Recognition: unknown
Boosting Robust AIGI Detection with LoRA-based Pairwise Training
Pith reviewed 2026-05-10 14:51 UTC · model grok-4.3
The pith
LoRA-based pairwise training improves AI-generated image detection under severe real-world distortions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors show that a LoRA-based Pairwise Training strategy, built on targeted finetuning of a visual foundation model together with distortion and size simulations to match validation and test distributions, plus a pairwise process that decouples generalization from robustness optimization, delivers robust AIGI detection under severe distortions.
What carries the argument
LoRA-based Pairwise Training (LPT), which applies low-rank adaptation to a visual foundation model while using pairwise comparisons on simulated distorted pairs to separately tune generalization and robustness.
If this is right
- Detectors maintain higher accuracy when images undergo compression, resizing, or other common alterations after generation.
- Simulation of expected data distributions during training reduces the performance drop seen in wild deployment.
- Pairwise training allows independent control over detection accuracy and distortion tolerance without one harming the other.
- Low-rank adaptation makes it practical to adapt large visual models for this task without full retraining.
Where Pith is reading between the lines
- The same decoupling idea could apply to other detection or classification tasks that face distribution shift after initial training.
- More sophisticated or adaptive simulation of distortions might further narrow the remaining gap to real-world conditions.
- The method's reliance on a specific foundation model raises the question of how performance scales when swapping to newer or smaller backbones.
Load-bearing premise
The simulated distortions and size variations introduced during training will sufficiently represent the unpredictable distortions that appear in actual deployment.
What would settle it
A new test set containing distortion types or combinations absent from the training simulations, on which the method shows no gain over standard fine-tuning of the same foundation model.
Figures


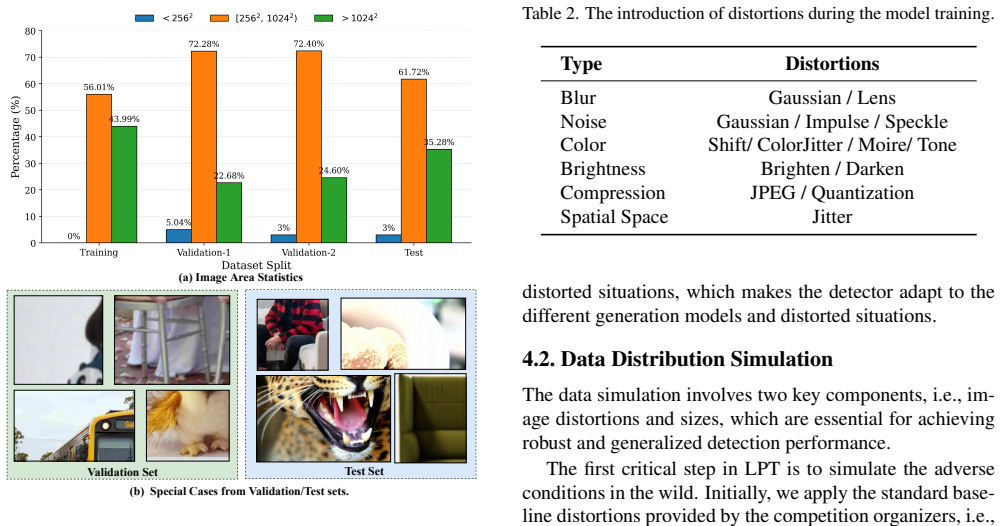

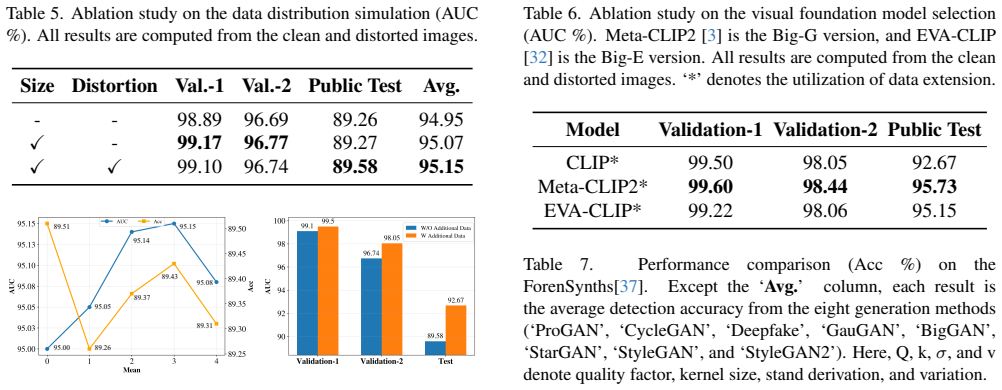
read the original abstract
The proliferation of highly realistic AI-Generated Image (AIGI) has necessitated the development of practical detection methods. While current AIGI detectors perform admirably on clean datasets, their detection performance frequently decreases when deployed "in the wild", where images are subjected to unpredictable, complex distortions. To resolve the critical vulnerability, we propose a novel LoRA-based Pairwise Training (LPT) strategy designed specifically to achieve robust detection for AIGI under severe distortions. The core of our strategy involves the targeted finetuning of a visual foundation model, the deliberate simulation of data distribution during the training phase, and a unique pairwise training process. Specifically, we introduce distortion and size simulations to better fit the distribution from the validation and test sets. Based on the strong visual representation capability of the visual foundation model, we finetune the model to achieve AIGI detection. The pairwise training is utilized to improve the detection via decoupling the generalization and robustness optimization. Experiments show that our approach secured the 3th placement in the NTIRE Robust AI-Generated Image Detection in the Wild challenge
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a LoRA-based Pairwise Training (LPT) strategy for robust AI-generated image (AIGI) detection under severe, unpredictable distortions. The method finetunes a visual foundation model via LoRA, introduces targeted distortion and size simulations during training to align with validation/test distributions, and applies a pairwise training process to separately optimize generalization and robustness. The central empirical claim is that this yields strong performance, evidenced by a third-place ranking in the NTIRE Robust AI-Generated Image Detection in the Wild challenge.
Significance. If the LPT components prove reproducible and the distortion simulations generalize beyond the specific challenge distribution, the work could provide a practical, parameter-efficient route to hardening AIGI detectors for real-world deployment. The combination of LoRA finetuning with explicit distribution simulation and pairwise decoupling is a targeted adaptation for the robustness setting. However, the significance is constrained by the absence of any reported quantitative metrics, ablation results, or out-of-distribution tests, leaving the contribution resting primarily on an unreported challenge ranking rather than transparent evidence.
major comments (3)
- [Abstract] Abstract: The claim that the method 'secured the 3th placement' is presented without any accompanying quantitative results (accuracy, AUC, or F1 on clean vs. distorted images), ablation studies on the LoRA, simulation, or pairwise components, or error bars. Because the central claim of robust detection rests on this empirical outcome, the lack of supporting numbers prevents evaluation of whether LPT actually drives the ranking.
- [Method] Method description (pairwise training): The text states that pairwise training 'decouples the generalization and robustness optimization,' yet supplies no details on pair construction, the specific loss terms, how positive/negative pairs are sampled, or the training schedule. This mechanism is load-bearing for the claimed improvement in robustness and must be specified for the contribution to be assessable.
- [Experiments] Experiments / simulation procedure: Distortion and size simulations are introduced 'to better fit the distribution from the validation and test sets,' but no analysis is given showing coverage of the distortion space or performance on novel combinations outside the challenge set. The robustness claim therefore risks being tied to the particular NTIRE test distribution rather than unpredictable real-world distortions.
minor comments (2)
- [Abstract] Abstract contains the typo '3th placement' (should be '3rd').
- [Abstract] The manuscript would be strengthened by including at least one summary table of key metrics (clean vs. distorted performance) early in the paper, even if full ablations appear later.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We address each major comment point by point below, indicating the revisions we will make to improve clarity, reproducibility, and evidential support.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the method 'secured the 3th placement' is presented without any accompanying quantitative results (accuracy, AUC, or F1 on clean vs. distorted images), ablation studies on the LoRA, simulation, or pairwise components, or error bars. Because the central claim of robust detection rests on this empirical outcome, the lack of supporting numbers prevents evaluation of whether LPT actually drives the ranking.
Authors: We agree that the abstract, constrained by length, does not include supporting metrics or ablations. In the revised manuscript we will expand the abstract to report key quantitative results from the NTIRE challenge (accuracy, AUC on the test set) and will add a dedicated experiments subsection with ablation tables for the LoRA, distortion/size simulation, and pairwise components, including error bars from repeated runs where available. This will make the empirical contribution transparent and directly tied to the ranking. revision: yes
-
Referee: [Method] Method description (pairwise training): The text states that pairwise training 'decouples the generalization and robustness optimization,' yet supplies no details on pair construction, the specific loss terms, how positive/negative pairs are sampled, or the training schedule. This mechanism is load-bearing for the claimed improvement in robustness and must be specified for the contribution to be assessable.
Authors: We acknowledge that the current description of pairwise training is insufficient for reproducibility. In the revised version we will expand the method section with explicit details on pair construction (pairing each image with its simulated-distortion counterpart), the loss terms (standard cross-entropy for generalization and an additional robustness-oriented term), positive/negative pair sampling strategy, and the full training schedule with hyperparameters. This will clarify how the decoupling is achieved and allow independent assessment of the robustness gains. revision: yes
-
Referee: [Experiments] Experiments / simulation procedure: Distortion and size simulations are introduced 'to better fit the distribution from the validation and test sets,' but no analysis is given showing coverage of the distortion space or performance on novel combinations outside the challenge set. The robustness claim therefore risks being tied to the particular NTIRE test distribution rather than unpredictable real-world distortions.
Authors: We recognize the value of demonstrating that the simulations are not narrowly tuned to the challenge distribution. In the revision we will add a detailed breakdown of the distortion types and parameter ranges used, together with coverage analysis (e.g., tables or figures). We will also include performance results on a small number of novel distortion combinations outside the challenge set and a limitations paragraph discussing the extent of generalization to truly unpredictable real-world distortions. Because new large-scale OOD experiments would require additional compute, we mark this revision as partial. revision: partial
Circularity Check
No significant circularity; empirical method validated externally
full rationale
The paper presents an empirical engineering approach (LoRA-based finetuning, deliberate distortion/size simulations, and pairwise training) whose central claim of robustness is supported by 3rd-place ranking on the external NTIRE challenge benchmark. No mathematical derivation, equations, or fitted parameters are presented as predictions that reduce to the inputs by construction. The simulations are described as a design choice to match challenge distributions, but this is not a self-referential reduction or load-bearing self-citation; success is measured against an independent test set rather than by internal consistency alone. The derivation chain is self-contained as a practical training procedure.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Visual foundation models possess strong representation capabilities that can be adapted via LoRA for AIGI detection
- domain assumption Pairwise training can decouple generalization and robustness optimization without harming overall performance
Reference graph
Works this paper leans on
-
[1]
Ruoxin Chen, Junwei Xi, Zhiyuan Yan, Ke-Yue Zhang, Shuang Wu, Jingyi Xie, Xu Chen, Lei Xu, Isabel Guan, Taiping Yao, et al. Dual data alignment makes ai- generated image detector easier generalizable.arXiv preprint arXiv:2505.14359, 2025. 7
-
[2]
Fair deepfake detec- tors can generalize
Harry Cheng, Ming-Hui Liu, Yangyang Guo, Tianyi Wang, Liqiang Nie, and Mohan Kankanhalli. Fair deepfake detec- tors can generalize. InNeurIPS, 2025. 2
2025
-
[3]
Meta clip 2: A worldwide scaling recipe.arXiv preprint arXiv:2507.22062,
Yung-Sung Chuang, Yang Li, Dong Wang, Ching-Feng Yeh, Kehan Lyu, Ramya Raghavendra, James Glass, Lifei Huang, Jason Weston, Luke Zettlemoyer, et al. Meta clip 2: A world- wide scaling recipe.arXiv preprint arXiv:2507.22062, 2025. 7
-
[4]
On the detection of synthetic images generated by diffusion mod- els
Riccardo Corvi, Davide Cozzolino, Giada Zingarini, Gio- vanni Poggi, Koki Nagano, and Luisa Verdoliva. On the detection of synthetic images generated by diffusion mod- els. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2023. 3
2023
-
[5]
Forensics adapter: Adapting clip for generalizable face forgery detection
Xinjie Cui, Yuezun Li, Ao Luo, Jiaran Zhou, and Junyu Dong. Forensics adapter: Adapting clip for generalizable face forgery detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 2
2025
-
[6]
Think twice before detect- ing GAN-generated fake images from their spectral domain imprints
Chengyu Dong, Zhiqi Wang, Ting Yao, Jiale Liang, Shouhong Ding, Jiatong Li, et al. Think twice before detect- ing GAN-generated fake images from their spectral domain imprints. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022. 2
2022
-
[7]
Watch your up-convolution: Cnn based generative deep neural net- works are failing to reproduce spectral distributions
Ricard Durall, Margret Keuper, and Janis Keuper. Watch your up-convolution: Cnn based generative deep neural net- works are failing to reproduce spectral distributions. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020. 2
2020
-
[8]
Leveraging fre- quency analysis for deep fake image recognition
Joel Frank, Thorsten Eisenhofer, Lea Sch ¨onherr, Asja Fis- cher, Dorothea Kolossa, and Thorsten Holz. Leveraging fre- quency analysis for deep fake image recognition. InPro- ceedings of the 37th International Conference on Machine Learning (ICML), 2020. 2
2020
-
[9]
Improving interpretabil- ity and robustness for the detection of ai-generated images
Tatiana Gaintseva, Laida Kushnareva, German Magai, Irina Piontkovskaya, Sergey Nikolenko, Martin Benning, Serguei Barannikov, and Gregory Slabaugh. Improving interpretabil- ity and robustness for the detection of ai-generated images. arXiv preprint arXiv:2406.15035, 2024. 3
-
[10]
NTIRE 2026 Challenge on Robust AI-Generated Image Detection in the Wild
Aleksandr Gushchin, Khaled Abud, Ekaterina Shumitskaya, Artem Filippov, Georgii Bychkov, Sergey Lavrushkin, Mikhail Erofeev, Anastasia Antsiferova, Changsheng Chen, Shunquan Tan, Radu Timofte, Dmitriy Vatolin, et al. NTIRE 2026 Challenge on Robust AI-Generated Image Detection in the Wild . InProceedings of the IEEE/CVF Conference on Computer Vision and Pa...
2026
-
[11]
Parameter-efficient transfer learning for nlp
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Maziar Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for nlp. InProceedings of the 36th Inter- national Conference on Machine Learning (ICML), 2019. 3
2019
-
[12]
LoRA: Low-rank adaptation of large language mod- els
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. LoRA: Low-rank adaptation of large language mod- els. InInternational Conference on Learning Representa- tions (ICLR), 2022. 3, 5
2022
-
[13]
Zhenglin Huang, Tianxiao Li, Xiangtai Li, Haiquan Wen, Yiwei He, Jiangning Zhang, Hao Fei, Xi Yang, Xiaowei Huang, Bei Peng, et al. So-fake: Benchmarking and explain- ing social media image forgery detection.arXiv preprint arXiv:2505.18660, 2025. 6
-
[14]
Scaling up visual and vision-language representa- tion learning with noisy text supervision
Chao Jia, Yinfei Yang, Ye Xia, Yucen Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representa- tion learning with noisy text supervision. InProceedings of the 38th International Conference on Machine Learning (ICML), 2021. 2
2021
-
[15]
Vi- sual prompt tuning
Menglin Jia, Luming Tang, Bor-Chun Chen, Claire Cardie, Serge Belongie, Bharath Hariharan, and Ser-Nam Lim. Vi- sual prompt tuning. InEuropean Conference on Computer Vision (ECCV), 2022. 3 8
2022
-
[16]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 4401–4410, 2019. 1
2019
-
[17]
Despina Konstantinidou, Dimitrios Karageorgiou, Chris- tos Koutlis, Olga Papadopoulou, Emmanouil Schinas, and Symeon Papadopoulos. Navigating the challenges of ai- generated image detection in the wild: What truly matters? arXiv preprint arXiv:2507.10236, 2025. 3
-
[18]
Leveraging rep- resentations from intermediate encoder-blocks for synthetic image detection
Christos Koutlis and Symeon Papadopoulos. Leveraging rep- resentations from intermediate encoder-blocks for synthetic image detection. InEuropean Conference on computer vi- sion, pages 394–411. Springer, 2024. 7
2024
-
[19]
Learning real facial concepts for independent deepfake detection
Ming-Hui Liu, Harry Cheng, Tianyi Wang, Xin Luo, and Xin-Shun Xu. Learning real facial concepts for independent deepfake detection. InIJCAI, pages 1585–1593. ijcai.org,
-
[20]
SGDR: Stochastic Gradient Descent with Warm Restarts
Ilya Loshchilov and Frank Hutter. Sgdr: Stochas- tic gradient descent with warm restarts.arXiv preprint arXiv:1608.03983, 2016. 6
work page internal anchor Pith review arXiv 2016
-
[21]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 6
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[22]
Detecting gan-generated images by orthogo- nal training of multiple cnns
Sara Mandelli, Nicol `o Bonettini, Paolo Bestagini, and Ste- fano Tubaro. Detecting gan-generated images by orthogo- nal training of multiple cnns. In2022 IEEE International Conference on Image Processing (ICIP), pages 3091–3095. IEEE, 2022. 3
2022
-
[23]
Do GANs leave artificial fingerprints? arXiv preprint arXiv:1812.11842, 2019
Francesco Marra, Diego Gragnaniello, Davide Cozzolino, and Luisa Verdoliva. Do GANs leave artificial fingerprints? arXiv preprint arXiv:1812.11842, 2019. 2
-
[24]
Towards uni- versal fake image detectors that generalize across generative models
Utkarsh Ojha, Yuheng Li, and Yong Jae Lee. Towards uni- versal fake image detectors that generalize across generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023. 2
2023
-
[25]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 4195–4205,
-
[26]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 2, 6, 7
2021
-
[27]
Im- proving robustness against common corruptions with fre- quency biased models
Tonmoy Saikia, Cordelia Schmid, and Thomas Brox. Im- proving robustness against common corruptions with fre- quency biased models. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision, pages 10211– 10220, 2021. 5
2021
-
[28]
Shield: An evaluation benchmark for face spoofing and forgery detection with multimodal large lan- guage models.Visual Intelligence, 3(1):9, 2025
Yichen Shi, Yuhao Gao, Yingxin Lai, Hongyang Wang, Jun Feng, Lei He, Jun Wan, Changsheng Chen, Zitong Yu, and Xiaochun Cao. Shield: An evaluation benchmark for face spoofing and forgery detection with multimodal large lan- guage models.Visual Intelligence, 3(1):9, 2025. 1
2025
-
[29]
Flava: A foundational language and vision alignment model
Amanpreet Singh et al. Flava: A foundational language and vision alignment model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022. 2
2022
-
[30]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020. 1
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[31]
Towards general visual-linguistic face forgery detection
Kaixin Sun et al. Towards general visual-linguistic face forgery detection. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR),
-
[32]
EVA-CLIP: Improved Training Techniques for CLIP at Scale
Quan Sun, Yuxin Fang, Ledell Wu, Xinlong Wang, and Yue Cao. Eva-clip: Improved training techniques for clip at scale. arXiv preprint arXiv:2303.15389, 2023. 5, 7
work page internal anchor Pith review arXiv 2023
-
[33]
Rethinking the up-sampling op- erations in cnn-based generative network for generalizable deepfake detection
Chuangchuang Tan, Yao Zhao, Shikui Wei, Guanghua Gu, Ping Liu, and Yunchao Wei. Rethinking the up-sampling op- erations in cnn-based generative network for generalizable deepfake detection. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 28130–28139, 2024. 7
2024
-
[34]
Chuangchuang Tan, Xiang Ming, Jinglu Wang, Renshuai Tao, Bin Li, Yunchao Wei, Yao Zhao, and Yan Lu. Seman- tic visual anomaly detection and reasoning in ai-generated images.arXiv preprint arXiv:2510.10231, 2025. 2
-
[35]
Oddn: Addressing unpaired data challenges in open-world deepfake detection on online social networks
Renshuai Tao, Manyi Le, Chuangchuang Tan, Huan Liu, Haotong Qin, and Yao Zhao. Oddn: Addressing unpaired data challenges in open-world deepfake detection on online social networks. InProceedings of the AAAI Conference on Artificial Intelligence, pages 799–807, 2025. 1
2025
-
[36]
Improving robustness to corruptions with multiplica- tive weight perturbations.Advances in Neural Information Processing Systems, 37:35492–35516, 2024
Trung Trinh, Markus Heinonen, Luigi Acerbi, and Samuel Kaski. Improving robustness to corruptions with multiplica- tive weight perturbations.Advances in Neural Information Processing Systems, 37:35492–35516, 2024. 5
2024
-
[37]
Cnn-generated images are surprisingly easy to spot
Sheng-Yu Wang, Oliver Wang, Richard Zhang, Andrew Owens, and Alexei A Efros. Cnn-generated images are surprisingly easy to spot... for now. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8695–8704, 2020. 1, 2, 3, 7, 8
2020
-
[38]
A sanity check for ai-generated image detection.arXiv preprint arXiv:2406.19435, 2024
Shilin Yan, Ouxiang Li, Jiayin Cai, Yanbin Hao, Xi- aolong Jiang, Yao Hu, and Weidi Xie. A sanity check for ai-generated image detection.arXiv preprint arXiv:2406.19435, 2024. 6
-
[39]
Zhiyuan Yan, Jiangming Wang, Peng Jin, Ke-Yue Zhang, Chengchun Liu, Shen Chen, Taiping Yao, Shouhong Ding, Baoyuan Wu, and Li Yuan. Orthogonal subspace decompo- sition for generalizable ai-generated image detection.arXiv preprint arXiv:2411.15633, 2024. 7
-
[40]
Attributing fake im- ages to GANs: Learning and analyzing GAN fingerprints
Ning Yu, Larry Davis, and Mario Fritz. Attributing fake im- ages to GANs: Learning and analyzing GAN fingerprints. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019. 2
2019
-
[41]
Mlep: Multi-granularity local entropy patterns for generalized ai-generated image detection
Lin Yuan, Xiaowan Li, Yan Zhang, Jiawei Zhang, Hongbo Li, and Xinbo Gao. Mlep: Multi-granularity local entropy patterns for generalized ai-generated image detection. InThe Thirty-ninth Annual Conference on Neural Information Pro- cessing Systems, 2025. 7
2025
-
[42]
Lit: Zero-shot transfer with locked-image text tuning
Xiaohua Zhai, Xiao Wang, Basil Mustafa, Andreas Steiner, Daniel Keysers, Alexander Kolesnikov, and Lucas Beyer. Lit: Zero-shot transfer with locked-image text tuning. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), 2022. 2 9
2022
-
[43]
Adalora: Adap- tive budget allocation for parameter-efficient fine-tuning
Qingru Zhang, Minshuo Chen, Anton Bukharin, Pengcheng He, Yu Cheng, Weizhu Chen, and Tuo Zhao. Adalora: Adap- tive budget allocation for parameter-efficient fine-tuning. InInternational Conference on Learning Representations (ICLR), 2023. 3
2023
-
[44]
Detect- ing and simulating artifacts in GAN fake images.arXiv preprint arXiv:1907.06515, 2019
Xu Zhang, Sidharth Karaman, and Shih-Fu Chang. Detect- ing and simulating artifacts in GAN fake images.arXiv preprint arXiv:1907.06515, 2019. 2
-
[45]
Breaking semantic artifacts for gener- alized ai-generated image detection
Cheng Zheng et al. Breaking semantic artifacts for gener- alized ai-generated image detection. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. 2 10
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.