Recognition: unknown
TierBPF: Page Migration Admission Control for Tiered Memory via eBPF
Pith reviewed 2026-05-10 14:23 UTC · model grok-4.3
The pith
TierBPF adds eBPF-based admission control to existing tiered memory systems so they can decide page migrations based on size and hardware topology.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
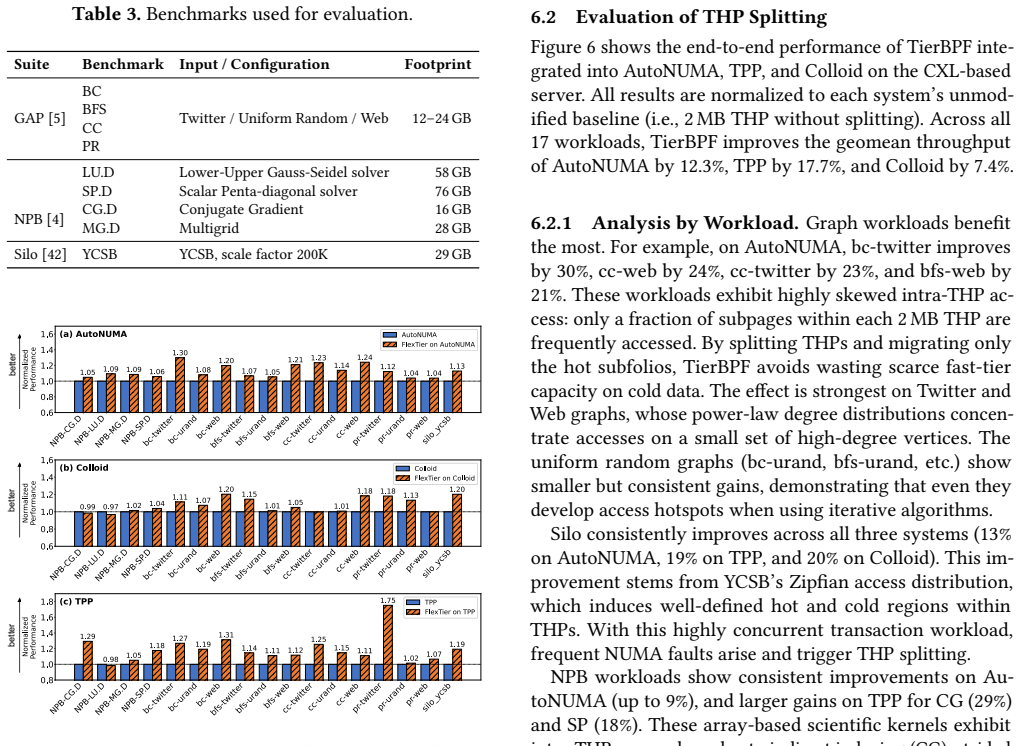
TierBPF is implemented as a collection of eBPF hooks that perform binary page admission control for migrations in tiered memory. It incorporates a lightweight page-profiling tracker whose cost does not grow with working-set size, and it exposes hooks so that custom policies can weigh page size against the specific device and topology of the memory tiers. When integrated into three existing memory tiering systems and run across 17 workloads, the mechanism delivers a geometric-mean throughput increase of 17.7 percent, reaching as high as 75 percent on individual applications.
What carries the argument
TierBPF, a pluggable set of eBPF hooks that perform binary admission decisions on page migrations while using lightweight profiling independent of working-set size.
If this is right
- Existing tiering systems gain the ability to reject costly migrations of large pages or pages headed to mismatched hardware without altering their core logic.
- Applications can experience higher throughput on heterogeneous memory hardware simply by enabling the new admission layer.
- Users can define workload-specific migration rules through the eBPF interface and apply them across different base tiering implementations.
- The profiling cost remains bounded regardless of application memory footprint, allowing the mechanism to stay active on large-scale workloads.
Where Pith is reading between the lines
- The same hook-based admission pattern could be applied to other OS decisions such as storage tiering or network buffer placement where size and device topology matter.
- If the lightweight tracker proves robust under bursty access patterns, it may support dynamic policy changes at runtime in cloud environments with shifting workloads.
- Avoiding unnecessary migrations could indirectly lower power draw on systems where fast memory consumes more energy than slow memory.
Load-bearing premise
That the eBPF hooks and lightweight profiling can be inserted into existing tiering systems without creating unacceptable overhead or correctness problems.
What would settle it
Running the same workloads with and without TierBPF on a system whose fast tier is small enough that migration volume becomes the dominant cost, then checking whether measured throughput and page placement accuracy match the claimed gains.
Figures





read the original abstract
Existing software-based memory tiering systems decide which pages to place on the slower or faster tier. However, they do not take into account two important factors that greatly influence application performance: the size of the migrated pages, and the underlying hardware device and tiering topology. We introduce TierBPF, a software mechanism that can be plugged into existing memory tiering systems to take these factors into account, by making simple binary page admission decisions. TierBPF is implemented as a set of eBPF hooks, which allow users to define their own custom policies. In order to make its decisions, TierBPF utilizes a lightweight tracking mechanism for page profiling which is not dependent on the application's working set size. TierBPF, integrated into three memory tiering systems and evaluated with 17 workloads, achieves geomean throughput gains of up to 17.7% with improvements of up to 75% for individual workloads.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents TierBPF, an eBPF-based pluggable admission control layer for software memory tiering systems. It performs simple binary decisions on page migrations by considering migrated page sizes and underlying hardware topology, using a lightweight page-profiling mechanism that is independent of application working-set size. The mechanism is integrated into three existing tiering systems and evaluated across 17 workloads, reporting geomean throughput gains of up to 17.7% (with individual workload improvements up to 75%).
Significance. If the empirical results hold under scrutiny, TierBPF offers a practical, extensible approach to improving tiered-memory performance without altering core tiering logic. The eBPF design enables user-defined policies and the claimed independence from working-set size addresses a key scalability concern in heterogeneous memory systems. The multi-system integration and workload count provide evidence of broad applicability.
major comments (2)
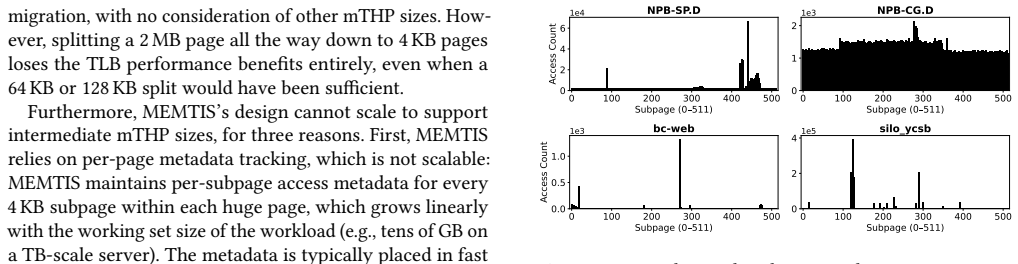
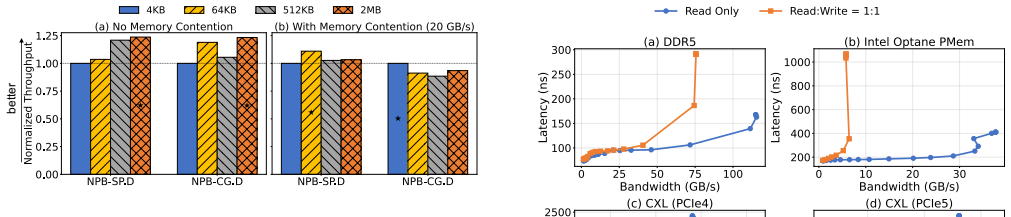
- [Evaluation section] Evaluation section: The abstract and evaluation report specific throughput numbers (geomean 17.7%, up to 75%) but supply no information on experimental methodology, including workload selection criteria, hardware configurations, number of runs, error bars, or how overhead was isolated from the baseline tiering systems. This is load-bearing for the central performance claim and prevents verification of the reported gains.
- [§3 (Design)] §3 (Design): The description of the lightweight tracking mechanism asserts independence from working-set size via fixed-size eBPF maps, but does not detail how binary admission decisions remain accurate under varying access patterns or large working sets; without this, the scalability advantage over existing profilers is not fully substantiated.
minor comments (2)
- The abstract should explicitly name the three memory tiering systems into which TierBPF was integrated.
- Figure captions and table headers in the evaluation could more clearly distinguish baseline vs. TierBPF configurations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and commit to revisions that will strengthen the paper's clarity and verifiability.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section: The abstract and evaluation report specific throughput numbers (geomean 17.7%, up to 75%) but supply no information on experimental methodology, including workload selection criteria, hardware configurations, number of runs, error bars, or how overhead was isolated from the baseline tiering systems. This is load-bearing for the central performance claim and prevents verification of the reported gains.
Authors: We agree that additional methodological details are needed for full verification of the reported gains. In the revised manuscript, we will expand the evaluation section with a new subsection that explicitly describes: the criteria used to select the 17 workloads and their key characteristics; the hardware configurations of the three evaluated systems (including CPU, memory tiers, and interconnect details); the number of runs per experiment and how results were aggregated; the use of error bars or variance measures in figures; and the methodology for isolating TierBPF overhead from the baseline tiering systems (e.g., via controlled microbenchmarks and profiling). These additions will directly address the load-bearing nature of the performance claims. revision: yes
-
Referee: [§3 (Design)] §3 (Design): The description of the lightweight tracking mechanism asserts independence from working-set size via fixed-size eBPF maps, but does not detail how binary admission decisions remain accurate under varying access patterns or large working sets; without this, the scalability advantage over existing profilers is not fully substantiated.
Authors: We acknowledge that the current description in §3 could more explicitly substantiate the accuracy and scalability of the binary decisions. In the revision, we will augment the design section with additional explanation of the page-profiling mechanism: how the fixed-size eBPF maps perform lightweight sampling of page accesses (via hooks that track migration candidates without full working-set enumeration), how this sampling remains effective for varying access patterns by focusing on recent migration events rather than exhaustive profiling, and why decisions on page size and hardware topology retain accuracy even for large working sets. This will better contrast the approach against traditional profilers that scale with working-set size. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical systems contribution: an eBPF-based pluggable admission control layer for existing memory tiering systems, evaluated across three systems and 17 workloads. No equations, fitted parameters, or derivation steps are present that could reduce to their own inputs by construction. Claims rest on measured throughput gains rather than any self-referential logic or self-citation load-bearing premises.
Axiom & Free-Parameter Ledger
invented entities (1)
-
TierBPF
no independent evidence
Reference graph
Works this paper leans on
-
[1]
[n. d.]. pmem.io. memkind. https://pmem.io/memkind/
-
[2]
Angeles, Mark Hildebrand, Venkatesh Akella, and Jason Lowe-Power
Julian T. Angeles, Mark Hildebrand, Venkatesh Akella, and Jason Lowe-Power. 2021. Investigating Hardware Caches for Terabyte-scale NVDIMMs. InAnnual Non-Volatile Memories Workshop
2021
-
[3]
Gal Assa, Moritz Lumme, Lucas Bürgi, Michal Friedman, and Ori Lahav
-
[4]
InInternational Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2
A Programming Model for Disaggregated Memory over CXL. InInternational Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2
-
[5]
D. H. Bailey, L. Dagum, E. Barszcz, and H. D. Simon. 1992. NAS parallel benchmark results. InSupercomputing ’92: Proceedings of the 1992 ACM/IEEE conference on Supercomputing(Minneapolis, Minnesota, United States). IEEE Computer Society Press, Los Alamitos, CA, USA, 386–393
1992
- [6]
-
[7]
Xuechun Cao, Shaurya Patel, Soo Yee Lim, Xueyuan Han, and Thomas Pasquier. 2024. {FetchBPF}: Customizable prefetching policies in linux with {eBPF}. In2024 USENIX Annual Technical Conference (USENIX ATC 24). 369–378
2024
-
[8]
J. Corbet. [n. d.]. AutoNUMA: the Other Approach to NUMA Schedul- ing. http://lwn.net/Articles/488709
-
[9]
Subramanya R Dulloor, Amitabha Roy, Zheguang Zhao, Narayanan Sundaram, Nadathur Satish, Rajesh Sankaran, Jeff Jackson, and Karsten Schwan. 2016. Data tiering in heterogeneous memory systems. In Proceedings of the Eleventh European Conference on Computer Systems. ACM, 15
2016
-
[10]
Simon Guo, Conan Truong, and Brian Demsky. 2026. CXLMC: Model Checking CXL Shared Memory Programs. InInternational Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2
2026
-
[11]
Hyungyo Kim, Qirong Xia, Jinghan Huang, Nachuan Wang, Youn- joo Lee, Jung Ho Ahn, Wajdi K Feghali, Ren Wang, and Nam Sung Kim. 2026. LiLo: Harnessing the on-Chip Accelerators in Intel CPUs for Compressed LLM Inference Acceleration. InIEEE International Symposium on High Performance Computer Architecture (HPCA)
2026
-
[12]
Dusol Lee, Inhyuk Choi, Chanyoung Lee, Hyungsoo Jung, and Ji- hong Kim. 2026. P2Cache: Enhancing data-centric applications via application-guided management of OS page caches.ACM Transactions on Storage22, 1 (2026), 1–33
2026
-
[13]
Taehyung Lee, Sumit Kumar Monga, Changwoo Min, and Young Ik Eom. 2023. MEMTIS: Efficient Memory Tiering with Dynamic Page Classification and Page Size Determination. InProceedings of the 29th ACM Symposium on Operating Systems Principles (SOSP). 17–34
2023
-
[14]
Anatole Lefort, Julian Pritzi, Nicolò Carpentieri, David Schall, Simon Dittrich, Soham Chakraborty, Nicolai Oswald, and Pramod Bhato- tia. 2026. vCXLGen: Automated Synthesis and Verification of CXL Bridges for Heterogeneous Architectures. InInternational Conference on Architectural Support for Programming Languages and Operating Systems
2026
-
[15]
Berger, Lisa Hsu, Daniel Ernst, Pantea Zar- doshti, Stanko Novakovic, Monish Shah, Samir Rajadnya, Scott Lee, Ishwar Agarwal, Mark D
Huaicheng Li, Daniel S. Berger, Lisa Hsu, Daniel Ernst, Pantea Zar- doshti, Stanko Novakovic, Monish Shah, Samir Rajadnya, Scott Lee, Ishwar Agarwal, Mark D. Hill, Marcus Fontoura, and Ricardo Bianchini
-
[16]
InInternational Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS)
Pond: CXL-Based Memory Pooling Systems for Cloud Platforms. InInternational Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS)
-
[17]
Shaobo Li, Yirui (Eric) Zhou, Hao Ren, and Jian Huang. 2025. ByteFS: System Support for (CXL-based) Memory-Semantic Solid-State Drives. InInternational Conference on Architectural Support for Programming Languages and Operating Systems
2025
-
[18]
Berger, Marie Nguyen, Xun Jian, Sam H
Jinshu Liu, Hamid Hadian, Yuyue Wang, Daniel S. Berger, Marie Nguyen, Xun Jian, Sam H. Noh, and Huaicheng Li. 2025. System- atic CXL Memory Characterization and Performance Analysis at Scale. InInternational Conference on Architectural Support for Programming Languages and Operating Systems
2025
-
[19]
Jinshu Liu, Hamid Hadian, Hanchen Xu, and Huaicheng Li. 2025. Tiered Memory Management Beyond Hotness. InProceedings of USENIX Conference on Operating Systems Design and Implementation (OSDI)
2025
-
[20]
Daniel Lustig, Abhishek Bhattacharjee, and Margaret Martonosi. 2013. TLB Improvements for Chip Multiprocessors.ACM Transactions on Architecture and Code Optimization10, 2 (2013), 1–31
2013
-
[21]
Teng Ma, Zheng Liu, Chengkun Wei, Jialiang Huang, Youwei Zhuo, Haoyu Li, Ning Zhang, Yijin Guan, Dimin Niu, Mingxing Zhang, et al
-
[22]
InUSENIX Annual Technical Conference
{HydraRPC}:{RPC} in the {CXL} Era. InUSENIX Annual Technical Conference. 13
- [23]
-
[24]
Hasan Al Maruf, Hao Wang, Abhishek Dhanotia, Johannes Weiner, Niket Agarwal, Pallab Bhattacharya, Chris Petrov, Prakash Chalap- athi, Mosharaf Chaudhry, and Russ Cranney. 2023. TPP: Transparent Page Placement for CXL-Enabled Tiered-Memory. InProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operati...
2023
-
[25]
McCalpin
John D. McCalpin. 2012. Measuring TLB Miss Handling Cost in x86-64. Technical report and Intel performance counter analysis
2012
-
[26]
Mitesh R Meswani, Sergey Blagodurov, David Roberts, John Slice, Mike Ignatowski, and Gabriel H Loh. 2015. Heterogeneous memory architectures: A HW/SW approach for mixing die-stacked and off- package memories. InInternational Symposium on High Performance Computer Architecture (HPCA)
2015
-
[27]
Meta and Google. 2024. sched_ext: Extensible Scheduler Class with BPF.https://docs.kernel.org/scheduler/sched-ext.html. Linux kernel feature, merged in Linux 6.12
2024
-
[28]
Konstantinos Mores et al. 2024. eBPF-mm: Userspace-guided Memory Management in Linux with eBPF. arXiv preprint arXiv:2404.xxxxx
2024
- [29]
-
[30]
Newton Ni, Yan Sun, Zhiting Zhu, and Emmett Witchel. 2026. Cxlalloc: Safe and Efficient Memory Allocation for a CXL Pod. InInternational Conference on Architectural Support for Programming Languages and Operating Systems
2026
-
[31]
Adarsh Patil, Vijay Nagarajan, Nikos Nikoleris, and Nicolai Oswald
-
[32]
In2023 53rd Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN)
¯Apta: Fault-tolerant object-granular CXL disaggregated mem- ory for accelerating FaaS. In2023 53rd Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN)
-
[33]
E. C. Pielou. 1966. The Measurement of Diversity in Different Types of Biological Collections.Journal of Theoretical Biology13 (1966), 131–144
1966
-
[34]
Luiz Ramos, Eugene Gorbatov, and Ricardo Bianchini. 2011. Page Placement in Hybrid Memory Systems. InInternational Conference on Supercomputing
2011
-
[35]
Amanda Raybuck, Tim Stamler, Wei Zhang, Mattan Erez, and Simon Peter. 2021. HeMem: Scalable Tiered Memory Management for Big Data Applications and Real NVM. InProceedings of the ACM SIGOPS 28th Symposium on Operating Systems Principles
2021
-
[36]
Amanda Raybuck, Tim Stamler, Wei Zhang, Mattan Zhong, Tapan Palit, Justine Sherry, Greg Epping, Aasheesh Phan, and Hakim Weath- erspoon. 2021. HeMem: Scalable Tiered Memory Management for Big Data Applications and Real NVM. InProceedings of the 28th ACM Symposium on Operating Systems Principles (SOSP). 392–407
2021
-
[37]
Jie Ren, Jiaolin Luo, Ivy Peng, Kai Wu, and Dong Li. 2021. Optimizing Large-Scale Plasma Simulations on Persistent Memory-based Het- erogeneous Memory with Effective Data Placement Across Memory Hierarchy. InInternational Conference on Supercomputing (ICS)
2021
-
[38]
Jie Ren, Dong Xu, Junhee Ryu, Kwangsik Shin, Daewoo Kim, and Dong Li. 2024. MTM: Rethinking Memory Profiling and Migration for Multi- Tiered Large Memory Systems. InEuropean Conference on Computer Systems
2024
-
[39]
Jie Ren, Minjia Zhang, and Dong Li. 2020. HM-ANN: Efficient Billion- Point Nearest Neighbor Search on Heterogeneous Memory. InConfer- ence on Neural Information Processing Systems (NeurIPS)
2020
-
[40]
Ryan Roberts and Linux Kernel Community. 2024. Multi-size THP (mTHP).https://docs.kernel.org/admin-guide/mm/transhuge.html. Linux kernel feature, merged in Linux 6.8
2024
- [41]
-
[42]
Chihun Song, Austin Antony Cruz, Michael Jaemin Kim, Minbok Wi, Gaohan Ye, Kyungsan Kim, Sangyeol Lee, Jung Ho Ahn, and Nam Sung Kim. 2026. ReScue: Reliable and Secure CXL Memory. InIEEE Interna- tional Symposium on High Performance Computer Architecture (HPCA)
2026
-
[43]
Kevin Song, Jiacheng Yang, Zixuan Wang, Jishen Zhao, Sihang Liu, and Gennady Pekhimenko. 2025. HybridTier: an Adaptive and Lightweight CXL-Memory Tiering System. InInternational Conference on Architec- tural Support for Programming Languages and Operating Systems
2025
-
[44]
Yan Sun, Yifan Yuan, Zeduo Yu, Reese Kuper, Chihun Song, Jinghan Huang, Houxiang Ji, Siddharth Agarwal, Jiaqi Lou, Ipoom Jeong, Ren Wang, Jung Ho Ahn, Tianyin Xu, and Nam Sung Kim. 2023. Demysti- fying CXL Memory with Genuine CXL-Ready Systems and Devices. InIEEE/ACM International Symposium on Microarchitecture
2023
-
[45]
Yupeng Tang, Ping Zhou, Wenhui Zhang, Henry Hu, Qirui Yang, Hao Xiang, Tongping Liu, Jiaxin Shan, Ruoyun Huang, Cheng Zhao, Cheng Chen, Hui Zhang, Fei Liu, Shuai Zhang, Xiaoning Ding, and Jianjun Chen. 2024. Exploring Performance and Cost Optimization with ASIC- Based CXL Memory. InProceedings of the European Conference on Computer Systems
2024
-
[46]
Stephen Tu, Wenting Zheng, Eddie Kohler, Barbara Liskov, and Samuel Madden. 2013. Speedy Transactions in Multicore In-Memory Databases. InProceedings of the 24th ACM Symposium on Operating Systems Principles (SOSP). 18–32
2013
-
[47]
Midhul Vuppalapati, Rodrigo Fonseca, and Hakim Weatherspoon. 2024. Colloid: A Latency-Aware Tiered Memory Management System. In Proceedings of the 30th ACM Symposium on Operating Systems Principles (SOSP)
2024
-
[48]
Xi Wang, Bin Ma, Jongryool Kim, Byungil Koh, Hoshik Kim, and Dong Li. 2025. cMPI: Using CXL Memory Sharing for MPI One-Sided and Two-Sided Inter-Node Communications. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis
2025
-
[49]
Xi (Sherry) Wang, Jie Liu, Jianbo Wu, Shuangyan Yang, Jie Ren, Bhanu Shankar, and Dong Li. 2025. Performance Characterization of CXL Memory and Its Use Cases. InInternational Parallel and Distributed Processing Symposium
2025
-
[50]
Peter Weisberg and Yitzhak Wiseman. 2009. Using 4KB Page Size for Virtual Memory Is Obsolete. InProceedings of the 8th IEEE International Symposium on Network Computing and Applications (NCA). 262–265
2009
-
[51]
K. Wu, Y. Huang, and D. Li. 2017. Unimem: Runtime Data Management on Non-Volatile Memory-based Heterogeneous Main Memory. InIn- ternational Conference for High Performance Computing, Networking, Storage and Analysis
2017
-
[52]
Lingfeng Xiang, Zhen Lin, Arkaprava Basu, and Rong Lv. 2024. Nomad: Non-Exclusive Memory Tiering via Transactional Page Migration. In Proceedings of the 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI)
2024
-
[53]
Dong Xu, Han Meng, Xinyu Chen, Dengcheng Zhu, Wei Tang, Fei Liu, Liguang Xie, Wu Xiang, Rui Shi, Yue Li, Henry Hu, Hui Zhang, Jianping Jiang, and Dong Li. 2026. CCCL: Node-Spanning GPU Collectives with CXL Memory Pooling. arXiv:2602.22457 [cs.DC]https://arxiv.org/abs/ 2602.22457
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[54]
Dong Xu, Junhee Ryu, Jinho Baek, Kwangsik Shin, Pengfei Su, and Dong Li. 2024. FlexMem: Adaptive Page Profiling and Migration for Tiered Memory. In30th USENIX Annual Technical Conference (ATC)
2024
-
[55]
Zi Yan, Daniel Lustig, David Nellans, and Abhishek Bhattacharjee. 2019. Nimble Page Management for Tiered Memory Systems. InProceedings of the 24th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS). 331–345
2019
-
[56]
Shao-Peng Yang, Minjae Kim, Sanghyun Nam, Juhyung Park, Jin yong Choi, Eyee Hyun Nam, Eunji Lee, Sungjin Lee, and Bryan S. Kim. 2023. Overcoming the Memory Wall with CXL-Enabled SSDs. InUSENIX Annual Technical Conference. 14
2023
- [57]
-
[58]
Xinjun Yang, Yingqiang Zhang, Hao Chen, Feifei Li, Gerry Fan, Yang Kong, Bo Wang, Jing Fang, Yuhui Wang, Tao Huang, Wenpu Hu, Jim Kao, and Jianping Jiang. 2025. Unlocking the Potential of CXL for Disaggregated Memory in Cloud-Native Databases. InCompanion of the 2025 International Conference on Management of Data
2025
- [59]
-
[60]
Anil Yelam, Kan Wu, Zhiyuan Guo, Suli Yang, Rajath Shashidhara, Wei Xu, Stanko Novaković, Alex C Snoeren, and Kimberly Keeton
-
[61]
In2025 USENIX Annual Technical Conference (USENIX ATC 25)
{PageFlex}: Flexible and Efficient User-space Delegation of Linux Paging Policies with {eBPF}. In2025 USENIX Annual Technical Conference (USENIX ATC 25). 291–306
-
[62]
Berger, Carl Waldspurger, Ryan Wee, Ishwar Agarwal, Rajat Agarwal, Frank Hady, Karthik Kumar, Mark D
Yuhong Zhong, Daniel S. Berger, Carl Waldspurger, Ryan Wee, Ishwar Agarwal, Rajat Agarwal, Frank Hady, Karthik Kumar, Mark D. Hill, Mosharaf Chowdhury, and Asaf Cidon. 2024. Managing memory tiers with CXL in virtualized environments. InProceedings of the 18th USENIX Conference on Operating Systems Design and Implementation (OSDI)
2024
-
[63]
Zhiting Zhu, Newton Ni, Yibo Huang, Yan Sun, Zhipeng Jia, Nam Sung Kim, and Emmett Witchel. 2024. Lupin: Tolerating partial failures in a cxl pod. InProceedings of the 2nd Workshop on Disruptive Memory Systems
2024
-
[64]
Tal Zussman et al. 2025. cache_ext: Customizing the Page Cache with eBPF. InProceedings of the 30th ACM Symposium on Operating Systems Principles (SOSP)
2025
-
[65]
Tal Zussman, Teng Jiang, and Asaf Cidon. 2024. Custom page fault han- dling with ebpf. InProceedings of the ACM SIGCOMM 2024 Workshop on eBPF and Kernel Extensions. 15
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.