Recognition: unknown
Scaffold-Conditioned Preference Triplets for Controllable Molecular Optimization with Large Language Models
Pith reviewed 2026-05-10 15:47 UTC · model grok-4.3
The pith
Scaffold-conditioned preference triplets allow LLMs to optimize molecular properties while preserving the core scaffold.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce Scaffold-Conditioned Preference Triplets (SCPT), a pipeline that constructs similarity-constrained triplets ⟨scaffold, better, worse⟩ via scaffold alignment and chemistry-driven filters for validity, synthesizability, and meaningful property gains. Using these preferences, we align a pretrained molecular LLM as a conditional editor, enabling property-improving edits that retain the scaffold. Across single- and multi-objective benchmarks, SCPT improves optimization success and property gains while maintaining higher scaffold similarity than competitive baselines.
What carries the argument
Scaffold-Conditioned Preference Triplets (SCPT), the triplets of scaffold, better molecule, and worse molecule built through alignment and filters that provide the supervision signal for aligning the LLM into a conditional molecular editor.
Load-bearing premise
The preference triplets constructed via scaffold alignment and chemistry-driven filters supply high-quality supervision signals that align the LLM effectively without causing overfitting or data-induced biases.
What would settle it
Training an LLM with SCPT triplets and testing it on a standard molecular optimization benchmark where it fails to outperform baselines in both property improvement and scaffold similarity scores would disprove the central claim.
Figures

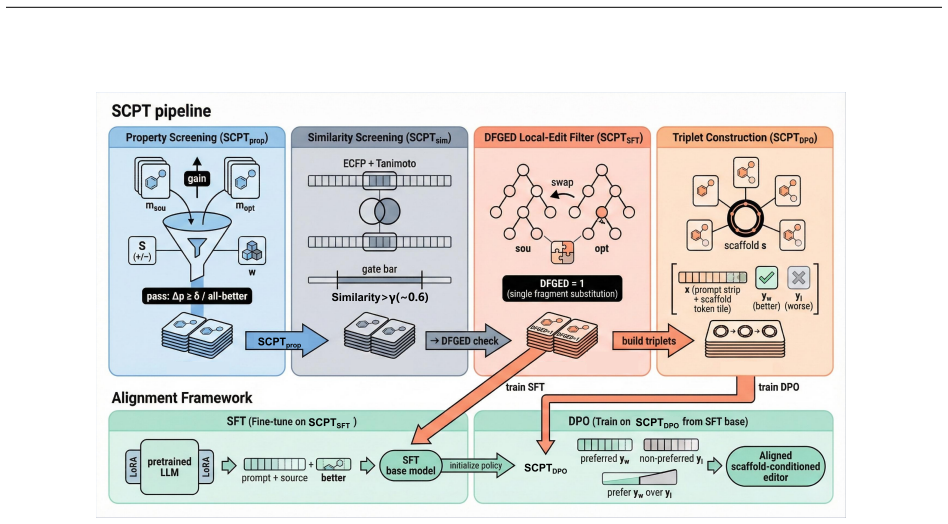







read the original abstract
Molecular property optimization is central to drug discovery, yet many deep learning methods rely on black-box scoring and offer limited control over scaffold preservation, often producing unstable or biologically implausible edits. While large language models (LLMs) are promising molecular generators, optimization remains constrained by the lack of chemistry-grounded preference supervision and principled data curation. We introduce \textbf{Scaffold-Conditioned Preference Triplets (SCPT)}, a pipeline that constructs similarity-constrained triplets $\langle\text{scaffold}, \text{better}, \text{worse}\rangle$ via scaffold alignment and chemistry-driven filters for validity, synthesizability, and meaningful property gains. Using these preferences, we align a pretrained molecular LLM as a conditional editor, enabling property-improving edits that retain the scaffold. Across single- and multi-objective benchmarks, SCPT improves optimization success and property gains while maintaining higher scaffold similarity than competitive baselines. Compared with representative non-LLM molecular optimization methods, SCPT-trained LLMs are better suited to scaffold-constrained and multi-objective optimization. In addition, models trained on single-property and two-property supervision generalize effectively to three-property tasks, indicating promising extrapolative generalization under limited higher-order supervision. SCPT also provides controllable data-construction knobs that yield a predictable similarity-gain frontier, enabling systematic adaptation to diverse optimization regimes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Scaffold-Conditioned Preference Triplets (SCPT), a data-construction pipeline that generates similarity-constrained triplets ⟨scaffold, better, worse⟩ via scaffold alignment plus chemistry-driven filters for validity, synthesizability, and meaningful property gains. These triplets are used to align a pretrained molecular LLM as a conditional editor that performs property-improving edits while retaining the input scaffold. The method is evaluated on single- and multi-objective molecular optimization benchmarks, where SCPT-aligned models reportedly achieve higher optimization success, larger property gains, and better scaffold similarity than competitive baselines; the paper also claims that models trained on 1- or 2-property supervision generalize to 3-property tasks and that the pipeline supplies controllable similarity-gain knobs.
Significance. If the performance gains prove independent of curation artifacts, the work supplies a practical route to controllable, scaffold-preserving molecular editing with LLMs, addressing a key limitation of black-box optimization methods in drug discovery. The explicit provision of data-construction parameters that trace a predictable similarity-gain frontier is a concrete strength, as is the emphasis on extrapolative generalization under limited higher-order supervision. These elements could support more interpretable generative workflows once the supervision quality is verified.
major comments (1)
- [SCPT pipeline (abstract and §3)] SCPT pipeline description (abstract and §3): the 'meaningful property gains' filter thresholds on scalar properties that appear to be the same ones used for the single- and multi-objective benchmarks. Because the training triplets are thereby enriched with examples already aligned with the evaluation objectives, the reported improvements in success rate, property gain, and scaffold similarity may be an artifact of selection bias rather than evidence that the conditional LLM has learned generalizable editing rules. This directly affects the central claim that scaffold-conditioned preference alignment yields effective and extrapolative optimization.
minor comments (2)
- [Abstract] The abstract states that SCPT 'improves optimization success and property gains while maintaining higher scaffold similarity than competitive baselines' yet provides no quantitative deltas, baseline names, or statistical significance tests; these details are needed to assess the practical magnitude of the gains.
- [Abstract] Notation for the triplet ⟨scaffold, better, worse⟩ is introduced without an explicit definition of how 'better' and 'worse' are assigned when multiple properties are optimized simultaneously; a short clarifying sentence would remove ambiguity.
Simulated Author's Rebuttal
We thank the referee for the detailed review and for identifying a potential selection bias in the SCPT data-construction pipeline. We respond to the major comment below and outline revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: SCPT pipeline description (abstract and §3): the 'meaningful property gains' filter thresholds on scalar properties that appear to be the same ones used for the single- and multi-objective benchmarks. Because the training triplets are thereby enriched with examples already aligned with the evaluation objectives, the reported improvements in success rate, property gain, and scaffold similarity may be an artifact of selection bias rather than evidence that the conditional LLM has learned generalizable editing rules. This directly affects the central claim that scaffold-conditioned preference alignment yields effective and extrapolative optimization.
Authors: We acknowledge that the 'meaningful property gains' filter is defined using the same scalar properties (such as QED, logP, and others) that appear in the single- and multi-objective benchmarks. This choice is deliberate: the filter ensures that each triplet encodes a chemically meaningful preference for improvement rather than random or trivial changes. The triplets themselves are not taken from the benchmark test sets; they are generated from a broad pool of molecules via scaffold alignment plus independent validity and synthesizability filters. The LLM is trained only to follow the preference ordering conditioned on the scaffold, not to optimize the properties directly. Evidence that the model learns generalizable editing rules, rather than benchmark-specific artifacts, comes from the reported extrapolation results: models trained on 1- or 2-property supervision still improve on 3-property tasks whose property combinations were never seen during training. Nevertheless, we agree that an explicit discussion of this design choice is warranted. In the revised manuscript we will (i) clarify that the filter thresholds are general improvement criteria applied uniformly across the data-construction stage and (ii) add an ablation that constructs triplets using a disjoint set of auxiliary properties unrelated to the main benchmarks, thereby testing whether performance gains persist when the training objectives diverge from the evaluation objectives. revision: partial
Circularity Check
No significant circularity; derivation is self-contained data pipeline plus empirical evaluation
full rationale
The paper defines a data-construction pipeline (scaffold alignment plus filters for validity, synthesizability, and property gains) that produces preference triplets as training inputs. These triplets are then used to align a pretrained LLM, after which performance is measured on separate single- and multi-objective benchmarks using standard success rates, property deltas, and scaffold similarity. None of the reported outcomes (optimization success, generalization from 1- or 2-property to 3-property tasks) are shown by equation or definition to be identical to the input filters or triplets; the evaluation metrics remain independent observables. No self-citations, uniqueness theorems, or ansatzes are invoked in the provided text to close the chain. The central claims therefore rest on external benchmark results rather than reducing tautologically to the construction steps.
Axiom & Free-Parameter Ledger
free parameters (1)
- similarity thresholds or filter parameters
axioms (1)
- domain assumption Chemistry-driven filters ensure validity and synthesizability
invented entities (1)
-
Scaffold-Conditioned Preference Triplets (SCPT)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
OpenAI Josh Achiam, Steven Adler, and Sandhini Agarwal. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Viraj Bagal, Rishal Aggarwal, P
Accessed: 2025-10-28. Viraj Bagal, Rishal Aggarwal, P. K. Vinod, and U. Deva Priyakumar. Molgpt: Molecular generation using a transformer-decoder model.Journal of Chemical Information and Modeling, 62(9):2064–2076,
2025
-
[3]
doi: 10.1021/acs.jcim.1c00600. PMID: 34694798. Guy Barshatski, Galia Nordon, and Kira Radinsky. Multi-property molecular optimization using an inte- grated poly-cycle architecture. InProceedings of the 30th ACM International Conference on Information & Knowledge Management, pp. 3727–3736,
-
[4]
Bran, Sam Cox, Oliver Schilter, Carlo Baldassari, Andrew D
ISSN 2522-5839. doi: 10.1038/s42256-024-00832-8. URLhttps://doi.org/10.1038/ s42256-024-00832-8. Adrià Cereto-Massagué, María José Ojeda, Cristina Valls, Miquel Mulero, Santiago Garcia-Vallvé, and Ger- ard Pujadas. Molecular fingerprint similarity search in virtual screening.Methods, 71:58–63,
-
[5]
doi: https://doi.org/10.1016/j.ymeth.2014.08.005
ISSN 1046-2023. doi: https://doi.org/10.1016/j.ymeth.2014.08.005. URLhttps://www.sciencedirect.com/ science/article/pii/S1046202314002631. Virtual Screening. Ziqi Chen, Martin Renqiang Min, Srinivasan Parthasarathy, and Xia Ning. A deep generative model for molecule optimization via one fragment modification.Nature Machine Intelligence, 3(12):1040– 1049,
-
[6]
doi: 10.1038/s42256-021-00410-2
ISSN 2522-5839. doi: 10.1038/s42256-021-00410-2. URLhttps://doi.org/10.1038/ s42256-021-00410-2. Vishal Dey, Xiao Hu, and Xia Ning. GeLLM3O: Generalizing large language models for multi-property molecule optimization. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (eds.),Proceedings of the 63rd Annual Meeting of the Associa...
-
[7]
Association for Computational Linguistics. ISBN979-8-89176-251-0. doi: 10.18653/v1/2025.acl-long.1225. URLhttps://aclanthology. org/2025.acl-long.1225/. 14 Abhimanyu Dubey, Abhinav Jauhri, and Abhinav Pandey. The llama 3 herd of models.ArXiv, abs/2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2025.acl-long.1225 2025
-
[8]
Wenhao Gao, Tianfan Fu, Jimeng Sun, and Connor Coley
URLhttps://api.semanticscholar.org/CorpusID:271571434. Wenhao Gao, Tianfan Fu, Jimeng Sun, and Connor Coley. Sample efficiency matters: a benchmark for practical molecular optimization.Advances in Neural Information Processing Systems, 35:21342–21357, 2022a. Wenhao Gao, Tianfan Fu, Jimeng Sun, and Connor Coley. Sample efficiency matters: A benchmark for p...
2022
-
[9]
Automatic chemical design using a data-driven continuous representation of molecules.ACS Cent
doi: 10.1021/acscentsci.7b00572. URLhttps: //doi.org/10.1021/acscentsci.7b00572. Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Representations,
-
[10]
URLhttps://doi.org/10.1088/2632-2153/ac3ffb
doi: 10.1088/2632-2153/ac3ffb. URLhttps://doi.org/10.1088/2632-2153/ac3ffb. Jan H. Jensen. A graph-based genetic algorithm and generative model/monte carlo tree search for the exploration of chemical space.Chem. Sci., 10:3567–3572,
-
[11]
doi: 10.1039/C8SC05372C. URLhttp: //dx.doi.org/10.1039/C8SC05372C. Albert Q. Jiang, Alexandre Sablayrolles, and Arthur Mensch. Mistral 7b,
-
[12]
URLhttps://arxiv.org/ abs/2310.06825. Wengong Jin, Regina Barzilay, and Tommi Jaakkola. Junction tree variational autoencoder for molecular graph generation. In Jennifer Dy and Andreas Krause (eds.),Proceedings of the 35th International Con- ference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pp. 2323–2332. PMLR, 10–15 Jul
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
doi: 10.1088/2632-2153/aba947. Seul Lee, Karsten Kreis, Srimukh Prasad Veccham, Meng Liu, Danny Reidenbach, Saee Pali- wal, Arash Vahdat, and Weili Nie. Molecule generation with fragment retrieval augmentation. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (eds.),Advances in Neural Information Processing Systems, vol...
-
[14]
Peiyao Li, Lan Hua, Zhechao Ma, Wenbo Hu, Ye Liu, and Jun Zhu
URLhttps://proceedings.neurips.cc/paper_files/paper/2024/file/ ef107bb91dae96368c856b1064370bd0-Paper-Conference.pdf. Peiyao Li, Lan Hua, Zhechao Ma, Wenbo Hu, Ye Liu, and Jun Zhu. Conformalized graph learning for molecular admet property prediction and reliable uncertainty quantification.Journal of Chemical Infor- mation and Modeling, 64(23):8705–8717,
2024
-
[15]
ISSN 1549-9596. doi: 10.1021/acs.jcim.4c01139. URL https://doi.org/10.1021/acs.jcim.4c01139. 15 Sohvi Luukkonen, Helle W.van den Maagdenberg, MichaelT.M. Emmerich, and GerardJ.P. van Westen. Ar- tificial intelligence in multi-objective drug design.Current Opinion in Structural Biology, 79:102537,
-
[16]
doi: https://doi.org/10.1016/j.sbi.2023.102537
ISSN 0959-440X. doi: https://doi.org/10.1016/j.sbi.2023.102537. URLhttps://www.sciencedirect. com/science/article/pii/S0959440X23000118. Nicholas A. Meanwell. Synopsis of some recent tactical application of bioisosteres in drug design.Journal of Medicinal Chemistry, 54(8):2529–2591,
-
[17]
ISSN 0022-2623. doi: 10.1021/jm1013693. URLhttps: //doi.org/10.1021/jm1013693. Tung Nguyen and Aditya Grover. LICO: Large language models for in-context molecular optimization. In The Thirteenth International Conference on Learning Representations,
-
[18]
URLhttps://doi.org/10.1186/s13321-017-0235-x
doi: 10.1186/ s13321-017-0235-x. URLhttps://doi.org/10.1186/s13321-017-0235-x. Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and ...
-
[19]
doi: 10.1021/acscentsci.3c00572
ISSN 2374-7943. doi: 10.1021/acscentsci.3c00572. URLhttps://doi.org/10.1021/ acscentsci.3c00572. Rafael Rafailov, Archit Sharma, Eric Mitchell, Chelsea Finn, Stefano Ermon, et al. Direct preference optimization: Your language model is secretly a reward model.arXiv preprint arXiv:2305.18290,
-
[20]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
URLhttps://arxiv.org/abs/2305.18290. Patrick Reiser, Marlen Neubert, André Eberhard, Luca Torresi, Chen Zhou, Chen Shao, Houssam Metni, Clint van Hoesel, Henrik Schopmans, Timo Sommer, and Pascal Friederich. Graph neural networks for materials science and chemistry.Communications Materials, 3(1):93,
work page internal anchor Pith review arXiv
-
[21]
doi: 10.1038/s43246-022-00315-6
ISSN 2662-4443. doi: 10.1038/s43246-022-00315-6. URLhttps://doi.org/10.1038/s43246-022-00315-6. Teague Sterling and John J. Irwin. Zinc 15 – ligand discovery for everyone.Journal of Chemical Information and Modeling, 55(11):2324–2337,
-
[22]
doi: 10.1021/acs.jcim.5b00559. URLhttps://doi.org/10.1021/ acs.jcim.5b00559. C. W. Thornber. Isosterism and molecular modification in drug design.Chem. Soc. Rev., 8:563–580,
-
[23]
URLhttp://dx.doi.org/10.1039/CS9790800563
doi: 10.1039/CS9790800563. URLhttp://dx.doi.org/10.1039/CS9790800563. Haorui Wang, Marta Skreta, Cher Tian Ser, Wenhao Gao, Lingkai Kong, Felix Strieth-Kalthoff, Chenru Duan, Yuchen Zhuang, Yue Yu, Yanqiao Zhu, Yuanqi Du, Alan Aspuru-Guzik, Kirill Neklyudov, and Chao Zhang. Efficient evolutionary search over chemical space with large language models. InTh...
-
[24]
doi: 10.1038/s42256-022-00447-x
ISSN 2522-5839. doi: 10.1038/s42256-022-00447-x. URLhttps://doi.org/10.1038/s42256-022-00447-x. David Weininger. Smiles,
-
[25]
Smiles, a chemical language and information system
doi: 10.1021/ci00057a005. Fang Wu, Dragomir Radev, and Stan Z. Li. Molformer: Motif-based transformer on 3d heterogeneous molecular graphs. InAAAI, pp. 5312–5320,
-
[26]
URLhttps://doi.org/10.1609/aaai.v37i4.25662. X. Xia, Y. Zhang, X. Zeng, X. Zhang, C. Zheng, and Y. Su. Artificial intelligence in molecular optimization: Current paradigms and future frontiers.International Journal of Molecular Sciences, 26(10):4878,
-
[27]
URLhttps://doi.org/10.3390/ijms26104878
doi: 10.3390/ijms26104878. URLhttps://doi.org/10.3390/ijms26104878. Xuhua Xia. Bioinformatics and drug discovery.Current topics in medicinal chemistry, 17(15):1709–1726,
-
[28]
Chemllm: A chemical large language model.arXiv preprint arXiv:2402.06852, 2024
URLhttps://openreview.net/forum?id=lY6XTF9tPv. Di Zhang, Wei Liu, and Qian Tan. Chemllm: A chemical large language model.ArXiv, abs/2402.06852,
-
[29]
ISSN 0360-0300. doi: 10.1145/3715318. URLhttps://doi.org/10.1145/3715318. Yuhang Xia Yongkang Wang Zhiwei Wang Wen Zhang. A comprehensive review of molecular optimization in artificial intelligence-based drug discovery.Quantitative Biology, 12:15–29,
-
[30]
doi: https://doi.org/10.1002/qub2.30
ISSN 2095-4689. doi: https://doi.org/10.1002/qub2.30. URLhttps://journal.hep.com.cn/qb/EN/10.1002/qub2.30. A Algorithm The SCPT pipeline and the alignment framework are illustrated in Algorithm Algorithm
-
[31]
B Data Construction For all properties considered in this work, we construct scaffold-conditioned preference triples from molecules sampled from the ZINC/ZINC250k library Sterling & Irwin (2015); Gómez-Bombarelli et al. (2018). For each property, we first annotate candidate molecules using oracles Gao et al. (2022b); Huang et al. (2021); Li et al. (2024) ...
2015
-
[32]
higher is better
18 Table 9: Summary statistics of multi-property training data. Properties Count Properties Count GSK3β+DRD2 +pLogP 9,469 JNK3+QED 8,152 GSK3β+DRD2 +QED 13,898 JNK3+pLogP 10,609 GSK3β+pLogP +QED 7,268 GSK3β+QED 23,251 DRD2+pLogP +QED 2,349 GSK3β+pLogP 19,571 JNK3+GSK3β9,885 pLogP+QED 15,874 C Experiment C.1 Metrics (1) Success Rate (SR).The fraction of so...
2023
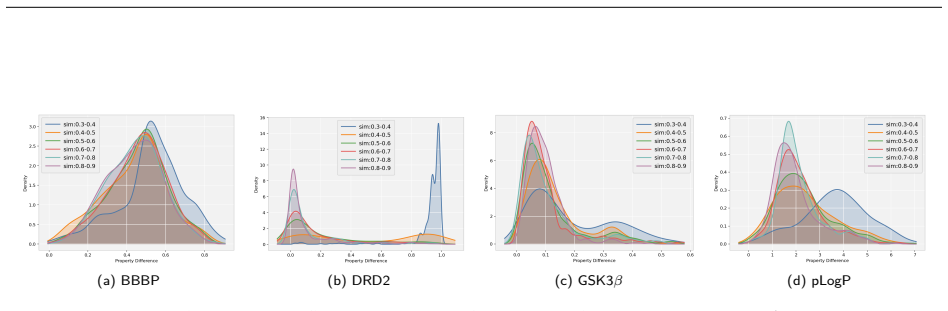
-
[33]
Overall, the similarity threshold induces a stable trade-off between similarity and improvability. We rec- ommend operating around 0.5–0.6 to balance scaffold preservation and property gains; stricter thresholds can be used when fidelity is paramount, with the caveat of reduced RI and potential SR drops on sensitive endpoints such as DRD2. As shown in Fig...
2000
-
[34]
better" and
26 Table 11: Single-property optimization results by property-gap thresholds. Each row corresponds to a property-difference percentile range (the first row is the top 10% largest gaps), and each column to a task. Property RangeBBBP DRD2 HIA Mutag pLogP QED GSK3βJNK3 SR↑SIM↑RI↑SR↑SIM↑RI↑SR↑SIM↑RI↑SR↑SIM↑RI↑SR↑SIM↑RI↑SR↑SIM↑RI↑SR↑SIM↑RI↑SR↑SIM↑RI↑ 0–0.1 100...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.