Recognition: unknown
Latent-Condensed Transformer for Efficient Long Context Modeling
Pith reviewed 2026-05-10 15:07 UTC · model grok-4.3
The pith
Latent-Condensed Attention condenses context inside MLA's latent space to cut KV cache by 90% and accelerate prefilling 2.5 times at 128K lengths.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Context can be condensed inside the disentangled latent space of MLA by applying query-aware pooling to semantic latent vectors and anchor selection to positional keys. This single mechanism simultaneously lowers the quadratic cost of attention and the size of the KV cache while adding no new parameters, and the resulting approximation carries a length-independent error bound that holds regardless of how long the input becomes.
What carries the argument
Latent-Condensed Attention (LCA), which performs query-aware pooling on semantic latent vectors and anchor selection on positional keys within the disentangled MLA representation.
Load-bearing premise
Disentangling semantic latent vectors from positional keys inside the MLA space lets query-aware pooling and anchor selection keep enough information for downstream tasks without unacceptable error at long lengths.
What would settle it
An empirical measurement showing that LCA's task accuracy or attention output error grows with context length beyond 128K, or that performance falls substantially below standard MLA or full attention on the same long-context benchmarks.
Figures


read the original abstract
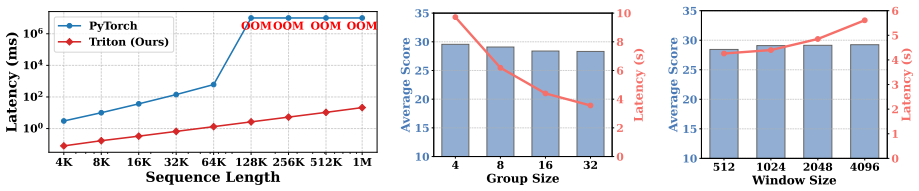
Large language models (LLMs) face significant challenges in processing long contexts due to the linear growth of the key-value (KV) cache and quadratic complexity of self-attention. Existing approaches address these bottlenecks separately: Multi-head Latent Attention (MLA) reduces the KV cache by projecting tokens into a low-dimensional latent space, while sparse attention reduces computation. However, sparse methods cannot operate natively on MLA's compressed latent structure, missing opportunities for joint optimization. In this paper, we propose Latent-Condensed Attention (LCA), which directly condenses context within MLA's latent space, where the representation is disentangled into semantic latent vectors and positional keys. LCA separately aggregates semantic vectors via query-aware pooling and preserves positional keys via anchor selection. This approach jointly reduces both computational cost and KV cache without adding parameters. Beyond MLA, LCA's design is architecture-agnostic and readily extends to other attention mechanisms such as GQA. Theoretically, we prove a length-independent error bound. Experiments show LCA achieves up to 2.5$\times$ prefilling speedup and 90% KV cache reduction at 128K context while maintaining competitive performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Latent-Condensed Attention (LCA), which condenses context directly inside the latent space of Multi-head Latent Attention (MLA) by disentangling semantic latent vectors from positional keys. Semantic vectors are aggregated via query-aware pooling while positional keys are preserved through anchor selection; the resulting construction is claimed to jointly reduce prefilling compute and KV cache size without added parameters. The paper states a length-independent error bound theoretically and reports up to 2.5× prefilling speedup together with 90% KV cache reduction at 128K context while preserving competitive performance. The method is presented as architecture-agnostic and extensible to mechanisms such as GQA.
Significance. If the length-independent error bound is rigorously established and the reported speed/memory gains prove robust across models and tasks, LCA would constitute a meaningful advance in efficient long-context modeling by unifying latent compression with sparse selection inside an existing attention mechanism, without introducing new parameters or requiring separate sparse-attention redesigns.
major comments (2)
- [Theoretical Analysis] Theoretical Analysis section: the length-independent error bound is asserted to follow from query-aware pooling of semantic vectors and anchor selection on positional keys, yet the manuscript provides no derivation sketch, explicit assumptions on the quality of semantic-positional disentanglement in MLA space, or quantitative characterization of retained information. Without these, it is impossible to verify whether residual positional leakage or missed long-range signals would cause the approximation error to grow with context length, directly undermining the central theoretical guarantee that supports the efficiency claims.
- [Experiments] Experiments section: the headline empirical results (2.5× prefilling speedup, 90% KV cache reduction at 128K, competitive performance) are stated without reference to the precise baselines (standard MLA, other sparse or latent methods), evaluation protocol (perplexity vs. downstream tasks, exact context lengths tested), or ablation studies isolating the contribution of query-aware pooling versus anchor selection. These omissions render the performance claims unverifiable and prevent assessment of whether the gains are load-bearing or incidental.
minor comments (1)
- [Abstract] Abstract: the phrase 'architecture-agnostic and readily extends to other attention mechanisms such as GQA' would benefit from a one-sentence concrete illustration of the required interface changes.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our theoretical and empirical contributions. We address each point below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [Theoretical Analysis] Theoretical Analysis section: the length-independent error bound is asserted to follow from query-aware pooling of semantic vectors and anchor selection on positional keys, yet the manuscript provides no derivation sketch, explicit assumptions on the quality of semantic-positional disentanglement in MLA space, or quantitative characterization of retained information. Without these, it is impossible to verify whether residual positional leakage or missed long-range signals would cause the approximation error to grow with context length, directly undermining the central theoretical guarantee that supports the efficiency claims.
Authors: We acknowledge that the current Theoretical Analysis section would benefit from greater explicitness. Although the manuscript asserts a length-independent error bound derived from the query-aware pooling and anchor selection steps, we agree that a derivation sketch, the precise assumptions on semantic-positional disentanglement within MLA latent space, and quantitative bounds on retained information are necessary for verification. In the revised manuscript we will expand this section with a step-by-step proof outline, state the assumptions clearly, and include a quantitative characterization of information retention to demonstrate that the error remains independent of context length. revision: yes
-
Referee: [Experiments] Experiments section: the headline empirical results (2.5× prefilling speedup, 90% KV cache reduction at 128K, competitive performance) are stated without reference to the precise baselines (standard MLA, other sparse or latent methods), evaluation protocol (perplexity vs. downstream tasks, exact context lengths tested), or ablation studies isolating the contribution of query-aware pooling versus anchor selection. These omissions render the performance claims unverifiable and prevent assessment of whether the gains are load-bearing or incidental.
Authors: We agree that the experimental reporting requires additional specificity to allow independent verification. The revised manuscript will explicitly list the baselines (standard MLA together with representative sparse and latent attention methods), describe the evaluation protocol in detail (including perplexity on long-context corpora and downstream task results at the exact context lengths tested), and add ablation studies that isolate the individual contributions of query-aware pooling and anchor selection. revision: yes
Circularity Check
No significant circularity; derivation is a new construction with independent theoretical claim
full rationale
The paper introduces Latent-Condensed Attention as an explicit new mechanism operating on MLA's latent space via query-aware pooling and anchor selection. The length-independent error bound is stated as a proved theoretical result rather than a fitted quantity or renamed empirical pattern. No equations or steps in the provided abstract reduce the speedup, cache reduction, or error bound to parameters chosen from target data or to self-citations by construction. The architecture-agnostic extension claim further indicates independent content. This matches the default expectation of non-circularity for a novel method presentation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Program Synthesis with Large Language Models
GQA: Training generalized multi-query trans- former models from multi-head checkpoints. InPro- ceedings of the 2023 Conference on Empirical Meth- ods in Natural Language Processing, pages 4895– 4901, Singapore. Association for Computational Lin- guistics. Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jian...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
InInterna- tional Conference on Learning Representations
Token merging: Your vit but faster. InInterna- tional Conference on Learning Representations. Yaofo Chen, Zeng You, Shuhai Zhang, Haokun Li, Yirui Li, Yaowei Wang, and Mingkui Tan. 2025. Core context aware transformers for long context language modeling. InInternational Conference on Machine Learning. Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark C...
2025
-
[3]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word prob- lems.arXiv preprint arXiv:2110.14168. Tri Dao, Daniel Y . Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. 2022. Flashattention: Fast and memory-efficient exact attention with io-awareness. InAdvances in Neural Information Processing Sys- tems. DeepSeek-AI. 2025. Deepseek-v3.2: Pushing the frontier of open lar...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
RULER: What's the Real Context Size of Your Long-Context Language Models?
Measuring massive multitask language under- standing. InInternational Conference on Learning Representations. Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shan- tanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. 2024. Ruler: What’s the real context size of your long-context language models? arXiv preprint arXiv:2404.06654. 10 Shengding Hu...
work page internal anchor Pith review arXiv 2024
-
[5]
Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437. Xiang Liu, Zhenheng Tang, Peijie Dong, Zeyu Li, Yue Liu, Bo Li, Xuming Hu, and Xiaowen Chu. 2025. Chunkkv: Semantic-preserving kv cache compres- sion for efficient long-context llm inference. InAd- vances in Neural Information Processing Systems. Potsawee Manakul and Mark J. F. Gales. 2021. Lon...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
InPro- ceedings of the International Workshop on Machine Learning and Programming Languages, pages 10– 19
Triton: an intermediate language and com- piler for tiled neural network computations. InPro- ceedings of the International Workshop on Machine Learning and Programming Languages, pages 10– 19. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. InAd...
2017
-
[7]
First, we bound the logit perturbations
We start by bounding the first term. First, we bound the logit perturbations. Using the Cauchy–Schwarz inequality and the given bounds on the query norm and key approximations, |ai −b i|= |q⊤ t (ki − ˜ki)|√dh ≤ ∥qt∥2∥ki − ˜ki∥2√dh ≤ Qδk√dh =:ε, where bi denotes the logit used by LCA for token i (i.e., bi =a i for i∈R and bi =b rep G(i) for i∈H ). Hence ea...
-
[8]
Given ∥vi − ˜vi∥2 ≤δ v and the fact that p′ i form a proba- bility distribution, we have tX i=1 p′ i(vi − ˜vi) 2 ≤ tX i=1 p′ i∥vi − ˜vi∥2 ≤δv tX i=1 p′ i =δ v.(14)
We bound the second error component. Given ∥vi − ˜vi∥2 ≤δ v and the fact that p′ i form a proba- bility distribution, we have tX i=1 p′ i(vi − ˜vi) 2 ≤ tX i=1 p′ i∥vi − ˜vi∥2 ≤δv tX i=1 p′ i =δ v.(14)
-
[9]
(13) and (14) gives ∥E∥2 ≤V e2ε −1 +δ v, whereε=Qδ k/√dh
Combing Eqn. (13) and (14) gives ∥E∥2 ≤V e2ε −1 +δ v, whereε=Qδ k/√dh. A.3 Empirical Validation of Key and Value Deviations we empirically measure the per-token key and value deviations δk and δv across different con- text lengths and tasks. For each setting, we ran- domly sample 128 sequences and compute the ra- tio of the L2 norm of the deviation betwee...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.