Recognition: unknown
Beyond Perception Errors: Semantic Fixation in Large Vision-Language Models
Pith reviewed 2026-05-10 15:01 UTC · model grok-4.3
The pith
Large vision-language models favor familiar semantic rules over explicitly prompted alternatives even on identical visual inputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
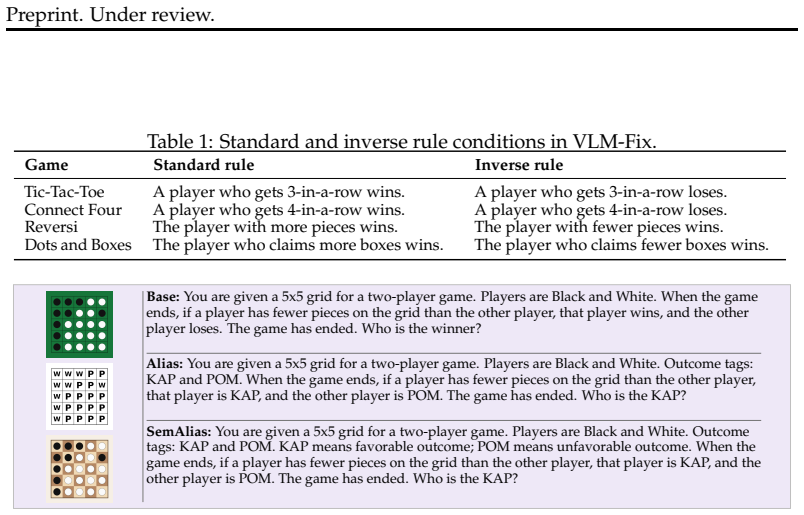
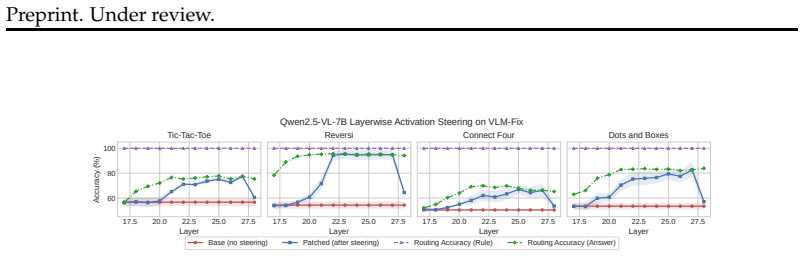
Semantic fixation is the tendency of VLMs to preserve a default interpretation even when the prompt specifies an alternative, equally valid mapping. The VLM-Fix benchmark isolates this by evaluating identical terminal board states under standard and inverse rule formulations in abstract strategy games. Across 14 models accuracy favors standard rules; neutral aliases narrow the inverse gap while loaded aliases reopen it. Post-training on one rule improves same-rule transfer but impairs opposite-rule transfer, and late-layer steering partially edits the error.
What carries the argument
Semantic fixation, the preservation of a default rule interpretation despite a prompt-specified alternative; isolated by comparing accuracy on identical board states under standard versus inverse rules in the VLM-Fix benchmark.
If this is right
- Accuracy is higher on standard rules than on inverse rules for the same board states.
- Neutral alias prompts substantially reduce the performance gap on inverse rules.
- Semantically loaded alias prompts reopen the inverse-rule accuracy gap.
- Training on one rule set improves transfer to the same rule but hurts transfer to the opposite rule.
- Late-layer activation steering partially recovers performance on inverse-rule tasks.
Where Pith is reading between the lines
- The same fixation mechanism may limit model adaptability when real-world instructions require overriding common priors, such as modified safety rules or novel game variants.
- Activation steering or neutral rephrasing could be tested as general tools for improving rule flexibility in other multimodal reasoning settings.
- The observed transfer patterns suggest that rule knowledge in VLMs is stored in a form tied to surface semantics rather than abstract mappings.
- If the pattern holds in non-game domains, current fine-tuning practices may systematically reduce a model's ability to handle defamiliarized instructions.
Load-bearing premise
The paired standard and inverse rule formulations in the abstract games cleanly separate semantic fixation from perception or prompt-parsing failures.
What would settle it
Finding no consistent accuracy difference between standard and inverse rule versions on the VLM-Fix dataset across multiple models would falsify the claimed semantic-fixation gap.
Figures














read the original abstract
Large vision-language models (VLMs) often rely on familiar semantic priors, but existing evaluations do not cleanly separate perception failures from rule-mapping failures. We study this behavior as semantic fixation: preserving a default interpretation even when the prompt specifies an alternative, equally valid mapping. To isolate this effect, we introduce VLM-Fix, a controlled benchmark over four abstract strategy games that evaluates identical terminal board states under paired standard and inverse rule formulations. Across 14 open and closed VLMs, accuracy consistently favors standard rules, revealing a robust semantic-fixation gap. Prompt interventions support this mechanism: neutral alias prompts substantially narrow the inverse-rule gap, while semantically loaded aliases reopen it. Post-training is strongly rule-aligned: training on one rule improves same-rule transfer but hurts opposite-rule transfer, while joint-rule training improves broader transfer. To test external validity beyond synthetic games, we evaluate analogous defamiliarization interventions on VLMBias and observe the same qualitative pattern. Finally, late-layer activation steering partially recovers degraded performance, indicating that semantic-fixation errors are at least partly editable in late representations. Project page, code, and dataset available at https://maveryn.github.io/vlm-fix/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces 'semantic fixation' as a failure mode in VLMs where models preserve default semantic priors even when prompts explicitly specify alternative, valid mappings. It presents the VLM-Fix benchmark over four abstract strategy games, evaluating identical terminal board states under paired standard vs. inverse rule formulations across 14 open and closed VLMs. Results show consistent accuracy favoring standard rules; neutral alias prompts narrow the inverse-rule gap while semantically loaded aliases reopen it. Additional experiments examine post-training transfer effects, extension to VLMBias, and partial recovery via late-layer activation steering. Code, dataset, and project page are released.
Significance. If the central isolation of semantic fixation holds, the work identifies a reproducible, intervention-sensitive bias in VLMs' rule interpretation that is distinct from perception or general reasoning failures, with implications for robust deployment in rule-governed tasks. Strengths include the controlled paired-rule design on synthetic games, the qualitative replication on VLMBias, the open release of code/dataset for reproducibility, and the demonstration that both prompt-level and representation-level interventions can modulate the effect.
major comments (2)
- [§3] §3 (VLM-Fix benchmark construction): The claim that accuracy differences isolate semantic fixation from parsing or linguistic confounds requires that standard and inverse rule prompts are matched on surface features. Inverse formulations are likely to contain additional negations, conditionals, or non-canonical phrasing, which could independently raise token-level or syntactic processing costs and produce the observed gap even without fixation on priors. The alias-prompt results are consistent with the mechanism but do not include explicit ablations or metrics (e.g., prompt length, parse depth, or lexical complexity) to rule out this alternative.
- [§4.2 and §5] §4.2 (prompt interventions) and §5 (post-training): While neutral aliases narrow the inverse-rule gap and loaded aliases reopen it, the paper does not report quantitative controls confirming that the alias prompts preserve equivalent syntactic complexity and token statistics to the original formulations. Without such matching, the intervention evidence remains compatible with a parsing-difficulty account rather than a pure semantic-fixation account.
minor comments (3)
- Report exact per-model sample sizes, number of terminal states per game, error bars or confidence intervals, and the statistical tests used for the accuracy-gap claims.
- Clarify the precise procedure for generating and verifying that terminal board states are identical and rule-consistent under both standard and inverse formulations.
- In the activation-steering experiments, specify the exact layers, steering coefficients, and how the steering vectors were derived.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address the major comments point by point below, agreeing that additional quantitative controls on prompt surface features would strengthen the isolation of semantic fixation. We have incorporated these analyses in the revision.
read point-by-point responses
-
Referee: [§3] §3 (VLM-Fix benchmark construction): The claim that accuracy differences isolate semantic fixation from parsing or linguistic confounds requires that standard and inverse rule prompts are matched on surface features. Inverse formulations are likely to contain additional negations, conditionals, or non-canonical phrasing, which could independently raise token-level or syntactic processing costs and produce the observed gap even without fixation on priors. The alias-prompt results are consistent with the mechanism but do not include explicit ablations or metrics (e.g., prompt length, parse depth, or lexical complexity) to rule out this alternative.
Authors: We agree that explicit matching on surface features is necessary to isolate semantic fixation from potential parsing costs. The VLM-Fix prompts were intentionally constructed with parallel syntactic structures, comparable sentence lengths, and minimal unnecessary negations or conditionals for the inverse rules. However, we acknowledge that the original manuscript did not report quantitative metrics for these properties. In the revised version we add a dedicated analysis (new Table and paragraph in §3) reporting token counts, number of negations/conditionals, dependency-parse depth, and lexical complexity (type-token ratio and Flesch-Kincaid grade level) for each paired standard/inverse formulation. These metrics confirm close matching, with average differences too small to account for the observed accuracy gaps across 14 models. The neutral-alias results, which alter only semantic content while preserving syntax, provide further evidence against a pure parsing-difficulty explanation. revision: yes
-
Referee: [§4.2 and §5] §4.2 (prompt interventions) and §5 (post-training): While neutral aliases narrow the inverse-rule gap and loaded aliases reopen it, the paper does not report quantitative controls confirming that the alias prompts preserve equivalent syntactic complexity and token statistics to the original formulations. Without such matching, the intervention evidence remains compatible with a parsing-difficulty account rather than a pure semantic-fixation account.
Authors: We thank the referee for noting this gap in the reported controls. The alias prompts were designed to keep syntactic structure, length, and token statistics as close as possible to the base formulations, with changes limited to the semantic descriptors of the rules. In the revision we add explicit quantitative comparisons (new paragraph and supplementary table in §4.2) of token length, syntactic complexity (average dependency depth), and token-frequency statistics between original and alias prompts. These show high equivalence, supporting that the narrowing or reopening of the fixation gap is driven by semantic content. The same structural consistency holds for the post-training experiments in §5, where rule prompt phrasing is held fixed across training conditions. revision: yes
Circularity Check
No circularity: purely empirical benchmark with no derivations or self-referential predictions
full rationale
The paper introduces VLM-Fix as a controlled empirical benchmark evaluating VLMs on paired standard/inverse rule formulations across abstract games, with results reported as observed accuracy gaps and intervention effects. No equations, fitted parameters, or derivation chains appear in the abstract or described methodology. Claims rest on direct measurements of model behavior rather than any self-definitional mapping, renamed empirical pattern, or load-bearing self-citation that reduces the central result to its own inputs. The work is self-contained against external benchmarks and does not invoke uniqueness theorems or ansatzes from prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Models can parse and apply explicit textual rule descriptions to visual board states
invented entities (1)
-
semantic fixation
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Accessed: 2026-03-21. Rabiul Awal, Saba Ahmadi, Le Zhang, and Aishwarya Agrawal. Vismin: Visual minimal- change understanding. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.ar...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2026
-
[2]
doi: 10.1109/CVPR52733.2024.01138. Jen-tse Huang, Ruijia Wang, Yiqiao Jin, Yang Song, Esin Durmus, Dale Schuurmans, David Blei, Jacob Steinhardt, and Tatsunori Hashimoto. VisBias: A benchmark for measuring explicit and implicit social biases in vision language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing...
-
[3]
Answer with only<label1>or<label2>. Do not add any other text
Solitaire Laboratory. Accessed: 2026-03-23. Jonathan Kim, Anna Podlasek, Kie Shidara, Feng Liu, Ahmed Alaa, and Danilo Bernardo. Limitations of large language models in clinical problem-solving arising from inflexible reasoning.Scientific reports, 15(1):39426, 2025. Kang-il Lee, Minbeom Kim, Seunghyun Yoon, Minsung Kim, Dongryeol Lee, Hyukhun Koh, and Kyo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.