Recognition: unknown
All in One: A Unified Synthetic Data Pipeline for Multimodal Video Understanding
Pith reviewed 2026-05-10 15:23 UTC · model grok-4.3
The pith
A unified synthetic pipeline generates unlimited multimodal video data that trains models to generalize to real datasets and often outperform real-data training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
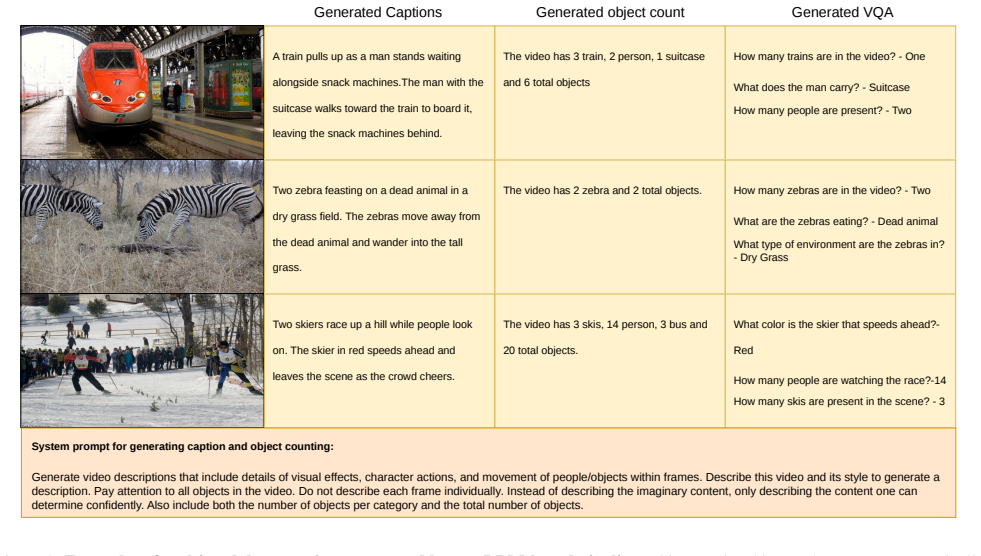
We introduce a unified synthetic data generation pipeline that automatically produces unlimited multimodal video data with rich and diverse supervision across multiple task formats. We further add a VQA-based fine-tuning strategy that trains models to answer structured questions about visual content. Models trained predominantly on data from this pipeline generalize effectively to real-world datasets in video object counting, video-based visual question answering, and video object segmentation, often outperforming models trained on traditional real data.
What carries the argument
The unified synthetic data generation pipeline that produces consistent multimodal video data with annotations for multiple tasks in one framework, together with a VQA-based fine-tuning method that requires structured answers about visual content.
Load-bearing premise
The synthetic videos and their annotations are realistic enough in appearance, motion, and semantics that models can learn from them and apply the knowledge directly to real videos.
What would settle it
A controlled experiment in which models trained only on the synthetic data are tested on standard real-world benchmarks for counting, VQA, or segmentation and show clearly lower accuracy than equivalent models trained on real annotated data.
Figures



read the original abstract
Training multimodal large language models (MLLMs) for video understanding requires large-scale annotated data spanning diverse tasks such as object counting, question answering, and segmentation. However, collecting and annotating multimodal video data in real-world is costly, slow, and inherently limited in diversity and coverage. To address this challenge, we propose a unified synthetic data generation pipeline capable of automatically producing unlimited multimodal video data with rich and diverse supervision. Our framework supports multiple task formats within a single pipeline, enabling scalable and consistent data creation across tasks. To further enhance reasoning ability, we introduce a VQA-based fine-tuning strategy that trains models to answer structured questions about visual content rather than relying solely on captions or simple instructions. This formulation encourages deeper visual grounding and reasoning. We evaluate our approach in three challenging tasks: video object counting, video-based visual question answering, and video object segmentation. Experimental results demonstrate that models trained predominantly on synthetic data generalize effectively to real-world datasets, often outperforming traditionally trained counterparts. Our findings highlight the potential of unified synthetic data pipelines as a scalable alternative to expensive real-world annotation for multimodal video understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a unified synthetic data generation pipeline that automatically produces large-scale multimodal video data with rich annotations supporting multiple tasks (object counting, VQA, and segmentation) within a single framework. It introduces a VQA-based fine-tuning strategy to promote deeper visual reasoning in MLLMs and reports that models trained predominantly on this synthetic data generalize well to real-world video benchmarks, often outperforming models trained on conventional real-world datasets.
Significance. If the central claims are substantiated with proper controls, the work could have substantial significance for multimodal video understanding by demonstrating a scalable, low-cost alternative to real-world data collection and annotation, potentially enabling broader experimentation and deployment of MLLMs in video tasks.
major comments (1)
- [Experimental evaluation] The experimental comparisons between predominantly synthetic training and traditional real-world training do not report or control for total training data volume (sample counts, tokens, or epoch budgets). Without ablations that hold data scale fixed while varying source, it is impossible to isolate whether reported gains arise from the unified pipeline, VQA fine-tuning, or simply from differences in data quantity. This directly undermines the headline claim of effective generalization and outperformance.
minor comments (1)
- [Abstract] The abstract would be strengthened by including at least one key quantitative result (e.g., accuracy delta on a specific benchmark) to allow immediate assessment of effect size.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address the major comment point by point below and will revise the manuscript to incorporate the suggested controls.
read point-by-point responses
-
Referee: [Experimental evaluation] The experimental comparisons between predominantly synthetic training and traditional real-world training do not report or control for total training data volume (sample counts, tokens, or epoch budgets). Without ablations that hold data scale fixed while varying source, it is impossible to isolate whether reported gains arise from the unified pipeline, VQA fine-tuning, or simply from differences in data quantity. This directly undermines the headline claim of effective generalization and outperformance.
Authors: We agree that the current experiments do not explicitly control for or report total training data volume, which limits the ability to isolate the contribution of the synthetic pipeline and VQA fine-tuning from potential differences in data scale. In the revised manuscript, we will add new ablations that hold the number of training samples (and report approximate token budgets and epoch counts) fixed across synthetic-only, real-only, and mixed training regimes for each task. These controls will allow direct comparison of data sources while clarifying the source of the reported generalization gains. revision: yes
Circularity Check
No significant circularity; empirical evaluation uses independent real-world benchmarks
full rationale
The paper describes a synthetic data generation pipeline and reports empirical results from training models on that data then testing on separate real-world video datasets for counting, VQA, and segmentation. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the abstract or described claims. Generalization performance is measured against external real data, satisfying the criterion for self-contained evaluation against external benchmarks. The skeptic concern about data volume is an experimental-design issue, not a circular reduction of the derivation to its inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- various hyperparameters in the data generation and model training
axioms (1)
- domain assumption Synthetic data can approximate real-world video distributions sufficiently for generalization.
Reference graph
Works this paper leans on
-
[1]
Vqa: Visual question answering
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C Lawrence Zitnick, and Devi Parikh. Vqa: Visual question answering. InProceedings of the IEEE international conference on computer vision, pages 2425–2433, 2015. 2
2015
-
[2]
Shekoofeh Azizi, Simon Kornblith, Chitwan Saharia, Mo- hammad Norouzi, and David J Fleet. Synthetic data from diffusion models improves imagenet classification.arXiv preprint arXiv:2304.08466, 2023. 3
-
[3]
Ai- generated video detection via spatial-temporal anomaly learning
Jianfa Bai, Man Lin, Gang Cao, and Zijie Lou. Ai- generated video detection via spatial-temporal anomaly learning. InChinese Conference on Pattern Recognition and Computer Vision (PRCV), pages 460–470. Springer,
-
[4]
Tianyi Bai, Hao Liang, Binwang Wan, Yanran Xu, Xi Li, Shiyu Li, Ling Yang, Bozhou Li, Yifan Wang, Bin Cui, et al. A survey of multimodal large language model from a data-centric perspective.arXiv preprint arXiv:2405.16640,
-
[5]
Learning to see by looking at noise.Advances in Neural Information Processing Systems, 34:2556–2569, 2021
Manel Baradad Jurjo, Jonas Wulff, Tongzhou Wang, Phillip Isola, and Antonio Torralba. Learning to see by looking at noise.Advances in Neural Information Processing Systems, 34:2556–2569, 2021. 3
2021
-
[6]
Cnn detection of gan-generated face im- ages based on cross-band co-occurrences analysis
Mauro Barni, Kassem Kallas, Ehsan Nowroozi, and Benedetta Tondi. Cnn detection of gan-generated face im- ages based on cross-band co-occurrences analysis. In2020 IEEE international workshop on information forensics and security (WIFS), pages 1–6. IEEE, 2020. 2
2020
-
[7]
Samyadeep Basu, Maziar Sanjabi, Daniela Massiceti, Shell Xu Hu, and Soheil Feizi. Augmenting clip with improved visio-linguistic reasoning.arXiv preprint arXiv:2307.09233, 2(6):10, 2023. 3
-
[8]
This dataset does not exist: train- ing models from generated images
Victor Besnier, Himalaya Jain, Andrei Bursuc, Matthieu Cord, and Patrick P´erez. This dataset does not exist: train- ing models from generated images. InICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2020. 3
2020
-
[9]
Ioana Bica, Anastasija Ili ´c, Matthias Bauer, Goker Erdo- gan, Matko Bo ˇsnjak, Christos Kaplanis, Alexey A Grit- senko, Matthias Minderer, Charles Blundell, Razvan Pas- canu, et al. Improving fine-grained understanding in image- text pre-training.arXiv preprint arXiv:2401.09865, 2024. 3
-
[10]
Make it count: Text-to-image generation with an accurate number of objects
Lital Binyamin, Yoad Tewel, Hilit Segev, Eran Hirsch, Royi Rassin, and Gal Chechik. Make it count: Text-to-image generation with an accurate number of objects. InProceed- ings of the Computer Vision and Pattern Recognition Con- ference, pages 13242–13251, 2025. 2
2025
-
[11]
Revisiting the” video” in video-language understanding
Shyamal Buch, Crist ´obal Eyzaguirre, Adrien Gaidon, Jia- jun Wu, Li Fei-Fei, and Juan Carlos Niebles. Revisiting the” video” in video-language understanding. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2917–2927, 2022. 1
2022
-
[12]
One- shot video object segmentation
Sergi Caelles, Kevis-Kokitsi Maninis, Jordi Pont-Tuset, Laura Leal-Taix´e, Daniel Cremers, and Luc Van Gool. One- shot video object segmentation. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 221–230, 2017. 2
2017
-
[13]
Natural language infer- ence improves compositionality in vision-language models
Paola Cascante-Bonilla, Yu Hou, Yang Trista Cao, Hal Daum´e III, and Rachel Rudinger. Natural language infer- ence improves compositionality in vision-language models. arXiv preprint arXiv:2410.22315, 2024. 3
-
[14]
Santiago Castro, Amir Ziai, Avneesh Saluja, Zhuoning Yuan, and Rada Mihalcea. Clove: Encoding compositional language in contrastive vision-language models.arXiv preprint arXiv:2402.15021, 2024. 3
-
[15]
What makes fake images detectable? understanding prop- erties that generalize
Lucy Chai, David Bau, Ser-Nam Lim, and Phillip Isola. What makes fake images detectable? understanding prop- erties that generalize. InEuropean conference on computer vision, pages 103–120. Springer, 2020. 2
2020
-
[16]
All you may need for vqa are image captions
Soravit Changpinyo, Doron Kukliansy, Idan Szpektor, Xi Chen, Nan Ding, and Radu Soricut. All you may need for vqa are image captions. InProceedings of the 2022 confer- ence of the north american chapter of the association for computational linguistics: human language technologies, pages 1947–1963, 2022. 1
2022
-
[17]
Smote: synthetic minority over- sampling technique.Journal of artificial intelligence re- search, 16:321–357, 2002
Nitesh V Chawla, Kevin W Bowyer, Lawrence O Hall, and W Philip Kegelmeyer. Smote: synthetic minority over- sampling technique.Journal of artificial intelligence re- search, 16:321–357, 2002. 2
2002
-
[18]
Text analysis for detecting terrorism-related articles on the web.Journal of Network and Computer Applica- tions, 38:16–21, 2014
Dongjin Choi, Byeongkyu Ko, Heesun Kim, and Pankoo Kim. Text analysis for detecting terrorism-related articles on the web.Journal of Network and Computer Applica- tions, 38:16–21, 2014. 8
2014
-
[19]
The epic-kitchens dataset: Collection, challenges and baselines.IEEE Transactions on Pattern Analysis and Ma- chine Intelligence, 43(11):4125–4141, 2020
Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Sanja Fidler, Antonino Furnari, Evangelos Kazakos, Da- vide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, et al. The epic-kitchens dataset: Collection, challenges and baselines.IEEE Transactions on Pattern Analysis and Ma- chine Intelligence, 43(11):4125–4141, 2020. 2
2020
-
[20]
An overview of privacy in machine learning.arXiv preprint arXiv:2005.08679, 2020
Emiliano De Cristofaro. An overview of privacy in machine learning.arXiv preprint arXiv:2005.08679, 2020. 1
-
[21]
An introduction to variational autoencoders.Foundations and Trends® in Ma- chine Learning, 12(4):307–392, 2019
P Kingma Diederik and Welling Max. An introduction to variational autoencoders.Foundations and Trends® in Ma- chine Learning, 12(4):307–392, 2019. 2
2019
-
[22]
Explaining deepfake detection by analysing im- age matching
Shichao Dong, Jin Wang, Jiajun Liang, Haoqiang Fan, and Renhe Ji. Explaining deepfake detection by analysing im- age matching. InEuropean conference on computer vision, pages 18–35. Springer, 2022. 2
2022
-
[23]
Dense and aligned captions (dac) promote compositional reason- ing in vl models.Advances in Neural Information Process- ing Systems, 36:76137–76150, 2023
Sivan Doveh, Assaf Arbelle, Sivan Harary, Roei Herzig, Donghyun Kim, Paola Cascante-Bonilla, Amit Alfassy, Rameswar Panda, Raja Giryes, Rogerio Feris, et al. Dense and aligned captions (dac) promote compositional reason- ing in vl models.Advances in Neural Information Process- ing Systems, 36:76137–76150, 2023. 3
2023
-
[24]
Teaching structured vision & language concepts to vision & language models
Sivan Doveh, Assaf Arbelle, Sivan Harary, Eli Schwartz, Roei Herzig, Raja Giryes, Rogerio Feris, Rameswar Panda, Shimon Ullman, and Leonid Karlinsky. Teaching structured vision & language concepts to vision & language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2657–2668, 2023. 3
2023
-
[25]
Sugarcrepe++ dataset: Vision-language model 9 sensitivity to semantic and lexical alterations.Advances in Neural Information Processing Systems, 37:17972–18018,
Sri Harsha Dumpala, Aman Jaiswal, Chandramouli Shama Sastry, Evangelos Milios, Sageev Oore, and Has- san Sajjad. Sugarcrepe++ dataset: Vision-language model 9 sensitivity to semantic and lexical alterations.Advances in Neural Information Processing Systems, 37:17972–18018,
-
[26]
Leveraging frequency analysis for deep fake image recognition
Joel Frank, Thorsten Eisenhofer, Lea Sch ¨onherr, Asja Fis- cher, Dorothea Kolossa, and Thorsten Holz. Leveraging frequency analysis for deep fake image recognition. InIn- ternational conference on machine learning, pages 3247–
-
[27]
Vane-bench: Video anomaly evaluation benchmark for conversational lmms
Hanan Gani, Rohit Bharadwaj, Muzammal Naseer, Fa- had Shahbaz Khan, and Salman Khan. Vane-bench: Video anomaly evaluation benchmark for conversational lmms. In Findings of the Association for Computational Linguistics: NAACL 2025, pages 3123–3140, 2025. 3
2025
-
[28]
Jiahui Gao, Renjie Pi, Yong Lin, Hang Xu, Jiacheng Ye, Zhiyong Wu, Weizhong Zhang, Xiaodan Liang, Zhenguo Li, and Lingpeng Kong. Self-guided noise-free data gen- eration for efficient zero-shot learning.arXiv preprint arXiv:2205.12679, 2022. 3
-
[29]
Deep learning for video object segmentation: a review.Artificial Intelligence Re- view, 56(1):457–531, 2023
Mingqi Gao, Feng Zheng, James JQ Yu, Caifeng Shan, Guiguang Ding, and Jungong Han. Deep learning for video object segmentation: a review.Artificial Intelligence Re- view, 56(1):457–531, 2023. 2
2023
-
[30]
Generative adversarial networks.Com- munications of the ACM, 63(11):139–144, 2020
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks.Com- munications of the ACM, 63(11):139–144, 2020. 2
2020
-
[31]
Making the v in vqa matter: El- evating the role of image understanding in visual ques- tion answering
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the v in vqa matter: El- evating the role of image understanding in visual ques- tion answering. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 6904–6913,
-
[32]
Diego Gragnaniello, Davide Cozzolino, Francesco Marra, Giovanni Poggi, and Luisa Verdoliva. Are gan generated images easy to detect? a critical analysis of the state-of- the-art.arXiv preprint arXiv:2104.02617, 2021. 2
-
[33]
How close is ChatGPT to human experts? Comparison corpus, evaluation, and detection
Biyang Guo, Xin Zhang, Ziyuan Wang, Minqi Jiang, Jinran Nie, Yuxuan Ding, Jianwei Yue, and Yupeng Wu. How close is chatgpt to human experts? compar- ison corpus, evaluation, and detection.arXiv preprint arXiv:2301.07597, 2023. 3
-
[34]
Ruifei He, Shuyang Sun, Xin Yu, Chuhui Xue, Wenqing Zhang, Philip Torr, Song Bai, and Xiaojuan Qi. Is synthetic data from generative models ready for image recognition? arXiv preprint arXiv:2210.07574, 2022. 3
-
[35]
Generate, annotate, and learn: Nlp with synthetic text.Transactions of the Association for Computational Linguistics, 10:826–842, 2022
Xuanli He, Islam Nassar, Jamie Kiros, Gholamreza Haffari, and Mohammad Norouzi. Generate, annotate, and learn: Nlp with synthetic text.Transactions of the Association for Computational Linguistics, 10:826–842, 2022. 3
2022
-
[36]
Incorporating structured representations into pretrained vi- sion & language models using scene graphs
Roei Herzig, Alon Mendelson, Leonid Karlinsky, Assaf Ar- belle, Rogerio Feris, Trevor Darrell, and Amir Globerson. Incorporating structured representations into pretrained vi- sion & language models using scene graphs. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 14077–14098, 2023. 3
2023
-
[37]
On pre-trained image features and synthetic images for deep learning
Stefan Hinterstoisser, Vincent Lepetit, Paul Wohlhart, and Kurt Konolige. On pre-trained image features and synthetic images for deep learning. InProceedings of the European Conference on Computer Vision (ECCV) Workshops, pages 0–0, 2018. 3
2018
-
[38]
Root mean square error (rmse) or mean absolute error (mae): When to use them or not.Geoscien- tific Model Development Discussions, 2022:1–10, 2022
Timothy O Hodson. Root mean square error (rmse) or mean absolute error (mae): When to use them or not.Geoscien- tific Model Development Discussions, 2022:1–10, 2022. 8
2022
-
[39]
Unnatural instructions: Tuning language mod- els with (almost) no human labor
Or Honovich, Thomas Scialom, Omer Levy, and Timo Schick. Unnatural instructions: Tuning language mod- els with (almost) no human labor. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14409–14428,
-
[40]
Evading deepfake detectors via adversar- ial statistical consistency
Yang Hou, Qing Guo, Yihao Huang, Xiaofei Xie, Lei Ma, and Jianjun Zhao. Evading deepfake detectors via adversar- ial statistical consistency. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12271–12280, 2023. 2
2023
-
[41]
Sugarcrepe: Fixing hackable benchmarks for vision-language compositional- ity.Advances in neural information processing systems, 36: 31096–31116, 2023
Cheng-Yu Hsieh, Jieyu Zhang, Zixian Ma, Aniruddha Kembhavi, and Ranjay Krishna. Sugarcrepe: Fixing hackable benchmarks for vision-language compositional- ity.Advances in neural information processing systems, 36: 31096–31116, 2023. 3
2023
-
[42]
Scaling up vision-language pre-training for image captioning
Xiaowei Hu, Zhe Gan, Jianfeng Wang, Zhengyuan Yang, Zicheng Liu, Yumao Lu, and Lijuan Wang. Scaling up vision-language pre-training for image captioning. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17980–17989, 2022. 1
2022
-
[43]
Promptcap: Prompt-guided im- age captioning for vqa with gpt-3
Yushi Hu, Hang Hua, Zhengyuan Yang, Weijia Shi, Noah A Smith, and Jiebo Luo. Promptcap: Prompt-guided im- age captioning for vqa with gpt-3. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2963–2975, 2023. 1
2023
-
[44]
Video-to-audio generation with fine-grained temporal semantics.arXiv preprint arXiv:2409.14709, 2024
Yuchen Hu, Yu Gu, Chenxing Li, Rilin Chen, and Dong Yu. Video-to-audio generation with fine-grained temporal semantics.arXiv preprint arXiv:2409.14709, 2024. 4
-
[45]
Structure-clip: Towards scene graph knowledge to enhance multi-modal structured representations
Yufeng Huang, Jiji Tang, Zhuo Chen, Rongsheng Zhang, Xinfeng Zhang, Weijie Chen, Zeng Zhao, Zhou Zhao, Tangjie Lv, Zhipeng Hu, et al. Structure-clip: Towards scene graph knowledge to enhance multi-modal structured representations. InProceedings of the AAAI conference on artificial intelligence, pages 2417–2425, 2024. 3
2024
-
[46]
Learning with label noise for im- age retrieval by selecting interactions
Sarah Ibrahimi, Arnaud Sors, Rafael Sampaio de Rezende, and St´ephane Clinchant. Learning with label noise for im- age retrieval by selecting interactions. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 2181–2190, 2022. 3
2022
-
[47]
Revisiting temporal modeling for video super-resolution
Takashi Isobe, Fang Zhu, Xu Jia, and Shengjin Wang. Revisiting temporal modeling for video super-resolution. arXiv preprint arXiv:2008.05765, 2020. 1
-
[48]
Distinguish any fake videos: Unleashing the power of large-scale data and motion features,
Lichuan Ji, Yingqi Lin, Zhenhua Huang, Yan Han, Xiao- gang Xu, Jiafei Wu, Chong Wang, and Zhe Liu. Distin- guish any fake videos: Unleashing the power of large-scale data and motion features.arXiv preprint arXiv:2405.15343,
-
[49]
Vqa2: visual question answer- ing for video quality assessment
Ziheng Jia, Zicheng Zhang, Jiaying Qian, Haoning Wu, Wei Sun, Chunyi Li, Xiaohong Liu, Weisi Lin, Guangtao Zhai, and Xiongkuo Min. Vqa2: visual question answer- ing for video quality assessment. InProceedings of the 10 33rd ACM International Conference on Multimedia, pages 6751–6760, 2025. 1
2025
-
[50]
What’s “up” with vision-language models? investigating their struggle with spatial reasoning
Amita Kamath, Jack Hessel, and Kai-Wei Chang. What’s “up” with vision-language models? investigating their struggle with spatial reasoning. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 9161–9175, 2023. 3
2023
-
[51]
Is clip ideal? no
Raphi Kang, Yue Song, Georgia Gkioxari, and Pietro Per- ona. Is clip ideal? no. can we fix it? yes! InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 22436–22446, 2025. 8
2025
-
[52]
SRL-CLIP: Efficient CLIP Video Adaptation via Structured Semantic Role Labels
Zeeshan Khan, Makarand Tapaswi, et al. Figclip: Fine- grained clip adaptation via densely annotated videos.arXiv preprint arXiv:2401.07669, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
Misalign, contrast then distill: Rethinking misalign- ments in language-image pre-training
Bumsoo Kim, Yeonsik Jo, Jinhyung Kim, and Seunghwan Kim. Misalign, contrast then distill: Rethinking misalign- ments in language-image pre-training. InProceedings of the IEEE/CVF international conference on computer vi- sion, pages 2563–2572, 2023. 3
2023
-
[54]
Segment anything
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. InProceedings of the IEEE/CVF international conference on computer vision, pages 4015–4026, 2023. 4, 6
2023
-
[55]
Visual genome: Connecting language and vision using crowdsourced dense image annotations.International journal of computer vi- sion, 123(1):32–73, 2017
Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalan- tidis, Li-Jia Li, David A Shamma, et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations.International journal of computer vi- sion, 123(1):32–73, 2017. 2
2017
-
[56]
Data augmentation using pre-trained transformer models
Varun Kumar, Ashutosh Choudhary, and Eunah Cho. Data augmentation using pre-trained transformer models. InPro- ceedings of the 2nd workshop on life-long learning for spo- ken language systems, pages 18–26, 2020. 3
2020
-
[57]
Learning to learn from noisy labeled data
Junnan Li, Yongkang Wong, Qi Zhao, and Mohan S Kankanhalli. Learning to learn from noisy labeled data. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5051–5059, 2019. 3
2019
-
[58]
Learn- ing from noisy data with robust representation learning
Junnan Li, Caiming Xiong, and Steven CH Hoi. Learn- ing from noisy data with robust representation learning. In Proceedings of the IEEE/CVF international conference on computer vision, pages 9485–9494, 2021. 3
2021
-
[59]
Uniformerv2: Unlocking the potential of image vits for video understanding
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Limin Wang, and Yu Qiao. Uniformerv2: Unlocking the potential of image vits for video understanding. InProceed- ings of the IEEE/CVF International Conference on Com- puter Vision, pages 1632–1643, 2023. 2
2023
-
[60]
Videochat: Chat-centric video understanding.Science China Information Sciences, 68(10):200102, 2025
KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. Videochat: Chat-centric video understanding.Science China Information Sciences, 68(10):200102, 2025. 1
2025
-
[61]
Fakebench: Probing explainable fake image detection via large multi- modal models.IEEE Transactions on Information Foren- sics and Security, 2025
Yixuan Li, Xuelin Liu, Xiaoyang Wang, Bu Sung Lee, Shiqi Wang, Anderson Rocha, and Weisi Lin. Fakebench: Probing explainable fake image detection via large multi- modal models.IEEE Transactions on Information Foren- sics and Security, 2025. 3
2025
-
[62]
Multi- granularity video object segmentation
Sangbeom Lim, Seongchan Kim, Seungjun An, Seokju Cho, Paul Hongsuck Seo, and Seungryong Kim. Multi- granularity video object segmentation. InProceedings of the AAAI Conference on Artificial Intelligence, pages 5200– 5208, 2025. 4, 7
2025
-
[63]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll ´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014. 2, 5
2014
-
[64]
Noise-resistant deep metric learning with ranking-based in- stance selection
Chang Liu, Han Yu, Boyang Li, Zhiqi Shen, Zhanning Gao, Peiran Ren, Xuansong Xie, Lizhen Cui, and Chunyan Miao. Noise-resistant deep metric learning with ranking-based in- stance selection. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, pages 6811–6820, 2021. 3
2021
-
[65]
Revisiting temporal modeling for clip-based image-to-video knowledge transferring
Ruyang Liu, Jingjia Huang, Ge Li, Jiashi Feng, Xinglong Wu, and Thomas H Li. Revisiting temporal modeling for clip-based image-to-video knowledge transferring. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6555–6564, 2023. 1
2023
-
[66]
Learn to explain: Multimodal reasoning via thought chains for science question answering.Ad- vances in neural information processing systems, 35:2507– 2521, 2022
Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering.Ad- vances in neural information processing systems, 35:2507– 2521, 2022. 3
2022
-
[67]
Seeing is not always be- lieving: Benchmarking human and model perception of ai- generated images.Advances in neural information process- ing systems, 36:25435–25447, 2023
Zeyu Lu, Di Huang, Lei Bai, Jingjing Qu, Chengyue Wu, Xihui Liu, and Wanli Ouyang. Seeing is not always be- lieving: Benchmarking human and model perception of ai- generated images.Advances in neural information process- ing systems, 36:25435–25447, 2023. 3
2023
-
[68]
Gen- erating training data with language models: Towards zero- shot language understanding.Advances in Neural Informa- tion Processing Systems, 35:462–477, 2022
Yu Meng, Jiaxin Huang, Yu Zhang, and Jiawei Han. Gen- erating training data with language models: Towards zero- shot language understanding.Advances in Neural Informa- tion Processing Systems, 35:462–477, 2022. 3
2022
-
[69]
Improving multimodal datasets with image captioning.NeurIPS, 36:22047–22069,
Thao Nguyen, Samir Yitzhak Gadre, Gabriel Ilharco, Se- woong Oh, and Ludwig Schmidt. Improving multimodal datasets with image captioning.NeurIPS, 36:22047–22069,
-
[70]
Synthesize diagnose and optimize: Towards fine- grained vision-language understanding
Wujian Peng, Sicheng Xie, Zuyao You, Shiyi Lan, and Zux- uan Wu. Synthesize diagnose and optimize: Towards fine- grained vision-language understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13279–13288, 2024. 3
2024
-
[71]
VisDA: The Visual Domain Adaptation Challenge
Xingchao Peng, Ben Usman, Neela Kaushik, Judy Hoff- man, Dequan Wang, and Kate Saenko. Visda: The visual domain adaptation challenge.arXiv preprint arXiv:1710.06924, 2017. 3
work page Pith review arXiv 2017
-
[72]
Capture: Evaluating spatial reasoning in vision language models via occluded object counting
Atin Pothiraj, Elias Stengel-Eskin, Jaemin Cho, and Mo- hit Bansal. Capture: Evaluating spatial reasoning in vision language models via occluded object counting. InProceed- ings of the IEEE/CVF International Conference on Com- puter Vision, pages 8001–8010, 2025. 2
2025
-
[73]
The artificial intelligence cognitive examination: A survey on the evolution of multimodal evaluation from recognition to reasoning.IEEE Access, 14:2690–2725, 2025
Mayank Ravishankara and Varindra V Persad Maharaj. The artificial intelligence cognitive examination: A survey on the evolution of multimodal evaluation from recognition to reasoning.IEEE Access, 14:2690–2725, 2025. 1 11
2025
-
[74]
Speech recognition with augmented synthesized speech
Andrew Rosenberg, Yu Zhang, Bhuvana Ramabhadran, Ye Jia, Pedro Moreno, Yonghui Wu, and Zelin Wu. Speech recognition with augmented synthesized speech. In2019 IEEE automatic speech recognition and understanding workshop (ASRU), pages 996–1002. IEEE, 2019. 3
2019
-
[75]
Building vision-language models on solid foundations with masked distillation
Sepehr Sameni, Kushal Kafle, Hao Tan, and Simon Jenni. Building vision-language models on solid foundations with masked distillation. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 14216–14226, 2024. 3
2024
-
[76]
Detecting and grounding multi-modal media manipulation
Rui Shao, Tianxing Wu, and Ziwei Liu. Detecting and grounding multi-modal media manipulation. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6904–6913, 2023. 2
2023
-
[77]
Towards vqa models that can read
Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8317–8326, 2019. 2
2019
-
[78]
Calvin: Improved contextual video captioning via instruc- tion tuning.Advances in Neural Information Processing Systems, 37:92983–93010, 2024
Gowthami Somepalli, Arkabandhu Chowdhury, Jonas Geiping, Ronen Basri, Tom Goldstein, and David Jacobs. Calvin: Improved contextual video captioning via instruc- tion tuning.Advances in Neural Information Processing Systems, 37:92983–93010, 2024. 2
2024
-
[79]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. Ucf101: A dataset of 101 human actions classes from videos in the wild.arXiv preprint arXiv:1212.0402, 2012. 2
work page internal anchor Pith review arXiv 2012
-
[80]
Video understanding with large language models: A survey.IEEE Transactions on Circuits and Sys- tems for Video Technology, 2025
Yunlong Tang, Jing Bi, Siting Xu, Luchuan Song, Susan Liang, Teng Wang, Daoan Zhang, Jie An, Jingyang Lin, Rongyi Zhu, et al. Video understanding with large language models: A survey.IEEE Transactions on Circuits and Sys- tems for Video Technology, 2025. 1
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.