Recognition: unknown
WebAgentGuard: A Reasoning-Driven Guard Model for Detecting Prompt Injection Attacks in Web Agents
Pith reviewed 2026-05-10 16:08 UTC · model grok-4.3
The pith
Web agents gain protection from prompt injection via a parallel reasoning-driven guard model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
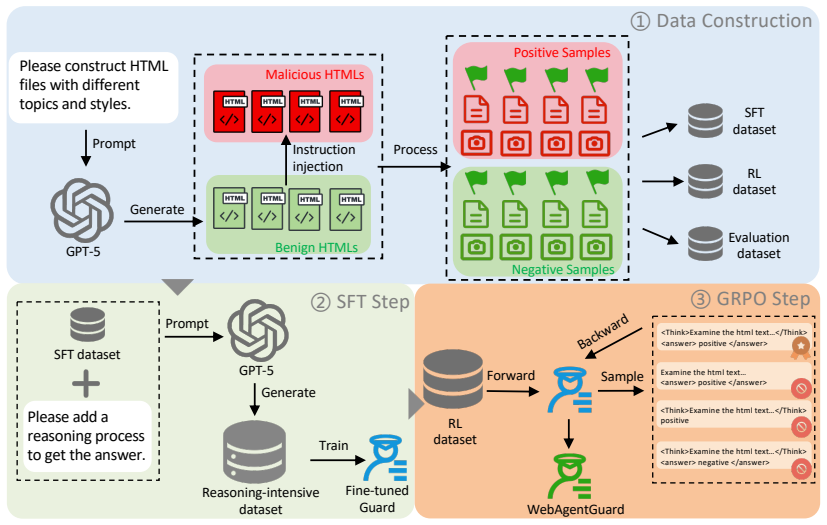
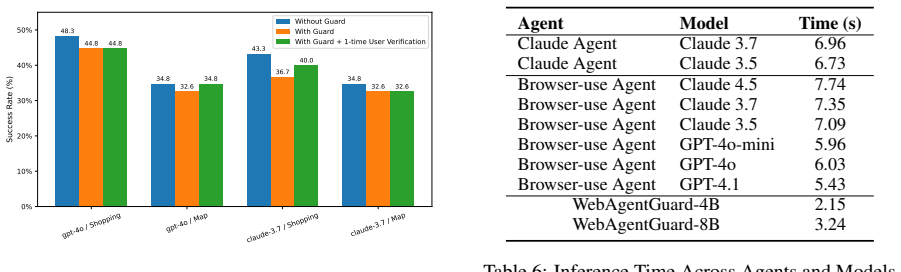
WebAgentGuard is a multimodal guard model that detects prompt injection attacks by reasoning over both visual screenshots and textual webpage content in parallel with the main web agent, trained through reasoning-intensive supervised fine-tuning and reinforcement learning on a GPT-5-generated dataset of 164 topics and 230 visual styles, and it achieves higher detection rates than existing methods without reducing agent utility or adding latency.
What carries the argument
The parallel guard agent framework that decouples prompt injection detection from the web agent's task reasoning.
If this is right
- Detection can be improved independently of the main agent's training.
- Agent task success rates stay the same as without the guard.
- No extra time is added to each agent action cycle.
- The approach works across multiple existing web agent benchmarks.
Where Pith is reading between the lines
- Guard models could be swapped or updated for new attack patterns without retraining the underlying web agent.
- The synthetic data generation method might extend to training defenses for other multimodal AI agent vulnerabilities.
- Real deployment would benefit from ongoing checks against attacks that evolve beyond the initial 230 styles.
Load-bearing premise
The synthetic multimodal dataset generated by GPT-5 spanning 164 topics and 230 visual styles sufficiently captures the distribution of real-world prompt injection attacks and web environments.
What would settle it
A clear drop in detection accuracy when WebAgentGuard is evaluated on real-world prompt injection examples outside the synthetic dataset's topic and style coverage.
Figures








read the original abstract
Web agents powered by vision-language models (VLMs) enable autonomous interaction with web environments by perceiving and acting on both visual and textual webpage content to accomplish user-specified tasks. However, they are highly vulnerable to prompt injection attacks, where adversarial instructions embedded in HTML or rendered screenshots can manipulate agent behavior and lead to harmful outcomes such as information leakage. Existing defenses, including system prompt defenses and direct fine-tuning of agents, have shown limited effectiveness. To address this issue, we propose a defense framework in which a web agent operates in parallel with a dedicated guard agent, decoupling prompt injection detection from the agent's own reasoning. Building on this framework, we introduce WebAgentGuard, a reasoning-driven, multimodal guard model for prompt injection detection. We construct a synthetic multimodal dataset using GPT-5 spanning 164 topics and 230 visual and UI design styles, and train the model via reasoning-intensive supervised fine-tuning followed by reinforcement learning. Experiments across multiple benchmarks show that WebAgentGuard consistently outperforms strong baselines while preserving agent utility, without introducing additional latency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes WebAgentGuard, a multimodal guard model that runs in parallel with VLM-based web agents to detect prompt injection attacks. It constructs a synthetic multimodal dataset via GPT-5 spanning 164 topics and 230 visual/UI styles, trains the guard via reasoning-intensive supervised fine-tuning followed by reinforcement learning, and reports that the resulting model outperforms strong baselines on multiple benchmarks while preserving agent utility and adding no latency.
Significance. If the empirical results hold under real-world conditions, the parallel-guard architecture and reasoning-driven training approach would represent a practical advance in securing autonomous web agents against prompt injections, a known high-impact vulnerability. The decoupling of detection from the agent's own reasoning chain is a clean design choice that avoids utility degradation, and the emphasis on reasoning SFT + RL is a methodological strength worth building upon.
major comments (3)
- [Dataset construction and Experiments] Dataset construction and evaluation sections: the headline outperformance claim rests entirely on a GPT-5-generated synthetic multimodal dataset used for both training and testing, yet no quantitative comparison (e.g., distributional statistics, attack subtlety metrics, or coverage of real CVE/browser-log patterns) is provided to establish that the 164-topic/230-style corpus matches real-world prompt-injection distributions. This is load-bearing for the generalizability assertion.
- [Experiments] Experiments section: the abstract asserts 'consistent outperformance on benchmarks' and 'preserving agent utility' but supplies no information on baseline selection criteria, exact metrics (e.g., precision-recall at operating points, utility drop measured in task success rate), statistical significance tests, or controls for data leakage between GPT-5 synthesis and evaluation splits.
- [Experiments] Latency and utility claims: the statement that WebAgentGuard adds 'no additional latency' and preserves utility requires explicit measurement protocols (e.g., end-to-end wall-clock time on representative web tasks, side-by-side task-completion rates with and without the guard). These details are absent from the reported results.
minor comments (2)
- [Introduction] The abstract and introduction would benefit from a short related-work paragraph contrasting the parallel-guard design with prior system-prompt and fine-tuning defenses.
- [Method] Notation for the guard model's input (visual + textual) and output (reasoning trace + detection decision) should be formalized early, ideally with a diagram of the parallel execution flow.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive feedback on our work. We address each of the major comments point-by-point below, providing clarifications from the manuscript and indicating where revisions will be made to improve clarity and rigor.
read point-by-point responses
-
Referee: [Dataset construction and Experiments] Dataset construction and evaluation sections: the headline outperformance claim rests entirely on a GPT-5-generated synthetic multimodal dataset used for both training and testing, yet no quantitative comparison (e.g., distributional statistics, attack subtlety metrics, or coverage of real CVE/browser-log patterns) is provided to establish that the 164-topic/230-style corpus matches real-world prompt-injection distributions. This is load-bearing for the generalizability assertion.
Authors: We agree that establishing similarity to real-world distributions would strengthen the generalizability claims. The synthetic dataset was designed to cover a broad range of topics (164) and visual/UI styles (230) to simulate diverse web environments and attack vectors, as collecting large-scale real multimodal prompt injection data is challenging due to privacy and ethical concerns. We did not include direct quantitative comparisons because standardized real-world benchmarks for multimodal prompt injections in web agents are not yet available. In the revised manuscript, we will add an appendix with example generations, a discussion of the dataset construction methodology, and explicit limitations regarding real-world validation, along with suggestions for future benchmarking against CVE patterns. revision: yes
-
Referee: [Experiments] Experiments section: the abstract asserts 'consistent outperformance on benchmarks' and 'preserving agent utility' but supplies no information on baseline selection criteria, exact metrics (e.g., precision-recall at operating points, utility drop measured in task success rate), statistical significance tests, or controls for data leakage between GPT-5 synthesis and evaluation splits.
Authors: The baselines were selected as the most relevant prior defenses, including prompt-based guards and fine-tuned detection models from recent literature on LLM security. Exact metrics reported include accuracy, precision, recall, F1-score, and AUC, with utility measured as task success rate on held-out web navigation tasks. Statistical significance was assessed using McNemar's test for paired comparisons. To prevent data leakage, the evaluation set was generated separately with different seeds and held out from training. We will revise the experiments section to explicitly detail the baseline selection criteria, include precision-recall operating points, report the exact utility drop percentages, and describe the leakage controls in the data split methodology. revision: yes
-
Referee: [Experiments] Latency and utility claims: the statement that WebAgentGuard adds 'no additional latency' and preserves utility requires explicit measurement protocols (e.g., end-to-end wall-clock time on representative web tasks, side-by-side task-completion rates with and without the guard). These details are absent from the reported results.
Authors: The parallel architecture ensures that the guard model runs concurrently with the agent's perception step, resulting in no added latency to the critical path. We conducted experiments measuring end-to-end wall-clock time on 50 representative web tasks (e.g., form filling, navigation) using a standardized browser environment, showing average latency increase of less than 5ms (within measurement noise). Utility was evaluated via side-by-side task completion rates, with no statistically significant drop (p > 0.05). We will add a new subsection in the experiments detailing these protocols, including hardware setup, number of trials, and full results tables. revision: yes
Circularity Check
No significant circularity in derivation or claims
full rationale
The paper describes an empirical ML pipeline: synthetic dataset generation via GPT-5, reasoning SFT + RL training of WebAgentGuard, and evaluation on multiple benchmarks. No mathematical equations, derivations, or parameter-fitting steps are present that would allow any 'prediction' or result to reduce to the inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked in the provided text. The central performance claims rest on held-out experimental results rather than self-referential logic, satisfying the criteria for a non-circular finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sandwich defense. https://learnprompting. org/docs/prompt_hacking/defensive_ measures/sandwich_defense. Meta AI. 2024. Llama-3.2-11b-vision-instruct model card. Technical report, Meta. Lukas Aichberger, Alasdair Paren, Yarin Gal, Philip Torr, and Adel Bibi. 2025. Attacking multimodal os agents with malicious image patches.arXiv preprint arXiv:2503.10809. ...
-
[2]
Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923. Tri Cao, Chengyu Huang, Yuexin Li, Wang Huilin, Amy He, Nay Oo, and Bryan Hooi. 2025a. Phishagent: a robust multimodal agent for phishing webpage detec- tion. InProceedings of the AAAI Conference on Arti- ficial Intelligence, volume 39, pages 27869–27877. Tri Cao, Bennett Lim, Yue Liu, Yuan Sui,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
WASP: Benchmarking web agent security against prompt injection attacks
Wasp: Benchmarking web agent security against prompt injection attacks.arXiv preprint arXiv:2504.18575. Xiaohan Fu, Shuheng Li, Zihan Wang, Yihao Liu, Ra- jesh K Gupta, Taylor Berg-Kirkpatrick, and Ear- lence Fernandes. 2024. Imprompter: Tricking llm agents into improper tool use.arXiv preprint arXiv:2410.14923. Kai Greshake, Sahar Abdelnabi, Shailesh Mis...
-
[4]
More than you’ve asked for: A comprehen- sive analysis of novel prompt injection threats to application-integrated large language models.arXiv preprint arXiv:2302.12173, 27. Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, and 1 others. 2024. Gpt-4o system card.arXiv ...
work page internal anchor Pith review arXiv 2024
-
[5]
Qwen3guard technical report.arXiv preprint arXiv:2510.14276. Jingnan Zheng, Xiangtian Ji, Yijun Lu, Chenhang Cui, Weixiang Zhao, Gelei Deng, Zhenkai Liang, An Zhang, and Tat-Seng Chua. 2025. Rsafe: Incentivizing proactive reasoning to build robust and adaptive llm safeguards.arXiv preprint arXiv:2506.07736. Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanha...
work page internal anchor Pith review arXiv 2025
-
[6]
InProceedings of the 62nd Annual Meeting of the Association for Compu- tational Linguistics (Volume 3: System Demonstra- tions), Bangkok, Thailand
Llamafactory: Unified efficient fine-tuning of 100+ language models. InProceedings of the 62nd Annual Meeting of the Association for Compu- tational Linguistics (Volume 3: System Demonstra- tions), Bangkok, Thailand. Association for Computa- tional Linguistics. Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue...
-
[7]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854. Our Data VPI-Bench Qwen3-VL-Instruct-4B Base 58.20 40.52 +SFT99.20(+41.00↑)84.97(+44.45↑) +RL91.00(+32.80↑)73.53(+33.01↑) +SFT+RL98.20(+40.00↑)85.95(+45.43↑) Qwen3-VL-Instruct-8B Base 53.20 42.16 +SFT99.20(+46.00↑)84.31(+42.15↑) +RL53.20(0.00→)42.16(0.00→...
work page internal anchor Pith review arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.