Recognition: 2 theorem links
· Lean TheoremAlphaEval: Evaluating Agents in Production
Pith reviewed 2026-05-10 16:26 UTC · model grok-4.3
The pith
AlphaEval introduces a benchmark of 94 real production tasks from seven companies to test complete AI agent systems in their actual operating conditions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
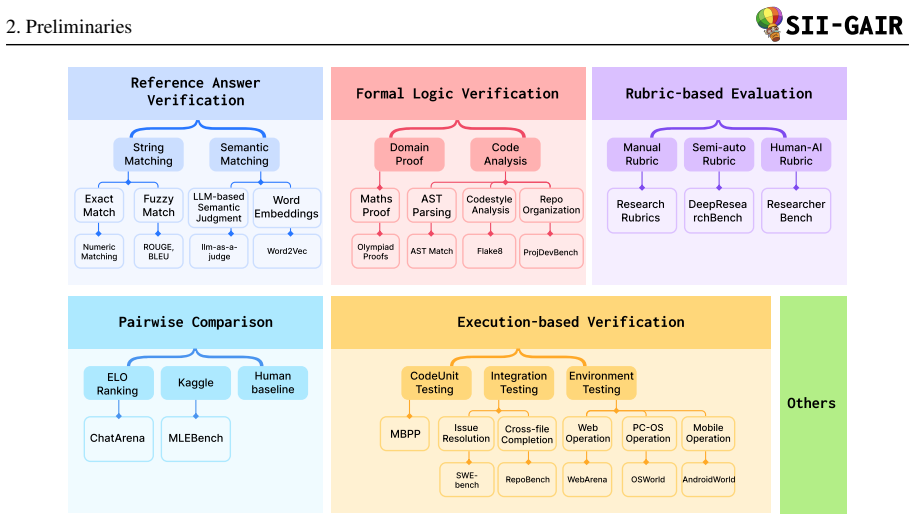
AlphaEval evaluates complete agent products as commercial systems on 94 tasks sourced from seven companies, using a mix of judgment paradigms that match production realities including implicit constraints, heterogeneous multi-modal inputs, undeclared domain expertise, long-horizon outputs, and time-varying expert judgment.
What carries the argument
The requirement-to-benchmark construction framework, which converts authentic production requirements into executable tasks through a standardized, modular pipeline.
If this is right
- Agent products can be compared directly on long-horizon deliverables that require domain judgment rather than on short, fully specified prompts.
- Performance gaps between different commercial agents become measurable even when model-level scores look similar.
- Any organization can replicate the construction pipeline to generate its own production-matched evaluation set without starting from scratch.
- Evaluation can combine several assessment methods inside one domain instead of forcing a single metric across all tasks.
Where Pith is reading between the lines
- Widespread adoption would shift agent development priorities toward handling incomplete information and multi-source documents.
- The framework could be extended to track how agent performance changes when the same task is re-evaluated after expert standards evolve.
- Cross-company comparisons might reveal domain-specific failure patterns that single-company tests cannot detect.
Load-bearing premise
Tasks taken from the seven companies and processed through the framework still carry the same implicit constraints, mixed inputs, hidden expertise needs, and changing success standards that exist in live commercial environments.
What would settle it
Run the same 94 tasks on new agents inside one of the source companies and check whether the relative rankings match the rankings produced by the company's own internal expert review process.
Figures


read the original abstract
The rapid deployment of AI agents in commercial settings has outpaced the development of evaluation methodologies that reflect production realities. Existing benchmarks measure agent capabilities through retrospectively curated tasks with well-specified requirements and deterministic metrics -- conditions that diverge fundamentally from production environments where requirements contain implicit constraints, inputs are heterogeneous multi-modal documents with information fragmented across sources, tasks demand undeclared domain expertise, outputs are long-horizon professional deliverables, and success is judged by domain experts whose standards evolve over time. We present AlphaEval, a production-grounded benchmark of 94 tasks sourced from seven companies deploying AI agents in their core business, spanning six O*NET (Occupational Information Network) domains. Unlike model-centric benchmarks, AlphaEval evaluates complete agent products -- Claude Code, Codex, etc. -- as commercial systems, capturing performance variations invisible to model-level evaluation. Our evaluation framework covers multiple paradigms (LLM-as-a-Judge, reference-driven metrics, formal verification, rubric-based assessment, automated UI testing, etc.), with individual domains composing multiple paradigms. Beyond the benchmark itself, we contribute a requirement-to-benchmark construction framework -- a systematic methodology that transforms authentic production requirements into executable evaluation tasks in minimal time. This framework standardizes the entire pipeline from requirement to evaluation, providing a reproducible, modular process that any organization can adopt to construct production-grounded benchmarks for their own domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AlphaEval, a production-grounded benchmark consisting of 94 tasks sourced from seven companies deploying AI agents in core business operations, spanning six O*NET domains. It evaluates complete agent products (e.g., Claude Code, Codex) as commercial systems using multiple paradigms including LLM-as-a-Judge, reference-driven metrics, formal verification, rubric-based assessment, and automated UI testing. The central contribution is a requirement-to-benchmark construction framework that transforms authentic production requirements into executable evaluation tasks in a standardized, reproducible, and modular pipeline.
Significance. If the tasks and framework are shown to faithfully capture production complexities, this work could meaningfully advance agent evaluation by addressing the gap between synthetic, model-centric benchmarks and real commercial environments with implicit constraints, multi-modal inputs, and evolving expert judgment. The framework's reproducibility for other organizations is a potentially valuable methodological contribution.
major comments (2)
- [Abstract] Abstract: The central claim that the 94 tasks preserve implicit constraints, heterogeneous multi-modal inputs, undeclared domain expertise, long-horizon outputs, and evolving expert judgment standards is load-bearing but unsupported; no task selection criteria, concrete examples, validation against production realities, inter-rater reliability metrics, or quantitative results are provided to substantiate that the sourced tasks retain these properties.
- [Framework description] Framework description (throughout): The requirement-to-benchmark construction framework is presented as systematic and reproducible, yet the manuscript supplies no concrete steps, tools, time estimates, or worked examples demonstrating its application to the seven companies' requirements; this undermines the claim that any organization can adopt it.
minor comments (1)
- The six O*NET domains should be explicitly listed with brief descriptions to allow readers to assess domain coverage.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and are committed to revising the manuscript to incorporate the requested clarifications and details, which will strengthen the presentation of both the benchmark properties and the construction framework.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the 94 tasks preserve implicit constraints, heterogeneous multi-modal inputs, undeclared domain expertise, long-horizon outputs, and evolving expert judgment standards is load-bearing but unsupported; no task selection criteria, concrete examples, validation against production realities, inter-rater reliability metrics, or quantitative results are provided to substantiate that the sourced tasks retain these properties.
Authors: We agree that the abstract's claims regarding the preservation of production-specific properties require stronger substantiation in the manuscript. While the current text describes the sourcing from seven companies' core operations and contrasts these with synthetic benchmarks, we will add a new subsection in the benchmark construction section that explicitly details the task selection criteria (e.g., requirements must originate from live deployments with documented implicit constraints and multi-modal inputs). We will include two anonymized concrete task examples showing original requirements, input fragmentation, and long-horizon deliverables. Validation will be supported by reporting inter-rater reliability statistics (Cohen's kappa) from the domain experts involved in judgment, plus quantitative metrics comparing task properties (e.g., average input modalities, horizon steps) against existing benchmarks. These revisions will be added without altering the core claims. revision: yes
-
Referee: [Framework description] Framework description (throughout): The requirement-to-benchmark construction framework is presented as systematic and reproducible, yet the manuscript supplies no concrete steps, tools, time estimates, or worked examples demonstrating its application to the seven companies' requirements; this undermines the claim that any organization can adopt it.
Authors: We acknowledge that the framework is described at a high level as a modular, standardized pipeline but lacks the operational details needed for immediate adoption. In the revised manuscript, we will expand the framework section with a numbered step-by-step process covering requirement elicitation and anonymization, subtask decomposition, multi-modal packaging, multi-paradigm metric assignment, and iterative validation. For each step we will specify the tools used (e.g., scripting for UI automation and templated prompts for LLM-as-a-Judge), provide time estimates drawn from our construction process (approximately 3-5 person-hours per task for initial conversion), and include one fully worked, anonymized example from a single O*NET domain illustrating end-to-end application to a real company requirement. This will directly support the reproducibility claim. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces an empirical benchmark (AlphaEval) consisting of 94 tasks sourced from production environments and a requirement-to-benchmark construction framework. It contains no mathematical derivations, equations, fitted parameters, predictions, or self-referential definitions that could reduce to prior quantities by construction. The core claims rest on the description of the benchmark construction process and evaluation paradigms, which are presented as independent contributions without load-bearing self-citations or ansatzes that loop back to the paper's own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Authentic production requirements can be systematically transformed into executable evaluation tasks without losing key characteristics such as implicit constraints and evolving expert standards.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We present AlphaEval, a production-grounded benchmark of 94 tasks sourced from seven companies... requirement-to-benchmark construction framework... four-stage pipeline (partner engagement, requirement elicitation, task formalization, iterative validation)
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our evaluation framework covers multiple paradigms (LLM-as-a-Judge, reference-driven metrics, formal verification, rubric-based assessment, automated UI testing...)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeffrey Han, et al. 2025. Browsecomp: A simple yet challenging benchmark for browsing agents.arXiv preprint arXiv:2504.12516
work page internal anchor Pith review arXiv 2025
- [3]
- [4]
- [5]
-
[6]
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, et al. 2024. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments.arXiv preprint arXiv:2404.07972
work page internal anchor Pith review arXiv 2024
-
[7]
Frank F Xu et al. 2024. Theagentcompany: Benchmarking llm agents on consequential real world tasks.arXiv preprint arXiv:2412.14161
work page internal anchor Pith review arXiv 2024
- [8]
-
[9]
Qianyu Yang, Yang Liu, Jiaqi Li, Jun Bai, Hao Chen, Kaiyuan Chen, Tiliang Duan, Jiayun Dong, Xiaobo Hu, Zixia Jia, Yang Liu, Tao Peng, Yixin Ren, Ran Tian, Zaiyuan Wang, Yanglihong Xiao, Gang Yao, Lingyue Yin, Ge Zhang, Chun Zhang, Jianpeng Jiao, Zilong Zheng, and Yuan Gong. 2026. $onemillion-bench: How far are language agents from human experts?arXiv pre...
-
[10]
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. 2024. τ-bench: A benchmark for tool-agent-user interaction in real-world domains.arXiv preprint arXiv:2406.12045
work page internal anchor Pith review arXiv 2024
-
[11]
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, et al. 2023. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi.arXiv preprint arXiv:2311.16502
work page internal anchor Pith review arXiv 2023
- [12]
- [13]
-
[14]
Zhang, Joey Ji, Celeste Menders, Riya Dulepet, T
Andy K. Zhang, Joey Ji, Celeste Menders, Riya Dulepet, Thomas Qin, Ron Y . Wang, Junrong Wu, Kyleen Liao, Jiliang Li, Jinghan Hu, Sara Hong, Nardos Demilew, Shivatmica Murgai, Jason Tran, Nishka Kacheria, Ethan Ho, Denis Liu, Lauren McLane, Olivia Bruvik, Dai-Rong Han, Seungwoo Kim, Akhil Vyas, Cuiyuanxiu Chen, Ryan Li, Weiran Xu, Jonathan Z. Ye, Prerit C...
- [15]
-
[16]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P Xing, et al. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena. arXiv preprint arXiv:2306.05685. Published at NeurIPS 2023
work page internal anchor Pith review arXiv 2023
-
[17]
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, et al. 2024. Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854
work page internal anchor Pith review arXiv 2024
-
[18]
Does this step contain a critical error? Answer with only ‘yes’ or ‘no’
Mingchen Zhuge, Changsheng Zhao, Dylan Ashley, Wenyi Wang, Dmitrii Khizbullin, Yunyang Xiong, Zechun Liu, Ernie Chang, Raghuraman Krishnamoorthi, Yuandong Tian, Yangyang Shi, Vikas Chandra, and J¨urgen Schmidhuber. 2024. Agent-as-a-judge: Evaluate agents with agents.arXiv preprint arXiv:2410.10934. 16 A. Evaluation Infrastructure Details SII-GAIR A Evalua...
-
[19]
Automated evaluation platform construction(weight: 0.47): automated problem localization, iteration recommendations, and priority ranking
-
[20]
Objective evaluation standards(weight: 0.24): reliable product quality verification and performance bench- marking
-
[21]
no criteria
Cost and efficiency optimization(weight: 0.18): reducing testing costs, improving inference efficiency, and token cost control Survey Instrument.The questionnaire comprised 15 items covering product information (Q1–Q5), technical status (Q6–Q11), and evaluation needs (Q12–Q16). Key questions included: development stage (single choice), target customer typ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.