Recognition: unknown
Calibrated Confidence Estimation for Tabular Question Answering
Pith reviewed 2026-05-10 14:56 UTC · model grok-4.3
The pith
Agreement across lossless table formats like Markdown and JSON calibrates LLM confidence more accurately than self-ratings or sampling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
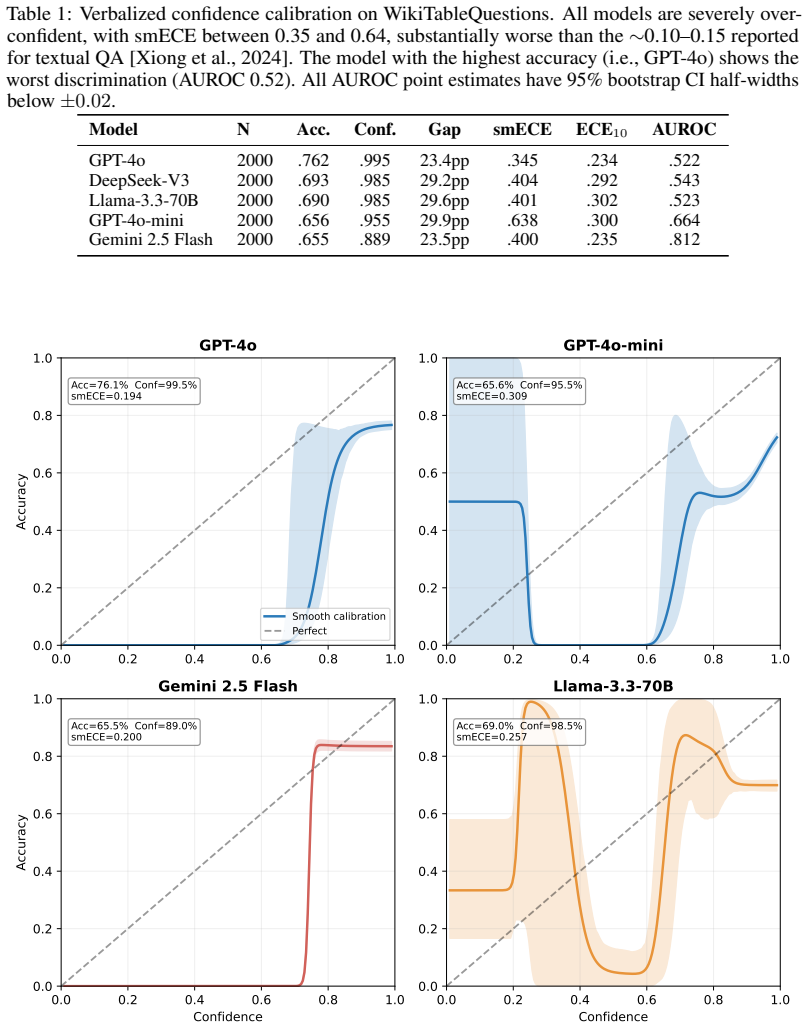
The paper shows that Multi-Format Agreement exploits the unique property of structured data to have multiple lossless serializations, and that agreement across these serializations yields reliable confidence estimates that reduce ECE by 44-63 percent and lift AUROC to 0.80 on TableBench, generalizing across models and complementing sampling-based methods.
What carries the argument
Multi-Format Agreement (MFA): confidence derived from agreement among model answers when the input table is serialized in four different lossless formats (Markdown, HTML, JSON, CSV).
If this is right
- MFA reduces expected calibration error by 44-63% across tested models.
- It achieves mean AUROC of 0.80 on TableBench and generalizes to four models.
- An MFA plus self-consistency ensemble raises AUROC from 0.74 to 0.82 at 20% lower API cost.
- Structure-aware recalibration improves AUROC by 10 points over standard post-hoc methods.
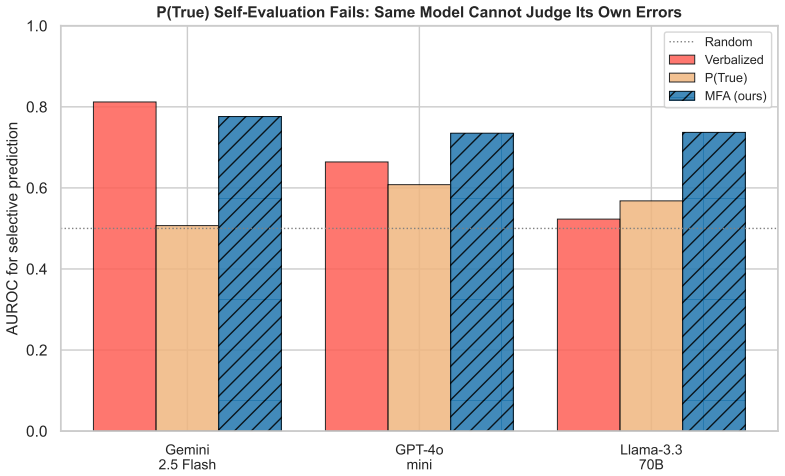
- The performance gap between self-evaluation and perturbation methods holds across both benchmarks and all fully covered models.
Where Pith is reading between the lines
- Production tabular QA systems could adopt format variation as a default low-overhead calibration step.
- Structured inputs offer natural diversity signals that free-text methods lack, suggesting similar techniques for code or database queries.
- Optimal weighting or selection among formats could further improve results without additional model calls.
- The approach may transfer to other domains where data admits multiple canonical representations.
Load-bearing premise
That the different lossless table serializations produce independent, unbiased signals of uncertainty without format-specific artifacts that distort AUROC or ECE measurements.
What would settle it
Measuring no ECE reduction or AUROC gain from MFA versus single-format baselines on a new tabular QA benchmark with varied table structures would falsify the central claim.
Figures






read the original abstract
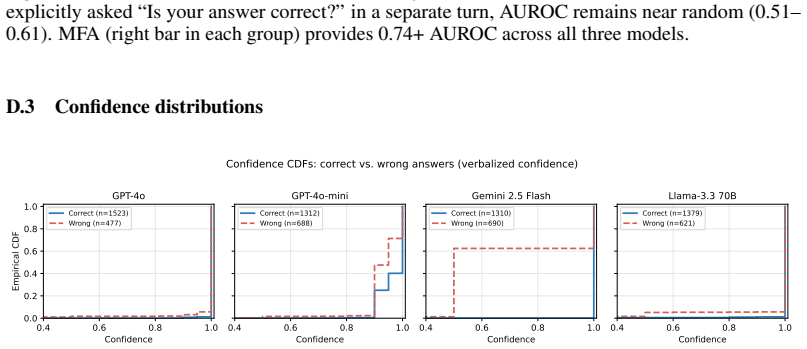
Large language models (LLMs) are increasingly deployed for tabular question answering, yet calibration on structured data is largely unstudied. This paper presents the first systematic comparison of five confidence estimation methods across five frontier LLMs and two tabular QA benchmarks. All models are severely overconfident (smooth ECE 0.35-0.64 versus 0.10-0.15 reported for textual QA). A consistent self-evaluation versus perturbation dichotomy replicates across both benchmarks and all four fully-covered models: self-evaluation methods (verbalized, P(True)) achieve AUROC 0.42-0.76, while perturbation methods (semantic entropy, self-consistency, and our Multi-Format Agreement) achieve AUROC 0.78-0.86. Per-model paired bootstrap tests reject the null at p<0.001 after Holm-Bonferroni correction, and a 3-seed check on GPT-4o-mini gives a per-seed standard deviation of only 0.006. The paper proposes Multi-Format Agreement (MFA), which exploits the lossless and deterministic serialization variation unique to structured data (Markdown, HTML, JSON, CSV) to estimate confidence at 20% lower API cost than sampling baselines. MFA reduces ECE by 44-63%, generalizes across all four models on TableBench (mean AUROC 0.80), and combines complementarily with sampling: an MFA + self-consistency ensemble lifts AUROC from 0.74 to 0.82. A secondary contribution, structure-aware recalibration, improves AUROC by +10 percentage points over standard post-hoc methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the first systematic study of confidence calibration for LLMs on tabular question answering. It evaluates five estimation methods across five frontier models and two benchmarks, documenting severe overconfidence (ECE 0.35-0.64). It identifies a consistent gap between self-evaluation methods (AUROC 0.42-0.76) and perturbation methods (AUROC 0.78-0.86), supported by paired bootstrap tests with Holm-Bonferroni correction and low seed variance. The central contribution is Multi-Format Agreement (MFA), which uses agreement across four lossless table serializations (Markdown, HTML, JSON, CSV) to estimate confidence at reduced API cost. MFA is reported to cut ECE by 44-63%, achieve mean AUROC 0.80 on TableBench, generalize across models, and combine complementarily with self-consistency (lifting AUROC from 0.74 to 0.82). A secondary method, structure-aware recalibration, improves AUROC by 10 points over standard post-hoc approaches.
Significance. If the empirical claims hold, the work fills a clear gap in calibration research for structured data, where LLMs are increasingly applied. MFA exploits a property unique to tabular inputs (deterministic lossless serializations) to deliver a lower-cost uncertainty signal than sampling baselines. The consistent self-evaluation vs. perturbation dichotomy across benchmarks and models, together with the reported statistical controls (paired bootstraps, correction, 3-seed variance of 0.006), provides reproducible evidence. The complementarity result and the recalibration technique have direct practical value for reliable deployment of LLMs on tables.
major comments (2)
- [MFA definition and experimental results] The load-bearing assumption for MFA—that the four serializations supply sufficiently independent, unbiased signals whose disagreements primarily reflect model uncertainty—is not directly tested. The manuscript does not report per-format accuracy, ECE, or AUROC statistics (e.g., in the experimental results section or any accompanying table), leaving open the possibility that format-specific performance differences (e.g., JSON vs. HTML) contribute to the observed agreement metric. This directly affects the interpretation of the reported AUROC 0.80, ECE reductions of 44-63%, and the complementarity claim with sampling.
- [Results on TableBench and recalibration experiments] The generalization claim for MFA (mean AUROC 0.80 across four models on TableBench) and the +10-point AUROC gain from structure-aware recalibration rest on the same untested independence assumption. Adding per-format breakdowns and a controlled ablation (e.g., agreement on random vs. format-matched perturbations) would be required to confirm that the gains are not partly artifacts of format compatibility.
minor comments (2)
- [Methods] The abstract and methods could more explicitly state the exact prompt templates and decision rules used for each serialization to enable exact reproduction.
- [Figures] Figure captions for the calibration plots should include the exact number of examples per bin and the smoothing parameter for the reported smooth ECE.
Simulated Author's Rebuttal
We thank the referee for the positive summary and constructive major comments. We address each point below and will revise the manuscript accordingly to strengthen the empirical support for MFA.
read point-by-point responses
-
Referee: [MFA definition and experimental results] The load-bearing assumption for MFA—that the four serializations supply sufficiently independent, unbiased signals whose disagreements primarily reflect model uncertainty—is not directly tested. The manuscript does not report per-format accuracy, ECE, or AUROC statistics (e.g., in the experimental results section or any accompanying table), leaving open the possibility that format-specific performance differences (e.g., JSON vs. HTML) contribute to the observed agreement metric. This directly affects the interpretation of the reported AUROC 0.80, ECE reductions of 44-63%, and the complementarity claim with sampling.
Authors: We agree that per-format performance statistics were not reported and that they would help validate the independence assumption. In the revised manuscript we will add a new table reporting accuracy, ECE, and AUROC for each individual serialization (Markdown, HTML, JSON, CSV) across all models and both benchmarks. We will also report pairwise agreement rates between formats to show that systematic format biases do not dominate the disagreement signal. These additions will allow readers to assess whether format-specific differences drive the MFA results. The MFA definition itself (majority agreement across lossless serializations) remains unchanged, but the new statistics will clarify its interpretation and support the reported AUROC and ECE gains. revision: yes
-
Referee: [Results on TableBench and recalibration experiments] The generalization claim for MFA (mean AUROC 0.80 across four models on TableBench) and the +10-point AUROC gain from structure-aware recalibration rest on the same untested independence assumption. Adding per-format breakdowns and a controlled ablation (e.g., agreement on random vs. format-matched perturbations) would be required to confirm that the gains are not partly artifacts of format compatibility.
Authors: We accept that a controlled ablation would further isolate the contribution of deterministic format variation. In the revision we will include the per-format breakdowns noted above. We will also add an ablation comparing MFA (using the four lossless formats) against agreement computed on randomly perturbed versions of a single format (e.g., multiple noisy Markdown serializations). This will test whether gains arise from the unique lossless serialization diversity of tabular data rather than generic perturbation effects. The structure-aware recalibration method operates on post-hoc features of the table structure and is independent of MFA; we will clarify this distinction in the text and report its results separately. These changes will strengthen the generalization and complementarity claims. revision: yes
Circularity Check
No circularity: purely empirical method comparisons with no derivations or self-referential reductions
full rationale
The paper conducts systematic empirical evaluations of five confidence estimation methods (including the proposed Multi-Format Agreement) across LLMs and tabular QA benchmarks, reporting AUROC, ECE, and bootstrap tests. No equations, derivations, or fitted parameters are defined in terms of the target quantities; MFA is introduced as a practical serialization-variation heuristic and evaluated directly via measurements rather than derived from self-citations or ansatzes. All central claims rest on external experimental outcomes (per-model paired tests, seed variance checks) that do not reduce to the paper's own inputs by construction. The analysis is self-contained against benchmarks with no load-bearing self-citation chains or renaming of known results as novel derivations.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Bootstrap resampling yields valid p-values for paired AUROC comparisons after multiple-testing correction
- domain assumption AUROC and smooth ECE are appropriate metrics for assessing confidence estimation quality
invented entities (1)
-
Multi-Format Agreement (MFA)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
DiverseAgentEntropy : Knowledge-preserving query reformulation for multi-agent uncertainty estimation
AWS AI Labs . DiverseAgentEntropy : Knowledge-preserving query reformulation for multi-agent uncertainty estimation. In Findings of EMNLP, 2025
2025
-
[4]
Smooth ECE : Principled reliability diagrams via kernel smoothing
Jaros aw B asiok and Preetum Nakkiran. Smooth ECE : Principled reliability diagrams via kernel smoothing. In Proceedings of ICLR, 2024
2024
-
[5]
Elephants never forget: Memorization and learning of tabular data in large language models
Sebastian Bordt, Harsha Nori, Vanessa Rodrigues, Besmira Nushi, and Rich Caruana. Elephants never forget: Memorization and learning of tabular data in large language models. In Proceedings of COLM, 2024
2024
-
[6]
Adaptive abstention for text-to- SQL via conformal prediction on hidden layers
Wei Chen et al. Adaptive abstention for text-to- SQL via conformal prediction on hidden layers. In Proceedings of SIGMOD, 2025
2025
-
[7]
FinQA : A dataset of numerical reasoning over financial data
Zhiyu Chen, Wenhu Chen, Charese Smiley, Sameena Shah, Iana Borber, Siamak Shakeri, et al. FinQA : A dataset of numerical reasoning over financial data. In Proceedings of EMNLP, 2021
2021
-
[8]
Multicalibration of language models
Gianluca Detommaso et al. Multicalibration of language models. In Proceedings of ICML, 2024
2024
-
[9]
Confidence estimation for LLM -based text-to- SQL
Reza Entezari Maleki et al. Confidence estimation for LLM -based text-to- SQL . In Proceedings of AAAI, 2025
2025
-
[10]
SPUQ : Perturbation-based uncertainty quantification for large language models
Xiang Gao, Jiaxin Zhang, Lalla Mouatadid, and Kamalika Das. SPUQ : Perturbation-based uncertainty quantification for large language models. In Proceedings of EACL, 2024
2024
-
[11]
Selective classification for deep neural networks
Yonatan Geifman and Ran El-Yaniv. Selective classification for deep neural networks. In Advances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[12]
arXiv preprint arXiv:2311.08298 , year=
Jiahui Geng, Fengyu Cai, Yuxia Wang, Heinz Koeppl, Preslav Nakov Anil, and Iryna Gurevych. A survey of confidence estimation and calibration in large language models. arXiv preprint arXiv:2311.08298, 2024
-
[13]
On calibration of modern neural networks
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q Weinberger. On calibration of modern neural networks. In Proceedings of the International Conference on Machine Learning (ICML), 2017
2017
-
[14]
Large language models cannot self-correct reasoning yet
Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. Large language models cannot self-correct reasoning yet. In Proceedings of ICLR, 2024
2024
-
[15]
Maximizing overall diversity for improved uncertainty estimates in deep ensembles
Siddhartha Jain, Ge Liu, Jonas Mueller, and David Gifford. Maximizing overall diversity for improved uncertainty estimates in deep ensembles. In Proceedings of AAAI, 2020
2020
-
[16]
Sample-dependent adaptive temperature scaling for improved calibration
Tom Joy et al. Sample-dependent adaptive temperature scaling for improved calibration. In Proceedings of AAAI, 2023
2023
-
[17]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language models (mostly) know what they know. arXiv preprint arXiv:2207.05221, 2022
work page internal anchor Pith review arXiv 2022
-
[18]
CCPS : Calibrated confidence via perturbed hidden states
Reza Khanmohammadi et al. CCPS : Calibrated confidence via perturbed hidden states. In Proceedings of EMNLP, 2025
2025
-
[19]
Semantic entropy probes: Uncertainty from hidden states
Jannik Kossen et al. Semantic entropy probes: Uncertainty from hidden states. In Proceedings of ICLR, 2025
2025
-
[20]
Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation. In Proceedings of ICLR, 2023
2023
-
[21]
Verified uncertainty calibration
Ananya Kumar, Percy Liang, and Tengyu Ma. Verified uncertainty calibration. In Advances in Neural Information Processing Systems (NeurIPS), 2019
2019
-
[22]
Conformal prediction with large language models for multi-choice question answering
Bhawesh Kumar, Charlie Lu, Gauri Gupta, Anil Palepu, David Bellamy, Ramesh Raskar, and Andrew Beam. Conformal prediction with large language models for multi-choice question answering. arXiv preprint arXiv:2305.18404, 2023
-
[23]
Evidential semantic entropy for LLM uncertainty quantification
Lucie Kunitomo-Jacquin, Edison Marrese-Taylor, Ken Fukuda, and Masahiro Hamasaki. Evidential semantic entropy for LLM uncertainty quantification. In Proceedings of EACL, 2026
2026
-
[24]
Simple and scalable predictive uncertainty estimation using deep ensembles
Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple and scalable predictive uncertainty estimation using deep ensembles. In Advances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[25]
TrustSQL : A reliability benchmark for text-to- SQL with penalty-based scoring and uncertainty-based abstention
Gyubok Lee et al. TrustSQL : A reliability benchmark for text-to- SQL with penalty-based scoring and uncertainty-based abstention. In Proceedings of ICLR, 2025
2025
-
[26]
ConfTuner : Tokenized brier score for verbalized confidence fine-tuning
Hao Li et al. ConfTuner : Tokenized brier score for verbalized confidence fine-tuning. In Advances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[27]
Can LLM already serve as a database interface? A B ig bench for large-scale database grounded text-to- SQL
Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo, et al. Can LLM already serve as a database interface? A B ig bench for large-scale database grounded text-to- SQL . In Advances in Neural Information Processing Systems (NeurIPS), 2024 a
2024
-
[28]
Few-shot recalibration of language models
Xiang Lisa Li, Urvashi Khandelwal, and Kelvin Guu. Few-shot recalibration of language models. arXiv preprint arXiv:2403.18286, 2024 b
-
[29]
Calibrating LLM -based evaluator for text-to- SQL
Hansong Liu et al. Calibrating LLM -based evaluator for text-to- SQL . In Proceedings of EMNLP, 2025
2025
-
[30]
Semantic energy: Detecting LLM hallucination beyond entropy
Huan Ma, Jiadong Pan, Jing Liu, Yan Chen, Joey Tianyi Zhou, Guangyu Wang, Qinghua Hu, Hua Wu, Changqing Zhang, and Haifeng Wang. Semantic energy: Detecting LLM hallucination beyond entropy. arXiv preprint arXiv:2508.14496, 2025
-
[31]
Confidence scoring for LLM -generated SQL in supply chain data extraction
Jiekai Ma and Yikai Zhao. Confidence scoring for LLM -generated SQL in supply chain data extraction. In KDD Workshop on AI for Supply Chain, 2025
2025
-
[32]
QA -calibration: Conditional calibration of LLM confidence via input-group embeddings
Pia Manggala et al. QA -calibration: Conditional calibration of LLM confidence via input-group embeddings. In Proceedings of ICLR, 2025
2025
-
[33]
Language models with conformal factuality guarantees
Christopher Mohri and Tatsunori Hashimoto. Language models with conformal factuality guarantees. In Proceedings of ICML, 2024
2024
-
[34]
u ller, Nicholas Popovic, Michael F \
Philip M \"u ller, Nicholas Popovi c , Michael F \"a rber, and Peter Steinbach. Benchmarking uncertainty calibration in large language model long-form question answering. arXiv preprint arXiv:2602.00279, 2026
-
[35]
Beyond semantic entropy: Smooth nearest neighbor entropy for long-form LLM uncertainty
Hai Nguyen et al. Beyond semantic entropy: Smooth nearest neighbor entropy for long-form LLM uncertainty. In Findings of the Association for Computational Linguistics: ACL, 2025
2025
-
[36]
Nemotron-4 340b technical report
NVIDIA . Nemotron-4 340b technical report. Technical report, NVIDIA, 2024. Lists WikiTableQuestions among supervised fine-tuning datasets
2024
-
[37]
Compositional semantic parsing on semi-structured tables
Panupong Pasupat and Percy Liang. Compositional semantic parsing on semi-structured tables. In Proceedings of ACL, 2015
2015
-
[38]
Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods
John Platt. Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods. Advances in Large Margin Classifiers, 1999
1999
-
[39]
Strength in numbers: Estimating confidence of large language models via multiple completions
Glenn Portillo Wightman, Alexandra Delucia, and Mark Dredze. Strength in numbers: Estimating confidence of large language models via multiple completions. In Proceedings of the TrustNLP Workshop at ACL, 2023
2023
-
[40]
Text-to- SQL calibration: No need to ask---just rescale model probabilities
Ashwin Ramachandran and Sunita Sarawagi. Text-to- SQL calibration: No need to ask---just rescale model probabilities. arXiv preprint arXiv:2411.16742, 2024
-
[41]
Mapping from meaning: Modeling prompt sensitivity as generalization error
Yair Reing et al. Mapping from meaning: Modeling prompt sensitivity as generalization error. In Proceedings of AAAI, 2025
2025
-
[42]
Tabular representation, noisy operators, and impacts on table structure understanding tasks in LLM s
Ananya Singha, Jos \'e Cambronero, Sumit Gulwani, Vu Le, and Chris Parnin. Tabular representation, noisy operators, and impacts on table structure understanding tasks in LLM s. arXiv preprint arXiv:2310.10358, 2023
-
[43]
Selective classification with entropy-based confidence for text-to- SQL error detection
Alexander Somov and Elena Tutubalina. Selective classification with entropy-based confidence for text-to- SQL error detection. In Proceedings of AAAI, 2025
2025
-
[44]
Calibrated interpretation: Confidence estimation in semantic parsing
Elias Stengel-Eskin and Benjamin Van Durme. Calibrated interpretation: Confidence estimation in semantic parsing. Transactions of the Association for Computational Linguistics (TACL), 2023
2023
-
[45]
Table meets LLM : Can large language models understand structured table data? A benchmark and empirical study
Yuan Sui, Mengyu Zhou, Mingjie Zhou, Shi Han, and Dongmei Zhang. Table meets LLM : Can large language models understand structured table data? A benchmark and empirical study. Proceedings of WSDM, 2024
2024
-
[46]
Lei Tang, Wei Zhou, and Mohsen Mesgar. Exploring generative process reward modeling for semi-structured data: A case study of table question answering. In Proceedings of EACL, 2026. arXiv:2510.20304
-
[47]
Confidence improves self-consistency in LLM s
Amir Taubenfeld, Tom Sheffer, Eran Ofek, Amir Feder, Ariel Goldstein, Zorik Gekhman, and Gal Yona. Confidence improves self-consistency in LLM s. In Findings of the Association for Computational Linguistics: ACL, 2025
2025
-
[48]
Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback
Katherine Tian, Eric Mitchell, Huaxiu Yao, Christopher D Manning, and Chelsea Finn. Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. In Proceedings of EMNLP, 2023
2023
-
[49]
Bayesian prompt ensembles: Model uncertainty estimation for black-box large language models
Francesco Tonolini, Thomas Sherborne, and Tom Sherborne. Bayesian prompt ensembles: Model uncertainty estimation for black-box large language models. In Findings of ACL, 2024
2024
-
[50]
APRICOT : Calibrating large language models using their generations only
Dennis Ulmer, Christian Hardmeier, and Jes Frellsen. APRICOT : Calibrating large language models using their generations only. In Proceedings of ACL, 2024
2024
-
[51]
LM -polygraph: A library for uncertainty quantification in language models
Roman Vashurin et al. LM -polygraph: A library for uncertainty quantification in language models. Transactions of the Association for Computational Linguistics (TACL), 2025
2025
-
[52]
Self-consistency improves chain of thought reasoning in language models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. In Proceedings of ICLR, 2023
2023
-
[53]
Self-consistency sampling outperforms self-evaluation on reasoning tasks
Xuezhi Wang et al. Self-consistency sampling outperforms self-evaluation on reasoning tasks. In Findings of EMNLP, 2024 a
2024
-
[54]
Accurate and regret-aware numerical problem solver for tabular question answering
Yuxiang Wang, Jianzhong Qi, and Junhao Gan. Accurate and regret-aware numerical problem solver for tabular question answering. In Proceedings of the AAAI Conference on Artificial Intelligence, 2025
2025
-
[55]
Chain-of-table: Evolving tables in the reasoning chain for table understanding
Zilong Wang, Hao Zhang, Chun-Liang Li, Julian Eisenschlos, Vincent Perot, Zifeng Wang, et al. Chain-of-table: Evolving tables in the reasoning chain for table understanding. In Proceedings of ICLR, 2024 b
2024
-
[56]
TableBench : A comprehensive and complex benchmark for table question answering
Xianjie Wu, Jian Yang, Linzheng Chai, Ge Zhang, Jiaheng Liu, Xinrun Du, Di Liang, Daixin Shu, Xianfu Cheng, Tianzhen Sun, Guanglin Niu, Tongliang Li, and Zhoujun Li. TableBench : A comprehensive and complex benchmark for table question answering. In Proceedings of the AAAI Conference on Artificial Intelligence, 2025
2025
-
[57]
Can LLM s express their uncertainty? an empirical evaluation of confidence elicitation in LLM s
Miao Xiong, Zhiyuan Hu, Xinyang Lu, Yifei Li, Jie Fu, Junxian He, and Bryan Hooi. Can LLM s express their uncertainty? an empirical evaluation of confidence elicitation in LLM s. In Proceedings of the International Conference on Learning Representations (ICLR), 2024
2024
-
[58]
On calibration of large language models: From response to capability,
Sin-Han Yang, Cheng-Kuang Wu, Chieh-Yen Lin, Yun-Nung Chen, Hung-yi Lee, and Shao-Hua Sun. On calibration of large language models: From response to capability. arXiv preprint arXiv:2602.13540, 2026
-
[59]
Benchmarking LLM s via uncertainty quantification
Fanghua Ye, Mingming Yang, Jianhui Pang, Longyue Wang, Derek F Wong, Emine Yilmaz, Shuming Shi, and Zhaopeng Tu. Benchmarking LLM s via uncertainty quantification. In Advances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[60]
STaR : Towards effective and stable table reasoning via slow-thinking large language models
Huajian Zhang, Mingyue Cheng, Yucong Luo, and Xiaoyu Tao. STaR : Towards effective and stable table reasoning via slow-thinking large language models. arXiv preprint arXiv:2511.11233, 2025
-
[61]
Self-improving code generation via semantic entropy and behavioral consensus
Huan Zhang, Wei Cheng, and Wei Hu. Self-improving code generation via semantic entropy and behavioral consensus. arXiv preprint arXiv:2603.29292, 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.