Recognition: unknown
Automated BPMN Model Generation from Textual Process Descriptions: A Multi-Stage LLM-Driven Approach
Pith reviewed 2026-05-10 15:35 UTC · model grok-4.3
The pith
A multi-stage LLM pipeline generates valid BPMN models from text with average similarity above 0.75.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
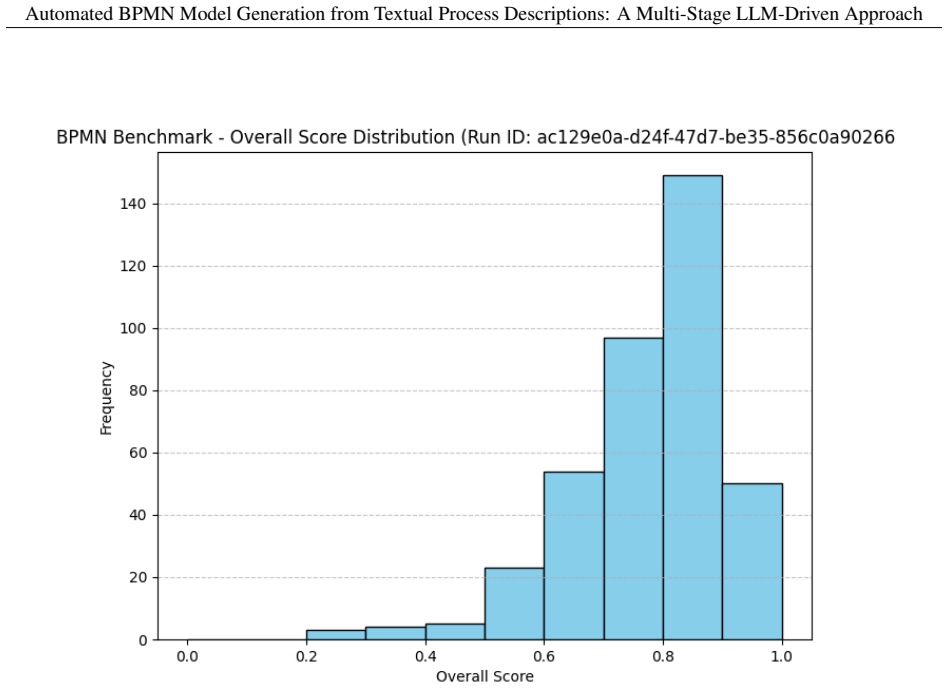
The multi-stage pipeline automates both the creation of a validated ground-truth corpus from 750 public BPMN diagrams, yielding 387 models, and the reconstruction of executable BPMN 2.0 XML from generated process descriptions, achieving an average reconstruction similarity above 0.75 with about 50 near-perfect matches.
What carries the argument
The multi-stage LLM-driven pipeline that automates ground-truth construction via translation, SpiffWorkflow validation, and LLM repairs, then performs description generation and model reconstruction for evaluation.
If this is right
- LLMs can generate structurally compliant and semantically meaningful BPMN diagrams at scale.
- The pipeline eliminates manual curation when building training data for text-to-model tasks.
- Multilingual process sources can be standardized to English for consistent reconstruction.
- A multi-dimensional similarity framework can reliably measure how well generated models match ground truth.
Where Pith is reading between the lines
- Organizations might convert employee-written process notes directly into executable diagrams without dedicated modelers.
- The approach could extend to proprietary internal workflows once ground-truth validation is adapted.
- Pairing the pipeline with voice-to-text tools might enable fully automated capture of processes from spoken descriptions.
Load-bearing premise
The combination of SpiffWorkflow execution checks and targeted LLM repairs produces a ground-truth corpus free of systematic semantic errors or biases introduced by the LLM itself.
What would settle it
Applying the full pipeline to a new independent collection of public BPMN diagrams and obtaining an average reconstruction similarity well below 0.75, or finding repeated semantic mismatches during manual inspection of the validated ground-truth models.
Figures


read the original abstract
Automatically reconstructing BPMN models from unstructured natural-language descriptions remains challenging due to heterogeneous modeling conventions, multilingual sources, and the lack of reliable ground truth. We present a scalable, multi-stage LLM-driven pipeline that automates both ground-truth construction and model reconstruction. Multilingual BPMN XML files are translated into English, validated using execution-oriented compliance checks in SpiffWorkflow, and iteratively repaired through targeted LLM-guided corrections to produce a consistent ground-truth corpus. From these validated models, process descriptions are generated and used to reconstruct executable BPMN~2.0 XML diagrams without manual curation. We introduce a multi-dimensional similarity framework combining structural metrics, type-distribution alignment, and embedding-based semantic measures. In an empirical study of 750 public BPMN diagrams, the pipeline generated 387 validated ground-truth models and achieved average reconstruction similarity above 0.75, including approximately 50 near-perfect reconstructions differing only in minor naming variations. The results demonstrate that LLMs can generate structurally compliant and semantically meaningful BPMN diagrams at scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a multi-stage LLM-driven pipeline for automatically generating BPMN models from textual process descriptions. The approach automates ground-truth construction by translating multilingual public BPMN XML files to English, validating them for executability using SpiffWorkflow, and applying targeted LLM-guided repairs to create a consistent corpus. Process descriptions are generated from these models and used to reconstruct executable BPMN 2.0 XML. A multi-dimensional similarity framework combining structural, type-distribution, and semantic embedding metrics is introduced for evaluation. On 750 public diagrams, 387 validated ground-truth models were produced, with average reconstruction similarity above 0.75 and approximately 50 near-perfect cases.
Significance. If the evaluation holds, this work offers a scalable method for BPMN model generation, which could significantly impact business process management by reducing the need for manual modeling. The use of public datasets and automated validation is commendable. However, the significance is tempered by potential circularity in the evaluation setup, where LLM involvement in ground-truth preparation may inflate similarity scores, limiting the demonstration of generalization to truly arbitrary textual descriptions.
major comments (1)
- [Ground-truth construction and empirical evaluation (sections describing the 387 models and similarity results)] The iterative LLM-guided repairs to produce the ground-truth corpus (described in the pipeline overview and empirical study sections), combined with LLM-based reconstruction from descriptions derived from those same repaired models, risks circularity. The SpiffWorkflow checks ensure executability but not that the repairs preserve the original semantic intent without introducing LLM-specific biases. This directly impacts the interpretation of the average similarity >0.75 (including ~50 near-perfect cases), as the high scores may reflect the reconstruction stage aligning with the LLM's prior outputs rather than accurately capturing process semantics from text. An independent human validation of a subset of the ground-truth models is needed to support the claim of semantically meaningful reconstructions.
minor comments (2)
- [Similarity framework definition] The exact formulations, weighting, or aggregation method for the multi-dimensional similarity framework (structural metrics, type-distribution alignment, and embedding-based measures) should be provided with formulas or pseudocode to support reproducibility.
- [Dataset and corpus construction] Additional details on the selection criteria for the initial 750 public BPMN diagrams and the specific exclusion rules that reduced the set to 387 validated models would help evaluate potential biases in the corpus.
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical pipeline that starts from external public BPMN diagrams, applies SpiffWorkflow validation plus LLM repairs to form a ground-truth corpus, generates process descriptions from those models, and measures reconstruction similarity using independent structural metrics, type-distribution alignment, and embedding-based semantic measures. No equations, fitted parameters presented as predictions, self-definitional steps, or load-bearing self-citations appear in the methodology. The reported similarity scores are direct empirical outputs from running the pipeline on external data rather than quantities that reduce to the inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs can accurately translate, validate, and repair BPMN models when guided by execution-oriented checks
- domain assumption SpiffWorkflow compliance checks provide a sufficient and unbiased measure of BPMN correctness
Reference graph
Works this paper leans on
-
[1]
SpiffWorkflow.https://github.com/ sartography/SpiffWorkflow, 2025
Samuel Abels, Matthew Hampton, Bruce Silver, and Kelly McDonald. SpiffWorkflow.https://github.com/ sartography/SpiffWorkflow, 2025
2025
-
[2]
Graph isomorphism in quasipolynomial time [extended abstract]
L ´aszl´o Babai. Graph isomorphism in quasipolynomial time [extended abstract]. InProceedings of the Forty- Eighth Annual ACM Symposium on Theory of Computing, STOC ’16, page 684–697, New York, NY , USA, 2016. Association for Computing Machinery
2016
-
[3]
Patrizio Bellan, Mauro Dragoni, Chiara Ghidini, Han van der Aa, and Simone Paolo Ponzetto. Process ex- traction from text: Benchmarking the state of the art and paving the way for future challenges.arXiv preprint arXiv:2110.03754, 2021. Version v2 last revised 25 Oct 2023
-
[4]
Czekster, and Thais Webber
Juliana Bowles, Ricardo M. Czekster, and Thais Webber. Annotated bpmn models for optimised healthcare resource planning. In Manuel Mazzara, Iulian Ober, and Gwen Sala¨un, editors,Software Technologies: Applica- tions and Foundations, pages 146–162. Springer International Publishing, 2018
2018
-
[5]
Automated generation of business process models from natural language text
Fabian Friedrich, Jan Mendling, and Frank Puhlmann. Automated generation of business process models from natural language text. InInternational Conference on Advanced Information Systems Engineering, pages 482– 496, 2011
2011
-
[6]
Deepeka Garg, Sihan Zeng, Sumitra Ganesh, and Leo Ardon. Generating structured plan representation of procedures with llms.arXiv preprint arXiv:2504.00029, 2025. Version v1 submitted March 28, 2025 (cs.SE, cs.AI)
-
[7]
The graph isomorphism problem.Commun
Martin Grohe and Pascal Schweitzer. The graph isomorphism problem.Commun. ACM, 63(11):128–134, Octo- ber 2020
2020
-
[8]
Vincent Derek Held. An enhanced automated approach for transforming natural language process descriptions to BPMN 2.0 process diagrams – with an evaluation of the application to ISO-norm process descriptions, December 2023. 10 Automated BPMN Model Generation from Textual Process Descriptions: A Multi-Stage LLM-Driven Approach
2023
-
[9]
Introducing bpmngen: An llm-based conversational framework for bpmn 2.0 process model generation
Luca Franziska H ¨orner. Introducing bpmngen: An llm-based conversational framework for bpmn 2.0 process model generation. InEMISA 2025, pages 17–31. Gesellschaft f ¨ur Informatik e.V ., Bonn, 2025
2025
-
[10]
From text to visual bpmn process models: design and evaluation
Ana Ivanchikj, Souhaila Serbout, and Cesare Pautasso. From text to visual bpmn process models: design and evaluation. InProceedings of the 23rd ACM/IEEE International Conference on Model Driven Engineering Languages and Systems, MODELS ’20, page 229–239, New York, NY , USA, 2020. Association for Computing Machinery
2020
-
[11]
S. A. Kassim, J. B. Gartner, L. Labb ´e, P. Landa, C. Paquet, F. Bergeron, C. Lemaire, and A. C ˆot´e. Benefits and limitations of business process model notation in modelling patient healthcare trajectory: a scoping review protocol.BMJ Open, 12(5):e060357, 2022
2022
-
[12]
Con- versational process modeling: Can generative ai empower domain experts in creating and redesigning process models?, 2024
Nataliia Klievtsova, Janik-Vasily Benzin, Timotheus Kampik, Juergen Mangler, and Stefanie Rinderle-Ma. Con- versational process modeling: Can generative ai empower domain experts in creating and redesigning process models?, 2024
2024
- [13]
-
[14]
Introducing the bpmn-chatbot for efficient llm-based process modeling
Julius K ¨opke and Aya Safan. Introducing the bpmn-chatbot for efficient llm-based process modeling. InProceed- ings of the Best Dissertation Award, Doctoral Consortium, and Demonstration and Resources Forum at BPM 2024, volume 3758 ofCEUR Workshop Proceedings, pages 86–90, Krakow, Poland, 2024. CEUR-WS.org. CC BY 4.0 open access
2024
-
[15]
Langchain.https://github.com/langchain-ai/langchain, 2025
LangChain Team. Langchain.https://github.com/langchain-ai/langchain, 2025
2025
-
[16]
Phuong Nam L ˆe, Charlotte Schneider-Depr´e, Alexandre Goossens, Alexander Stevens, Aur´elie Leribaux, and Jo- hannes De Smedt. Leveraging machine learning and enhanced parallelism detection for bpmn model generation from text.arXiv preprint arXiv:2507.08362, July 2025. Version v1 submitted 11 Jul 2025
-
[17]
Nl2processops: Towards llm-guided code generation for process execution
Flavia Monti, Francesco Leotta, Juergen Mangler, Massimo Mecella, and Stefanie Rinderle-Ma. Nl2processops: Towards llm-guided code generation for process execution. In Andrea Marrella, Manuel Resinas, Mieke Jans, and Michael Rosemann, editors,Business Process Management Forum, pages 127–143, Cham, 2024. Springer Nature Switzerland
2024
-
[18]
Julian Neuberger, Lars Ackermann, Han van der Aa, and Stefan Jablonski. A universal prompting strategy for extracting process model information from natural language text using large language models.arXiv preprint arXiv:2407.18540, 2024. Version v1 submitted July 26, 2024
-
[19]
GIVUP: Automated generation and verification of textual process descriptions
Quentin Nivon, Gwen Sala ¨un, and Fr ´ed´eric Lang. GIVUP: Automated generation and verification of textual process descriptions. InProceedings of the 33rd ACM International Conference on the Foundations of Software Engineering (FSE 2025), pages 1–5, Trondheim, Norway, June 2025. ACM. HAL Id: hal-05131967
2025
-
[20]
Business process model and notation (bpmn) version 2.0
Object Management Group. Business process model and notation (bpmn) version 2.0. Technical report, OMG Specification, 2011
2011
-
[21]
Sara Qayyum, Muhammad Moiz Asghar, and Muhammad Fouzan Yaseen. From dialogue to diagram: Task and relationship extraction from natural language for accelerated business process prototyping.arXiv preprint arXiv:2312.10432, 2023. Version v1 posted December 16, 2023
-
[22]
Sentence-bert: Sentence embeddings using siamese bert-networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks. InPro- ceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Com- putational Linguistics, 11 2019
2019
-
[23]
Borgwardt
Nino Shervashidze, Pascal Schweitzer, Erik Jan van Leeuwen, Kurt Mehlhorn, and Karsten M. Borgwardt. Weisfeiler-lehman graph kernels.Journal of Machine Learning Research, 12(77):2539–2561, 2011
2011
-
[24]
Marvin V oelter, Raheleh Hadian, Timotheus Kampik, Marius Breitmayer, and Manfred Reichert. Leveraging generative ai for extracting process models from multimodal documents.arXiv preprint arXiv:2406.04959,
-
[25]
Version v1 submitted June 2024
2024
-
[26]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V . Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InProceedings of the 36th International Conference on Neural Information Processing Systems, NIPS ’22, Red Hook, NY , USA,
-
[27]
Curran Associates Inc
-
[28]
Extraction of bpmn process models from unstructured textual descriptions
Bruno Zirnstein. Extraction of bpmn process models from unstructured textual descriptions. Report, April 2024
2024
-
[29]
Design nd development of an llm interface for prompt-based bpmn process generation and visualization, December 2024
Anastasiia Zubenko. Design nd development of an llm interface for prompt-based bpmn process generation and visualization, December 2024. 11
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.