Recognition: unknown
Learning Project-wise Subsequent Code Edits via Interleaving Neural-based Induction and Tool-based Deduction
Pith reviewed 2026-05-10 15:02 UTC · model grok-4.3
The pith
TRACE interleaves neural predictions for semantic code changes with tool-based deduction for syntactic fixes to improve project-wide edits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
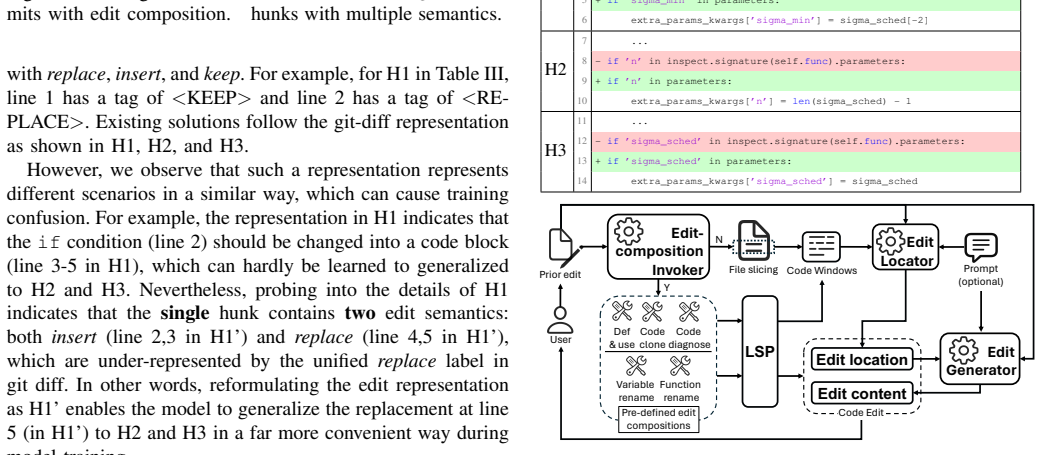
The central claim is that code edits arise from either semantic or syntactic triggers, so interleaving neural induction for the former with tool-based deduction for the latter, combined with a learned detector for tool invocation and a fine-grained editing representation, enables better prediction of subsequent project-wise edits in terms of scope, accuracy, and efficiency.
What carries the argument
TRACE interleaves neural-based induction for semantic edit prediction with tool-based deduction for syntactic edits, using a neural switch to decide tool calls and a fine-grained representation to improve neural output.
If this is right
- Cross-file edits become feasible at higher accuracy than local-only models like Cursor.
- Prediction speed increases by delegating syntactic details to fast IDE tools instead of pure neural generation.
- The method extends to any available IDE facilities such as refactoring or linting tools.
- Overall developer productivity rises for tasks spanning multiple files.
Where Pith is reading between the lines
- The hybrid switch might lower reliance on ever-larger language models for routine syntax handling.
- Similar interleaving could apply to editing other structured artifacts like configuration files or documentation.
- If the switch proves robust, it opens a path for IDEs to expose more internal tools as reliable oracles for AI assistants.
Load-bearing premise
Code edits split cleanly into semantic versus syntactic reasons, and a neural model can reliably learn when to call IDE tools while the fine-grained representation measurably improves results.
What would settle it
An experiment on a held-out set of real developer edit sequences where the learned switch invokes tools on fewer than half the syntactic cases or where removing the fine-grained representation leaves neural accuracy unchanged or lower.
Figures





read the original abstract
In industrial and open-source software engineering tasks, developers often perform project-wise code editing tasks, including feature enhancement, refactoring, and bug fixing, where the leading AI models are expected to support the productivity. Hence, researchers and practitioners have proposed and adopted many LLM-based solutions to facilitate their real-world development. However, they largely suffer from the balance among predicting scope, accuracy, and efficiency. For example, solutions like Cursor achieve high accuracy only in a local editing scope while its performance drops on cross-file edits. In contrast, solutions like CoEdPilot exhibit efficiency limitations when used to predict project-wise edits. In this work, we propose TRACE (Tool-integrated RecommendAtion for Code Editing), a novel subsequent code editing solution to push the boundary of scope, accuracy, and efficiency. Our rationale lies in that code edits are triggered for either semantic or syntactic reasons. Therefore, TRACE predicts subsequent edits by interleaving neural-based induction for semantic edit prediction and tool-based deduction for syntactic edit prediction. The tools can be any IDE facilities, such as refactoring tools (e.g., rename) or linting tools (e.g., use-def), providing decent performance of deducing edit-location and edit-generation. Technically, we address the challenge of (1) when to interleave between neural-based and tool-based prediction and (2) how to further improve the performance of neural-based prediction. As for the former, we learn a neural model to detect when to invoke IDE editing tools. As for the latter, we propose a novel and fine-grained editing representation to further boost the performance of neural editing models. ......
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TRACE, a hybrid system for predicting subsequent project-wise code edits. It interleaves neural-based induction (for edits triggered by semantic reasons) with tool-based deduction (for syntactic reasons, using IDE facilities like refactoring or linting tools). The approach learns a detector for when to invoke tools and introduces a fine-grained editing representation to improve neural prediction performance, aiming to balance scope, accuracy, and efficiency beyond pure LLM baselines like Cursor (limited cross-file scope) or CoEdPilot (efficiency issues).
Significance. If the interleaving strategy and detector prove reliable, TRACE could meaningfully advance AI-assisted software engineering by combining the flexibility of neural models with the precision of deterministic IDE tools. This hybrid paradigm addresses a practical pain point in large-scale refactoring and bug fixing, and the fine-grained representation may offer a reusable technical contribution for edit prediction tasks.
major comments (2)
- [Abstract, §3] Abstract and §3 (approach): The central rationale—that edits have cleanly separable semantic vs. syntactic triggers, with a learned neural detector reliably deciding the switch—is load-bearing for the interleaving claim, yet the manuscript provides no explicit definition of the two categories, no labeling protocol for training data, and no analysis of mixed edits (e.g., a rename that also changes control flow). Without this, the detector's decision boundary remains unverified and the pipeline's robustness is unclear.
- [§4, §5] §4 (evaluation) and §5 (results): The abstract asserts improvements in scope, accuracy, and efficiency, but the provided text contains no quantitative results, ablation studies on the interleaving detector, or comparisons isolating the contribution of the fine-grained representation versus the tool integration. Load-bearing claims therefore rest on unshown evidence.
minor comments (2)
- [§3.2] Notation for the fine-grained editing representation should be formalized with a clear schema or example in §3.2 to aid reproducibility.
- [Introduction] The abstract mentions 'project-wise' edits but does not define the scope (e.g., number of files or dependency distance); this should be stated explicitly in the introduction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on TRACE. The comments highlight areas where we can improve clarity around our core assumptions and strengthen the empirical support for our claims. We address each point below and will revise the manuscript to incorporate the suggested clarifications and additional analyses.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (approach): The central rationale—that edits have cleanly separable semantic vs. syntactic triggers, with a learned neural detector reliably deciding the switch—is load-bearing for the interleaving claim, yet the manuscript provides no explicit definition of the two categories, no labeling protocol for training data, and no analysis of mixed edits (e.g., a rename that also changes control flow). Without this, the detector's decision boundary remains unverified and the pipeline's robustness is unclear.
Authors: We agree that explicit definitions and supporting details are essential to substantiate the interleaving rationale. In the revised manuscript, we will expand §3 with precise definitions: semantic edits are those that modify program behavior or developer intent (e.g., logic changes for bug fixes or feature additions), while syntactic edits preserve semantics and can be derived via deterministic rules (e.g., renames or lint fixes). We will also describe the labeling protocol used to train the detector, including how edit pairs from our dataset were annotated according to these categories and any measures of annotation reliability. Finally, we will add an analysis of mixed edits, reporting their frequency in the data and explaining the detector's handling (typically routing to neural induction when semantic components are present). These additions will make the decision boundary verifiable and demonstrate robustness. revision: yes
-
Referee: [§4, §5] §4 (evaluation) and §5 (results): The abstract asserts improvements in scope, accuracy, and efficiency, but the provided text contains no quantitative results, ablation studies on the interleaving detector, or comparisons isolating the contribution of the fine-grained representation versus the tool integration. Load-bearing claims therefore rest on unshown evidence.
Authors: We acknowledge that the evaluation must fully substantiate the abstract's claims with visible evidence. While §5 of the manuscript reports quantitative comparisons of TRACE against baselines such as Cursor and CoEdPilot on scope, accuracy, and efficiency metrics, we agree that dedicated ablations and isolations are needed. In the revision, we will expand §5 to include ablation studies on the interleaving detector (e.g., variants with and without the learned switch) and controlled experiments isolating the fine-grained editing representation's contribution from the tool-based components. These will be presented in additional tables and figures to directly support the improvements claimed. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes TRACE as an engineering system that interleaves a learned neural detector (for deciding when to invoke IDE tools on syntactic edits) with neural induction on a new fine-grained edit representation (for semantic edits). No equations, predictions, or central claims reduce by construction to fitted parameters, self-defined quantities, or load-bearing self-citations; the interleaving logic and representation are presented as independent technical contributions whose performance is evaluated externally rather than derived tautologically from the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Code edits are triggered for either semantic or syntactic reasons.
Reference graph
Works this paper leans on
-
[1]
Codebert: A pre-trained model for programming and natural languages,
Z. Feng, D. Guo, D. Tang, N. Duan, X. Feng, M. Gong, L. Shou, B. Qin, T. Liu, D. Jiang, et al., “Codebert: A pre-trained model for programming and natural languages,” EMNLP, 2020
2020
-
[2]
Graphcodebert: Pre-training code rep- resentations with data flow,
D. Guo, S. Ren, S. Lu, Z. Feng, D. Tang, S. Liu, L. Zhou, N. Duan, A. Svyatkovskiy, S. Fu, et al. , “Graphcodebert: Pre-training code rep- resentations with data flow,” The International Conference on Learning Representations, 2020
2020
-
[3]
Y . Wang, W. Wang, S. Joty, and S. C. Hoi, “Codet5: Identifier-aware unified pre-trained encoder-decoder models for code understanding and generation,” arXiv preprint arXiv:2109.00859 , 2021
work page internal anchor Pith review arXiv 2021
-
[4]
GitHub Copilot,
GitHub, “GitHub Copilot,” 2023
2023
-
[5]
Chatgpt
OpenAI, “Chatgpt.” https://openai.com/chatgpt, 2021. Accessed on March 29, 2023
2021
-
[6]
A study of repetitiveness of code changes in software evolution,
H. A. Nguyen, A. T. Nguyen, T. T. Nguyen, T. N. Nguyen, and H. Rajan, “A study of repetitiveness of code changes in software evolution,” in 2013 28th IEEE/ACM International Conference on Automated Software Engineering (ASE), pp. 180–190, IEEE, 2013
2013
-
[7]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems , vol. 30, 2017
2017
-
[8]
Grace: Language models meet code edits,
P. Gupta, A. Khare, Y . Bajpai, S. Chakraborty, S. Gulwani, A. Kanade, A. Radhakrishna, G. Soares, and A. Tiwari, “Grace: Language models meet code edits,” in Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering , ESEC/FSE 2023, (New York, NY , USA), p. 1483–1495, Association f...
2023
-
[9]
Cct5: A code- change-oriented pre-trained model,
B. Lin, S. Wang, Z. Liu, Y . Liu, X. Xia, and X. Mao, “Cct5: A code- change-oriented pre-trained model,” arXiv preprint arXiv:2305.10785 , 2023
-
[10]
CoditT5: Pretraining for source code and natural language editing,
J. Zhang, S. Panthaplackel, P. Nie, J. J. Li, and M. Gligoric, “CoditT5: Pretraining for source code and natural language editing,” in Interna- tional Conference on Automated Software Engineering , 2022
2022
-
[11]
On multi-modal learning of editing source code,
S. Chakraborty and B. Ray, “On multi-modal learning of editing source code,” in 2021 36th IEEE/ACM International Conference on Automated Software Engineering (ASE) , (Los Alamitos, CA, USA), pp. 443–455, IEEE Computer Society, nov 2021
2021
-
[12]
Cursor - The AI Code Editor
“Cursor - The AI Code Editor.” https://www.cursor.com/, 2025. [Ac- cessed 25-02-2025]
2025
-
[13]
Introducing Copilot Edits (preview)
“Introducing Copilot Edits (preview).” https://code.visualstudio.com/ blogs/2024/11/12/introducing-copilot-edits/, 2024. [Accessed 03-08- 2024]
2024
-
[14]
Coedpilot: Recommending code edits with learned prior edit relevance, project-wise awareness, and interactive nature,
C. Liu, Y . Cai, Y . Lin, Y . Huang, Y . Pei, B. Jiang, P. Yang, J. S. Dong, and H. Mei, “Coedpilot: Recommending code edits with learned prior edit relevance, project-wise awareness, and interactive nature,” in Proceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis , ISSTA 2024, (New York, NY , USA), p. 466–478, Asso...
2024
-
[15]
Z. Xu, S. Jain, and M. Kankanhalli, “Hallucination is inevitable: An innate limitation of large language models,” arXiv preprint arXiv:2401.11817, 2024
-
[16]
Do code llms do static analysis?,
C.-Y . Su and C. McMillan, “Do code llms do static analysis?,” arXiv preprint arXiv:2505.12118, 2025
-
[17]
Git - git-diff Documentation
“Git - git-diff Documentation.” https://git-scm.com/docs/git-diff, 2024. [Accessed 12-09-2024]
2024
-
[18]
Visual Studio Code Extension API
“Visual Studio Code Extension API.” https://code.visualstudio.com/api, 2024
2024
-
[19]
TRACE — sites.google.com
“TRACE — sites.google.com.” https://sites.google.com/view/code-trace,
-
[20]
[Accessed 02-08-2024]
2024
-
[21]
Swe-agent: Agent-computer interfaces enable automated soft- ware engineering,
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. Narasimhan, and O. Press, “Swe-agent: Agent-computer interfaces enable automated soft- ware engineering,” Advances in Neural Information Processing Systems, vol. 37, pp. 50528–50652, 2024
2024
-
[22]
Autocoderover: Autonomous program improvement,
Y . Zhang, H. Ruan, Z. Fan, and A. Roychoudhury, “Autocoderover: Autonomous program improvement,” in Proceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis , pp. 1592–1604, 2024
2024
-
[23]
K. Zhang, J. Li, G. Li, X. Shi, and Z. Jin, “Codeagent: Enhancing code generation with tool-integrated agent systems for real-world repo-level coding challenges,” arXiv preprint arXiv:2401.07339 , 2024
-
[24]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. Narasimhan, “Swe-bench: Can language models resolve real-world github issues?,” arXiv preprint arXiv:2310.06770 , 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Tree-sitter Introduction — tree-sitter.github.io
“Tree-sitter Introduction — tree-sitter.github.io.” https://tree-sitter. github.io/tree-sitter/, 2024. [Accessed 01-08-2024]
2024
-
[26]
Masked language model scoring,
J. Salazar, D. Liang, T. Q. Nguyen, and K. Kirchhoff, “Masked language model scoring,” arXiv preprint arXiv:1910.14659 , 2019
-
[27]
An empirical study of bm25 and bm25f based feature location techniques,
Z. Shi, J. Keung, and Q. Song, “An empirical study of bm25 and bm25f based feature location techniques,” in Proceedings of the International Workshop on Innovative Software Development Methodologies and Practices, pp. 106–114, 2014
2014
-
[28]
Sequence to Sequence Learning with Neural Networks
I. Sutskever, “Sequence to sequence learning with neural networks,” arXiv preprint arXiv:1409.3215 , 2014
work page Pith review arXiv 2014
-
[29]
Beam search strategies for neural machine translation,
M. Freitag and Y . Al-Onaizan, “Beam search strategies for neural machine translation,” in Proceedings of the First Workshop on Neural Machine Translation, (Vancouver), pp. 56–60, Association for Compu- tational Linguistics, Aug. 2017
2017
-
[30]
Llama 3 model card,
AI@Meta, “Llama 3 model card,” 2024
2024
-
[31]
GitHub - rapidfuzz/RapidFuzz
“GitHub - rapidfuzz/RapidFuzz.” https://rapidfuzz.github.io/RapidFuzz/,
-
[32]
[Accessed 12-09-2024]
2024
-
[33]
Salesforce/codet5-large · Hugging Face — huggingface.co
“Salesforce/codet5-large · Hugging Face — huggingface.co.” https: //huggingface.co/Salesforce/codet5-large, 2024. [Accessed 01-08-2024]
2024
-
[34]
Bleu: a method for automatic evaluation of machine translation,
K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, “Bleu: a method for automatic evaluation of machine translation,” in Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pp. 311–318, 2002
2002
-
[35]
microsoft/pyright: Static Type Checker for Python
“microsoft/pyright: Static Type Checker for Python.” https://github.com/ microsoft/pyright, 2024. [Accessed 22-03-2025]
2024
-
[36]
tools/gopls at master
“tools/gopls at master.” https://github.com/golang/tools/tree/master/ gopls, 2024. [Accessed 22-03-2025]
2024
-
[37]
eclipse-jdtls/eclipse.jdt.ls: Java language server
“eclipse-jdtls/eclipse.jdt.ls: Java language server.” https://github.com/ eclipse-jdtls/eclipse.jdt.ls, 2024. [Accessed 22-03-2025]
2024
-
[38]
typescript-language-server/typescript-language-server: Type- Script & JavaScript Language Server
“typescript-language-server/typescript-language-server: Type- Script & JavaScript Language Server.” https://github.com/ typescript-language-server/typescript-language-server, 2024. [Accessed 22-03-2025]
2024
-
[39]
Fix up if http in : to be more sensible startswiths, AUTOMATIC1111/stable-diffusion-webui
“Fix up if http in : to be more sensible startswiths, AUTOMATIC1111/stable-diffusion-webui.” https://github. com/AUTOMATIC1111/stable-diffusion-webui/commit/ 0afbc0c2355ead3a0ce7149a6d678f1f2e2fbfee, 2024. [Accessed 12-09-2024]
2024
-
[40]
Add a flag to control the number of train examples. tensorflow/models
“Add a flag to control the number of train examples. tensorflow/models.” https://github.com/tensorflow/models/commit/ 1c89b792ccdb53dd0cc2504f3bce502e5f0aa4e5, 2024. [Accessed 12-09-2024]
2024
-
[41]
Add noise shape and seed to Dropout layer API. keras- team/keras
“Add noise shape and seed to Dropout layer API. keras- team/keras.” https://github.com/keras-team/keras/commit/ 8c0c3774e6cf88704f685784f8baba9694220d4d, 2024. [Accessed 12-09-2024]
2024
-
[42]
On the accuracy of spectrum-based fault localization,
R. Abreu, P. Zoeteweij, and A. J. Van Gemund, “On the accuracy of spectrum-based fault localization,” in Testing: Academic and industrial conference practice and research techniques-MUTATION (TAICPART- MUTATION 2007), pp. 89–98, IEEE, 2007
2007
-
[43]
Localizing failure-inducing program edits based on spectrum information,
L. Zhang, M. Kim, and S. Khurshid, “Localizing failure-inducing program edits based on spectrum information,” in 2011 27th IEEE International Conference on Software Maintenance (ICSM) , pp. 23–32, IEEE, 2011
2011
-
[44]
Effective fault localization using code coverage,
W. E. Wong, Y . Qi, L. Zhao, and K.-Y . Cai, “Effective fault localization using code coverage,” in 31st Annual International Computer Software and Applications Conference (COMPSAC 2007) , vol. 1, pp. 449–456, IEEE, 2007
2007
-
[45]
Ask the mutants: Mutating faulty programs for fault localization,
S. Moon, Y . Kim, M. Kim, and S. Yoo, “Ask the mutants: Mutating faulty programs for fault localization,” in 2014 IEEE Seventh Inter- national Conference on Software Testing, Verification and Validation , pp. 153–162, IEEE, 2014
2014
-
[46]
Metallaxis-fl: mutation-based fault localization,
M. Papadakis and Y . Le Traon, “Metallaxis-fl: mutation-based fault localization,” Software Testing, Verification and Reliability , vol. 25, no. 5-7, pp. 605–628, 2015
2015
-
[47]
A deep dive into large language models for automated bug localization and repair,
S. B. Hossain, N. Jiang, Q. Zhou, X. Li, W.-H. Chiang, Y . Lyu, H. Nguyen, and O. Tripp, “A deep dive into large language models for automated bug localization and repair,” Proceedings of the ACM on Software Engineering, vol. 1, no. FSE, pp. 1471–1493, 2024
2024
-
[48]
Large language models for test-free fault localization,
A. Z. Yang, C. Le Goues, R. Martins, and V . Hellendoorn, “Large language models for test-free fault localization,” in Proceedings of the 46th IEEE/ACM International Conference on Software Engineering , pp. 1–12, 2024
2024
-
[49]
Lase: An example-based program transformation tool for locating and applying systematic edits,
J. Jacobellis, N. Meng, and M. Kim, “Lase: An example-based program transformation tool for locating and applying systematic edits,” in 2013 35th International Conference on Software Engineering (ICSE) , pp. 1319–1322, IEEE, 2013
2013
-
[50]
Clone-based and interactive recommendation for modifying pasted code,
Y . Lin, X. Peng, Z. Xing, D. Zheng, and W. Zhao, “Clone-based and interactive recommendation for modifying pasted code,” in Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering, pp. 520–531, 2015
2015
-
[51]
Lever: Learning to verify language-to-code generation with execution,
A. Ni, S. Iyer, D. Radev, V . Stoyanov, W.-t. Yih, S. Wang, and X. V . Lin, “Lever: Learning to verify language-to-code generation with execution,” in International Conference on Machine Learning , pp. 26106–26128, PMLR, 2023
2023
-
[52]
Automated program refinement: Guide and verify code large language model with refinement calculus,
Y . Cai, Z. Hou, D. San ´an, X. Luan, Y . Lin, J. Sun, and J. S. Dong, “Automated program refinement: Guide and verify code large language model with refinement calculus,” Proceedings of the ACM on Program- ming Languages, vol. 9, no. POPL, pp. 2057–2089, 2025
2057
-
[53]
On-the-fly adapting code summarization on trainable cost-effective language models,
Y . Cai, Y . Lin, C. Liu, J. Wu, Y . Zhang, Y . Liu, Y . Gong, and J. S. Dong, “On-the-fly adapting code summarization on trainable cost-effective language models,” Advances in Neural Information Processing Systems , vol. 36, 2024
2024
-
[54]
Codamosa: Escaping coverage plateaus in test generation with pre-trained large language models,
C. Lemieux, J. P. Inala, S. K. Lahiri, and S. Sen, “Codamosa: Escaping coverage plateaus in test generation with pre-trained large language models,” in 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), pp. 919–931, IEEE, 2023
2023
-
[55]
Generating Project-Specific Test Cases with Requirement Validation Intention
B. Qi, Y . Lin, X. Weng, Y . Huang, C. Liu, H. Sun, and J. S. Dong, “Intention-driven generation of project-specific test cases,” arXiv preprint arXiv:2507.20619, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Api-knowledge aware search-based software testing: where, what, and how,
X. Ren, X. Ye, Y . Lin, Z. Xing, S. Li, and M. R. Lyu, “Api-knowledge aware search-based software testing: where, what, and how,” inProceed- ings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering , pp. 1320– 1332, 2023
2023
-
[57]
Graph-based seed object synthesis for search-based unit testing,
Y . Lin, Y . S. Ong, J. Sun, G. Fraser, and J. S. Dong, “Graph-based seed object synthesis for search-based unit testing,” inProceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, pp. 1068–1080, 2021
2021
-
[58]
Recovering fit- ness gradients for interprocedural boolean flags in search-based testing,
Y . Lin, J. Sun, G. Fraser, Z. Xiu, T. Liu, and J. S. Dong, “Recovering fit- ness gradients for interprocedural boolean flags in search-based testing,” in Proceedings of the 29th ACM SIGSOFT International Symposium on Software Testing and Analysis , pp. 440–451, 2020
2020
-
[59]
Guipilot: A consistency-based mobile gui testing approach for detecting application-specific bugs,
R. Liu, X. Teoh, Y . Lin, G. Chen, R. Ren, D. Poshyvanyk, and J. S. Dong, “Guipilot: A consistency-based mobile gui testing approach for detecting application-specific bugs,” Proceedings of the ACM on Software Engineering, vol. 2, no. ISSTA, pp. 753–776, 2025
2025
-
[60]
Edit-run behavior in programming and debugging,
A. Alaboudi and T. D. LaToza, “Edit-run behavior in programming and debugging,” in2021 IEEE Symposium on Visual Languages and Human- Centric Computing (VL/HCC) , pp. 1–10, IEEE, 2021
2021
-
[61]
Codit: Code editing with tree-based neural models,
S. Chakraborty, Y . Ding, M. Allamanis, and B. Ray, “Codit: Code editing with tree-based neural models,” IEEE Transactions on Software Engineering, vol. 48, no. 4, pp. 1385–1399, 2022
2022
-
[62]
A syntax-guided edit decoder for neural program repair,
Q. Zhu, Z. Sun, Y .-a. Xiao, W. Zhang, K. Yuan, Y . Xiong, and L. Zhang, “A syntax-guided edit decoder for neural program repair,” inProceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/FSE 2021, (New York, NY , USA), p. 341–353, Association for Computing Machi...
2021
-
[63]
Cure: Code-aware neural machine translation for automatic program repair,
N. Jiang, T. Lutellier, and L. Tan, “Cure: Code-aware neural machine translation for automatic program repair,” in 2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE) , pp. 1161– 1173, 2021
2021
-
[64]
Overwatch: Learning patterns in code edit sequences,
Y . Zhang, Y . Bajpai, P. Gupta, A. Ketkar, M. Allamanis, T. Barik, S. Gulwani, A. Radhakrishna, M. Raza, G. Soares, and A. Tiwari, “Overwatch: Learning patterns in code edit sequences,” Proc. ACM Program. Lang., vol. 6, oct 2022
2022
-
[65]
Better context makes better code language models: A case study on function call argument completion,
H. Pei, J. Zhao, L. Lausen, S. Zha, and G. Karypis, “Better context makes better code language models: A case study on function call argument completion,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 37, pp. 5230–5238, 2023
2023
-
[66]
Contextmodule: Improving code completion via repository- level contextual information,
Z. Guan, J. Liu, J. Liu, C. Peng, D. Liu, N. Sun, B. Jiang, W. Li, J. Liu, and H. Zhu, “Contextmodule: Improving code completion via repository- level contextual information,” arXiv preprint arXiv:2412.08063 , 2024
-
[67]
Statically contextualizing large language models with typed holes,
A. Blinn, X. Li, J. H. Kim, and C. Omar, “Statically contextualizing large language models with typed holes,” Proceedings of the ACM on Programming Languages, vol. 8, no. OOPSLA2, pp. 468–498, 2024
2024
-
[68]
Static analysis as a feedback loop: Enhancing llm-generated code beyond correctness,
S. Blyth, S. A. Licorish, C. Treude, and M. Wagner, “Static analysis as a feedback loop: Enhancing llm-generated code beyond correctness,” arXiv preprint arXiv:2508.14419 , 2025
-
[69]
IRIS: LLM-assisted static analysis for de- tecting security vulnerabilities,
Z. Li, S. Dutta, and M. Naik, “Iris: Llm-assisted static analysis for detecting security vulnerabilities,” arXiv preprint arXiv:2405.17238 , 2024
-
[70]
Enhancing static analysis for practical bug detection: An llm-integrated approach,
H. Li, Y . Hao, Y . Zhai, and Z. Qian, “Enhancing static analysis for practical bug detection: An llm-integrated approach,” Proceedings of the ACM on Programming Languages, vol. 8, no. OOPSLA1, pp. 474–499, 2024
2024
-
[71]
Codeplan: Repository-level coding using llms and planning,
R. Bairi, A. Sonwane, A. Kanade, A. Iyer, S. Parthasarathy, S. Rajamani, B. Ashok, and S. Shet, “Codeplan: Repository-level coding using llms and planning,” Proceedings of the ACM on Software Engineering, vol. 1, no. FSE, pp. 675–698, 2024
2024
-
[72]
Marscode agent: Ai-native automated bug fixing,
Y . Liu, P. Gao, X. Wang, J. Liu, Y . Shi, Z. Zhang, and C. Peng, “Marscode agent: Ai-native automated bug fixing,” arXiv preprint arXiv:2409.00899, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.