Recognition: unknown
BarbieGait: An Identity-Consistent Synthetic Human Dataset with Versatile Cloth-Changing for Gait Recognition
Pith reviewed 2026-05-10 15:11 UTC · model grok-4.3
The pith
A synthetic dataset maps real people to virtual characters with extensive clothing changes while preserving gait identity, enabling better cross-clothing recognition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
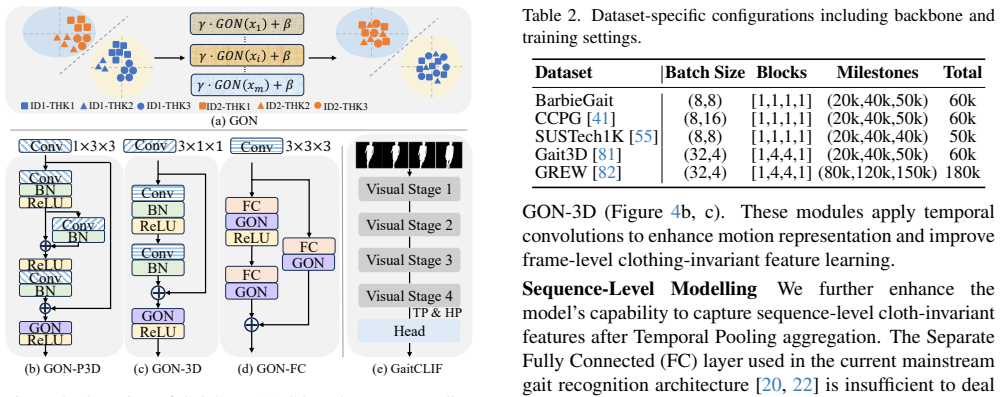
BarbieGait is a synthetic gait dataset where real-world subjects are uniquely mapped into a virtual engine to simulate extensive clothing changes while preserving their gait identity information. It offers a controllable generation method that produces large datasets for validating cross-clothing problems difficult to study with real data alone. GaitCLIF is introduced as a robust baseline model for learning cloth-invariant features, and experiments confirm it significantly improves cross-clothing performance on BarbieGait and existing popular gait benchmarks.
What carries the argument
BarbieGait identity-consistent virtual mapping combined with GaitCLIF for extracting cloth-invariant gait features.
If this is right
- Gait recognition systems can be trained on controllable synthetic variations to reduce the impact of clothing on identity matching.
- Large-scale datasets with systematic clothing changes become feasible without collecting new real-world footage for every outfit.
- Baseline models like GaitCLIF can serve as starting points for extracting features that generalize across clothing styles.
- Existing gait benchmarks can be augmented with synthetic examples to boost their cross-clothing robustness.
- Progress in related biometric tasks that suffer from appearance variation can draw on the same controllable synthesis approach.
Where Pith is reading between the lines
- If the identity preservation holds, the same mapping technique could generate paired data for studying other gait covariates like speed or viewpoint.
- Hybrid training that mixes real and BarbieGait synthetic samples might further close the gap to real-world deployment.
- The controllable clothing changes allow targeted ablation studies on which clothing attributes most degrade recognition.
- Downstream applications such as surveillance or security could adopt the dataset to pre-train models before fine-tuning on limited real data.
Load-bearing premise
The synthetic mapping from real subjects to virtual characters accurately preserves gait identity information across clothing changes.
What would settle it
Training models on BarbieGait and testing them on real-world cross-clothing gait datasets shows no improvement or a drop in accuracy compared to training on real data alone.
Figures







read the original abstract
Gait recognition, as a reliable biometric technology, has seen rapid development in recent years while it faces significant challenges caused by diverse clothing styles in the real world. This paper introduces BarbieGait, a synthetic gait dataset where real-world subjects are uniquely mapped into a virtual engine to simulate extensive clothing changes while preserving their gait identity information. As a pioneering work, BarbieGait provides a controllable gait data generation method, enabling the production of large datasets to validate cross-clothing issues that are difficult to verify with real-world data. However, the diversity of clothing increases intra-class variance and makes one of the biggest challenges to learning cloth-invariant features under varying clothing conditions. Therefore, we propose GaitCLIF (Gait-oriented CLoth-Invariant Feature) as a robust baseline model for cross-clothing gait recognition. Through extensive experiments, we validate that our method significantly improves cross-clothing performance on BarbieGait and the existing popular gait benchmarks. We believe that BarbieGait, with its extensive cross-clothing gait data, will further advance the capabilities of gait recognition in cross-clothing scenarios and promote progress in related research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BarbieGait, a synthetic gait dataset created by uniquely mapping real-world subjects into a virtual 3D engine to generate extensive clothing variations while preserving gait identity information. It proposes GaitCLIF as a baseline model for learning cloth-invariant features and reports that extensive experiments show significant improvements in cross-clothing gait recognition performance on BarbieGait as well as on existing popular gait benchmarks.
Significance. If the real-to-virtual mapping accurately preserves subject-specific gait cues independent of clothing simulation and the reported gains generalize beyond the synthetic setting, the dataset would offer a valuable controllable resource for studying and mitigating clothing-induced variance in gait recognition, an area where large-scale real data is hard to obtain. The explicit focus on cloth-changing diversity and the provision of a new baseline model are constructive contributions.
major comments (2)
- [§3] §3 (BarbieGait Dataset Construction): The central premise that the real-to-virtual mapping 'preserves their gait identity information' is stated without any quantitative validation, such as feature-level comparisons (stride length, joint angles, or embedding distances) or cross-domain recognition tests between real and synthetic sequences of the same subjects. This directly affects whether performance gains on BarbieGait can be attributed to cloth-invariance rather than artifacts of the simulation.
- [§5] §5 (Experiments): The claim of 'significantly improves cross-clothing performance' on BarbieGait and existing benchmarks lacks reported controls for the synthetic-to-real domain gap (e.g., no real-to-synthetic transfer results, no domain-adaptation baselines, and no error bars or statistical significance tests across multiple runs). Without these, it is unclear whether the gains are robust or specific to the synthetic distribution.
minor comments (2)
- [Abstract / §1] The abstract and introduction would benefit from a brief comparison to prior synthetic gait datasets (e.g., those using SMPL or other body models) to clarify the novelty of the identity-consistent mapping.
- [§4] Notation for the GaitCLIF loss terms and clothing variation parameters should be defined more explicitly in §4 to avoid ambiguity when reproducing the baseline.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address the two major comments point by point below and will revise the manuscript to incorporate additional quantitative validation and statistical reporting.
read point-by-point responses
-
Referee: [§3] §3 (BarbieGait Dataset Construction): The central premise that the real-to-virtual mapping 'preserves their gait identity information' is stated without any quantitative validation, such as feature-level comparisons (stride length, joint angles, or embedding distances) or cross-domain recognition tests between real and synthetic sequences of the same subjects. This directly affects whether performance gains on BarbieGait can be attributed to cloth-invariance rather than artifacts of the simulation.
Authors: We agree that the manuscript would be strengthened by explicit quantitative evidence that the real-to-virtual mapping preserves gait identity. The construction process maps real subjects into the virtual engine using subject-specific motion parameters while varying clothing independently; however, no feature-level or cross-domain comparisons are currently reported. In the revised version we will add stride-length and joint-angle similarity metrics, embedding-distance statistics, and preliminary cross-domain recognition results between real and synthetic sequences of the same subjects. revision: yes
-
Referee: [§5] §5 (Experiments): The claim of 'significantly improves cross-clothing performance' on BarbieGait and existing benchmarks lacks reported controls for the synthetic-to-real domain gap (e.g., no real-to-synthetic transfer results, no domain-adaptation baselines, and no error bars or statistical significance tests across multiple runs). Without these, it is unclear whether the gains are robust or specific to the synthetic distribution.
Authors: The improvements reported on real-world benchmarks already provide evidence that the learned features are not confined to the synthetic distribution. We did not include real-to-synthetic transfer experiments or domain-adaptation baselines because the primary contribution is a controllable synthetic resource and a cloth-invariant baseline rather than a domain-adaptation study. In the revision we will add error bars and statistical significance tests (e.g., paired t-tests over multiple random seeds) for all reported results. revision: partial
Circularity Check
No circularity: empirical validation on new dataset plus external benchmarks is self-contained
full rationale
The paper constructs a synthetic dataset by mapping real subjects to virtual characters while asserting identity preservation, then trains and evaluates GaitCLIF on that dataset together with existing public gait benchmarks. No equations, parameters, or derivations are shown that reduce a claimed result to a fitted quantity on the same data or to a self-citation chain. The identity-preservation statement is an input assumption of the data-generation pipeline rather than a derived output that loops back to itself. Performance gains are reported as measured quantities on held-out synthetic sequences and independent benchmarks, satisfying the criteria for a non-circular empirical claim.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Makehuman community. 2020. makehuman: Open source tool for making 3d characters.http : / / www . makehumancommunity.org. 3, 4
2020
-
[2]
Easymocap - make human motion capture easier. Github,
-
[3]
Comparison between euler and quaternion parametrization in uav dynamics
Andrea Alaimo, Valeria Artale, C Milazzo, and Angela Ricciardello. Comparison between euler and quaternion parametrization in uav dynamics. InAIP Conference Pro- ceedings, pages 1228–1231. American Institute of Physics,
-
[4]
Posetrack: A benchmark for human pose estima- tion and tracking
Mykhaylo Andriluka, Umar Iqbal, Eldar Insafutdinov, Leonid Pishchulin, Anton Milan, Juergen Gall, and Bernt Schiele. Posetrack: A benchmark for human pose estima- tion and tracking. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5167–5176,
-
[5]
Eduard Gabriel Bazavan, Andrei Zanfir, Mihai Zanfir, William T Freeman, Rahul Sukthankar, and Cristian Smin- chisescu. Hspace: Synthetic parametric humans animated in complex environments.arXiv preprint arXiv:2112.12867,
-
[6]
Disentangled diffusion-based 3d human pose estimation with hierarchical spatial and temporal de- noiser
Qingyuan Cai, Xuecai Hu, Saihui Hou, Li Yao, and Yongzhen Huang. Disentangled diffusion-based 3d human pose estimation with hierarchical spatial and temporal de- noiser. InProceedings of the AAAI Conference on Artificial Intelligence, pages 882–890, 2024
2024
-
[7]
Qingyuan Cai, Linxin Zhang, Xuecai Hu, Saihui Hou, and Yongzhen Huang. Fastddhpose: Towards unified, efficient, and disentangled 3d human pose estimation.arXiv preprint arXiv:2512.14162, 2025
-
[8]
Playing for 3d human re- covery.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
Zhongang Cai, Mingyuan Zhang, Jiawei Ren, Chen Wei, Daxuan Ren, Zhengyu Lin, Haiyu Zhao, Lei Yang, Chen Change Loy, and Ziwei Liu. Playing for 3d human re- covery.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024. 2, 4
2024
-
[9]
Learning style-invariant robust representation for generaliz- able visual instance retrieval
Tianyu Chang, Xun Yang, Xin Luo, Wei Ji, and Meng Wang. Learning style-invariant robust representation for generaliz- able visual instance retrieval. InProceedings of the 31st ACM International Conference on Multimedia, pages 6171– 6180, 2023. 5
2023
-
[10]
Gaitset: Regarding gait as a set for cross-view gait recognition
Hanqing Chao, Yiwei He, Junping Zhang, and Jianfeng Feng. Gaitset: Regarding gait as a set for cross-view gait recognition. InProceedings of the AAAI conference on arti- ficial intelligence, pages 8126–8133, 2019. 3, 7, 8
2019
-
[11]
Meta batch-instance normalization for generalizable person re-identification
Seokeon Choi, Taekyung Kim, Minki Jeong, Hyoungseob Park, and Changick Kim. Meta batch-instance normalization for generalizable person re-identification. InProceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 3425–3435, 2021. 5
2021
-
[12]
Blender - a 3d modelling and rendering package, 2018
Blender Community. Blender - a 3d modelling and rendering package, 2018. 3
2018
-
[13]
Openmmlab pose estimation tool- box and benchmark.https://github.com/open- mmlab/mmpose, 2020
MMPose Contributors. Openmmlab pose estimation tool- box and benchmark.https://github.com/open- mmlab/mmpose, 2020. 2
2020
-
[14]
Mevid: Multi-view extended videos with identities for video per- son re-identification
Daniel Davila, Dawei Du, Bryon Lewis, Christopher Funk, Joseph Van Pelt, Roderic Collins, Kellie Corona, Matt Brown, Scott McCloskey, Anthony Hoogs, et al. Mevid: Multi-view extended videos with identities for video per- son re-identification. InProceedings of the IEEE/CVF Win- ter Conference on Applications of Computer Vision, pages 1634–1643, 2023. 1
2023
-
[15]
Hybridgait: A bench- mark for spatial-temporal cloth-changing gait recognition with hybrid explorations
Yilan Dong, Chunlin Yu, Ruiyang Ha, Ye Shi, Yuexin Ma, Lan Xu, Yanwei Fu, and Jingya Wang. Hybridgait: A bench- mark for spatial-temporal cloth-changing gait recognition with hybrid explorations. InProceedings of the AAAI Con- ference on Artificial Intelligence, pages 1600–1608, 2024. 2, 1
2024
-
[16]
Gaitpart: Temporal part-based model for gait recognition
Chao Fan, Yunjie Peng, Chunshui Cao, Xu Liu, Saihui Hou, Jiannan Chi, Yongzhen Huang, Qing Li, and Zhiqiang He. Gaitpart: Temporal part-based model for gait recognition. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 14225–14233, 2020. 3, 5, 7, 8
2020
-
[17]
Ex- ploring deep models for practical gait recognition.arXiv preprint arXiv:2303.03301, 2023
Chao Fan, Saihui Hou, Yongzhen Huang, and Shiqi Yu. Ex- ploring deep models for practical gait recognition.arXiv preprint arXiv:2303.03301, 2023
-
[18]
Opengait: Revisiting gait recognition towards better practicality
Chao Fan, Junhao Liang, Chuanfu Shen, Saihui Hou, Yongzhen Huang, and Shiqi Yu. Opengait: Revisiting gait recognition towards better practicality. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9707–9716, 2023. 3, 6, 7, 8, 1
2023
-
[19]
Skeletongait: Gait recognition using skeleton maps
Chao Fan, Jingzhe Ma, Dongyang Jin, Chuanfu Shen, and Shiqi Yu. Skeletongait: Gait recognition using skeleton maps. InProceedings of the AAAI Conference on Artificial Intelligence, pages 1662–1669, 2024. 3, 7, 8, 2
2024
-
[20]
Open- gait: A comprehensive benchmark study for gait recognition towards better practicality.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
Chao Fan, Saihui Hou, Junhao Liang, Chuanfu Shen, Jingzhe Ma, Dongyang Jin, Yongzhen Huang, and Shiqi Yu. Open- gait: A comprehensive benchmark study for gait recognition towards better practicality.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025. 3, 6, 7, 8, 1
2025
-
[21]
Gpgait: Generalized pose-based gait recognition
Yang Fu, Shibei Meng, Saihui Hou, Xuecai Hu, and Yongzhen Huang. Gpgait: Generalized pose-based gait recognition. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 19595–19604, 2023. 3, 7
2023
-
[22]
Cut out the middleman: Revisiting pose-based gait recognition
Yang Fu, Saihui Hou, Shibei Meng, Xuecai Hu, Chunshui Cao, Xu Liu, and Yongzhen Huang. Cut out the middleman: Revisiting pose-based gait recognition. InEuropean Confer- ence on Computer Vision, pages 112–128. Springer, 2025. 3
2025
-
[23]
Clothes-changing person re-identification with rgb modality only
Xinqian Gu, Hong Chang, Bingpeng Ma, Shutao Bai, Shiguang Shan, and Xilin Chen. Clothes-changing person re-identification with rgb modality only. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1060–1069, 2022. 1
2022
-
[24]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll´ar, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000– 16009, 2022. 2
2022
-
[25]
Saihui Hou, Chenye Wang, Wenpeng Lang, Zhengxiang Lan, and Yongzhen Huang. Gaitsnippet: Gait recognition be- yond unordered sets and ordered sequences.arXiv preprint arXiv:2508.07782, 2025. 3
-
[26]
The devil is in the details: Delving into unbiased data processing for human pose estimation
Junjie Huang, Zheng Zhu, Feng Guo, and Guan Huang. The devil is in the details: Delving into unbiased data processing for human pose estimation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5700–5709, 2020. 2
2020
-
[27]
Occluded gait recognition with mixture of experts: an action detection perspective
Panjian Huang, Yunjie Peng, Saihui Hou, Chunshui Cao, Xu Liu, Zhiqiang He, and Yongzhen Huang. Occluded gait recognition with mixture of experts: an action detection perspective. InEuropean Conference on Computer Vision, pages 380–397. Springer, 2024. 3, 5, 8
2024
-
[28]
V ocabulary-guided gait recognition
Panjian Huang, Saihui Hou, Chunshui Cao, Xu Liu, and Yongzhen Huang. V ocabulary-guided gait recognition. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[29]
Learning a unified template for gait recognition
Panjian Huang, Saihui Hou, Junzhou Huang, and Yongzhen Huang. Learning a unified template for gait recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 12459–12469, 2025. 3
2025
-
[30]
Catalin Ionescu, Dragos Papava, Vlad Olaru, and Cristian Sminchisescu. Human3. 6m: Large scale datasets and pre- dictive methods for 3d human sensing in natural environ- ments.IEEE transactions on pattern analysis and machine intelligence, 36(7):1325–1339, 2013. 2
2013
-
[31]
arXiv preprint arXiv:2303.07399 (2023)
Tao Jiang, Peng Lu, Li Zhang, Ningsheng Ma, Rui Han, Chengqi Lyu, Yining Li, and Kai Chen. Rtmpose: Real- time multi-person pose estimation based on mmpose.arXiv preprint arXiv:2303.07399, 2023. 2
-
[32]
Dy- namically transformed instance normalization network for generalizable person re-identification
Bingliang Jiao, Lingqiao Liu, Liying Gao, Guosheng Lin, Lu Yang, Shizhou Zhang, Peng Wang, and Yanning Zhang. Dy- namically transformed instance normalization network for generalizable person re-identification. InEuropean confer- ence on computer vision, pages 285–301. Springer, 2022. 5
2022
-
[33]
On denoising walking videos for gait recognition
Dongyang Jin, Chao Fan, Jingzhe Ma, Jingkai Zhou, Wei- hua Chen, and Shiqi Yu. On denoising walking videos for gait recognition. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 12347–12357, 2025. 3
2025
-
[34]
Style normalization and restitution for generalizable person re-identification
Xin Jin, Cuiling Lan, Wenjun Zeng, Zhibo Chen, and Li Zhang. Style normalization and restitution for generalizable person re-identification. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3143–3152, 2020. 5
2020
-
[35]
Learning 3d human dynamics from video
Angjoo Kanazawa, Jason Y Zhang, Panna Felsen, and Jiten- dra Malik. Learning 3d human dynamics from video. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 5614–5623, 2019. 2
2019
-
[36]
Beyond sparse keypoints: Dense pose modeling for robust gait recog- nition
Wenpeng Lang, Saihui Hou, and Yongzhen Huang. Beyond sparse keypoints: Dense pose modeling for robust gait recog- nition. InProceedings of the 33rd ACM International Con- ference on Multimedia, pages 669–678, 2025. 3, 8, 2
2025
-
[37]
Gait recognition with drones: A benchmark.IEEE Transactions on Multimedia, 2023
Aoqi Li, Saihui Hou, Qingyuan Cai, Yang Fu, and Yongzhen Huang. Gait recognition with drones: A benchmark.IEEE Transactions on Multimedia, 2023. 3
2023
-
[38]
Aerialgait: Bridging aerial and ground views for gait recognition
Aoqi Li, Saihui Hou, Chenye Wang, Qingyuan Cai, and Yongzhen Huang. Aerialgait: Bridging aerial and ground views for gait recognition. InProceedings of the 32nd ACM International Conference on Multimedia, pages 1139–1147,
-
[39]
An in-depth ex- ploration of person re-identification and gait recognition in cloth-changing conditions
Weijia Li, Saihui Hou, Chunjie Zhang, Chunshui Cao, Xu Liu, Yongzhen Huang, and Yao Zhao. An in-depth ex- ploration of person re-identification and gait recognition in cloth-changing conditions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13824–13833, 2023. 2, 4, 6, 7
2023
-
[40]
A model-based gait recognition method with body pose and human prior knowledge.Pattern Recognition, 98:107069,
Rijun Liao, Shiqi Yu, Weizhi An, and Yongzhen Huang. A model-based gait recognition method with body pose and human prior knowledge.Pattern Recognition, 98:107069,
-
[41]
Gaitgl: Learning discriminative global-local feature representations for gait recognition,
Beibei Lin, Shunli Zhang, Ming Wang, Lincheng Li, and Xin Yu. Gaitgl: Learning discriminative global-local fea- ture representations for gait recognition.arXiv preprint arXiv:2208.01380, 2022. 3, 7
-
[42]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pages 740–755. Springer, 2014. 8, 2
2014
-
[43]
Yi Liu, Lutao Chu, Guowei Chen, Zewu Wu, Zeyu Chen, Baohua Lai, and Yuying Hao. Paddleseg: A high-efficient development toolkit for image segmentation.arXiv preprint arXiv:2101.06175, 2021. 5
-
[44]
Matthew Loper, Naureen Mahmood, Javier Romero, Ger- ard Pons-Moll, and Michael J. Black. SMPL: A skinned multi-person linear model.ACM Trans. Graphics (Proc. SIGGRAPH Asia), 34(6):248:1–248:16, 2015. 2, 4
2015
-
[45]
Amass: Archive of motion capture as surface shapes
Naureen Mahmood, Nima Ghorbani, Nikolaus F Troje, Ger- ard Pons-Moll, and Michael J Black. Amass: Archive of motion capture as surface shapes. InProceedings of the IEEE/CVF international conference on computer vision, pages 5442–5451, 2019. 2
2019
-
[46]
Makihara, H
Y . Makihara, H. Mannami, A. Tsuji, M.A. Hossain, K. Sug- iura, A. Mori, and Y . Yagi. The ou-isir gait database com- prising the treadmill dataset.IPSJ Trans. on Computer Vision and Applications, 4:53–62, 2012. 1
2012
-
[47]
Seeing from magic mirror: Contrastive learning from reconstruction for pose-based gait recognition
Shibei Meng, Saihui Hou, Yang Fu, Xuecai Hu, Junzhou Huang, and Yongzhen Huang. Seeing from magic mirror: Contrastive learning from reconstruction for pose-based gait recognition. InProceedings of the 33rd ACM International Conference on Multimedia, pages 7719–7728, 2025. 2
2025
-
[48]
Two at once: Enhancing learning and generalization capacities via ibn-net
Xingang Pan, Ping Luo, Jianping Shi, and Xiaoou Tang. Two at once: Enhancing learning and generalization capacities via ibn-net. InProceedings of the european conference on computer vision (ECCV), pages 464–479, 2018. 5
2018
-
[49]
Agora: Avatars in geography optimized for regression analysis
Priyanka Patel, Chun-Hao P Huang, Joachim Tesch, David T Hoffmann, Shashank Tripathi, and Michael J Black. Agora: Avatars in geography optimized for regression analysis. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 13468–13478, 2021. 2, 4
2021
-
[50]
Expressive body capture: 3d hands, face, and body from a single image
Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed AA Osman, Dimitrios Tzionas, and Michael J Black. Expressive body capture: 3d hands, face, and body from a single image. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10975–10985, 2019. 3
2019
-
[51]
Cross view fusion for 3d human pose estimation
Haibo Qiu, Chunyu Wang, Jingdong Wang, Naiyan Wang, and Wenjun Zeng. Cross view fusion for 3d human pose estimation. InProceedings of the IEEE/CVF international conference on computer vision, pages 4342–4351, 2019. 3
2019
-
[52]
On the Convergence of Adam and Beyond
Sashank J Reddi, Satyen Kale, and Sanjiv Kumar. On the convergence of adam and beyond.arXiv preprint arXiv:1904.09237, 2019. 2
work page Pith review arXiv 1904
-
[53]
Lidargait: Benchmarking 3d gait recognition with point clouds
Chuanfu Shen, Chao Fan, Wei Wu, Rui Wang, George Q Huang, and Shiqi Yu. Lidargait: Benchmarking 3d gait recognition with point clouds. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1054–1063, 2023. 2, 6, 7
2023
-
[54]
Casia-e: a large comprehensive dataset for gait recognition.IEEE transactions on pattern analysis and ma- chine intelligence, 45(3):2801–2815, 2022
Chunfeng Song, Yongzhen Huang, Weining Wang, and Liang Wang. Casia-e: a large comprehensive dataset for gait recognition.IEEE transactions on pattern analysis and ma- chine intelligence, 45(3):2801–2815, 2022. 4
2022
-
[55]
Multi-view large popu- lation gait dataset and its performance evaluation for cross- view gait recognition.IPSJ transactions on Computer Vision and Applications, 10:1–14, 2018
Noriko Takemura, Yasushi Makihara, Daigo Muramatsu, Tomio Echigo, and Yasushi Yagi. Multi-view large popu- lation gait dataset and its performance evaluation for cross- view gait recognition.IPSJ transactions on Computer Vision and Applications, 10:1–14, 2018. 2, 4
2018
-
[56]
Gaitgraph: Graph convo- lutional network for skeleton-based gait recognition
Torben Teepe, Ali Khan, Johannes Gilg, Fabian Herzog, Ste- fan H¨ormann, and Gerhard Rigoll. Gaitgraph: Graph convo- lutional network for skeleton-based gait recognition. In2021 IEEE international conference on image processing (ICIP), pages 2314–2318. IEEE, 2021. 3, 7
2021
-
[57]
Towards a deeper under- standing of skeleton-based gait recognition
Torben Teepe, Johannes Gilg, Fabian Herzog, Stefan H¨ormann, and Gerhard Rigoll. Towards a deeper under- standing of skeleton-based gait recognition. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1569–1577, 2022. 3, 7
2022
-
[58]
Learning from synthetic humans
Gul Varol, Javier Romero, Xavier Martin, Naureen Mah- mood, Michael J Black, Ivan Laptev, and Cordelia Schmid. Learning from synthetic humans. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 109–117, 2017. 2, 4
2017
-
[59]
Recovering ac- curate 3d human pose in the wild using imus and a moving camera
Timo V on Marcard, Roberto Henschel, Michael J Black, Bodo Rosenhahn, and Gerard Pons-Moll. Recovering ac- curate 3d human pose in the wild using imus and a moving camera. InProceedings of the European conference on com- puter vision (ECCV), pages 601–617, 2018. 2
2018
-
[60]
Ra-gar: A richly annotated benchmark for gait attribute recognition
Chenye Wang, Saihui Hou, Aoqi Li, Qingyuan Cai, and Yongzhen Huang. Ra-gar: A richly annotated benchmark for gait attribute recognition. InProceedings of the AAAI Con- ference on Artificial Intelligence, pages 7591–7599, 2025. 2
2025
-
[61]
Deep high-resolution repre- sentation learning for visual recognition.IEEE transactions on pattern analysis and machine intelligence, 43(10):3349– 3364, 2020
Jingdong Wang, Ke Sun, Tianheng Cheng, Borui Jiang, Chaorui Deng, Yang Zhao, Dong Liu, Yadong Mu, Mingkui Tan, Xinggang Wang, et al. Deep high-resolution repre- sentation learning for visual recognition.IEEE transactions on pattern analysis and machine intelligence, 43(10):3349– 3364, 2020. 3, 5, 8, 2
2020
-
[62]
Surpassing real-world source training data: Random 3d characters for generalizable person re-identification
Yanan Wang, Shengcai Liao, and Ling Shao. Surpassing real-world source training data: Random 3d characters for generalizable person re-identification. InProceedings of the 28th ACM international conference on multimedia, pages 3422–3430, 2020. 2, 3, 4
2020
-
[63]
Gaitparsing: Human semantic parsing for gait recognition.IEEE Transactions on Multime- dia, 26:4736–4748, 2023
Zengbin Wang, Saihui Hou, Man Zhang, Xu Liu, Chunshui Cao, and Yongzhen Huang. Gaitparsing: Human semantic parsing for gait recognition.IEEE Transactions on Multime- dia, 26:4736–4748, 2023. 5
2023
-
[64]
Gait- x: Exploring x modality for generalized gait recognition
Zengbin Wang, Saihui Hou, Junjie Li, Xu Liu, Chunshui Cao, Yongzhen Huang, Siye Wang, and Man Zhang. Gait- x: Exploring x modality for generalized gait recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 13259–13269, 2025. 3
2025
-
[65]
Butterworth-Heinemann, 2014
Michael W Whittle.Gait analysis: an introduction. Butterworth-Heinemann, 2014. 6
2014
-
[66]
David A Winter.Biomechanics and motor control of human gait: normal, elderly and pathological. 1991. 6
1991
-
[67]
Rethinking illumi- nation for person re-identification: A unified view
Suncheng Xiang, Guanjie You, Leqi Li, Mengyuan Guan, Ting Liu, Dahong Qian, and Yuzhuo Fu. Rethinking illumi- nation for person re-identification: A unified view. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4731–4739, 2022. 3, 4
2022
-
[68]
Ghum & ghuml: Generative 3d human shape and articulated pose models
Hongyi Xu, Eduard Gabriel Bazavan, Andrei Zanfir, William T Freeman, Rahul Sukthankar, and Cristian Smin- chisescu. Ghum & ghuml: Generative 3d human shape and articulated pose models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6184–6193, 2020. 3
2020
-
[69]
Vit- pose: Simple vision transformer baselines for human pose estimation.Advances in Neural Information Processing Sys- tems, 35:38571–38584, 2022
Yufei Xu, Jing Zhang, Qiming Zhang, and Dacheng Tao. Vit- pose: Simple vision transformer baselines for human pose estimation.Advances in Neural Information Processing Sys- tems, 35:38571–38584, 2022. 8, 2, 3
2022
-
[70]
Bridging gait recognition and large language models sequence modeling
Shaopeng Yang, Jilong Wang, Saihui Hou, Xu Liu, Chun- shui Cao, Liang Wang, and Yongzhen Huang. Bridging gait recognition and large language models sequence modeling. InProceedings of the Computer Vision and Pattern Recogni- tion Conference, pages 3460–3469, 2025. 3
2025
-
[71]
Synbody: Synthetic dataset with layered human models for 3d human perception and modeling
Zhitao Yang, Zhongang Cai, Haiyi Mei, Shuai Liu, Zhaoxi Chen, Weiye Xiao, Yukun Wei, Zhongfei Qing, Chen Wei, Bo Dai, et al. Synbody: Synthetic dataset with layered human models for 3d human perception and modeling. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 20282–20292, 2023. 2, 4
2023
-
[72]
Biggait: Learning gait representation you want by large vision models
Dingqiang Ye, Chao Fan, Jingzhe Ma, Xiaoming Liu, and Shiqi Yu. Biggait: Learning gait representation you want by large vision models. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 200–210, 2024. 3
2024
-
[73]
Dingqiang Ye, Chao Fan, Zhanbo Huang, Chengwen Luo, Jianqiang Li, Shiqi Yu, and Xiaoming Liu. Biggergait: Un- locking gait recognition with layer-wise representations from large vision models.arXiv preprint arXiv:2505.18132, 2025. 3
-
[74]
A framework for evaluating the effect of view angle, clothing and carrying condition on gait recognition
Shiqi Yu, Daoliang Tan, and Tieniu Tan. A framework for evaluating the effect of view angle, clothing and carrying condition on gait recognition. In18th international con- ference on pattern recognition (ICPR’06), pages 441–444. IEEE, 2006. 2, 4
2006
-
[75]
Spatial transformer network on skeleton-based gait recognition.Expert Systems, 40(6):e13244, 2023
Cun Zhang, Xing-Peng Chen, Guo-Qiang Han, and Xiang- Jie Liu. Spatial transformer network on skeleton-based gait recognition.Expert Systems, 40(6):e13244, 2023. 3, 7
2023
-
[76]
Direct multi-view multi-person 3d pose estimation
Jianfeng Zhang, Yujun Cai, Shuicheng Yan, Jiashi Feng, et al. Direct multi-view multi-person 3d pose estimation. Advances in Neural Information Processing Systems, 34: 13153–13164, 2021. 6
2021
-
[77]
A large- scale synthetic gait dataset towards in-the-wild simulation and comparison study.ACM Transactions on Multimedia Computing, Communications and Applications, 19(1):1–23,
Pengyi Zhang, Huanzhang Dou, Wenhu Zhang, Yuhan Zhao, Zequn Qin, Dongping Hu, Yi Fang, and Xi Li. A large- scale synthetic gait dataset towards in-the-wild simulation and comparison study.ACM Transactions on Multimedia Computing, Communications and Applications, 19(1):1–23,
-
[78]
Unrealperson: An adap- tive pipeline towards costless person re-identification
Tianyu Zhang, Lingxi Xie, Longhui Wei, Zijie Zhuang, Yongfei Zhang, Bo Li, and Qi Tian. Unrealperson: An adap- tive pipeline towards costless person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 11506–11515, 2021. 2, 3, 4
2021
-
[79]
Gait recognition in the wild with dense 3d representations and a benchmark
Jinkai Zheng, Xinchen Liu, Wu Liu, Lingxiao He, Cheng- gang Yan, and Tao Mei. Gait recognition in the wild with dense 3d representations and a benchmark. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20228–20237, 2022. 2, 4, 6, 7
2022
-
[80]
Gait recognition in the wild: A benchmark
Zheng Zhu, Xianda Guo, Tian Yang, Junjie Huang, Jiankang Deng, Guan Huang, Dalong Du, Jiwen Lu, and Jie Zhou. Gait recognition in the wild: A benchmark. InProceedings of the IEEE/CVF international conference on computer vi- sion, pages 14789–14799, 2021. 2, 4, 6
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.