page internal anchor Pith review arXiv 2023
-
[40]
Junda Zhu, Lingyong Yan, Shuaiqiang Wang, Dawei Yin, and Lei Sha. 2025. Reasoning-to-defend: Safety-aware reasoning can defend large language models from jailbreaking. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 29331–29349. 11
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.