Recognition: unknown
Black-Box Optimization From Small Offline Datasets via Meta Learning with Synthetic Tasks
Pith reviewed 2026-05-10 16:00 UTC · model grok-4.3
The pith
Meta-learning optimization bias from Gaussian process synthetic tasks improves surrogate ranking for offline black-box optimization in small data regimes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that training a surrogate model via meta-learning on synthetic tasks generated from a Gaussian process prior instills a reusable optimization bias that captures how to rank input designs correctly; fine-tuning this model on a small target dataset then yields better offline optimization performance than prior methods, as demonstrated across diverse continuous and discrete benchmarks in small-data settings.
What carries the argument
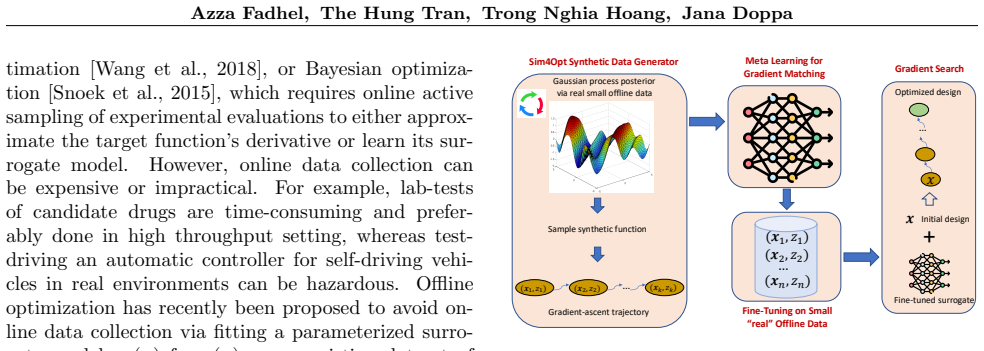
OptBias, the meta-learning framework that generates synthetic tasks from Gaussian process priors to learn and transfer a reusable optimization bias (ranking ability) into the surrogate model before fine-tuning on limited real data.
If this is right
- Surrogate models achieve better ranking of candidate designs even with very limited experimental data.
- Offline optimization becomes practical for scientific problems that only have small or low-quality past datasets.
- Performance gains hold across both continuous and discrete design spaces in standard benchmarks.
- The approach reduces reliance on collecting large new datasets before optimization can proceed.
Where Pith is reading between the lines
- If real functions deviate strongly from Gaussian processes, one might need to generate synthetic tasks from alternative priors or mixture models to maintain transfer.
- The method could be inserted into iterative design loops to provide stronger initial surrogates for subsequent active learning rounds.
- Extensions to structured data such as graphs or sequences would require adapting the synthetic task generator while keeping the same meta-learning structure.
- Combining OptBias with other surrogate architectures might further amplify gains when the base model already encodes domain knowledge.
Load-bearing premise
The optimization bias learned from Gaussian process synthetic tasks will transfer to and improve ranking on real-world small datasets whose underlying functions may differ substantially from the GP prior.
What would settle it
Run OptBias on a benchmark dataset whose objective function is known to be highly discontinuous or adversarial and far from Gaussian process behavior, then check whether it still outperforms the baselines in ranking quality and final optimized value.
Figures


read the original abstract
We consider the problem of offline black-box optimization, where the goal is to discover optimal designs (e.g., molecules or materials) from past experimental data. A key challenge in this setting is data scarcity: in many scientific applications, only small or poor-quality datasets are available, which severely limits the effectiveness of existing algorithms. Prior work has theoretically and empirically shown that performance of offline optimization algorithms depends on how well the surrogate model captures the optimization bias (i.e., ability to rank input designs correctly), which is challenging to accomplish with limited experimental data. This paper proposes Surrogate Learning with Optimization Bias via Synthetic Task Generation (OptBias), a meta-learning framework that directly tackles data scarcity. OptBias learns a reusable optimization bias by training on synthetic tasks generated from a Gaussian process, and then fine-tunes the surrogate model on the small data for the target task. Across diverse continuous and discrete offline optimization benchmarks, OptBias consistently outperforms state-of-the-art baselines in small data regimes. These results highlight OptBias as a robust and practical solution for offline optimization in realistic small data settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes OptBias, a meta-learning framework for offline black-box optimization from small datasets. It generates synthetic tasks from a Gaussian process prior to meta-train a surrogate model that learns optimization bias (i.e., the ability to correctly rank candidate designs), then fine-tunes this surrogate on the limited target data. The central claim is that this approach yields consistent outperformance over state-of-the-art baselines across diverse continuous and discrete offline optimization benchmarks in small-data regimes.
Significance. If the empirical gains hold under scrutiny and the GP-to-real transfer proves robust, the work offers a practical advance for data-scarce scientific optimization tasks such as molecule and materials design. The explicit focus on learning reusable ranking bias via synthetic tasks, rather than direct surrogate fitting, is a clear strength, and the reported results on multiple benchmark types provide initial evidence of utility in realistic small-data settings.
major comments (2)
- [Method and Experiments sections] The central empirical claim (consistent outperformance in small-data regimes) rests on transfer from GP-generated synthetic tasks to real benchmarks, yet the manuscript provides no theoretical transfer bound, no ablation on GP kernel choice or hyperprior mismatch, and no analysis of how non-stationary or discrete structure in target functions (e.g., molecule design) deviates from the GP prior. This directly affects whether the reported gains are general or benchmark-specific.
- [Experimental evaluation] The abstract and available description report outperformance without accompanying error bars, data-split details, or statistical significance tests. Because the soundness of the central claim depends on these experimental controls, their absence prevents verification that the gains exceed baseline variability.
minor comments (2)
- [Method] Notation for the meta-training objective and the fine-tuning step could be clarified with an explicit equation relating the learned bias embedding to the final ranking loss.
- [Figures] Figure captions should explicitly state the number of independent runs and the precise small-data regime sizes used for each benchmark.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Method and Experiments sections] The central empirical claim (consistent outperformance in small-data regimes) rests on transfer from GP-generated synthetic tasks to real benchmarks, yet the manuscript provides no theoretical transfer bound, no ablation on GP kernel choice or hyperprior mismatch, and no analysis of how non-stationary or discrete structure in target functions (e.g., molecule design) deviates from the GP prior. This directly affects whether the reported gains are general or benchmark-specific.
Authors: We agree that a formal theoretical transfer bound would strengthen the claims, but deriving non-vacuous bounds for meta-learned ranking bias under GP-to-real distribution shift is a substantial open theoretical problem that lies beyond the scope of the current empirical contribution. We will add a dedicated limitations paragraph acknowledging this gap. To address the remaining concerns, we will include new ablations varying the GP kernel family (RBF, Matérn-3/2, Matérn-5/2) and hyperprior parameters, together with an expanded analysis section that quantifies performance degradation on benchmarks exhibiting clear non-stationarity or discrete structure (e.g., the molecule-design tasks). These additions will clarify the conditions under which the observed gains remain reliable. revision: partial
-
Referee: [Experimental evaluation] The abstract and available description report outperformance without accompanying error bars, data-split details, or statistical significance tests. Because the soundness of the central claim depends on these experimental controls, their absence prevents verification that the gains exceed baseline variability.
Authors: We accept this criticism. The revised manuscript will report mean performance with standard-error bars computed over at least five independent random seeds, provide explicit descriptions of all train/validation/test splits and preprocessing steps, and include statistical significance tests (paired Wilcoxon signed-rank tests with Holm-Bonferroni correction) comparing OptBias against each baseline. These controls will be added to all tables and figures in the experimental section. revision: yes
- Deriving a non-trivial theoretical transfer bound from GP-generated synthetic tasks to arbitrary real-world black-box optimization functions
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes OptBias as a meta-learning framework that generates synthetic tasks from a Gaussian process prior (independent of target data), meta-trains a surrogate to capture optimization bias on those tasks, and then fine-tunes on small real offline datasets. No equations or steps in the provided text reduce the final performance claim to a self-definition, a fitted parameter renamed as prediction, or a load-bearing self-citation chain. Synthetic task generation uses a standard GP prior that does not encode the target benchmarks by construction, and evaluation occurs on external continuous/discrete benchmarks. The central transfer claim is empirical rather than tautological.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Can Sam Chen, Christopher Beckham, Zixuan Liu, Xue Liu, and Christopher Pal
URLhttps://arxiv.org/abs/2309.11592. Can Sam Chen, Christopher Beckham, Zixuan Liu, Xue Liu, and Christopher Pal. Robust guided dif- fusion for offline black-box optimization.arXiv preprint arXiv:2410.00983, 2024. Shankar Dara et al. Machine learning in drug discov- ery: A review.Archives of Computational Methods in Engineering, 2021. Aryan Deshwal and Ja...
-
[2]
Azza Fadhel, Yassine Chemingui, Minh Hoang, Aryan Deshwal, Trong Nghia Hoang, and Jana Doppa
PMLR, 2023. Azza Fadhel, Yassine Chemingui, Minh Hoang, Aryan Deshwal, Trong Nghia Hoang, and Jana Doppa. Nanoporous materials discovery via search bias- guided surrogate modeling. InProceedings of the AAAI Conference on Artificial Intelligence, vol- ume 40, pages 38422–38431, 2026a. Azza Fadhel, Nathaniel W Zuckschwerdt, Aryan Desh- wal, Susmita Bose, Am...
-
[3]
PMLR, 2018a. Marta Garnelo, Jonathan Schwarz, Dan Rosenbaum, Fabio Viola, Danilo J Rezende, SM Eslami, and Yee Whye Teh. Neural processes.arXiv preprint arXiv:1807.01622, 2018b. Roman Garnett.Bayesian optimization. Cambridge University Press, 2023. Ethan Goan and Clinton Fookes. Bayesian neural net- works: An introduction and survey. InCase Stud- ies in A...
-
[4]
Ye Yuan, Youyuan Zhang, Can Chen, Haolun Wu, Zix- uan Li, Jianmo Li, James J Clark, and Xue Liu
URLhttps://arxiv.org/abs/2309.11600. Ye Yuan, Youyuan Zhang, Can Chen, Haolun Wu, Zix- uan Li, Jianmo Li, James J Clark, and Xue Liu. Design editing for offline model-based optimization. arXiv preprint arXiv:2405.13964, 2024. Taeyoung Yun, Sujin Yun, Jaewoo Lee, and Jinkyoo Park. Guided trajectory generation with diffusion models for offline model-based o...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.