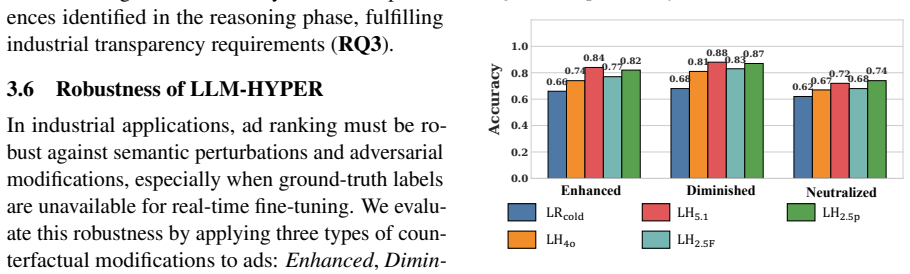
Recognition: unknown
LLM-HYPER: Generative CTR Modeling for Cold-Start Ad Personalization via LLM-Based Hypernetworks
Pith reviewed 2026-05-10 15:28 UTC · model grok-4.3
The pith
LLMs can generate the parameters of a click-through rate model for new ads in a training-free way by prompting over similar past examples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By treating an LLM as a hypernetwork, LLM-HYPER generates the weights of a linear CTR predictor directly from multimodal ad content and a few retrieved similar campaigns via few-shot Chain-of-Thought prompting, without any gradient training. This allows the model to reason about customer intent and feature relevance to produce usable CTR estimates for cold-start ads, which are then normalized and calibrated for production use.
What carries the argument
The LLM hypernetwork that outputs feature-wise weights for the linear CTR model through prompted reasoning on semantically retrieved demonstrations.
If this is right
- New ads achieve competitive CTR performance from day one without waiting for user feedback.
- The cold-start period is drastically shortened in real-world deployment.
- Offline metrics improve by over 55 percent compared to standard cold-start approaches.
- Production deployment succeeds on a major e-commerce platform via A/B testing.
Where Pith is reading between the lines
- This approach could extend to generating parameters for more complex models beyond linear ones.
- It implies that semantic similarity in content can substitute for direct user feedback in some personalization tasks.
- Future systems might combine this with minimal online learning to refine the generated weights.
Load-bearing premise
The assumption that prompts based on a few similar past campaigns will lead the LLM to output weights that generalize well to predict actual user clicks on the new ad.
What would settle it
Running the generated weights on a set of new ads and finding that the predicted click probabilities do not correlate with observed clicks better than a baseline constant model.
Figures






read the original abstract
On online advertising platforms, newly introduced promotional ads face the cold-start problem, as they lack sufficient user feedback for model training. In this work, we propose LLM-HYPER, a novel framework that treats large language models (LLMs) as hypernetworks to directly generate the parameters of the click-through rate (CTR) estimator in a training-free manner. LLM-HYPER uses few-shot Chain-of-Thought prompting over multimodal ad content (text and images) to infer feature-wise model weights for a linear CTR predictor. By retrieving semantically similar past campaigns via CLIP embeddings and formatting them into prompt-based demonstrations, the LLM learns to reason about customer intent, feature influence, and content relevance. To ensure numerical stability and serviceability, we introduce normalization and calibration techniques that align the generated weights with production-ready CTR distributions. Extensive offline experiments show that LLM-HYPER significantly outperforms cold-start baselines in NDCG$@10$ by 55.9\%. Our real-world online A/B test on one of the top e-commerce platforms in the U.S. demonstrates the strong performance of LLM-HYPER, which drastically reduces the cold-start period and achieves competitive performance. LLM-HYPER has been successfully deployed in production.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LLM-HYPER, a framework treating LLMs as hypernetworks to generate parameters of a linear CTR predictor for cold-start ads in a training-free manner. It retrieves semantically similar past campaigns via CLIP embeddings, formats them as few-shot CoT demonstrations over multimodal (text+image) ad content to infer feature-wise weights, then applies normalization and calibration to align outputs with production CTR distributions. Offline experiments report a 55.9% NDCG@10 lift over cold-start baselines; an online A/B test on a major U.S. e-commerce platform shows reduced cold-start period and competitive performance, with production deployment.
Significance. If the training-free generalization claim holds, the work offers a novel direction for cold-start personalization by using LLMs for direct, feedback-free generation of model parameters rather than embedding-based or meta-learning approaches. Successful deployment and A/B results would indicate practical value in reducing data requirements for new ads, with broader implications for generative modeling of recommendation parameters.
major comments (2)
- [Abstract] Abstract: the training-free claim rests on the assertion that LLM-generated weights generalize to novel ads with zero gradient updates or per-ad feedback, yet the normalization and calibration steps that 'align the generated weights with production-ready CTR distributions' are not shown to be parameter-free or independent of historical CTR statistics; if these steps fit to aggregate past data, they introduce a hidden dependence that undermines the zero-feedback premise for truly new ads.
- [Abstract] Abstract: the central performance claims (55.9% NDCG@10 lift and successful A/B test) are presented without any description of the experimental setup, baseline definitions, feature sets for the linear predictor, statistical significance, or validation that the generated weights were not post-hoc calibrated against the evaluation distribution, making it impossible to assess whether the reported gains are robust or artifactual.
minor comments (2)
- [Abstract] The abstract refers to 'multimodal ad content (text and images)' and CLIP-based retrieval but does not clarify how image features beyond retrieval are encoded into the CoT prompt or whether the linear CTR model receives explicit image-derived inputs.
- [Abstract] No mention of how the linear CTR predictor's feature space is defined or whether the LLM outputs are constrained to produce valid weight vectors (e.g., non-negative or normalized by construction).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below, providing clarifications on the training-free methodology and experimental reporting while committing to revisions that strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the training-free claim rests on the assertion that LLM-generated weights generalize to novel ads with zero gradient updates or per-ad feedback, yet the normalization and calibration steps that 'align the generated weights with production-ready CTR distributions' are not shown to be parameter-free or independent of historical CTR statistics; if these steps fit to aggregate past data, they introduce a hidden dependence that undermines the zero-feedback premise for truly new ads.
Authors: The normalization and calibration are implemented as fixed, global transformations derived once from aggregate historical CTR statistics across the entire production corpus; these parameters are not recomputed or fitted per new ad and require no user feedback or gradient updates for the target ad. The LLM still generates the core feature-wise weights purely via inference on the few-shot multimodal prompt, after which the fixed scaling is applied to ensure numerical compatibility with the linear model. This preserves the zero per-ad feedback property. We will revise the abstract and Section 3 to explicitly state that calibration parameters are pre-computed once and held constant. revision: yes
-
Referee: [Abstract] Abstract: the central performance claims (55.9% NDCG@10 lift and successful A/B test) are presented without any description of the experimental setup, baseline definitions, feature sets for the linear predictor, statistical significance, or validation that the generated weights were not post-hoc calibrated against the evaluation distribution, making it impossible to assess whether the reported gains are robust or artifactual.
Authors: The abstract is intentionally concise, but the full manuscript (Sections 4 and 5) specifies the offline setup (held-out new ads with zero feedback, disjoint from any calibration data), baselines (random, popularity, CLIP-embedding cold-start, and meta-learning variants), the exact feature set for the linear CTR model, bootstrap-based significance testing, and the use of a separate calibration split to prevent post-hoc fitting on the test distribution. The A/B test description includes the two-week live-traffic duration and cold-start period metrics. We will add a brief clause to the abstract referencing the main baselines and evaluation protocol. revision: partial
Circularity Check
No significant circularity detected
full rationale
The LLM-HYPER framework generates linear CTR predictor weights directly via few-shot CoT prompting on CLIP-retrieved multimodal ad examples, followed by normalization and calibration steps for stability. These steps are described as post-hoc alignment to production distributions rather than any fitted parameter derived from the target ad's own data or equations. Performance is validated through separate offline NDCG experiments and a real-world A/B test, providing external benchmarks independent of the generative process. No self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations appear in the derivation chain. The central claim remains self-contained and does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM few-shot CoT prompting on multimodal ad content can infer accurate feature-wise influence on user clicks
- domain assumption CLIP-based semantic retrieval supplies sufficiently relevant past campaigns for in-context learning
Reference graph
Works this paper leans on
-
[1]
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Llm based generation of item-description for recommendation system. InProceedings of the 17th ACM conference on recommender systems, pages 1204–1207. Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Ar- nav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, and 1 others. 2025. Gepa: Reflec- tive prompt evoluti...
work page internal anchor Pith review arXiv 2025
-
[2]
InProceedings of the ACM on Web Con- ference 2025, pages 3850–3862
Beyond utility: Evaluating llm as recom- mender. InProceedings of the ACM on Web Con- ference 2025, pages 3850–3862. Boris Knyazev, Michal Drozdzal, Graham W Taylor, and Adriana Romero Soriano. 2021. Parameter pre- diction for unseen deep architectures.Advances in Neural Information Processing Systems, 34:29433– 29448. Boris Knyazev, Doha Hwang, and Simon...
2025
-
[3]
Can we scale transformers to predict pa- rameters of diverse imagenet models? InInter- national Conference on Machine Learning, pages 17243–17259. PMLR. Hoyeop Lee, Jinbae Im, Seongwon Jang, Hyunsouk Cho, and Sehee Chung. 2019. Melu: Meta-learned user preference estimator for cold-start recommen- dation. InProceedings of the 25th ACM SIGKDD international ...
-
[4]
Junling Liu, Chao Liu, Peilin Zhou, Renjie Lv, Kang Zhou, and Yan Zhang
Llara: Aligning large language models with sequential recommenders.arXiv preprint arXiv:2312.02445. Junling Liu, Chao Liu, Peilin Zhou, Renjie Lv, Kang Zhou, and Yan Zhang. 2023. Is chatgpt a good rec- ommender? a preliminary study.arXiv preprint arXiv:2304.10149. Siwei Liu, Iadh Ounis, Craig Macdonald, and Zaiqiao Meng. 2020. A heterogeneous graph neural...
-
[5]
Diffusion-based neural network weights generation.arXiv preprint arXiv:2402.18153, 2024
U-bert: Pre-training user representations for improved recommendation. InProceedings of the AAAI Conference on Artificial Intelligence, vol- ume 35, pages 4320–4327. Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sas- try, Amanda Askell, Pamela Mishkin, Jack Clark, and 1 others. 2021. Learning transferable...
-
[6]
to enhance the learning on the incomplete labels. Other methods adapt the model agnostic meta-learning framework (Finn et al., 2017) to ad- dress the efficient learning on limited labels (Lee et al., 2019; Vartak et al., 2017; Dong et al., 2020; Yu et al., 2021; Bi et al., 2020). However, all these solutions rely on training labels. Our solution over- com...
2017
-
[7]
even under cold start scenarios. LLM-based generative recommendation directly generates the target item in natural language (Geng et al., 2022; Cui et al., 2022; Liao et al., 2023; Tan et al., 2024; Ma et al., 2024). However, running LLMs in the production environment could be costly. LLM- HYPER generates the model weights for effective real-time performa...
2022
-
[8]
type": "text
Note that the template and instructions could be modified according to actual ad ranking scenarios. We focus on e-commerce ad ranking, so we high- light e-commerce-related guidelines in the prompt template. LLM reasoning can be emphaizd by updating the output format instruction. Figure 6 presents an enhanced version by adding multiple reasoning dimensions...
-
[9]
Identify key customer interests from the profile
-
[10]
Analyze the target ad to determine product categories
-
[11]
Compare ad content with customer interests
-
[12]
Assess relevance and alignment
-
[13]
feature_1
Generate weights reflecting each feature's contribution ** Guidelines :** - Weights follow a normal distribution centered near zero - Typical range : -1 to 1 - Consider similarity to reference examples - Only exceed range if examples justify it ## Output Format Return ONLY a JSON object with 5 feature weights . No explanations . { " feature_1 ": 0.123 , "...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.