Recognition: no theorem link
Do Transformers Use their Depth Adaptively? Evidence from a Relational Reasoning Task
Pith reviewed 2026-05-10 15:30 UTC · model grok-4.3
The pith
Finetuned transformers show clearer adaptive depth use on relational reasoning tasks than pretrained ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
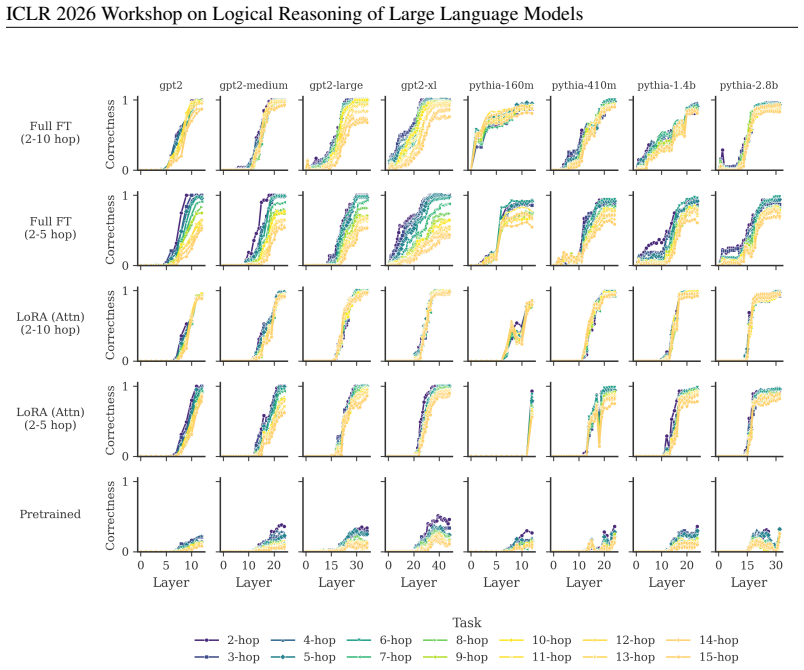
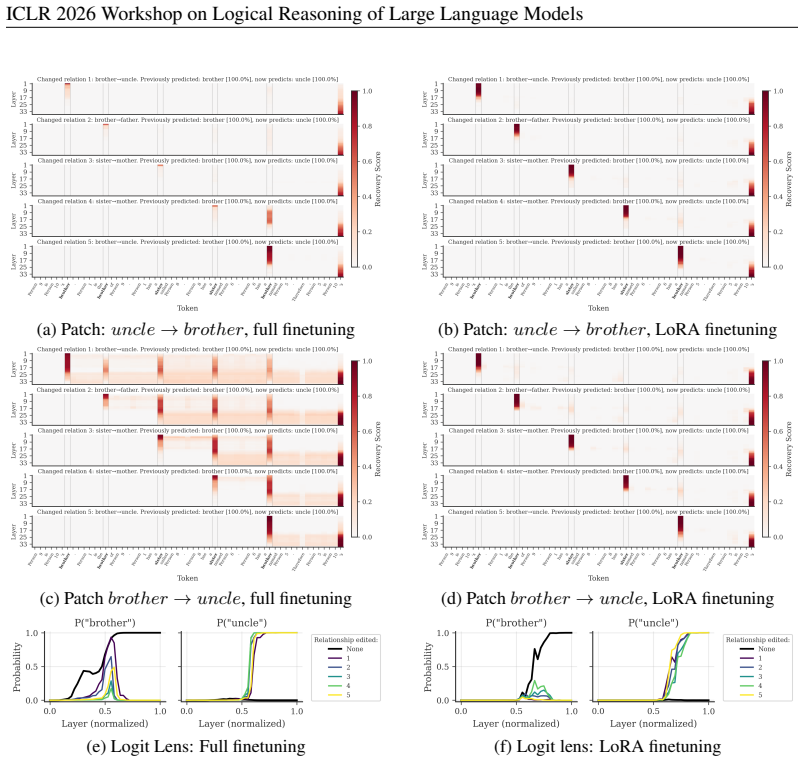
On a controlled family-relation reasoning task whose difficulty scales with the number of hops that must be composed, logit-lens readouts and causal-patching measurements reveal limited adaptive depth in pretrained transformers, with larger models sometimes converging on easier instances in fewer layers and all models generally recruiting more layers to integrate information as hop count rises. The same measurements on task-finetuned models yield clearer and more consistent evidence that depth usage scales with difficulty, and the effect is larger when finetuning is less constrained and therefore moves the model farther from its original language-modeling distribution.
What carries the argument
Logit-lens early readouts that expose how the final prediction distribution evolves across successive layers, together with causal-patching interventions that quantify the number of layers required to integrate tokens that hold successive links in a relational chain.
Load-bearing premise
The logit lens and causal patching measurements accurately reflect whether the model is genuinely using different amounts of depth rather than merely producing different surface-level output patterns.
What would settle it
If, after finetuning, the logit lens shows essentially identical prediction trajectories for short and long chains and causal patching shows no systematic increase in the layers needed to combine tokens as hop count grows, the claim of adaptive depth use would be falsified.
Figures





read the original abstract
We investigate whether transformers use their depth adaptively across tasks of increasing difficulty. Using a controlled multi-hop relational reasoning task based on family stories, where difficulty is determined by the number of relationship hops that must be composed, we monitor (i) how predictions evolve across layers via early readouts (the logit lens) and (ii) how task-relevant information is integrated across tokens via causal patching. For pretrained models, we find some limited evidence for adaptive depth use: some larger models need fewer layers to arrive at plausible answers for easier tasks, and models generally use more layers to integrate information across tokens as chain length increases. For models finetuned on the task, we find clearer and more consistent evidence of adaptive depth use, with the effect being stronger for less constrained finetuning regimes that do not preserve general language modeling abilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates whether transformer models use their depth adaptively on tasks of varying difficulty, using a controlled multi-hop relational reasoning task based on family relationship chains. Difficulty is parameterized by the number of hops. The authors track prediction evolution via logit lens early readouts and measure cross-token information integration via causal patching experiments. They report limited evidence of adaptive depth use in pretrained models (e.g., larger models stabilizing earlier on short chains) and clearer, more consistent evidence in finetuned models, with stronger effects under less constrained finetuning that does not preserve general language modeling capabilities.
Significance. If the central observations hold under tighter controls, the work would provide useful empirical evidence that finetuning regimes can promote adaptive computation in transformers, with potential implications for mechanistic understanding of depth utilization and efficient inference. The controlled task and dual measurement approach (logit lens plus patching) are strengths that allow systematic variation of difficulty; however, the observational character limits the strength of causal claims about internal adaptive mechanisms.
major comments (2)
- [§4] §4 (Logit Lens Results): The finding that predictions for shorter chains stabilize at earlier layers does not distinguish adaptive depth allocation from the simpler alternative that easier inputs produce representations that become linearly separable after fewer layers by construction. No controls (e.g., early-exit performance matching full-depth performance on hard examples, or comparison to a fixed-depth baseline) are reported to separate these possibilities.
- [§5] §5 (Causal Patching Experiments): The reported increase in cross-token information flow for longer chains could arise from input complexity or token count rather than any internal decision to allocate additional depth. The manuscript lacks ablations such as length-matched controls, shuffled difficulty labels, or forced fixed-layer models that would test whether the patching effect reflects adaptive modulation.
minor comments (2)
- [§3] The task description would benefit from a concrete example of a 1-hop vs. 3-hop query in the methods section to make the difficulty parameterization immediately clear to readers.
- Figure captions for the patching heatmaps could explicitly note the statistical test and number of examples used to compute the reported effects.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. The suggestions for tighter controls are well-taken and will help clarify the interpretation of our results on adaptive depth use. We respond to each major comment below and outline the revisions we will incorporate.
read point-by-point responses
-
Referee: §4 (Logit Lens Results): The finding that predictions for shorter chains stabilize at earlier layers does not distinguish adaptive depth allocation from the simpler alternative that easier inputs produce representations that become linearly separable after fewer layers by construction. No controls (e.g., early-exit performance matching full-depth performance on hard examples, or comparison to a fixed-depth baseline) are reported to separate these possibilities.
Authors: We agree that the logit lens stabilization pattern for shorter chains is consistent with the alternative that easier inputs simply become linearly separable earlier by construction, without requiring an internal adaptive allocation of depth. Our manuscript already notes that evidence is limited in pretrained models and stronger after finetuning, which we interpret as task-specific encouragement of this behavior. To address the concern directly, we will revise §4 to explicitly discuss this alternative explanation. We will add post-hoc comparisons of early-readout accuracy on hard examples against full-depth performance and include truncated fixed-depth baselines by evaluating the model at intermediate layers. These analyses can be performed without retraining and will be reported in the revision. revision: partial
-
Referee: §5 (Causal Patching Experiments): The reported increase in cross-token information flow for longer chains could arise from input complexity or token count rather than any internal decision to allocate additional depth. The manuscript lacks ablations such as length-matched controls, shuffled difficulty labels, or forced fixed-layer models that would test whether the patching effect reflects adaptive modulation.
Authors: We acknowledge that longer chains involve more tokens and greater input complexity, which could drive the observed increase in cross-token patching effects independently of any adaptive depth mechanism. While our task design holds the overall story template fixed and varies only the number of relational hops, token count does scale with difficulty. We will add length-matched controls by subsampling or constructing examples with comparable token lengths across hop counts. We will also include analyses with shuffled difficulty labels to test specificity to actual task difficulty and compare information flow in models forced to fixed shallower depths. These ablations will be incorporated into §5 of the revised manuscript. revision: yes
Circularity Check
No significant circularity: purely empirical measurements independent of claims
full rationale
This is an observational study that applies logit-lens readouts and causal patching to track layer-wise prediction stabilization and cross-token information flow on a controlled relational-reasoning task. No derivations, parameter fits, or self-citations are used to generate the central claims; the reported patterns are direct empirical observations whose validity can be assessed against external benchmarks or alternative models. The paper therefore contains no load-bearing steps that reduce to their own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Nora Belrose, Zach Furman, Logan Smith, Danny Halawi, Igor Ostrovsky, Lev McKinney, Stella Biderman, and Jacob Steinhardt. Eliciting latent predictions from transformers with the tuned lens.arXiv preprint arXiv:2303.08112,
work page internal anchor Pith review arXiv
-
[2]
Yangyi Chen, Binxuan Huang, Yifan Gao, Zhengyang Wang, Jingfeng Yang, and Heng Ji
Dan Biderman, Jacob Portes, Jose Javier Gonzalez Ortiz, Mansheej Paul, Philip Greengard, Connor Jennings, Daniel King, Sam Havens, Vitaliy Chiley, Jonathan Frankle, et al. Lora learns less and forgets less.arXiv preprint arXiv:2405.09673,
-
[3]
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901,
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901,
1901
-
[4]
R´obert Csord´as, Christopher D Manning, and Christopher Potts. Do language models use their depth efficiently?arXiv preprint arXiv:2505.13898,
-
[5]
Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Łukasz Kaiser. Universal transformers.arXiv preprint arXiv:1807.03819,
work page internal anchor Pith review arXiv
-
[6]
arXiv preprint arXiv:2409.15647 (2024)
Ying Fan, Yilun Du, Kannan Ramchandran, and Kangwook Lee. Looped transformers for length generalization.arXiv preprint arXiv:2409.15647,
-
[7]
Nnsight and ndif: Democratizing access to foundation model internals
Jaden Fiotto-Kaufman, Alexander R Loftus, Eric Todd, Jannik Brinkmann, Caden Juang, Koyena Pal, Can Rager, Aaron Mueller, Samuel Marks, Arnab Sen Sharma, et al. NNsight and NDIF: Democratizing access to foundation model internals.arXiv preprint arXiv:2407.14561,
-
[8]
Predictability and surprise in large generative models
10 ICLR 2026 Workshop on Logical Reasoning of Large Language Models Deep Ganguli, Danny Hernandez, Liane Lovitt, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova Dassarma, Dawn Drain, Nelson Elhage, et al. Predictability and surprise in large generative models. InProceedings of the 2022 ACM conference on fairness, accountability, and transparency, ...
2026
-
[9]
Transformer feed-forward layers build predictions by promoting concepts in the vocabulary space
Mor Geva, Avi Caciularu, Kevin Wang, and Yoav Goldberg. Transformer feed-forward layers build predictions by promoting concepts in the vocabulary space. InProceedings of the 2022 conference on empirical methods in natural language processing, pp. 30–45,
2022
-
[10]
The unreasonable ineffectiveness of the deeper layers.arXiv preprint arXiv:2403.17887, 2024
Andrey Gromov, Kushal Tirumala, Hassan Shapourian, Paolo Glorioso, and Daniel A Roberts. The unreasonable ineffectiveness of the deeper layers.arXiv preprint arXiv:2403.17887,
- [11]
-
[12]
Danny Halawi, Jean-Stanislas Denain, and Jacob Steinhardt. Overthinking the truth: Understanding how language models process false demonstrations.arXiv preprint arXiv:2307.09476,
-
[13]
What affects the effective depth of large language models? arXiv preprint arXiv:2512.14064,
Yi Hu, Cai Zhou, and Muhan Zhang. What affects the effective depth of large language models? arXiv preprint arXiv:2512.14064,
-
[14]
arXiv preprint arXiv:2406.19384 , year=
Vedang Lad, Jin Hwa Lee, Wes Gurnee, and Max Tegmark. The remarkable robustness of llms: Stages of inference?arXiv preprint arXiv:2406.19384,
-
[15]
Racing thoughts: Explaining contextualization errors in large language models
Michael A Lepori, Michael Curtis Mozer, and Asma Ghandeharioun. Racing thoughts: Explaining contextualization errors in large language models. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 3020–3036,
2025
-
[16]
Interpreting key mechanisms of factual recall in transformer-based language models
Ang Lv, Yuhan Chen, Kaiyi Zhang, Yulong Wang, Lifeng Liu, Ji-Rong Wen, Jian Xie, and Rui Yan. Interpreting key mechanisms of factual recall in transformer-based language models.arXiv preprint arXiv:2403.19521,
-
[17]
The expressive power of transformers with chain of thought, 2024
William Merrill and Ashish Sabharwal. The expressive power of transformers with chain of thought. arXiv preprint arXiv:2310.07923,
-
[18]
William Merrill and Ashish Sabharwal. A little depth goes a long way: The expressive power of log-depth transformers.arXiv preprint arXiv:2503.03961,
-
[19]
Language models implement simple word2vec- style vector arithmetic
Jack Merullo, Carsten Eickhoff, and Ellie Pavlick. Language models implement simple word2vec- style vector arithmetic. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 5030–5047,
2024
-
[20]
Accessed: 2026-02-18. Enrique Queipo-de Llano, ´Alvaro Arroyo, Federico Barbero, Xiaowen Dong, Michael Bronstein, Yann LeCun, and Ravid Shwartz-Ziv. Attention sinks and compression valleys in llms are two sides of the same coin.arXiv preprint arXiv:2510.06477,
-
[21]
Understanding transformer reasoning capabilities via graph algorithms.Advances in Neural Information Processing Systems, 37:78320–78370,
11 ICLR 2026 Workshop on Logical Reasoning of Large Language Models Clayton Sanford, Bahare Fatemi, Ethan Hall, Anton Tsitsulin, Mehran Kazemi, Jonathan Halcrow, Bryan Perozzi, and Vahab Mirrokni. Understanding transformer reasoning capabilities via graph algorithms.Advances in Neural Information Processing Systems, 37:78320–78370,
2026
-
[22]
Reasoning with latent thoughts: On the power of looped transformers
Nikunj Saunshi, Nishanth Dikkala, Zhiyuan Li, Sanjiv Kumar, and Sashank J Reddi. Reasoning with latent thoughts: On the power of looped transformers.arXiv preprint arXiv:2502.17416,
-
[23]
Clutrr: A diagnostic benchmark for inductive reasoning from text.arXiv preprint arXiv:1908.06177,
Koustuv Sinha, Shagun Sodhani, Jin Dong, Joelle Pineau, and William L Hamilton. Clutrr: A diagnostic benchmark for inductive reasoning from text.arXiv preprint arXiv:1908.06177,
-
[24]
Emergent Abilities of Large Language Models
Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yo- gatama, Maarten Bosma, Denny Zhou, Donald Metzler, et al. Emergent abilities of large language models.arXiv preprint arXiv:2206.07682,
work page internal anchor Pith review arXiv
-
[25]
Transformers: State-of-the-art natural language processing
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, et al. Transformers: State-of-the-art natural language processing. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pp. 38–45,
2020
-
[26]
How do transformers learn variable binding in symbolic programs?arXiv preprint arXiv:2505.20896,
Yiwei Wu, Atticus Geiger, and Rapha ¨el Milli `ere. How do transformers learn variable binding in symbolic programs?arXiv preprint arXiv:2505.20896,
-
[27]
Fred Zhang and Neel Nanda. Towards best practices of activation patching in language models: Metrics and methods.arXiv preprint arXiv:2309.16042,
-
[28]
12 ICLR 2026 Workshop on Logical Reasoning of Large Language Models A IMPLEMENTATION DETAILS All models are accessed through the huggingface transformers library (Wolf et al., 2020); see Table 1 for their links. The logit lens analyses were implemented by accessing the intermediate hidden states and LM-head modules using the functionalities present in the...
2026
-
[29]
Table 1: All pretrained models used in this study, with HuggingFace identifiers, parameter counts, and number of transformer layers
library. Table 1: All pretrained models used in this study, with HuggingFace identifiers, parameter counts, and number of transformer layers. Family HuggingFace identifier Parameters Layers GPT-2 gpt2117M 12 gpt2-medium345M 24 gpt2-large774M 36 gpt2-xl1.5B 48 Pythia pythia-160m-deduped160M 12 pythia-410m-deduped410M 24 pythia-1.4b-deduped1.4B 24 pythia-2....
2026
-
[30]
The first row is identical to Fig
(a) Llama3 Family (b) Qwen2 Family Figure B2: Layerwise decoding results for Llama and Qwen2 families 14 ICLR 2026 Workshop on Logical Reasoning of Large Language Models B.2 ADDITIONAL CAUSAL PATCHING RESULTS FOR PRETRAINED MODELS(SIBLINGS-ONLY SETTING) (a) 3-hop: Phi2 (b) 3-hop: Phi4 (c) 3-hop: Phi4-reasoning (d) 5-hop: Phi2 (e) 5-hop: Phi4 (f) 5-hop: Ph...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.