Recognition: unknown
Masked by Consensus: Disentangling Privileged Knowledge in LLM Correctness
Pith reviewed 2026-05-10 15:40 UTC · model grok-4.3
The pith
LLMs hold domain-specific privileged knowledge about answer correctness that only self-representations can access on disagreement cases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
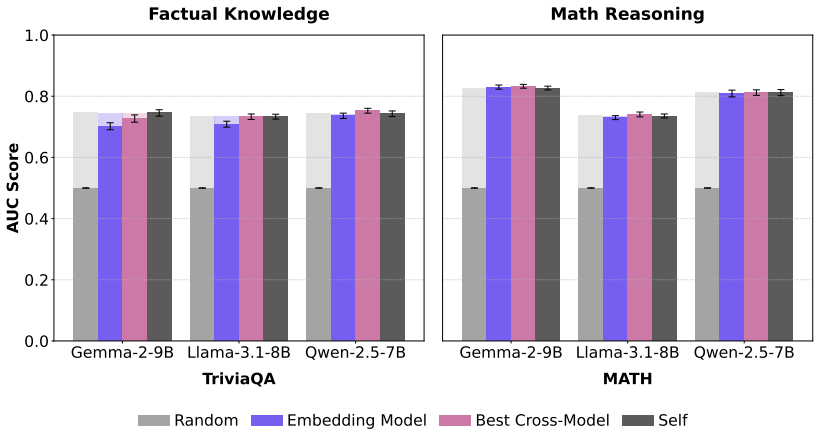
On disagreement subsets where models give conflicting answers, self-representations consistently outperform peer representations when predicting correctness for factual knowledge tasks, while showing no such advantage for math reasoning tasks. The factual advantage emerges progressively from early-to-mid layers onward, consistent with access to model-specific memory, whereas math reasoning exhibits no consistent layer-wise advantage.
What carries the argument
correctness classifiers trained on a model's own hidden states versus external peer-model hidden states, evaluated on disagreement subsets to separate consensus from privileged internal signals
If this is right
- Factual error detection can improve by probing the model's own states when external models disagree.
- Math reasoning correctness may depend more on patterns observable across multiple models.
- Layer-wise analysis can identify the point at which model-specific factual memory becomes accessible.
- Disagreement subsets provide a sharper test for uncovering internal knowledge than full agreement datasets.
- Self-probes may serve as a targeted tool for model self-correction in factual domains.
Where Pith is reading between the lines
- This approach could extend to other domains like code generation or commonsense reasoning by creating disagreement subsets.
- Multi-model systems might use self-probes to decide which model's answer to trust when outputs conflict.
- The layer localization suggests interventions that target mid-layer states for factual knowledge access.
- Consensus-based evaluation of LLMs may systematically underestimate individual model strengths in factual recall.
Load-bearing premise
Performance differences between self and peer probes on disagreement subsets reflect genuine privileged knowledge rather than biases in how those subsets were selected or differences between the factual and math benchmarks.
What would settle it
Finding equivalent performance between self and peer correctness classifiers on disagreement subsets after rebalancing those subsets to equalize difficulty, data source distribution, and answer patterns across factual and math domains.
Figures















read the original abstract
Humans use introspection to evaluate their understanding through private internal states inaccessible to external observers. We investigate whether large language models possess similar privileged knowledge about answer correctness, information unavailable through external observation. We train correctness classifiers on question representations from both a model's own hidden states and external models, testing whether self-representations provide a performance advantage. On standard evaluation, we find no advantage: self-probes perform comparably to peer-model probes. We hypothesize this is due to high inter-model agreement of answer correctness. To isolate genuine privileged knowledge, we evaluate on disagreement subsets, where models produce conflicting predictions. Here, we discover domain-specific privileged knowledge: self-representations consistently outperform peer representations in factual knowledge tasks, but show no advantage in math reasoning. We further localize this domain asymmetry across model layers, finding that the factual advantage emerges progressively from early-to-mid layers onward, consistent with model-specific memory retrieval, while math reasoning shows no consistent advantage at any depth.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates whether LLMs possess privileged internal knowledge about answer correctness by training binary correctness classifiers on hidden-state representations from the target model itself versus external peer models. On full evaluation sets, self-probes show no advantage over peer probes. The authors then restrict analysis to disagreement subsets (where target and peer models produce conflicting answers) and report that self-representations outperform peers on factual-knowledge tasks but not on math-reasoning tasks; they further localize the factual advantage to progressive emergence in early-to-mid layers, interpreting this as evidence of model-specific memory retrieval.
Significance. If the central empirical pattern survives controls for subset selection, the work offers a concrete, domain-differentiated probe for internal versus external knowledge in LLMs and supplies layer-localization evidence that could inform mechanistic interpretability. The purely empirical design avoids circular derivations and the layer-wise analysis constitutes a positive methodological step beyond aggregate accuracy comparisons.
major comments (2)
- [Experimental setup and disagreement-subset definition] The construction of disagreement subsets (described after the standard-evaluation results) is performed post-hoc without reported balancing or regression controls for subset-level statistics such as question length, answer entropy, model confidence, or ground-truth difficulty. Because factual and math benchmarks may differ systematically in these properties, the observed domain asymmetry and layer-wise pattern could be an artifact of the filtering procedure rather than evidence of privileged knowledge; explicit controls or matched-subset re-analysis are needed to support the claim.
- [Results on disagreement subsets] The abstract and results sections state that self-probes 'consistently outperform' peers on factual disagreement subsets, yet no exact subset sizes, confidence intervals, or statistical significance tests for the self-versus-peer gap are provided. Without these quantities it is impossible to assess whether the reported advantage is robust or driven by small or imbalanced subsets.
minor comments (2)
- [Layer-wise analysis] The layer-localization plots would benefit from explicit error bars or shaded regions indicating variability across random seeds or cross-validation folds.
- [Methods] Notation for 'self-representations' versus 'peer representations' is used consistently but could be introduced with a short table of probe architectures and training objectives for clarity.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments. We appreciate the concerns about potential confounds in the disagreement-subset construction and the need for more complete statistical reporting. We address each major comment below and commit to revisions that strengthen the empirical claims.
read point-by-point responses
-
Referee: The construction of disagreement subsets (described after the standard-evaluation results) is performed post-hoc without reported balancing or regression controls for subset-level statistics such as question length, answer entropy, model confidence, or ground-truth difficulty. Because factual and math benchmarks may differ systematically in these properties, the observed domain asymmetry and layer-wise pattern could be an artifact of the filtering procedure rather than evidence of privileged knowledge; explicit controls or matched-subset re-analysis are needed to support the claim.
Authors: We agree that the post-hoc filtering on model disagreement could introduce confounds if factual and math benchmarks differ systematically in length, entropy, confidence, or difficulty. In the revision we will add (i) regression controls that include these covariates when predicting probe accuracy and (ii) a matched-subset re-analysis in which disagreement examples are balanced across domains on the listed statistics. These controls will allow us to test whether the domain asymmetry and layer-wise localization survive after accounting for subset-level differences. revision: yes
-
Referee: The abstract and results sections state that self-probes 'consistently outperform' peers on factual disagreement subsets, yet no exact subset sizes, confidence intervals, or statistical significance tests for the self-versus-peer gap are provided. Without these quantities it is impossible to assess whether the reported advantage is robust or driven by small or imbalanced subsets.
Authors: We acknowledge that the current manuscript lacks the quantitative details needed to evaluate robustness. The revised version will report the exact number of examples in each disagreement subset, bootstrap or analytic confidence intervals around the self-minus-peer accuracy differences, and the results of paired statistical tests (e.g., McNemar or Wilcoxon signed-rank) for every domain and layer comparison. These additions will make the magnitude and reliability of the reported advantages transparent. revision: yes
Circularity Check
No circularity: purely empirical probing with independent evaluations
full rationale
The paper conducts an empirical study by training correctness classifiers on hidden-state representations from self and peer models, then measuring accuracy differences on standard vs. disagreement subsets across factual and math tasks, with layer-wise localization. No equations, derivations, or first-principles results are presented that reduce by construction to fitted parameters, self-definitions, or self-citation chains. Subset construction and performance reporting are direct experimental outputs rather than renamed inputs or ansatzes smuggled via prior work. The analysis is self-contained against external benchmarks and does not invoke uniqueness theorems or load-bearing self-citations.
Axiom & Free-Parameter Ledger
free parameters (1)
- disagreement subset definition
axioms (1)
- domain assumption Hidden states encode extractable information about answer correctness
Reference graph
Works this paper leans on
-
[1]
From imitation to introspection: Probing self- consciousness in language models. InFindings of the Association for Computational Linguistics: ACL 2025, pages 7553–7583, Vienna, Austria. Associa- tion for Computational Linguistics. Cheang Seng Chi, Hou Pong Chan, Wenxuan Zhang, and Yang Deng. 2025. Large language models do not really know what they don’t k...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
What does BERT learn about the structure of language? InProceedings of the 57th Annual Meet- ing of the Association for Computational Linguistics, pages 3651–3657, Florence, Italy. Association for Computational Linguistics. Li Ji-An, Marcelo G Mattar, Hua-Dong Xiong, Mar- cus K Benna, and Robert C Wilson. 2025. Language models are capable of metacognitive...
work page internal anchor Pith review arXiv 2025
-
[3]
This text discusses [Concept A], [Concept B], and [Concept C]
Mintaka: A complex, natural, and multilin- gual dataset for end-to-end question answering. In Proceedings of the 29th International Conference on Computational Linguistics, pages 1604–1619. Yeongbin Seo, Dongha Lee, and Jinyoung Yeo. 2025. Quantifying self-awareness of knowledge in large language models.CoRR, abs/2509.15339. Hovhannes Tamoyan, Subhabrata ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.