Recognition: unknown
ReasonXL: Shifting LLM Reasoning Language Without Sacrificing Performance
Pith reviewed 2026-05-10 15:23 UTC · model grok-4.3
The pith
LLMs can be adapted to reason entirely in a target language using a parallel corpus of reasoning traces, matching or exceeding baseline performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
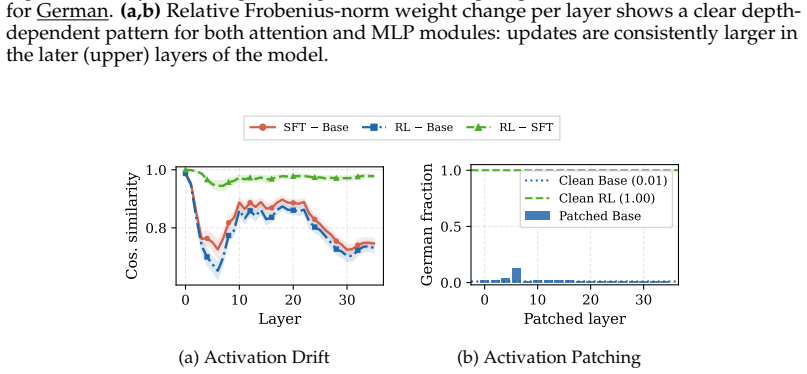
ReasonXL supplies over two million aligned prompt-reasoning-output triples per language across five European languages. Supervised fine-tuning on this corpus followed by reinforcement learning with verifiable rewards adapts LLMs to produce complete reasoning traces in the target language. The resulting models match or exceed baseline task performance with minimal loss in general knowledge and preserved cross-lingual transfer. Representational analysis finds that early layers contain an activation bottleneck determining language identity while upper layers concentrate adaptation-driven changes, and that reinforcement learning achieves greater behavioral divergence from the base model with far
What carries the argument
ReasonXL, the first large-scale parallel corpus of cross-domain reasoning traces, used in a two-stage supervised fine-tuning then reinforcement learning pipeline to reroute reasoning language.
If this is right
- Models generate reasoning traces in the language of the input rather than English.
- Task performance remains at or above the original baseline levels.
- General knowledge and cross-lingual transfer abilities stay largely preserved.
- Early layers determine the language identity of reasoning while upper layers handle task-specific adaptation.
- Reinforcement learning produces more behavioral change than supervised fine-tuning despite smaller parameter updates.
Where Pith is reading between the lines
- Similar parallel corpora could be built for additional languages to extend language-specific reasoning to more users.
- The early-layer bottleneck finding could support more targeted edits to control output language without full retraining.
- Adopting the method might reduce translation-induced errors in reasoning chains for multilingual applications.
- The approach suggests a path for incorporating language-specific reasoning during pretraining rather than only afterward.
Load-bearing premise
The parallel samples in ReasonXL are high-quality, accurately aligned across languages, and free of translation artifacts that would undermine language-specific supervision.
What would settle it
If models trained on ReasonXL still produce English reasoning traces on non-English tasks or show measurable drops in accuracy compared to the base model, the adaptation claim would not hold.
Figures








read the original abstract
Despite advances in multilingual capabilities, most large language models (LLMs) remain English-centric in their training and, crucially, in their production of reasoning traces. Even when tasked with non-English problems, these models predominantly reason in English, creating a fundamental mismatch for non-English usage scenarios. We address this disparity directly with three contributions. (i) We introduce ReasonXL, the first large-scale parallel corpus of cross-domain reasoning traces spanning five European languages (English, German, French, Italian, and Spanish), with over two million aligned samples per language, each comprising prompts, reasoning traces, and final outputs, enabling direct supervision of language-specific reasoning. (ii) Using ReasonXL, we demonstrate that LLMs can be adapted to reason entirely in a desired target language, using a simple two-stage pipeline of supervised fine-tuning (SFT) followed by reinforcement learning with verifiable rewards (RLVR). The resulting models match or exceed baseline performance, with minimal loss in general knowledge and broadly preserved cross-lingual transfer. (iii) We conduct an extensive representational analysis of the adaptation and find a clear functional division across model depth: early layers contain an activation bottleneck that causally determines language identity, while upper layers concentrate the weight and activation changes driven by adaptation. We further find that RLVR achieves greater behavioral divergence from the base model with smaller parameter updates than SFT, suggesting a more efficient representational rerouting despite much smaller weight updates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ReasonXL, a large-scale parallel corpus of cross-domain reasoning traces spanning five European languages with over two million aligned samples per language. It proposes adapting LLMs to reason entirely in a target language via a two-stage pipeline of supervised fine-tuning (SFT) followed by reinforcement learning with verifiable rewards (RLVR), claiming the resulting models match or exceed baseline performance with minimal loss in general knowledge and preserved cross-lingual transfer. The work further includes a representational analysis showing a functional division across model depth, with early layers forming an activation bottleneck for language identity and upper layers concentrating adaptation-driven changes, and notes that RLVR achieves greater behavioral divergence than SFT despite smaller weight updates.
Significance. If the empirical results hold and the corpus supplies high-quality natural reasoning traces, this work would be a meaningful contribution to multilingual LLM research by demonstrating a practical method to decouple reasoning language from English-centric defaults without performance trade-offs. The introduction of ReasonXL as a parallel resource and the layer-wise mechanistic analysis both add value; the finding that RLVR enables more efficient representational rerouting is a particular strength that could inform future adaptation techniques.
major comments (1)
- [Abstract and ReasonXL dataset description] The central claim that SFT+RLVR on ReasonXL produces target-language reasoning with no performance sacrifice depends on the 2M+ aligned samples providing high-quality, natural reasoning traces rather than translated approximations. The manuscript provides no concrete details on corpus construction, source of the traces, alignment/translation pipeline, human validation, or filtering steps to rule out artifacts (non-idiomatic logic, domain-term misalignment, or prompt-reasoning-output drift). This is load-bearing because such artifacts would allow final-answer accuracy while degrading actual reasoning quality in the target language, directly threatening the 'no sacrifice' and 'preserved cross-lingual transfer' results.
minor comments (1)
- [Abstract] The abstract states performance results and layer findings but supplies no quantitative metrics, baselines, or error bars; including at least headline numbers (e.g., accuracy deltas on key benchmarks) would strengthen the summary.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and positive evaluation of the work's significance. We address the major comment below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: The central claim that SFT+RLVR on ReasonXL produces target-language reasoning with no performance sacrifice depends on the 2M+ aligned samples providing high-quality, natural reasoning traces rather than translated approximations. The manuscript provides no concrete details on corpus construction, source of the traces, alignment/translation pipeline, human validation, or filtering steps to rule out artifacts (non-idiomatic logic, domain-term misalignment, or prompt-reasoning-output drift). This is load-bearing because such artifacts would allow final-answer accuracy while degrading actual reasoning quality in the target language, directly threatening the 'no sacrifice' and 'preserved cross-lingual transfer' results.
Authors: We agree that the quality and provenance of the reasoning traces are central to supporting our claims, and that the current manuscript description is insufficiently detailed on this point. We will revise the 'ReasonXL Dataset' section to include concrete information on corpus construction, including the sources of the original traces, the alignment and translation pipeline used to create the parallel samples, human validation procedures applied to subsets of the data, and the filtering steps employed to reduce artifacts such as non-idiomatic logic or output drift. These additions will allow readers to better evaluate the naturalness of the traces and the validity of the performance results. revision: yes
Circularity Check
No circularity: empirical dataset and standard training pipeline
full rationale
The paper introduces an externally constructed parallel corpus (ReasonXL) and applies standard SFT followed by RLVR without any mathematical derivations, equations, or claims that reduce to self-defined parameters or self-citations by construction. All load-bearing steps rely on new data and established training methods whose outcomes are measured against external benchmarks rather than being forced by the result itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption ReasonXL samples are accurately aligned and high-quality across languages
Reference graph
Works this paper leans on
-
[1]
doi: 10.18653/v1/2024.acl-long.44
Association for Computational Linguistics. doi: 10.18653/v1/2024.acl-long.44. URL https://aclanthology.org/2024.acl-long.44/. Akhiad Bercovich, Itay Levy, Izik Golan, et al. Llama-nemotron: Efficient reasoning models,
-
[2]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
URLhttps://arxiv.org/abs/2505.00949. Yonatan Bisk, Rowan Zellers, Ronan Le bras, Jianfeng Gao, and Yejin Choi. Piqa: Reasoning about physical commonsense in natural language.Proceedings of the AAAI Conference on Artificial Intelligence, 34(05):7432–7439, Apr. 2020. doi: 10.1609/aaai.v34i05.6239. URL https://ojs.aaai.org/index.php/AAAI/article/view/6239. C...
-
[3]
URLhttps://openreview.net/forum?id=7xjoTuaNmN. 11 Preprint. Under review. Daniil Gurgurov, Yusser Al Ghussin, Tanja Baeumel, et al. Clas-bench: A cross-lingual alignment and steering benchmark, 2026. URLhttps://arxiv.org/abs/2601.08331. Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive...
-
[4]
URLhttps://openreview.net/forum?id=k3gCieTXeY. 13 Preprint. Under review. Alan Saji, Raj Dabre, Anoop Kunchukuttan, and Ratish Puduppully. The reasoning lingua franca: A double-edged sword for multilingual AI. In Vera Demberg, Kentaro Inui, and Llu´ıs Marquez (eds.),Proceedings of the 19th Conference of the European Chapter of the Association for Computat...
-
[5]
Noam Shazeer and Mitchell Stern
ISSN 0001-0782. doi: 10.1145/3474381. URLhttps://doi.org/10.1145/3474381. Naomi Saphra and Sarah Wiegreffe. Mechanistic? In Yonatan Belinkov, Najoung Kim, Jaap Jumelet, Hosein Mohebbi, Aaron Mueller, and Hanjie Chen (eds.),Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP, pp. 480–498, Miami, Florida, US, Nove...
-
[6]
Freda Shi, Mirac Suzgun, Markus Freitag, et al
URLhttps://aclanthology.org/2024.acl-long.539/. Freda Shi, Mirac Suzgun, Markus Freitag, et al. Language models are multilingual chain- of-thought reasoners. InThe Eleventh International Conference on Learning Representations,
2024
-
[7]
Global MMLU : Understanding and Addressing Cultural and Linguistic Biases in Multilingual Evaluation
URLhttps://openreview.net/forum?id=fR3wGCk-IXp. Shivalika Singh, Angelika Romanou, Cl ´ementine Fourrier, et al. Global MMLU: Under- standing and addressing cultural and linguistic biases in multilingual evaluation. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (eds.), Proceedings of the 63rd Annual Meeting of the Associat...
-
[8]
URLhttps://aclanthology.org/2024.acl-long.309/. 14 Preprint. Under review. Jesse Vig, Sebastian Gehrmann, Yonatan Belinkov, et al. Investigating gender bias in lan- guage models using causal mediation analysis. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin (eds.),Advances in Neural Information Processing Systems, volume 33, pp. 12388–1...
-
[9]
URLhttps://aclanthology.org/2024.acl-long.820/. Zhaofeng Wu, Xinyan Velocity Yu, Dani Yogatama, Jiasen Lu, and Yoon Kim. The semantic hub hypothesis: Language models share semantic representations across languages and modalities. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=FrFQpAgnGE. Sh...
-
[10]
Output ONLY the translated text
-
[11]
Preserve ALL technical terms, code snippets, mathematical notation, and formatting exactly
-
[12]
Maintain the same tone, style, and formality
-
[13]
{language-specific formality guidance}
-
[14]
For code: Keep variable/function names in English
-
[15]
For math: Preserve LaTeX notation unchanged
-
[16]
Adapt examples and cultural references appropriately
-
[17]
Du bist ein hilfreicher Assistent. Denke zuerst in <think> -Tags nach und gib dann deine Antwort
Maintain terminology consistency throughout USER: TEXT TO TRANSLATE: {text} TRANSLATION: Figure 3: Translation prompt template. {field} is one of: input, thinking/reasoning, or output. 16 Preprint. Under review. C Dataset Samples Lang Sample EN Input:Which of the following statements is true about the singularity at the center of a black hole? Reasoning:O...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.