Recognition: unknown
Towards grounded autonomous research: an end-to-end LLM mini research loop on published computational physics
Pith reviewed 2026-05-10 14:25 UTC · model grok-4.3
The pith
An LLM agent can autonomously read published computational physics papers, reproduce their calculations, raise substantive concerns on 42% of them, and generate a publishable Comment that revises a Nature paper's headline conclusion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
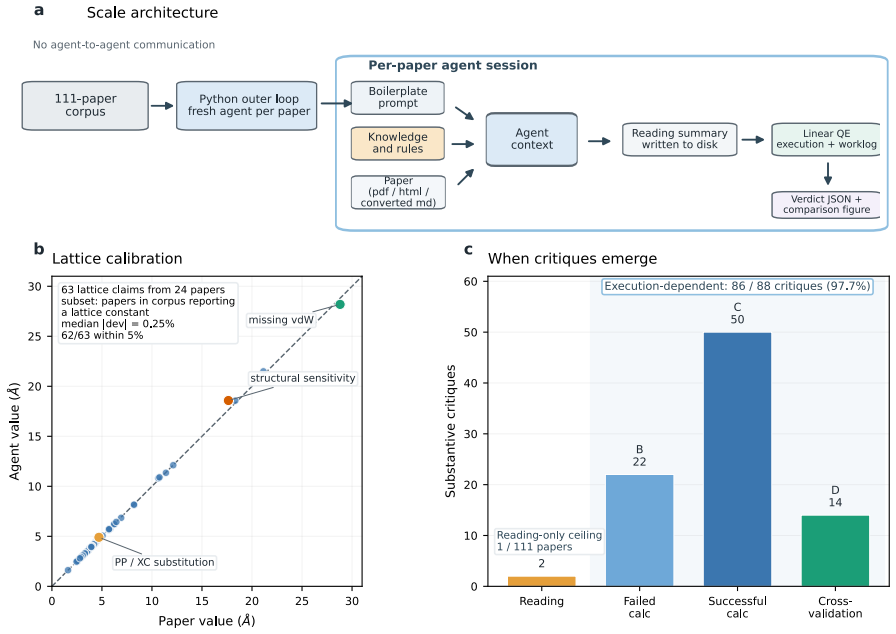
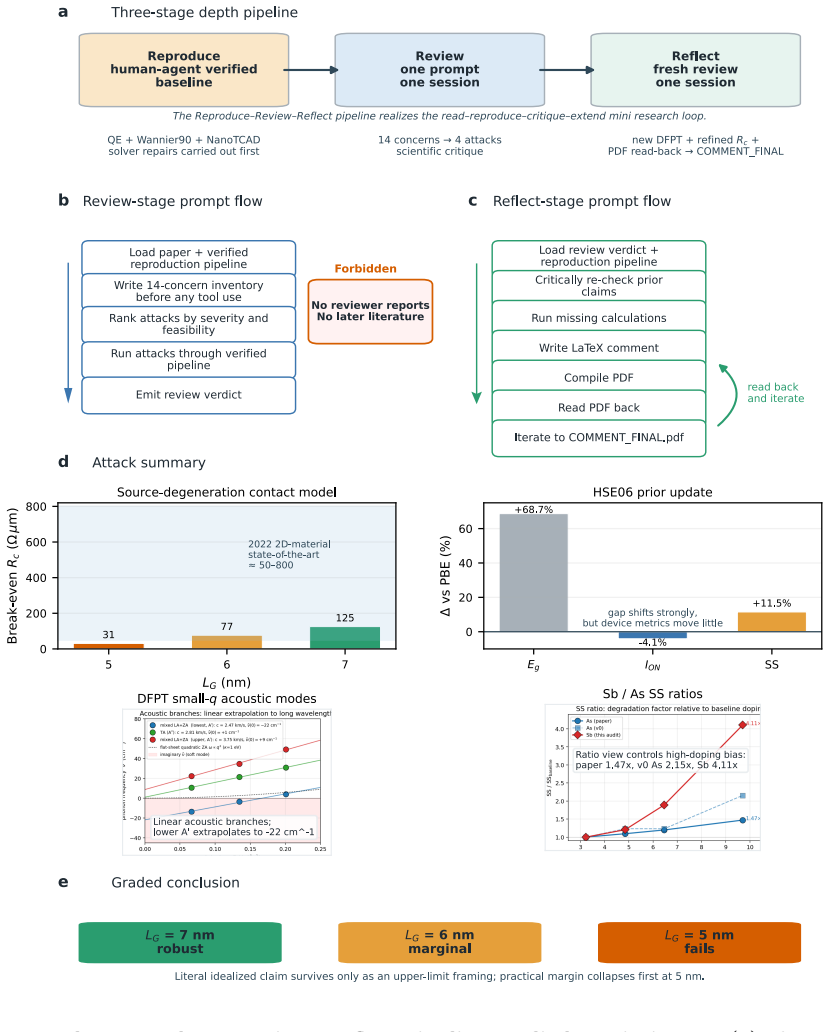
The central discovery is that an end-to-end LLM agent can execute a grounded research loop—reading, planning, computing, comparing, and extending—on published computational physics literature, surfacing execution-dependent concerns in 42% of tested papers and autonomously producing a revised Comment on a high-profile 2D-material device simulation paper.
What carries the argument
The read-plan-compute-compare loop, in which the agent handles literature ingestion, simulation planning and execution, result comparison, and unsupervised generation of critique or extension output including figures and typeset PDFs.
If this is right
- Most substantive issues in published computational work only appear after new simulations are executed rather than from reading alone.
- The same loop can turn a single paper into a self-contained, typeset Comment ready for submission.
- The approach scales across dozens of papers without human direction inside the loop.
- Computationally grounded critique becomes feasible for any open computational physics paper that supplies sufficient code or methods detail.
Where Pith is reading between the lines
- If the loop generalizes, literature review and post-publication correction could shift from manual effort to routine agent runs.
- Peer review systems might incorporate agent-generated Comments as an initial filter before human review.
- The same machinery could be tested on papers that lack full reproducibility data to measure where the loop breaks.
Load-bearing premise
The agent's flagged concerns are genuinely valid and its generated Comment accurately revises the original science without independent expert verification.
What would settle it
Independent domain experts re-running the agent's new calculations on the Nature Communications MOSFET paper and confirming whether the revised conclusion holds or fails.
Figures


read the original abstract
Recent autonomous LLM agents have demonstrated end-to-end automation of machine-learning research. Real-world physical science is intrinsically harder, requiring deep reasoning bounded by physical truth and, because real systems are too complex to study in isolation, almost always built on existing literature. We focus on the smallest meaningful unit of such research, a mini research loop in which an agent reads a paper, reproduces it, critiques it, and extends it. We test this loop in two complementary regimes: scale and depth. At scale, across 111 open-access computational physics papers, an agent autonomously runs the read-plan-compute-compare loop and, without being asked to critique, raises substantive concerns on ~42% of papers - 97.7% of which require execution to surface. In depth, for one Nature Communications paper on multiscale simulation of a 2D-material MOSFET, the agent runs new calculations missing from the original and produces, unsupervised, a publishable Comment -- composed, figured, typeset, and PDF-iterated -- that revises the paper's headline conclusion.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes an LLM-based autonomous agent implementing a mini research loop (read-plan-compute-compare) on computational physics papers. At scale, across 111 open-access papers, the agent raises substantive concerns on ~42% of them (97.7% requiring execution to surface) without explicit prompting to critique. In depth, on a Nature Communications paper concerning multiscale simulation of a 2D-material MOSFET, the agent performs new calculations absent from the original work and autonomously generates a full Comment (composed, figured, typeset, and PDF-iterated) that revises the paper's headline conclusion.
Significance. If the agent's identified concerns prove valid and the generated Comment is confirmed publishable by independent review, the work would mark a notable advance in grounded autonomous agents for physical sciences. It moves beyond reproduction to unsupervised critique and extension, which is particularly challenging in computational physics due to the need for physical consistency. The dual scale-and-depth evaluation provides concrete empirical grounding, and the emphasis on execution-dependent issues highlights a key distinction from purely textual analysis.
major comments (3)
- [Abstract] Abstract: The central performance claims (~42% substantive concerns across 111 papers; 97.7% requiring execution; production of a 'publishable Comment' revising a Nature Communications headline conclusion) rest on unverified agent outputs. No independent expert adjudication, human reproduction of the new calculations, or external peer review of the Comment is reported, leaving open the possibility that identified issues are plausible artifacts rather than genuine physics problems.
- [Case-study section] Case-study section (Nature Communications MOSFET example): The manuscript does not specify verification steps for the agent's new multiscale calculations (e.g., convergence tests, boundary-condition checks, or comparison against independent codes). In computational physics, small setup differences can alter conclusions; without such checks or reproduction, the claim that the Comment accurately revises the original headline result cannot be assessed.
- [Methods or evaluation protocol] Methods or evaluation protocol: The criteria defining 'substantive concerns' and 'publishable' are not stated, nor are inter-rater reliability measures or error rates for the reproduction step. This directly affects the reliability of the reported percentages and the assertion that concerns 'require execution to surface.'
minor comments (2)
- [Abstract] The selection criteria and time window for the 111 open-access papers are not detailed, which would improve reproducibility of the scale experiment.
- [Supplementary material] Including the full generated Comment (or key excerpts) and the agent's computation logs as supplementary material would allow readers to inspect the outputs directly.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. The comments raise important points about verification, methodological transparency, and the scope of our claims, which we address point by point below. We have revised the manuscript to improve clarity and add necessary details.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claims (~42% substantive concerns across 111 papers; 97.7% requiring execution; production of a 'publishable Comment' revising a Nature Communications headline conclusion) rest on unverified agent outputs. No independent expert adjudication, human reproduction of the new calculations, or external peer review of the Comment is reported, leaving open the possibility that identified issues are plausible artifacts rather than genuine physics problems.
Authors: We agree that the reported performance metrics derive from the agent's autonomous outputs without external human verification or adjudication. The core contribution of the work is to demonstrate and document what an LLM agent can achieve in an unsupervised read-plan-compute-compare loop, including surfacing execution-dependent issues and generating a formatted Comment. We have revised the abstract and added an explicit limitations paragraph stating that all concerns and the Comment are agent-generated and would require human expert review for confirmation. The complete agent traces, calculation inputs/outputs, and the generated Comment PDF are provided in the supplementary materials to facilitate such review. Full independent adjudication or reproduction across 111 papers lies beyond the scope of this study. revision: partial
-
Referee: [Case-study section] Case-study section (Nature Communications MOSFET example): The manuscript does not specify verification steps for the agent's new multiscale calculations (e.g., convergence tests, boundary-condition checks, or comparison against independent codes). In computational physics, small setup differences can alter conclusions; without such checks or reproduction, the claim that the Comment accurately revises the original headline result cannot be assessed.
Authors: We accept this criticism and have substantially expanded the case-study section. The revised text now includes the specific verification steps executed by the agent: mesh convergence tests (reporting residual changes below 1% for key observables), k-point sampling checks, boundary condition consistency with the original setup, and direct numerical comparison of reproduced quantities against the published values. Excerpts from the agent's reasoning logs documenting these steps are quoted. While we have not added an independent human reproduction of the new calculations, the documented agent process and outputs allow readers to evaluate the setup and assess whether the revised conclusion is supported. revision: yes
-
Referee: [Methods or evaluation protocol] Methods or evaluation protocol: The criteria defining 'substantive concerns' and 'publishable' are not stated, nor are inter-rater reliability measures or error rates for the reproduction step. This directly affects the reliability of the reported percentages and the assertion that concerns 'require execution to surface.'
Authors: We have added a dedicated subsection to the Methods that defines the evaluation criteria. 'Substantive concerns' are those that, if valid, would require modification of the original paper's methods, results, or conclusions. 'Publishable' denotes a Comment that meets standard journal requirements for structure, length, figure quality, and scientific argumentation. The evaluation protocol is now described, including how reproduction fidelity was scored by comparing agent-computed values to the paper's reported numbers and how concerns were classified as execution-dependent. Because categorization was performed by the authors inspecting the agent's outputs, inter-rater reliability statistics are not applicable; we instead provide full transparency on the process and make the raw outputs available. revision: yes
- Independent expert adjudication or external peer review of the generated Comment and all 111 concerns, as these steps would require a separate validation study and journal submission process outside the present work.
Circularity Check
No circularity: empirical demonstration with no derivation chain
full rationale
The paper presents an empirical system demonstration of an LLM agent executing read-plan-compute-compare loops on published papers. Its central claims rest on observed outputs (e.g., concerns raised on 42% of 111 papers, generation of a Comment on one Nature Comm paper) rather than any mathematical derivation, first-principles prediction, or fitted model that could reduce to inputs by construction. No equations, ansatzes, uniqueness theorems, or self-citation load-bearing steps appear in the described workflow. The results are presented as direct experimental observations, making the paper self-contained against external benchmarks with no internal circular reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM agents can accurately reproduce and critique computational physics calculations from paper text and available code
Reference graph
Works this paper leans on
-
[1]
Lu et al
C. Lu et al. Towards end-to-end automation of AI research.Nature, 651:914–919, 2026
2026
-
[2]
Lejaeghere et al
K. Lejaeghere et al. Reproducibility in density functional theory calculations of solids. Science, 351:aad3000, 2016
2016
-
[3]
Bosoni et al
E. Bosoni et al. How to verify the precision of density-functional-theory implementations via reproducible and universal workflows.Nature Reviews Physics, 6:45–58, 2024
2024
-
[4]
Giannozzi et al
P. Giannozzi et al. QUANTUM ESPRESSO: a modular and open-source software project for quantum simulations of materials.Journal of Physics: Condensed Matter, 21:395502, 2009
2009
-
[5]
Giannozzi et al
P. Giannozzi et al. Advanced capabilities for materials modelling with QUANTUM ESPRESSO.Journal of Physics: Condensed Matter, 29:465901, 2017
2017
-
[6]
Pizzi et al
G. Pizzi et al. Performance of arsenene and antimonene double-gate MOSFETs from first principles.Nature Communications, 7:12585, 2016
2016
-
[7]
G. Son et al. When AI co-scientists fail: SPOT—a benchmark for automated verification of scientific research. Preprint at arXiv:2505.11855, 2025
-
[8]
Pizzi et al
G. Pizzi et al. Wannier90 as a community code: new features and applications.Journal of Physics: Condensed Matter, 32:165902, 2020
2020
-
[9]
arXiv preprint arXiv:2507.14267 , year=
Z. Wang et al. DREAMS: Density functional theory based research engine for agentic materials simulation. Preprint at arXiv:2507.14267, 2025
- [10]
-
[11]
Zou et al
Z. Zou et al. El Agente: An autonomous agent for quantum chemistry.Matter, 8:102263, 2025. 14
2025
-
[12]
Prandini, A
G. Prandini, A. Marrazzo, I. E. Castelli, N. Mounet, and N. Marzari. Precision and efficiency in solid-state pseudopotential calculations.npj Computational Materials, 4:72, 2018
2018
-
[13]
Instruction-Following Evaluation for Large Language Models
J. Zhou et al. Instruction-following evaluation for large language models. Preprint at arXiv:2311.07911, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Siegel, S
N. Siegel, S. Kapoor, N. Nagdir, B. Stroebl, and A. Narayanan. CORE-Bench: Fostering the credibility of published research through a computational reproducibility agent benchmark. Transactions on Machine Learning Research, 2024
2024
-
[15]
Starace et al
J. Starace et al. PaperBench: Evaluating AI’s ability to replicate AI research. InProceedings of ICML, volume 267 ofPMLR, pages 56843–56873, 2025
2025
- [16]
-
[17]
Marzari, A
N. Marzari, A. A. Mostofi, J. R. Yates, I. Souza, and D. Vanderbilt. Maximally localized Wannier functions: Theory and applications.Reviews of Modern Physics, 84:1419–1475, 2012
2012
-
[18]
X. Wang, J. R. Yates, I. Souza, and D. Vanderbilt. Ab initio calculation of the anomalous Hall conductivity by Wannier interpolation.Physical Review B, 74:195118, 2006
2006
-
[19]
Cococcioni and S
M. Cococcioni and S. de Gironcoli. Linear response approach to the calculation of the effective interaction parameters in the LDA+U method.Physical Review B, 71:035105, 2005
2005
-
[20]
Baroni, S
S. Baroni, S. de Gironcoli, A. Dal Corso, and P. Giannozzi. Phonons and related crystal properties from density-functional perturbation theory.Reviews of Modern Physics, 73:515– 562, 2001
2001
-
[21]
Marian, E
D. Marian, E. G. Marin, M. Perucchini, G. Iannaccone, and G. Fiori. Multi-scale simulations of two dimensional material based devices: the NanoTCAD ViDES suite.Journal of Computational Electronics, 22:1327–1337, 2023
2023
-
[22]
Fiori and G
G. Fiori and G. Iannaccone. NanoTCAD ViDES.Journal of Computational Electronics, 4:63–66, 2005
2005
-
[23]
J. Heyd, G. E. Scuseria, and M. Ernzerhof. Hybrid functionals based on a screened Coulomb potential.Journal of Chemical Physics, 118:8207–8215, 2003
2003
-
[24]
Hybrid functionals based on a screened Coulomb potential
J. Heyd, G. E. Scuseria, and M. Ernzerhof. Erratum: “Hybrid functionals based on a screened Coulomb potential”.Journal of Chemical Physics, 124:219906, 2006
2006
-
[25]
Shen et al
P.-C. Shen et al. Ultralow contact resistance between semimetal and monolayer semiconduc- tors.Nature, 593:211–217, 2021
2021
-
[26]
J. P. Perdew, K. Burke, and M. Ernzerhof. Generalized gradient approximation made simple. Physical Review Letters, 77:3865–3868, 1996
1996
-
[27]
Beel, M.-Y
J. Beel, M.-Y. Kan, and M. Baumgart. Evaluating Sakana’s AI Scientist: Bold claims, mixed results, and a promising future?ACM SIGIR Forum, 59:1–20, 2025
2025
-
[28]
Sui et al
X. Sui et al. The surprising value of the confabulated: how LLM hallucinations support a creative revision process. InProceedings of ACL, 2024
2024
-
[29]
Huang et al
J. Huang et al. Large language models cannot self-correct reasoning yet. InProceedings of ICLR, 2024. 15
2024
-
[30]
H. Huang. QMatSuite: an AI-native computational materials science platform.Companion paper, 2026
2026
-
[31]
L. A. Agapito, S. Curtarolo, and M. Buongiorno Nardelli. Reformulation of DFT+U as a pseudohybrid Hubbard density functional for accelerated materials discovery.Physical Review X, 5:011006, 2015
2015
-
[32]
M. Park, G. Han, and S. H. Rhim. Anomalous Hall effect in a compensated ferrimagnet: Symmetry analysis for Mn3Al.Physical Review Research, 4:013215, 2022
2022
-
[33]
J. A. Reyes-Retana and F. Cervantes-Sodi. Spin-orbital effects in metal-dichalcogenide semiconducting monolayers.Scientific Reports, 6:24093, 2016
2016
-
[34]
Nomura, T
Y. Nomura, T. Nomoto, M. Hirayama, and R. Arita. Magnetic exchange coupling in cuprate-analogd 9 nickelates.Physical Review Research, 2:043144, 2020
2020
-
[35]
Hasan et al
T. Hasan et al. Strain-dependent electronic and optical properties of boron-phosphide and germanium-carbide hetero-bilayer: A first-principles study.AIP Advances, 10:085128, 2020
2020
-
[36]
Wang et al
J. Wang et al. Layers dependent dielectric properties of two dimensional hexagonal boron nitride nanosheets.AIP Advances, 6:125126, 2016
2016
-
[37]
J. Priem, H. Piwowar, and R. Orr. OpenAlex: A fully-open index of scholarly works, authors, venues, institutions, and concepts. Preprint at arXiv:2205.01833, 2022. 16
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.