Recognition: unknown
LightMat-HP: A Photonic-Electronic System for Accelerating General Matrix Multiplication With Configurable Precision
Pith reviewed 2026-05-10 14:29 UTC · model grok-4.3
The pith
A hybrid photonic-electronic system accelerates general matrix multiplication with configurable precision by slicing low-bit photonic operations inside block floating-point arithmetic.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
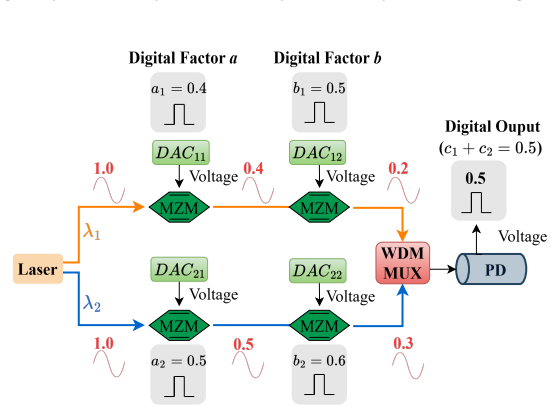
LightMat-HP is a hybrid photonic-electronic computing system that accelerates general matrix multiplication with configurable precision. It uses block floating-point arithmetic together with a slicing-based photonic multiplication scheme that performs accurate low bit-width photonic operations and accumulates the slices digitally to reach higher-precision mantissa results. A tile-based dataflow handles matrices of arbitrary size. Validation on a photonic computing prototype plus large-scale simulations shows that LightMat-HP outperforms FPGA, GPU, and state-of-the-art photonic accelerators in throughput, latency, and energy efficiency, especially for small- and medium-sized matrix multiplies
What carries the argument
The slicing-based photonic multiplication scheme inside a block floating-point (BFP) framework, which performs low bit-width photonic multiplications and digitally accumulates the resulting slices to obtain high-precision mantissa products, supported by a tile-based matrix multiplication dataflow.
If this is right
- Configurable BFP precision enables explicit tradeoffs between accuracy and performance for different workloads.
- The tile-based dataflow supports general matrix multiplication without hardware changes for any matrix size.
- Highly parallel photonic architecture plus reduced data movement yields better efficiency than pure electronic or prior photonic designs for small- and medium-sized problems.
- Slice-based BFP arithmetic overcomes the precision ceiling that has limited most existing photonic accelerators.
Where Pith is reading between the lines
- The same slicing and BFP approach could be applied to other dense linear-algebra kernels such as convolutions or tensor contractions.
- Integration into existing AI runtimes might cut power draw for inference workloads where full floating-point precision is unnecessary.
- Further hardware measurements would be needed to confirm whether digital accumulation overhead remains small once matrix dimensions exceed the sizes tested in simulation.
- The hybrid design suggests a path for mixed-precision systems that combine photonic speed with digital reliability in edge or data-center settings.
Load-bearing premise
That low bit-width photonic multiplications remain accurate enough after noise accumulation and that digital accumulation of slices adds negligible overhead when scaling to arbitrary matrix sizes on real hardware.
What would settle it
A direct measurement on the photonic prototype for a target precision level showing that accumulated optical noise produces output errors exceeding the allowed threshold, or that digital slice accumulation time dominates execution for large matrices.
Figures












read the original abstract
Matrix multiplication is a fundamental kernel in large-scale artificial intelligence and scientific computing, but its performance on conventional electronic accelerators is increasingly constrained by memory bandwidth and energy efficiency. Photonic computing offers a promising alternative due to its ultra-high bandwidth, massive parallelism, and low power dissipation. However, most existing photonic systems are limited to low-precision computation because of analog optical modulation constraints and noise accumulation, which restricts their applicability in precision-critical workloads. To address this limitation, we propose LightMat-HP, a hybrid photonic-electronic computing system that enables end-to-end acceleration of general matrix multiplication with configurable computational precision. LightMat-HP adopts block floating-point (BFP) arithmetic to reduce computational complexity while enabling flexible precision-performance tradeoffs. To overcome the precision limitations of photonic devices, we propose a slicing-based photonic multiplication scheme that exploits the high accuracy of low bit-width photonic multiplication in combination with digital accumulation to achieve high-precision mantissa multiplication. A tile-based matrix multiplication dataflow is further designed to support matrices of arbitrary sizes. We experimentally validate LightMat-HP on a photonic computing prototype and evaluate its performance through large-scale simulations. The results demonstrate that LightMat-HP outperforms FPGA, GPU, and a state-of-the-art photonic accelerator across throughput, latency, and energy efficiency, particularly for small- and medium-sized matrix multiplications, owing to its highly parallel photonic architecture, efficient data movement, and slice-based BFP arithmetic.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LightMat-HP, a hybrid photonic-electronic system for accelerating general matrix multiplication. It uses block floating-point (BFP) arithmetic with a slicing-based photonic multiplication scheme to achieve configurable precision by combining low bit-width photonic operations with digital accumulation. A tile-based dataflow supports arbitrary matrix sizes. The authors report experimental validation on a photonic computing prototype together with large-scale simulations, claiming superior throughput, latency, and energy efficiency versus FPGA, GPU, and prior photonic accelerators, especially for small- and medium-sized matrices.
Significance. If the accuracy and overhead claims hold after proper quantification, the work would advance photonic accelerators by demonstrating a practical route to configurable precision beyond the low-bit limits of analog optics. The hybrid slicing approach and prototype-plus-simulation methodology are positive elements that could influence hardware design for AI workloads.
major comments (3)
- [Abstract and experimental validation] Abstract and experimental validation section: the central claim of outperformance rests on prototype measurements and simulations, yet no quantitative error rates, noise models, error bars, or accuracy loss after slice accumulation are reported. This directly undermines verification of the weakest assumption that low bit-width photonic multiplications plus digital accumulation deliver the stated precision with negligible loss.
- [Tile-based matrix multiplication dataflow] Tile-based matrix multiplication dataflow section: no breakdown of digital accumulation latency or energy versus matrix dimension, nor scaling curves showing when tile overhead overtakes photonic gains, is provided. Without these, the claim that the architecture supports arbitrary sizes while retaining advantages for small/medium matrices cannot be evaluated.
- [Performance comparison] Performance comparison section: baseline configurations (e.g., specific FPGA/GPU implementations, matrix-size distributions, and precision settings) are not detailed, preventing assessment of whether the reported gains are robust or sensitive to particular test conditions.
minor comments (1)
- [Introduction] Notation for BFP parameters and slice widths should be defined consistently in the first use to avoid ambiguity for readers unfamiliar with the specific implementation.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review of our manuscript. We address each major comment point by point below. Where the comments identify gaps in the current presentation, we commit to revisions that add the requested quantitative details and clarifications without altering the core claims or methodology.
read point-by-point responses
-
Referee: [Abstract and experimental validation] Abstract and experimental validation section: the central claim of outperformance rests on prototype measurements and simulations, yet no quantitative error rates, noise models, error bars, or accuracy loss after slice accumulation are reported. This directly undermines verification of the weakest assumption that low bit-width photonic multiplications plus digital accumulation deliver the stated precision with negligible loss.
Authors: We agree that the manuscript would be strengthened by explicit quantitative error analysis. In the revised version we will add: measured error rates obtained from the photonic prototype, the noise models used in the large-scale simulations, error bars on all reported throughput/latency/energy figures, and a dedicated analysis of accumulated accuracy loss after multiple slice operations in the BFP scheme. These additions will directly support the claim that low-bit-width photonic multiplications combined with digital accumulation achieve the stated configurable precision. revision: yes
-
Referee: [Tile-based matrix multiplication dataflow] Tile-based matrix multiplication dataflow section: no breakdown of digital accumulation latency or energy versus matrix dimension, nor scaling curves showing when tile overhead overtakes photonic gains, is provided. Without these, the claim that the architecture supports arbitrary sizes while retaining advantages for small/medium matrices cannot be evaluated.
Authors: We acknowledge that a more granular breakdown is needed to substantiate the dataflow claims. The revised manuscript will include tables and figures that decompose digital accumulation latency and energy as functions of matrix dimension, together with scaling curves that identify the crossover point at which tile overhead begins to offset photonic gains. These additions will clarify the regime in which the architecture retains its advantages for small- and medium-sized matrices while still supporting arbitrary sizes. revision: yes
-
Referee: [Performance comparison] Performance comparison section: baseline configurations (e.g., specific FPGA/GPU implementations, matrix-size distributions, and precision settings) are not detailed, preventing assessment of whether the reported gains are robust or sensitive to particular test conditions.
Authors: The performance comparison section provides high-level descriptions of the baselines, but we concur that greater specificity is required for reproducibility and robustness assessment. We will expand the section to explicitly state the exact FPGA and GPU hardware models, synthesis/optimization settings, the precise matrix-size distributions used in the benchmarks, and the bit-width/precision configurations applied to each comparator. This will enable readers to evaluate the sensitivity of the reported gains to the chosen test conditions. revision: yes
Circularity Check
No significant circularity: claims rest on prototype measurements and simulations
full rationale
The paper describes a proposed hybrid photonic-electronic architecture for configurable-precision matrix multiplication, using block floating-point arithmetic and a slicing scheme for photonic multiplications. Validation is stated to come from direct experimental measurements on a photonic prototype plus large-scale simulations, with performance comparisons to FPGA, GPU, and prior photonic accelerators. No equations, derivations, fitted parameters presented as predictions, or self-citation chains appear in the abstract or described structure; the central claims do not reduce to self-definition or renaming of inputs. The architecture's dataflow and precision mechanisms are presented as design choices supported by hardware experiments rather than by construction from the target metrics.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sufi R Ahmed, Reza Baghdadi, Mikhail Bernadskiy, Nate Bowman, Ryan Braid, Jim Carr, Chen Chen, Pietro Ciccarella, Matthew Cole, John Cooke, et al. 2025. Universal photonic artificial intelligence acceleration.Nature640, 8058 (2025), 368–374
2025
-
[2]
Ivonne Bente, Shabnam Taheriniya, Francesco Lenzini, Frank Brückerhoff-Plückelmann, Michael Kues, Harish Bhaskaran, C David Wright, and Wolfram Pernice. 2025. The potential of multidimensional photonic computing.Nature Reviews Physics7, 8 (2025), 439–450
2025
-
[3]
Cadence Design Systems. 2023. Genus Synthesis Solution. https://www.cadence.com/en_US/home.html. Accessed: 2023
2023
-
[4]
Junwei Cheng, Hailong Zhou, and Jianji Dong. 2021. Photonic matrix computing: from fundamentals to applications.nanomaterials11, 7 (2021), 1683
2021
-
[5]
William R Clements, Peter C Humphreys, Benjamin J Metcalf, W Steven Kolthammer, and Ian A Walmsley. 2016. Optimal design for universal multiport interferometers.Optica3, 12 (2016), 1460–1465
2016
-
[6]
Cansu Demirkiran, Furkan Eris, Gongyu Wang, Jonathan Elmhurst, Nick Moore, Nicholas C Harris, Ayon Basumallik, Vijay Janapa Reddi, Ajay Joshi, and Darius Bunandar. 2023. An electro-photonic system for accelerating deep neural networks.ACM journal on emerging technologies in computing systems19, 4 (2023), 1–31
2023
-
[7]
Cansu Demirkiran, Guowei Yang, Darius Bunandar, and Ajay Joshi. 2024. Mirage: An RNS-based photonic accelerator for DNN training. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA). IEEE, Buenos Aires, Argentina, 73–87
2024
-
[8]
Johannes Feldmann, Nathan Youngblood, Maxim Karpov, Helge Gehring, Xuan Li, Maik Stappers, Manuel Le Gallo, Xin Fu, Anton Lukashchuk, Arslan S Raja, et al. 2021. Parallel convolutional processing using an integrated photonic tensor core.Nature589, 7840 (2021), 52–58
2021
-
[9]
Johannes Feldmann, Nathan Youngblood, C David Wright, Harish Bhaskaran, and Wolfram HP Pernice. 2019. All-optical spiking neurosynaptic networks with self-learning capabilities.Nature569, 7755 (2019), 208–214
2019
-
[10]
Ryan Hamerly, Liane Bernstein, Alexander Sludds, Marin Soljačić, and Dirk Englund. 2019. Large-scale optical neural networks based on photoelectric multiplication.Physical Review X9, 2 (2019), 021032
2019
-
[11]
Shiyue Hua, Erwan Divita, Shanshan Yu, Bo Peng, Charles Roques-Carmes, Zhan Su, Zhang Chen, Yanfei Bai, Jinghui Zou, Yunpeng Zhu, et al. 2025. An integrated large-scale photonic accelerator with ultralow latency.Nature640, 8058 (2025), 361–367
2025
-
[12]
Hideki Ishio, Junichiro Minowa, and Kiyoshi Nosu. 2003. Review and status of wavelength-division-multiplexing technology and its application.Journal of lightwave technology2, 4 (2003), 448–463
2003
-
[13]
Yazan Lampert, Amirhassan Shams-Ansari, Aleksei Gaier, Alessandro Tomasino, Xuhui Cao, Leticia Magalhaes, Shima Rajabali, Marko Lončar, and Ileana-Cristina Benea-Chelmus. 2025. Photonics-integrated terahertz transmission lines.Nature Communications16, 1 (2025), 7004
2025
-
[14]
Retrieved Dec
Laser 2025.Tunable Diode Laser from ID Photonics (25 kHz Spectral Linewidth). Retrieved Dec. 16, 2025 from https://shop.laserdiodesource. com/shop/tunable-c-band-laser-1528nm-1569nm-gc-idp
2025
-
[15]
Weichen Liu, Wenyang Liu, Yichen Ye, Qian Lou, Yiyuan Xie, and Lei Jiang. 2019. HolyLight: A Nanophotonic Accelerator for Deep Learning in Data Centers.2019 Design, Automation & Test in Europe Conference & Exhibition (DATE)(2019), 1483–1488. https: //api.semanticscholar.org/CorpusID:155109438
2019
-
[16]
Rinu Abraham Maniyara, Vahagn K Mkhitaryan, Tong Lai Chen, Dhriti Sundar Ghosh, and Valerio Pruneri. 2016. An antireflection transparent conductor with ultralow optical loss and electrical resistance.Nature Communications7, 1 (2016), 13771
2016
-
[17]
Shupeng Ning, Hanqing Zhu, Chenghao Feng, Jiaqi Gu, Zhixing Jiang, Zhoufeng Ying, Jason Midkiff, Sourabh Jain, May H Hlaing, David Z Pan, et al . 2024. Photonic-electronic integrated circuits for high-performance computing and AI accelerators.Journal of Lightwave Technology42, 22 (2024), 7834 – 7859
2024
-
[18]
Alan Oppenheim. 2003. Realization of digital filters using block-floating-point arithmetic.IEEE transactions on audio and electroacoustics 18, 2 (2003), 130–136
2003
-
[19]
Retrieved Dec
OPTICS 2025.OZ Optics DTS0165 Datasheet. Retrieved Dec. 16, 2025 from https://www.ozoptics.com/ALLNEW_PDF/DTS0165.pdf
2025
-
[20]
Nicola Peserico, Bhavin J Shastri, and Volker J Sorger. 2023. Integrated photonic tensor processing unit for a matrix multiply: a review. Journal of Lightwave Technology41, 12 (2023), 3704–3716
2023
-
[21]
Carlos Ríos, Nathan Youngblood, Zengguang Cheng, Manuel Le Gallo, Wolfram HP Pernice, C David Wright, Abu Sebastian, and Harish Bhaskaran. 2019. In-memory computing on a photonic platform.Science advances5, 2 (2019), eaau5759. ACM Trans. Des. Autom. Electron. Syst., Vol. 37, No. 4, Article 111. Publication date: August 2026. 111:28•GONG et al
2019
-
[22]
Retrieved Dec
RXM15EF 2025.Thorlabs RXM15EF Multimode Ultrafast Receiver, 750–1650 nm, DC–15 GHz, FC/PC. Retrieved Dec. 16, 2025 from https://www.thorlabs.com/thorproduct.cfm?partnumber=RXM15EF
2025
-
[23]
2007.Fundamentals of photonics
Bahaa E A Saleh and Malvin Carl Teich. 2007.Fundamentals of photonics. Wiley, New York, NY. https://cds.cern.ch/record/1084451
-
[24]
Yichen Shen, Nicholas C Harris, Scott Skirlo, Mihika Prabhu, Tom Baehr-Jones, Michael Hochberg, Xin Sun, Shijie Zhao, Hugo Larochelle, Dirk Englund, et al. 2017. Deep learning with coherent nanophotonic circuits.Nature photonics11, 7 (2017), 441–446
2017
-
[25]
Alina Sîrbu and Ozalp Babaoglu. 2016. Power Consumption Modeling and Prediction in a Hybrid CPU-GPU-MIC Supercomputer. In Proceedings of the 22nd International Conference on Euro-Par 2016: Parallel Processing - Volume 9833. Springer-Verlag, Berlin, Heidelberg, 117–130. doi:10.1007/978-3-319-43659-3_9
-
[26]
Aaron Stillmaker and Bevan Baas. 2017. Scaling equations for the accurate prediction of CMOS device performance from 180 nm to 7 nm.Integration58 (2017), 74–81
2017
-
[27]
Alexander N Tait. 2022. Quantifying power in silicon photonic neural networks.Physical Review Applied17, 5 (2022), 054029
2022
-
[28]
Alexander N Tait, Thomas Ferreira De Lima, Ellen Zhou, Allie X Wu, Mitchell A Nahmias, Bhavin J Shastri, and Paul R Prucnal. 2017. Neuromorphic photonic networks using silicon photonic weight banks.Scientific reports7, 1 (2017), 7430
2017
-
[29]
Retrieved Dec
THORLABS 2025.Thorlabs LNA2322 10 GHz Intensity Modulator with Internal Photodetector, X-Cut, FC/PC Connectors, 1525 nm–1605 nm. Retrieved Dec. 16, 2025 from https://www.thorlabs.com/thorproduct.cfm?partnumber=LNA2322
2025
-
[30]
2022.Numerical linear algebra
Lloyd N Trefethen and David Bau. 2022.Numerical linear algebra. SIAM
2022
-
[31]
Chengpeng Xia, Haibo Zhang, Hao Zhang, Yawen Chen, and Amanda Susan Barnard. 2025. BITLUME: Precision-Flexible Photonic Computing for Ultra-Fast and Energy-Efficient DNN Acceleration. In2025 IEEE/ACM International Conference On Computer Aided Design (ICCAD). IEEE, Munich, Germany, 1–9. doi:10.1109/ICCAD66269.2025.11240825
-
[32]
Shuiying Xiang, Yanan Han, Ziwei Song, Xingxing Guo, Yahui Zhang, Zhenxing Ren, Suhong Wang, Yuanting Ma, Weiwen Zou, Bowen Ma, et al. 2021. A review: Photonics devices, architectures, and algorithms for optical neural computing.Journal of Semiconductors42, 2 (2021), 023105
2021
-
[33]
Xingyuan Xu, Mengxi Tan, Bill Corcoran, Jiayang Wu, Andreas Boes, Thach G Nguyen, Sai T Chu, Brent E Little, Damien G Hicks, Roberto Morandotti, et al. 2021. 11 TOPS photonic convolutional accelerator for optical neural networks.Nature589, 7840 (2021), 44–51
2021
-
[34]
Xiao Yu, Ziqi Wei, Fangyuan Sha, Xinyu Wang, Yanqi Chu, Zhen Wang, Xilin Han, Hongwei Wang, Shulan Yi, Yuhu Cheng, et al. 2025. Parallel optical computing capable of 100-wavelength multiplexing.eLight5, 1 (2025), 10
2025
-
[35]
Haoran Zhang, Yuhang Song, Shifan Chen, Yunping Bai, Xingyuan Xu, Chaoran Huang, Jian Wang, Hongwei Chen, David J Moss, and Kun Xu. 2025. Integrated platforms and techniques for photonic neural networks.npj Nanophotonics2, 1 (2025), 40
2025
-
[36]
Hao Zhang, Haibo Zhang, Chengpeng Xia, Zhiyi Huang, Yawen Chen, and Amanda Barnard. 2025. ROCKET: An RNS-based Pho- tonic Accelerator for High-Precision and Energy-Efficient DNN Training. InProceedings of the 39th ACM International Conference on Supercomputing. ACM, Salt Lake City, USA, 1020–1033
2025
-
[37]
Zhizhen Zhong, Mingran Yang, Jay Lang, Christian Williams, Liam Kronman, Alexander Sludds, Homa Esfahanizadeh, Dirk Englund, and Manya Ghobadi. 2023. Lightning: A reconfigurable photonic-electronic smartnic for fast and energy-efficient inference. InProceedings of the ACM SIGCOMM Conference. ACM, New York, NY, USA, 452–472. Received xx January 2026; revis...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.