Recognition: unknown
VidTAG: Temporally Aligned Video to GPS Geolocalization with Denoising Sequence Prediction at a Global Scale
Pith reviewed 2026-05-10 15:32 UTC · model grok-4.3
The pith
VidTAG aligns video frames to GPS coordinates using temporal alignment and denoising for consistent global trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
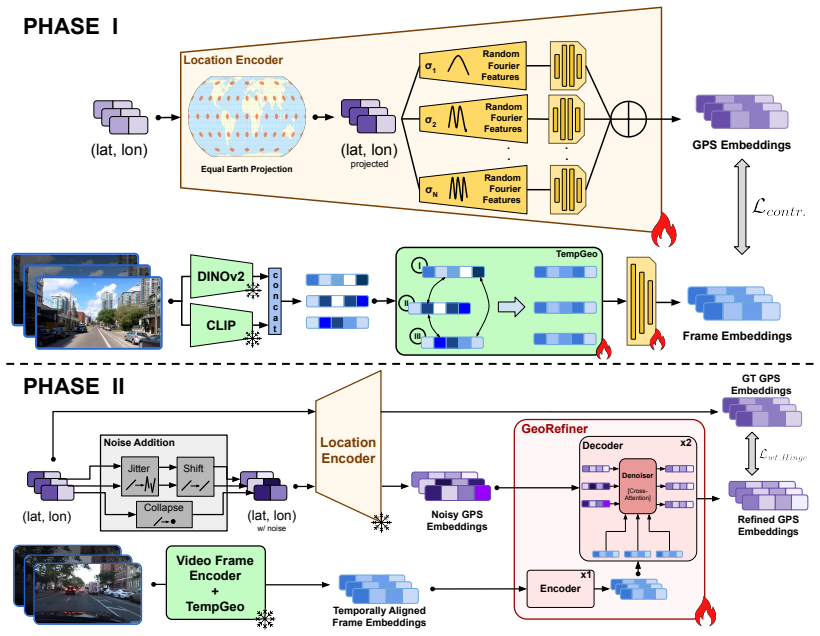
VidTAG performs frame-to-GPS retrieval with a dual-encoder architecture that leverages both self-supervised and language-aligned features. To handle temporal inconsistencies in video, it introduces the TempGeo module to align frame embeddings and the GeoRefiner module, an encoder-decoder that refines the GPS features using those aligned embeddings, enabling the generation of temporally consistent trajectories at global scale.
What carries the argument
Dual-encoder retrieval system with the TempGeo module for aligning frame embeddings temporally and the GeoRefiner module as an encoder-decoder for denoising and refining the GPS sequence predictions.
If this is right
- Supports fine-grained GPS localization and trajectory mapping for videos rather than only coarse city-level classification.
- Enables practical global-scale operation because constructing a GPS coordinate gallery is straightforward and low-cost compared to image galleries.
- Generates temporally consistent predictions across video frames.
- Improves accuracy by 20 percent at the 1 km threshold compared to GeoCLIP on Mapillary and GAMa datasets.
- Outperforms current state-of-the-art by 25 percent on the CityGuessr68k benchmark for coarse-grained video geolocalization.
Where Pith is reading between the lines
- Applications in forensics and social media verification could benefit from such precise video location data.
- The approach of combining alignment and denoising might apply to other video analysis tasks requiring sequence consistency.
- Testing on more diverse video sources could reveal how well it handles extreme variability in conditions.
Load-bearing premise
That self-supervised and language-aligned frame features combined with TempGeo alignment and GeoRefiner denoising will generalize across the full range of global video variability without overfitting to specific datasets.
What would settle it
Running the model on a new, unseen global-scale video dataset with varied conditions and finding that it does not achieve the claimed improvements in accuracy at the 1 km threshold or in trajectory consistency.
Figures
















read the original abstract
The task of video geolocalization aims to determine the precise GPS coordinates of a video's origin and map its trajectory; with applications in forensics, social media, and exploration. Existing classification-based approaches operate at a coarse city-level granularity and fail to capture fine-grained details, while image retrieval methods are impractical on a global scale due to the need for extensive image galleries which are infeasible to compile. Comparatively, constructing a gallery of GPS coordinates is straightforward and inexpensive. We propose VidTAG, a dual-encoder framework that performs frame-to-GPS retrieval using both self-supervised and language-aligned features. To address temporal inconsistencies in video predictions, we introduce the TempGeo module, which aligns frame embeddings, and the GeoRefiner module, an encoder-decoder architecture that refines GPS features using the aligned frame embeddings. Evaluations on Mapillary (MSLS) and GAMa datasets demonstrate our model's ability to generate temporally consistent trajectories and outperform baselines, achieving a 20% improvement at the 1 km threshold over GeoCLIP. We also beat current State-of-the-Art by 25% on global coarse grained video geolocalization (CityGuessr68k). Our approach enables fine-grained video geolocalization and lays a strong foundation for future research. More details on the project webpage: https://parthpk.github.io/vidtag_webpage/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents VidTAG, a dual-encoder framework for fine-grained video-to-GPS geolocalization at global scale. It extracts self-supervised and language-aligned frame features, employs the TempGeo module to enforce temporal alignment of embeddings across video frames, and uses the GeoRefiner encoder-decoder (with denoising sequence prediction) to refine GPS coordinate outputs. The central claims are that this produces temporally consistent trajectories and yields a 20% improvement at the 1 km threshold over GeoCLIP on the Mapillary (MSLS) and GAMa datasets, plus a 25% gain over prior SOTA on the CityGuessr68k benchmark for coarse-grained global video geolocalization.
Significance. If the performance claims prove robust under proper controls, the work would be significant: it sidesteps the infeasibility of maintaining global image galleries by operating directly on compact GPS coordinate sets, while the temporal alignment and denoising components directly tackle inconsistency issues that plague frame-independent retrieval. This could advance practical applications in forensics, social media verification, and exploration. The project webpage is noted as a positive step toward reproducibility.
major comments (2)
- [Abstract] Abstract: The headline performance numbers (20% gain at 1 km over GeoCLIP on MSLS/GAMa; 25% on CityGuessr68k) are presented without error bars, ablation tables isolating TempGeo/GeoRefiner contributions versus base features, train/test split definitions, GPS gallery construction/indexing details at global scale, or geographic diversity controls. These omissions are load-bearing because the central claim is that the proposed modules generalize across global video variability; without them the reported outperformance cannot be verified or attributed.
- [Abstract] Abstract (and §4 Experiments, if present): No information is supplied on data exclusion rules, potential leakage between video sequences and GPS points, or cross-dataset controls. This directly affects the weakest assumption that self-supervised/language-aligned features plus TempGeo/GeoRefiner will transfer without dataset-specific overfitting.
minor comments (1)
- [Abstract] Abstract: The claim that 'constructing a gallery of GPS coordinates is straightforward and inexpensive' would benefit from a short quantitative statement on gallery size and query latency to support the scalability argument.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of reproducibility and experimental rigor that we will address in the revision. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline performance numbers (20% gain at 1 km over GeoCLIP on MSLS/GAMa; 25% on CityGuessr68k) are presented without error bars, ablation tables isolating TempGeo/GeoRefiner contributions versus base features, train/test split definitions, GPS gallery construction/indexing details at global scale, or geographic diversity controls. These omissions are load-bearing because the central claim is that the proposed modules generalize across global video variability; without them the reported outperformance cannot be verified or attributed.
Authors: We agree that the abstract, constrained by length, does not include these details. The full manuscript in Section 4 describes the train/test splits for MSLS, GAMa, and CityGuessr68k, provides ablation studies isolating TempGeo and GeoRefiner, and explains the GPS coordinate gallery construction (a compact set of points rather than images) with indexing via coordinate hashing for global scale. Geographic coverage is achieved through the multi-continental scope of the evaluation datasets. We will add error bars to all reported metrics, include a concise reference to the ablations and splits in the abstract, and expand the GPS gallery description in the revised version to make attribution of gains explicit. revision: yes
-
Referee: [Abstract] Abstract (and §4 Experiments, if present): No information is supplied on data exclusion rules, potential leakage between video sequences and GPS points, or cross-dataset controls. This directly affects the weakest assumption that self-supervised/language-aligned features plus TempGeo/GeoRefiner will transfer without dataset-specific overfitting.
Authors: We acknowledge the absence of explicit discussion on these points. In the revised manuscript we will add a new subsection under Experiments detailing: (i) data exclusion rules (removal of low-quality, duplicate, or temporally incomplete sequences), (ii) leakage prevention (ensuring no shared video sequences or GPS coordinates between train and test partitions, verified via sequence ID and coordinate hashing), and (iii) cross-dataset controls (training on one dataset and evaluating zero-shot on others). These additions will directly support the generalization claims. revision: yes
Circularity Check
No significant circularity; empirical claims rest on external dataset evaluations.
full rationale
The paper introduces a dual-encoder retrieval framework augmented by TempGeo alignment and GeoRefiner denoising modules, then reports performance as measured improvements (20% at 1 km over GeoCLIP on MSLS/GAMa; 25% on CityGuessr68k) against independent baselines. No equations, self-definitional reductions, fitted-parameter predictions, or load-bearing self-citations appear in the provided text that would make any claimed result equivalent to its inputs by construction. The derivation chain consists of architectural choices evaluated on held-out external datasets and is therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Openstreetview-5m: The many roads to global visual geolocation
Guillaume Astruc, Nicolas Dufour, Ioannis Siglidis, Con- stantin Aronssohn, Nacim Bouia, Stephanie Fu, Romain Loiseau, Van Nguyen Nguyen, Charles Raude, Elliot Vin- cent, et al. Openstreetview-5m: The many roads to global visual geolocation. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 21967–21977, 2024. 6, 7
2024
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 2, 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Is space-time attention all you need for video understanding? InICML, page 4, 2021
Gedas Bertasius, Heng Wang, and Lorenzo Torresani. Is space-time attention all you need for video understanding? InICML, page 4, 2021. 7
2021
-
[4]
Gaea: A geolocation aware conversational model.arXiv preprint arXiv:2503.16423, 2025
Ron Campos, Ashmal Vayani, Parth Parag Kulkarni, Ro- hit Gupta, Aritra Dutta, and Mubarak Shah. Gaea: A geolocation aware conversational model.arXiv preprint arXiv:2503.16423, 2025. 2
-
[5]
Where we are and what we’re looking at: Query based worldwide image geo-localization using hierarchies and scenes
Brandon Clark, Alec Kerrigan, Parth Parag Kulkarni, Vi- cente Vivanco Cepeda, and Mubarak Shah. Where we are and what we’re looking at: Query based worldwide image geo-localization using hierarchies and scenes. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23182–23190, 2023. 1, 2, 6, 7, 5
2023
-
[6]
Sam- ple4geo: Hard negative sampling for cross-view geo- localisation
Fabian Deuser, Konrad Habel, and Norbert Oswald. Sam- ple4geo: Hard negative sampling for cross-view geo- localisation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 16847–16856, 2023. 1, 2
2023
-
[7]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, et al. An image is worth 16x16 words: Trans- formers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020. 2, 1
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[8]
Computing discrete fr´echet distance
Thomas Eiter and Heikki Mannila. Computing discrete fr´echet distance. Technical Report CD-TR 94/64, Christian Doppler Laboratory for Expert Systems, 1994. 6, 4
1994
- [9]
-
[10]
Xi-net: Transformer based seismic waveform reconstructor
Anshuman Gaharwar, Parth Parag Kulkarni, Joshua Dickey, and Mubarak Shah. Xi-net: Transformer based seismic waveform reconstructor. In2023 IEEE International Confer- ence on Image Processing (ICIP), pages 2725–2729. IEEE,
-
[11]
Garg and M
S. Garg and M. Milford. Seqnet: Learning descriptors for sequence-based hierarchical place recognition.IEEE Robotics and Automation Letters, 6(3):4305–4312, 2021. 3
2021
-
[12]
Lukas Haas, Silas Alberti, and Michal Skreta. Learning gen- eralized zero-shot learners for open-domain image geolocal- ization.arXiv preprint arXiv:2302.00275, 2023. 6, 7
-
[13]
Pigeon: Predicting image geolocations
Lukas Haas, Michal Skreta, Silas Alberti, and Chelsea Finn. Pigeon: Predicting image geolocations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12893–12902, 2024. 1, 2
2024
-
[14]
Im2gps: estimating geo- graphic information from a single image
James Hays and Alexei A Efros. Im2gps: estimating geo- graphic information from a single image. In2008 ieee con- ference on computer vision and pattern recognition, pages 1–8. IEEE, 2008. 2
2008
-
[15]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 2
2016
-
[16]
Cvm-net: Cross-view matching network for image- based ground-to-aerial geo-localization
Sixing Hu, Mengdan Feng, Rang MH Nguyen, and Gim Hee Lee. Cvm-net: Cross-view matching network for image- based ground-to-aerial geo-localization. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7258–7267, 2018. 2
2018
-
[17]
3d convolu- tional neural networks for human action recognition.IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(1):221–231, 2013
Shuiwang Ji, Wei Xu, Ming Yang, and Kai Yu. 3d convolu- tional neural networks for human action recognition.IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(1):221–231, 2013. 2
2013
-
[18]
G3: an effective and adaptive framework for worldwide geolocalization using large multi- modality models.Advances in Neural Information Process- ing Systems, 37:53198–53221, 2024
Pengyue Jia, Yiding Liu, Xiaopeng Li, Xiangyu Zhao, Yuhao Wang, Yantong Du, Xiao Han, Xuetao Wei, Shuaiqiang Wang, and Dawei Yin. G3: an effective and adaptive framework for worldwide geolocalization using large multi- modality models.Advances in Neural Information Process- ing Systems, 37:53198–53221, 2024. 2
2024
-
[19]
Pengyue Jia, Seongheon Park, Song Gao, Xiangyu Zhao, and Yixuan Li. Georanker: Distance-aware ranking for worldwide image geolocalization.arXiv preprint arXiv:2505.13731, 2025. 2
-
[20]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Cityguessr: City-level video geo-localization on a global scale
Parth Parag Kulkarni, Gaurav Kumar Nayak, and Mubarak Shah. Cityguessr: City-level video geo-localization on a global scale. InEuropean Conference on Computer Vision, pages 293–311. Springer, 2024. 1, 2, 3, 5, 6, 7, 8
2024
-
[22]
The benchmarking initiative for multimedia evaluation: Mediaeval 2016.IEEE MultiMedia, 24(1):93–96, 2017
Martha Larson, Mohammad Soleymani, Guillaume Gravier, Bogdan Ionescu, and Gareth JF Jones. The benchmarking initiative for multimedia evaluation: Mediaeval 2016.IEEE MultiMedia, 24(1):93–96, 2017. 2, 3
2016
-
[23]
Handwritten digit recognition with a back- propagation network.Advances in neural information pro- cessing systems, 2, 1989
Yann LeCun, Bernhard Boser, John Denker, Donnie Hen- derson, Richard Howard, Wayne Hubbard, and Lawrence Jackel. Handwritten digit recognition with a back- propagation network.Advances in neural information pro- cessing systems, 2, 1989. 2, 7 9
1989
-
[24]
M Lewis. Bart: Denoising sequence-to-sequence pre- training for natural language generation, translation, and comprehension.arXiv preprint arXiv:1910.13461, 2019. 4
work page internal anchor Pith review arXiv 1910
-
[25]
Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K¨uttler, Mike Lewis, Wen-tau Yih, Tim Rockt ¨aschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020. 2
2020
-
[26]
Georea- soner: Geo-localization with reasoning in street views using a large vision-language model
Ling Li, Yu Ye, Bingchuan Jiang, and Wei Zeng. Georea- soner: Geo-localization with reasoning in street views using a large vision-language model. InForty-first International Conference on Machine Learning, 2024. 2, 6, 7
2024
-
[27]
Lending orientation to neural networks for cross-view geo-localization
Liu Liu and Hongdong Li. Lending orientation to neural networks for cross-view geo-localization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5624–5633, 2019. 2
2019
-
[28]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 10012–10022, 2021. 7
2021
-
[29]
Mereu et al
R. Mereu et al. Learning sequential descriptors for sequence- based visual place recognition. InProceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2022. 3
2022
-
[30]
Li Mi, Chang Xu, Javiera Castillo-Navarro, Syrielle Montar- iol, Wen Yang, Antoine Bosselut, and Devis Tuia. Congeo: Robust cross-view geo-localization across ground view vari- ations.arXiv preprint arXiv:2403.13965, 2024. 1, 2
-
[31]
Maliar, L., Maliar, S., and Valli, F
Diganta Misra. Mish: A self regularized non-monotonic ac- tivation function.arXiv preprint arXiv:1908.08681, 2019. 2
-
[32]
Geolocation estimation of photos using a hierarchical model and scene classification
Eric Muller-Budack, Kader Pustu-Iren, and Ralph Ewerth. Geolocation estimation of photos using a hierarchical model and scene classification. InProceedings of the European Conference on Computer Vision (ECCV), pages 563–579,
-
[33]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 2, 3, 7, 8, 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Pytorch: An im- perative style, high-performance deep learning library.Ad- vances in neural information processing systems, 32, 2019
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An im- perative style, high-performance deep learning library.Ad- vances in neural information processing systems, 32, 2019. 1
2019
-
[35]
Karl Pearson. Liii. on lines and planes of closest fit to sys- tems of points in space.The London, Edinburgh, and Dublin philosophical magazine and journal of science, 2(11):559– 572, 1901. 5
1901
-
[36]
Manu S Pillai, Mamshad Nayeem Rizve, and Mubarak Shah. Garet: Cross-view video geolocalization with adapters and auto-regressive transformers.arXiv preprint arXiv:2408.02840, 2024. 2
-
[37]
Where in the world is this image? transformer-based geo-localization in the wild
Shraman Pramanick, Ewa M Nowara, Joshua Gleason, Car- los D Castillo, and Rama Chellappa. Where in the world is this image? transformer-based geo-localization in the wild. InEuropean Conference on Computer Vision, pages 196–
-
[38]
Springer, 2022. 1, 2
2022
-
[39]
Language models are unsu- pervised multitask learners.OpenAI blog, 1(8):9, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsu- pervised multitask learners.OpenAI blog, 1(8):9, 2019. 8
2019
-
[40]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PMLR, 2021. 2, 3, 7, 1
2021
-
[41]
Cross-view image synthesis using geometry-guided conditional gans.Computer Vision and Image Understanding, 187:102788, 2019
Krishna Regmi and Ali Borji. Cross-view image synthesis using geometry-guided conditional gans.Computer Vision and Image Understanding, 187:102788, 2019. 2
2019
-
[42]
Bridging the domain gap for ground-to-aerial image matching
Krishna Regmi and Mubarak Shah. Bridging the domain gap for ground-to-aerial image matching. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 470–479, 2019. 2
2019
-
[43]
Video geo-localization employing geo-temporal feature learning and gps trajectory smoothing
Krishna Regmi and Mubarak Shah. Video geo-localization employing geo-temporal feature learning and gps trajectory smoothing. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12126–12135, 2021. 2
2021
-
[44]
Generalized in- tersection over union: A metric and a loss for bounding box regression
Hamid Rezatofighi, Nathan Tsoi, JunYoung Gwak, Amir Sadeghian, Ian Reid, and Silvio Savarese. Generalized in- tersection over union: A metric and a loss for bounding box regression. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 658–666,
-
[45]
The equal earth map projection.International Journal of Geographical Information Science, 33(3):454–465, 2019
Bojan ˇSavriˇc, Tom Patterson, and Bernhard Jenny. The equal earth map projection.International Journal of Geographical Information Science, 33(3):454–465, 2019. 4, 2
2019
-
[46]
Cplanet: Enhancing image geolocalization by combi- natorial partitioning of maps
Paul Hongsuck Seo, Tobias Weyand, Jack Sim, and Bohyung Han. Cplanet: Enhancing image geolocalization by combi- natorial partitioning of maps. InProceedings of the Euro- pean Conference on Computer Vision (ECCV), pages 536– 551, 2018. 2
2018
-
[47]
Gt-loc: Unifying when and where in images through a joint embedding space
David G Shatwell, Ishan Rajendrakumar Dave, Sirnam Swetha, and Mubarak Shah. Gt-loc: Unifying when and where in images through a joint embedding space. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1–11, 2025. 2
2025
-
[48]
Where am i looking at? joint location and orientation es- timation by cross-view matching
Yujiao Shi, Xin Yu, Dylan Campbell, and Hongdong Li. Where am i looking at? joint location and orientation es- timation by cross-view matching. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4064–4072, 2020. 2
2020
-
[49]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Karen Simonyan and Andrew Zisserman. Very deep convo- lutional networks for large-scale image recognition.arXiv preprint arXiv:1409.1556, 2014. 2
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[50]
Fourier features let networks learn high frequency functions in low dimen- 10 sional domains.Advances in neural information processing systems, 33:7537–7547, 2020
Matthew Tancik, Pratul Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ra- mamoorthi, Jonathan Barron, and Ren Ng. Fourier features let networks learn high frequency functions in low dimen- 10 sional domains.Advances in neural information processing systems, 33:7537–7547, 2020. 4, 2
2020
-
[51]
Coming down to earth: Satellite-to-street view synthesis for geo-localization
Aysim Toker, Qunjie Zhou, Maxim Maximov, and Laura Leal-Taix´e. Coming down to earth: Satellite-to-street view synthesis for geo-localization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6488–6497, 2021. 2
2021
-
[52]
Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training.Advances in neural information processing systems, 35:10078–10093, 2022
Zhan Tong, Yibing Song, Jue Wang, and Limin Wang. Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training.Advances in neural information processing systems, 35:10078–10093, 2022. 7
2022
-
[53]
City scale geo-spatial trajectory estimation of a mov- ing camera
Gonzalo Vaca-Castano, Amir Roshan Zamir, and Mubarak Shah. City scale geo-spatial trajectory estimation of a mov- ing camera. In2012 IEEE Conference on Computer Vision and Pattern Recognition, pages 1186–1193. IEEE, 2012. 2
2012
-
[54]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. 2, 4, 1
2017
-
[55]
Geoclip: Clip-inspired alignment be- tween locations and images for effective worldwide geo- localization.Advances in Neural Information Processing Systems, 36, 2024
Vicente Vivanco Cepeda, Gaurav Kumar Nayak, and Mubarak Shah. Geoclip: Clip-inspired alignment be- tween locations and images for effective worldwide geo- localization.Advances in Neural Information Processing Systems, 36, 2024. 1, 2, 3, 6, 7, 8, 5
2024
-
[56]
Revisiting im2gps in the deep learning era
Nam V o, Nathan Jacobs, and James Hays. Revisiting im2gps in the deep learning era. InProceedings of the IEEE inter- national conference on computer vision, pages 2621–2630,
-
[57]
Gama: Cross- view video geo-localization
Shruti Vyas, Chen Chen, and Mubarak Shah. Gama: Cross- view video geo-localization. InEuropean Conference on Computer Vision, pages 440–456. Springer, 2022. 2, 5, 6, 1, 3, 7, 8
2022
-
[58]
Fairseq s2t: Fast speech-to-text modeling with fairseq.arXiv preprint arXiv:2010.05171, 2020
Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, and Juan Pino. Fairseq s2t: Fast speech-to-text modeling with fairseq.arXiv preprint arXiv:2010.05171, 2020. 4
-
[59]
Mapillary street-level sequences: A dataset for lifelong place recognition
Frederik Warburg, Soren Hauberg, Manuel Lopez- Antequera, Pau Gargallo, Yubin Kuang, and Javier Civera. Mapillary street-level sequences: A dataset for lifelong place recognition. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2626–2635, 2020. 2, 5, 8, 1, 3, 7
2020
-
[60]
Planet- photo geolocation with convolutional neural networks
Tobias Weyand, Ilya Kostrikov, and James Philbin. Planet- photo geolocation with convolutional neural networks. In European Conference on Computer Vision, pages 37–55. Springer, 2016. 2, 6, 7, 5
2016
-
[61]
Wide-area image geolocalization with aerial reference im- agery
Scott Workman, Richard Souvenir, and Nathan Jacobs. Wide-area image geolocalization with aerial reference im- agery. InProceedings of the IEEE International Conference on Computer Vision, pages 3961–3969, 2015. 2
2015
-
[62]
Cross-view geo-localization with layer-to-layer transformer.Advances in Neural Information Processing Systems, 34:29009–29020,
Hongji Yang, Xiufan Lu, and Yingying Zhu. Cross-view geo-localization with layer-to-layer transformer.Advances in Neural Information Processing Systems, 34:29009–29020,
-
[63]
Bdd100k: A diverse driving dataset for heterogeneous multitask learning
Fisher Yu, Haofeng Chen, Xin Wang, Wenqi Xian, Yingying Chen, Fangchen Liu, Vashisht Madhavan, and Trevor Dar- rell. Bdd100k: A diverse driving dataset for heterogeneous multitask learning. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 2636–2645, 2020. 5, 6, 1, 7
2020
-
[64]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023. 8
2023
-
[65]
Places: A 10 million image database for scene recognition.IEEE transactions on pattern analysis and machine intelligence, 40(6):1452–1464, 2017
Bolei Zhou, Agata Lapedriza, Aditya Khosla, Aude Oliva, and Antonio Torralba. Places: A 10 million image database for scene recognition.IEEE transactions on pattern analysis and machine intelligence, 40(6):1452–1464, 2017. 5
2017
-
[66]
Vigor: Cross- view image geo-localization beyond one-to-one retrieval
Sijie Zhu, Taojiannan Yang, and Chen Chen. Vigor: Cross- view image geo-localization beyond one-to-one retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 3640–3649, 2021. 1, 2
2021
-
[67]
Transgeo: Trans- former is all you need for cross-view image geo-localization
Sijie Zhu, Mubarak Shah, and Chen Chen. Transgeo: Trans- former is all you need for cross-view image geo-localization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1162–1171, 2022. 1, 2 11 VidTAG: Temporally Aligned Video to GPS Geolocalization with Denoising Sequence Prediction at a Global Scale Supplementary...
2022
-
[68]
(If there are a few outliers they can be skipped)
For each region that contains a sizable amount of train- ing data, get the maximum and minimum of both lat- itude and longitude(LAT M IN,LON M IN,LAT M AX, LONM AX). (If there are a few outliers they can be skipped). 3 Table 11. Comparison of Uniform Grid Gallery evaluation and Validation-set Gallery evaluation on Mapillary(MSLS) dataset Model Uniform Gri...
-
[69]
Also determine the resolution of the gallery (the finer the resolution the larger the gallery
To keep an error margin, determine a constant padding which is to be applied to (LAT M IN,LON M IN, LATM AX,LON M AX). Also determine the resolution of the gallery (the finer the resolution the larger the gallery
-
[70]
Determine new LATM IN =LAT M IN −padding, LATM AX =LAT M AX +padding, LONM IN =LON M IN −padding, LONM AX =LON M AX +padding
-
[71]
Compute distance(dis LAT ) between (LAT M IN, LONM IN) and (LAT M AX,LON M IN), and distance(disLON ) between (LAT M IN,LON M IN) and (LATM IN,LON M AX)
-
[72]
Generate a grid with each point at a uniform distance (resolution), dividing the area into equidistant points in both directions Npoints = (disLAT ∗dis LON )//resolution2 D.2. Evaluation with Val-set Gallery Retrieval A real world scenario entails not knowing the actual ground truth values pertaining to the queries, which is the reason for constructing a ...
-
[73]
Collect all model predictions and ground truth labels for a particular sequence
-
[74]
This will serve as the ground truth label of the entire video sequence
Compute the centroid of the ground truth labels. This will serve as the ground truth label of the entire video sequence
-
[75]
Obtain the prediction that is closest to this centroid (this reduces error due to out- liers)
Compute the centroid of predictions pertaining to all frames in the sequence. Obtain the prediction that is closest to this centroid (this reduces error due to out- liers). This will serve as the prediction for the entire video sequence
-
[76]
Compute distance accuracy at all thresholds using this distance measure
Finally compute the distance between the prediction and the ground truth label. Compute distance accuracy at all thresholds using this distance measure. This enables us to effectively measure performance of a model at video level. However, this set of metrics cannot be used to judge the quality of formed trajectories. For this exact purpose we use DFD and...
-
[77]
As Mapillary(MSLS) is a smaller dataset, we take the entire training split
-
[78]
(b) As CityGuessr68k is very large, we sample the data in such a way that the number of sequences is roughly equivalent to MSLS
For CityGuessr68k, (a) We remove training data from cities which are also present in MSLS to avoid false negatives in the con- trastive loss. (b) As CityGuessr68k is very large, we sample the data in such a way that the number of sequences is roughly equivalent to MSLS. (c) This is achieved by taking all sequences from cities with less than 80 sequences, ...
-
[79]
We train a model on this unified data for 200 epochs at an learning rate decay rate of 0.97
For GaMa, we randomly sample videos so that the cor- pus size is equivalent to the other two. We train a model on this unified data for 200 epochs at an learning rate decay rate of 0.97. Rest of the settings are unchanged. Tables 12 and 13 show evaluation performance of our model on individual datasets. Across all 3 datasets, we observe that our unified m...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.