Recognition: unknown
Preventing Safety Drift in Large Language Models via Coupled Weight and Activation Constraints
Pith reviewed 2026-05-10 16:00 UTC · model grok-4.3
The pith
Coupling weight and activation constraints preserves safety alignment in LLMs during fine-tuning better than constraining either alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Constraining weights or activations in isolation is insufficient to preserve safety; robust protection instead requires simultaneously enforcing a precomputed safety subspace on weight updates while regularizing safety-critical activation features identified by sparse autoencoders.
What carries the argument
Coupled Weight and Activation Constraints (CWAC), which applies a safety subspace to weight updates and targeted regularization to sparse-autoencoder safety features.
If this is right
- CWAC achieves the lowest harmful scores across four LLMs and diverse tasks with only minimal loss in fine-tuning accuracy.
- The method continues to outperform strong baselines even when fine-tuning data contains high ratios of harmful examples.
- Single-constraint approaches on weights or activations alone permit greater degradation of refusal behaviors.
- The coupled mechanism maintains alignment stability under conditions that break existing defenses.
Where Pith is reading between the lines
- If the subspace and feature identification prove stable, the same coupling idea could be layered onto other safety techniques such as preference optimization.
- Extending the constraints to online or streaming fine-tuning settings might prevent gradual drift in deployed systems.
- Checking whether the same subspace remains protective after multiple sequential fine-tuning stages would test broader applicability.
Load-bearing premise
The safety subspace derived from the base model and the safety-critical features from sparse autoencoders remain valid and sufficient to block alignment loss throughout fine-tuning on any downstream data.
What would settle it
A direct counterexample would be an experiment fine-tuning one of the tested models on a new task containing high harmful content where CWAC no longer produces the lowest harmful scores compared with single-constraint baselines.
Figures



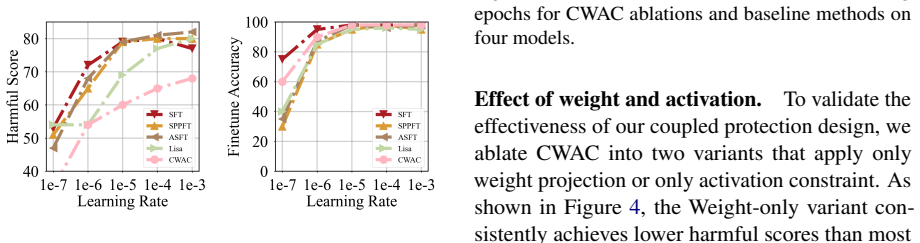
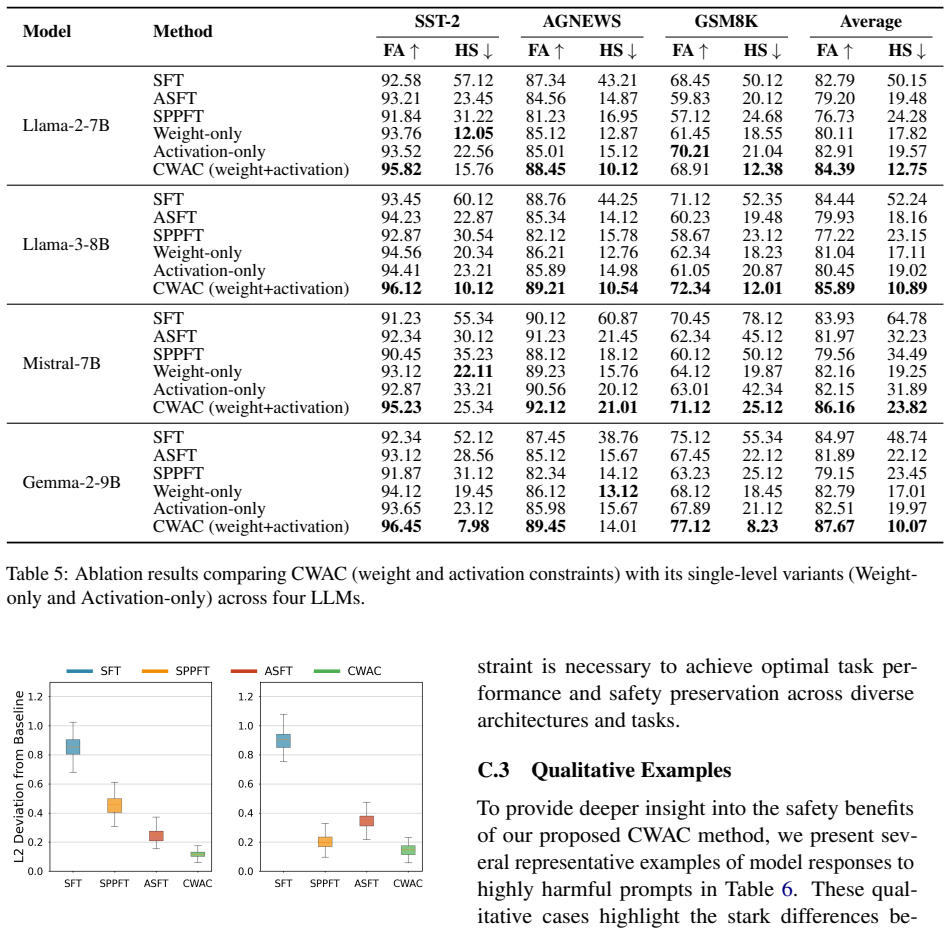
read the original abstract
Safety alignment in Large Language Models (LLMs) remains highly fragile during fine-tuning, where even benign adaptation can degrade pre-trained refusal behaviors and enable harmful responses. Existing defenses typically constrain either weights or activations in isolation, without considering their coupled effects on safety. In this paper, we first theoretically demonstrate that constraining either weights or activations alone is insufficient for safety preservation. To robustly preserve safety alignment, we propose Coupled Weight and Activation Constraints (CWAC), a novel approach that simultaneously enforces a precomputed safety subspace on weight updates and applies targeted regularization to safety-critical features identified by sparse autoencoders. Extensive experiments across four widely used LLMs and diverse downstream tasks show that CWAC consistently achieves the lowest harmful scores with minimal impact on fine-tuning accuracy, substantially outperforming strong baselines even under high harmful data ratios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that constraining either weights or activations in isolation is theoretically insufficient to preserve safety alignment in LLMs during fine-tuning, and proposes Coupled Weight and Activation Constraints (CWAC) that simultaneously projects weight updates onto a precomputed safety subspace while applying SAE-derived regularization to safety-critical activation features. Extensive experiments on four LLMs across diverse tasks reportedly show CWAC achieving the lowest harmful scores with minimal accuracy degradation, outperforming baselines even at high harmful data ratios.
Significance. If the central claims hold, the work offers a practical defense against safety drift that could improve reliable fine-tuning of aligned models. The theoretical argument for the necessity of coupling and the scale of the empirical evaluation (multiple models, tasks, and harmful ratios) are strengths; the method also ships a concrete, implementable procedure rather than purely abstract advice.
major comments (3)
- [Theoretical analysis section] The theoretical demonstration that isolated weight or activation constraints are insufficient (abstract and likely §3) provides no explicit construction of the safety subspace, no proof steps, and no derivation showing why the coupled projection is required; without these details the claim that single constraints fail remains only partially supported.
- [CWAC method description] The method applies a fixed safety subspace (derived once from the base model) and fixed SAE-identified features throughout fine-tuning; no analysis of subspace drift, feature stability, or re-computation is provided, which directly undermines the claim that the constraints remain sufficient as representations shift (see skeptic note on weakest assumption).
- [Experiments section] The experimental section reports strong results but omits details on SAE training procedure, exact safety-subspace construction, and controls for data contamination or downstream-task leakage; these omissions make it impossible to assess whether the reported gains are robust or artifactual.
minor comments (2)
- [Method] Notation for the safety subspace basis and SAE regularization strength should be introduced with explicit equations rather than descriptive prose.
- [Figures and tables] Figure captions and table legends lack sufficient detail on what the harmful-score metric exactly measures and how baselines were re-implemented.
Simulated Author's Rebuttal
We thank the referee for their thorough review and valuable feedback. We provide point-by-point responses to the major comments below, outlining the revisions we will make to address the concerns raised.
read point-by-point responses
-
Referee: [Theoretical analysis section] The theoretical demonstration that isolated weight or activation constraints are insufficient (abstract and likely §3) provides no explicit construction of the safety subspace, no proof steps, and no derivation showing why the coupled projection is required; without these details the claim that single constraints fail remains only partially supported.
Authors: We agree that the theoretical analysis would benefit from more explicit details. In the revised manuscript, we will expand Section 3 to include: an explicit construction of the safety subspace using principal components from the difference between aligned and unaligned model weights; step-by-step proof that isolated weight constraints allow activation drift and vice versa; and a derivation showing the necessity of the coupled projection to block all paths for safety degradation. This will make the claim fully supported. revision: yes
-
Referee: [CWAC method description] The method applies a fixed safety subspace (derived once from the base model) and fixed SAE-identified features throughout fine-tuning; no analysis of subspace drift, feature stability, or re-computation is provided, which directly undermines the claim that the constraints remain sufficient as representations shift (see skeptic note on weakest assumption).
Authors: The fixed nature of the subspace and features is a core design choice to anchor the model to its initial safety alignment. We will add a new subsection analyzing the stability of the safety subspace and SAE features during fine-tuning, including quantitative measures of drift (e.g., cosine similarity over epochs) and justification for not re-computing them. While we acknowledge the potential for representation shift, our empirical results across multiple models and tasks support the sufficiency of the fixed constraints. We will also discuss the weakest assumption explicitly. revision: partial
-
Referee: [Experiments section] The experimental section reports strong results but omits details on SAE training procedure, exact safety-subspace construction, and controls for data contamination or downstream-task leakage; these omissions make it impossible to assess whether the reported gains are robust or artifactual.
Authors: We appreciate this point and will significantly expand the experimental details. The revised paper will include: a detailed description of the SAE training procedure (architecture, loss, training data, hyperparameters); the precise algorithm for safety-subspace construction (including any matrix decompositions used); and explicit controls for data contamination and leakage (e.g., dataset overlap checks, use of separate validation sets not seen during pre-training or fine-tuning). These will be placed in the main text and supplementary material to ensure full reproducibility and robustness assessment. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper first presents a theoretical argument establishing the insufficiency of isolated weight or activation constraints for safety preservation, then defines CWAC as the simultaneous application of a precomputed safety subspace (from the base model) to weight updates and regularization on SAE-derived safety-critical features. These precomputed elements are fixed inputs used to constrain updates on new downstream data, with the safety-preservation claim evaluated via independent experiments across four LLMs and multiple tasks rather than reducing to a tautology, self-fit, or self-citation chain. No equations or steps equate the output safety metric to the input subspace by construction, and the method remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- safety subspace basis
- SAE regularization strength
axioms (2)
- domain assumption Constraining weights or activations in isolation is theoretically insufficient to preserve safety alignment.
- domain assumption Sparse autoencoders reliably identify safety-critical features that remain relevant after fine-tuning.
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, and 1 others. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Federico Bianchi, Mirac Suzgun, Giuseppe Attanasio, Paul Rottger, Dan Jurafsky, Tatsunori Hashimoto, and James Zou. 2024. https://openreview.net/forum?id=gT5hALch9z Safety-tuned LL a MA s: Lessons from improving the safety of large language models that follow instructions . In The Twelfth International Conference on Learning Representations
2024
-
[5]
Zouying Cao, Yifei Yang, and Hai Zhao. 2025. Scans: Mitigating the exaggerated safety for llms via safety-conscious activation steering. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 23523--23531
2025
-
[6]
JailbreakBench: An Open Robustness Benchmark for Jailbreaking Large Language Models
Patrick Chao, Edoardo Debenedetti, Alexander Robey, Maksym Andriushchenko, Francesco Croce, Vikash Sehwag, Edgar Dobriban, Nicolas Flammarion, George J. Pappas, Florian Tramer, Hamed Hassani, and Eric Wong. 2024. https://arxiv.org/abs/2404.01318 Jailbreakbench: An open robustness benchmark for jailbreaking large language models . Preprint, arXiv:2404.01318
work page internal anchor Pith review arXiv 2024
-
[7]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. https://arxiv.org/abs/2110.14168 Training verifiers to solve math word problems . Preprint, arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Aladin Djuhera, Swanand Ravindra Kadhe, Farhan Ahmed, Syed Zawad, and Holger Boche. 2025. Safemerge: Preserving safety alignment in fine-tuned large language models via selective layer-wise model merging. arXiv preprint arXiv:2503.17239
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, Shawn Presser, and Connor Leahy. 2020. https://arxiv.org/abs/2101.00027 The pile: An 800gb dataset of diverse text for language modeling . Preprint, arXiv:2101.00027
work page internal anchor Pith review arXiv 2020
-
[11]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, and 1 others. 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
a rle, Felix Friedrich, Manuel Brack, Bj \
Ruben H \"a rle, Felix Friedrich, Manuel Brack, Bj \"o rn Deiseroth, Patrick Schramowski, and Kristian Kersting. 2024. Scar: Sparse conditioned autoencoders for concept detection and steering in llms. arXiv preprint arXiv:2411.07122
-
[13]
Chia-Yi Hsu, Yu-Lin Tsai, Chih-Hsun Lin, Pin-Yu Chen, Chia-Mu Yu, and Chun-Ying Huang. 2024. Safe lora: The silver lining of reducing safety risks when finetuning large language models. Advances in Neural Information Processing Systems, 37:65072--65094
2024
- [14]
-
[15]
Tiansheng Huang, Sihao Hu, Fatih Ilhan, Selim Tekin, and Ling Liu. 2024 b . Lisa: Lazy safety alignment for large language models against harmful fine-tuning attack. Advances in Neural Information Processing Systems, 37:104521--104555
2024
-
[16]
Harmful Fine-tuning Attacks and Defenses for Large Language Models: A Survey
Tiansheng Huang, Sihao Hu, Fatih Ilhan, Selim Furkan Tekin, and Ling Liu. Harmful fine-tuning attacks and defenses for large language models: A survey, 2024. URL https://arxiv. org/abs/2409.18169
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [17]
-
[18]
Tiansheng Huang, Sihao Hu, and Ling Liu. 2024 d . Vaccine: Perturbation-aware alignment for large language models against harmful fine-tuning attack. Advances in Neural Information Processing Systems, 37:74058--74088
2024
-
[19]
Jiaming Ji, Mickel Liu, Juntao Dai, Xuehai Pan, Chi Zhang, Ce Bian, Boyuan Chen, Ruiyang Sun, Yizhou Wang, and Yaodong Yang. 2023. https://openreview.net/forum?id=g0QovXbFw3 Beavertails: Towards improved safety alignment of LLM via a human-preference dataset . In Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track
2023
-
[20]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. https://arxiv.org/abs/2310.0...
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [21]
- [22]
-
[23]
Kenneth Li, Oam Patel, Fernanda Vi \'e gas, Hanspeter Pfister, and Martin Wattenberg. 2023. https://openreview.net/forum?id=aLLuYpn83y Inference-time intervention: Eliciting truthful answers from a language model . In Thirty-seventh Conference on Neural Information Processing Systems
2023
- [24]
- [25]
-
[26]
Shen Li, Liuyi Yao, Lan Zhang, and Yaliang Li. 2025 b . https://openreview.net/forum?id=kUH1yPMAn7 Safety layers in aligned large language models: The key to LLM security . In The Thirteenth International Conference on Learning Representations
2025
-
[27]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, and 1 others. 2024. Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [28]
-
[29]
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, and 1 others. 2024. Harmbench: A standardized evaluation framework for automated red teaming and robust refusal. arXiv preprint arXiv:2402.04249
work page internal anchor Pith review arXiv 2024
- [30]
-
[31]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, and 1 others. 2022. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730--27744
2022
- [32]
- [34]
-
[35]
Xiangyu Qi, Yi Zeng, Tinghao Xie, Pin-Yu Chen, Ruoxi Jia, Prateek Mittal, and Peter Henderson. 2024. https://openreview.net/forum?id=hTEGyKf0dZ Fine-tuning aligned language models compromises safety, even when users do not intend to! In The Twelfth International Conference on Learning Representations
2024
- [36]
-
[37]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728--53741
2023
-
[38]
Domenic Rosati, Jan Wehner, Kai Williams, Lukasz Bartoszcze, Robie Gonzales, Subhabrata Majumdar, Hassan Sajjad, Frank Rudzicz, and 1 others. 2024. Representation noising: A defence mechanism against harmful finetuning. Advances in Neural Information Processing Systems, 37:12636--12676
2024
-
[39]
SEAT: Sparse Entity-Aware Tuning for Knowledge Adaptation while Preserving Epistemic Abstention
William F. Shen, Xinchi Qiu, Nicola Cancedda, and Nicholas D. Lane. 2025. https://arxiv.org/abs/2506.14387 Don't make it up: Preserving ignorance awareness in llm fine-tuning . Preprint, arXiv:2506.14387
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [40]
- [41]
-
[42]
Manning, Andrew Ng, and Christopher Potts
Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D. Manning, Andrew Ng, and Christopher Potts. 2013. https://aclanthology.org/D13-1170/ Recursive deep models for semantic compositionality over a sentiment treebank . In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, pages 1631--1642, Seattle, Washi...
2013
-
[43]
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B Hashimoto. 2023. Alpaca: A strong, replicable instruction-following model. Stanford Center for Research on Foundation Models. https://crfm. stanford. edu/2023/03/13/alpaca. html, 3(6):7
2023
-
[44]
Gemma: Open Models Based on Gemini Research and Technology
Gemma Team, T Mesnard, C Hardin, R Dadashi, S Bhupatiraju, S Pathak, L Sifre, M Rivi \`e re, MS Kale, J Love, and 1 others. Gemma: Open models based on gemini research and technology. arxiv 2024. arXiv preprint arXiv:2403.08295
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, and 1 others. 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[46]
Jiong Wang, Jiazhao Li, Yiquan Li, Xiangyu Qi, Junjie Hu, Sharon Li, Patrick Drew McDaniel, Muhao Chen, Bo Li, and Chaowei Xiao. 2024. https://api.semanticscholar.org/CorpusID:276117259 Backdooralign: Mitigating fine-tuning based jailbreak attack with backdoor enhanced safety alignment . Advances in Neural Information Processing Systems 37
2024
-
[47]
Yibo Wang, Tiansheng Huang, Li Shen, Huanjin Yao, Haotian Luo, Rui Liu, Naiqiang Tan, Jiaxing Huang, and Dacheng Tao. 2025. https://doi.org/10.48550/arXiv.2501.18100 Panacea: Mitigating harmful fine-tuning for large language models via post-fine-tuning perturbation . CoRR, abs/2501.18100
- [48]
- [50]
-
[51]
Xin Yi, Shunfan Zheng, Linlin Wang, Gerard de Melo, Xiaoling Wang, and Liang He. 2025. Nlsr: Neuron-level safety realignment of large language models against harmful fine-tuning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 25706--25714
2025
- [52]
- [53]
-
[54]
Andy Zou, Long Phan, Justin Wang, Derek Duenas, Maxwell Lin, Maksym Andriushchenko, J Zico Kolter, Matt Fredrikson, and Dan Hendrycks. 2024. https://openreview.net/forum?id=IbIB8SBKFV Improving alignment and robustness with circuit breakers . In The Thirty-eighth Annual Conference on Neural Information Processing Systems
2024
-
[55]
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. 2023. Universal and transferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.