Recognition: unknown
Enhance-then-Balance Modality Collaboration for Robust Multimodal Sentiment Analysis
Pith reviewed 2026-05-10 14:45 UTC · model grok-4.3
The pith
A two-stage enhance-then-balance process strengthens weaker signals and prevents dominant modalities from overshadowing them in multimodal sentiment analysis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The EBMC model improves representation quality via semantic disentanglement and cross-modal enhancement to strengthen weaker modalities, then employs an Energy-guided Modality Coordination mechanism that achieves implicit gradient rebalancing through a differentiable equilibrium objective together with Instance-aware Modality Trust Distillation that estimates sample-level reliability to modulate fusion weights adaptively, producing state-of-the-art or competitive accuracy and strong results under missing-modality conditions.
What carries the argument
The Enhance-then-Balance Modality Collaboration framework, which first lifts weaker-modality representations through disentanglement and cross-modal enhancement, then coordinates contributions via energy-based equilibrium objectives and reliability-weighted distillation to reduce modality competition.
If this is right
- Multimodal fusion can achieve higher overall accuracy by reducing the overshadowing effect of stronger modalities on weaker ones.
- Models remain effective for emotion inference even when audio, visual, or text channels are absent or corrupted.
- Implicit gradient rebalancing removes the need for manual modality-specific hyperparameters during training.
- Adaptive trust weighting improves sample-level reliability estimation across varied data distributions.
Where Pith is reading between the lines
- The same strengthen-then-rebalance pattern could extend to other multimodal tasks such as visual question answering where one modality frequently dominates.
- Testing the framework on real-world social-media data with naturally occurring missing channels would reveal its practical limits beyond controlled benchmarks.
- The trust-distillation component might transfer to settings like federated multimodal learning to handle device-specific signal quality differences.
Load-bearing premise
The premise that semantic disentanglement plus cross-modal enhancement will reliably improve weaker modalities and that energy-guided coordination plus trust distillation will rebalance contributions without introducing new overfitting or bias on real data.
What would settle it
On standard multimodal sentiment benchmarks such as CMU-MOSI or CMU-MOSEI, randomly remove one modality from test samples and check whether EBMC maintains higher accuracy or F1 than strong baselines; a substantial drop would falsify the robustness claim.
Figures


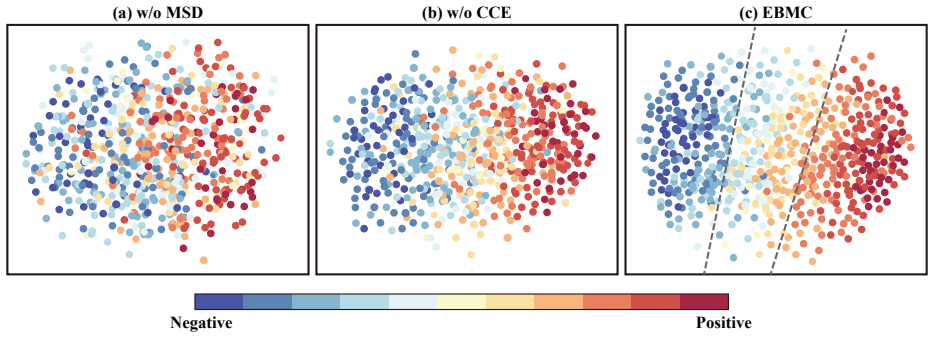



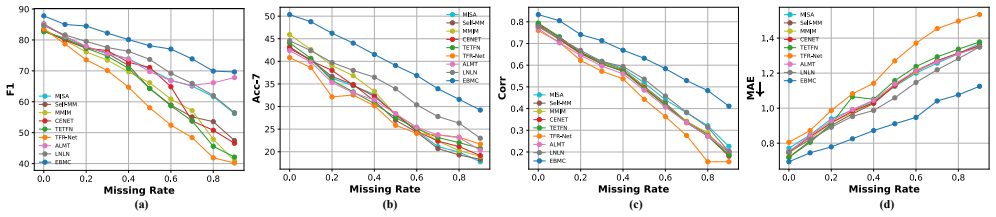

read the original abstract
Multimodal sentiment analysis (MSA) integrates heterogeneous text, audio, and visual signals to infer human emotions. While recent approaches leverage cross-modal complementarity, they often struggle to fully utilize weaker modalities. In practice, dominant modalities tend to overshadow non-verbal ones, inducing modality competition and limiting overall contributions. This imbalance degrades fusion performance and robustness under noisy or missing modalities. To address this, we propose a novel model, Enhance-then-Balance Modality Collaboration framework (EBMC). EBMC improves representation quality via semantic disentanglement and cross-modal enhancement, strengthening weaker modalities. To prevent dominant modalities from overwhelming others, an Energy-guided Modality Coordination mechanism achieves implicit gradient rebalancing via a differentiable equilibrium objective. Furthermore, Instance-aware Modality Trust Distillation estimates sample-level reliability to adaptively modulate fusion weights, ensuring robustness. Extensive experiments demonstrate that EBMC achieves state-of-the-art or competitive results and maintains strong performance under missing-modality settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Enhance-then-Balance Modality Collaboration (EBMC) framework for multimodal sentiment analysis. It first strengthens weaker modalities through semantic disentanglement and cross-modal enhancement, then applies an Energy-guided Modality Coordination mechanism that uses a differentiable equilibrium objective for implicit gradient rebalancing to prevent dominant modalities from overshadowing others. An Instance-aware Modality Trust Distillation component estimates sample-level reliability to adaptively modulate fusion weights. The authors claim that extensive experiments show EBMC achieves state-of-the-art or competitive results while maintaining strong performance under missing-modality conditions.
Significance. If the central mechanisms are shown to deliver the claimed rebalancing and robustness, the work could meaningfully advance multimodal sentiment analysis by providing a practical approach to modality competition and imbalance, a persistent issue in real-world deployments with noisy or incomplete inputs. The staged enhance-then-balance design and the use of an equilibrium objective represent a potentially useful direction for implicit coordination without explicit per-modality weights.
major comments (2)
- [Section 3.3] Section 3.3: The Energy-guided Modality Coordination is presented as the key mechanism for implicit gradient rebalancing via a differentiable equilibrium objective. Yet Tables 2–4 report only downstream accuracy/F1 and missing-modality robustness; there are no ablations that isolate the equilibrium term, no measurements or statistics of per-modality gradient norms before/after the mechanism, and no verification that the fixed point equalizes influence rather than acting as generic regularization. This leaves the central 'balance' claim without direct empirical support.
- [Experimental sections (Tables 2–4)] Experimental sections (Tables 2–4 and associated text): The manuscript asserts SOTA or competitive results and robustness, but provides no details on the number of random seeds, statistical significance tests, error bars, or component-wise ablations (disentanglement, enhancement, coordination, distillation). Without these, it is impossible to attribute performance gains specifically to the proposed rebalancing and trust mechanisms rather than to the enhancement stage alone.
minor comments (1)
- [Abstract] Abstract: The abstract refers to 'extensive experiments' without naming the datasets, modalities, or primary evaluation metrics; adding one sentence with this information would improve immediate readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and outline revisions that will strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [Section 3.3] Section 3.3: The Energy-guided Modality Coordination is presented as the key mechanism for implicit gradient rebalancing via a differentiable equilibrium objective. Yet Tables 2–4 report only downstream accuracy/F1 and missing-modality robustness; there are no ablations that isolate the equilibrium term, no measurements or statistics of per-modality gradient norms before/after the mechanism, and no verification that the fixed point equalizes influence rather than acting as generic regularization. This leaves the central 'balance' claim without direct empirical support.
Authors: We acknowledge that direct measurements such as per-modality gradient norm statistics and an ablation isolating the equilibrium objective would provide stronger verification of the rebalancing effect. The reported gains in accuracy, F1, and missing-modality robustness are consistent with the intended coordination, but we agree these do not constitute isolated evidence. In the revision we will add (i) an ablation removing only the equilibrium term and (ii) before/after gradient-norm statistics across modalities to confirm the fixed point equalizes influence rather than acting as generic regularization. revision: yes
-
Referee: [Experimental sections (Tables 2–4)] Experimental sections (Tables 2–4 and associated text): The manuscript asserts SOTA or competitive results and robustness, but provides no details on the number of random seeds, statistical significance tests, error bars, or component-wise ablations (disentanglement, enhancement, coordination, distillation). Without these, it is impossible to attribute performance gains specifically to the proposed rebalancing and trust mechanisms rather than to the enhancement stage alone.
Authors: We agree that the current experimental reporting lacks the granularity needed to attribute gains precisely. The manuscript will be revised to (i) state that all results are averaged over 5 random seeds with standard deviations shown as error bars, (ii) include statistical significance tests (paired t-tests with p-values), and (iii) expand the ablation table to evaluate each component in isolation (semantic disentanglement, cross-modal enhancement, energy-guided coordination, and instance-aware trust distillation). These additions will allow clearer separation of the contribution of the balance and trust stages from the enhancement stage. revision: yes
Circularity Check
No significant circularity; mechanisms proposed and validated empirically
full rationale
The paper introduces the EBMC framework consisting of semantic disentanglement plus cross-modal enhancement for strengthening weaker modalities, followed by an Energy-guided Modality Coordination mechanism defined via a differentiable equilibrium objective for implicit rebalancing, and Instance-aware Modality Trust Distillation for adaptive weighting. These components are presented as architectural choices whose effectiveness is assessed through downstream experiments on accuracy, F1, and missing-modality robustness rather than through any derivation that reduces the claimed outcomes to fitted inputs or self-referential definitions. No equations are shown that equate a prediction to its own construction, no load-bearing self-citations reduce the central premise to prior unverified work by the same authors, and the abstract and described structure treat the balance and enhancement steps as independent proposals supported by external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Heterogeneous text, audio, and visual signals contain complementary semantic information that can be disentangled and cross-enhanced to strengthen weaker modalities.
Reference graph
Works this paper leans on
-
[1]
Multimodal lan- guage analysis in the wild: CMU-MOSEI dataset and inter- pretable dynamic fusion graph
AmirAli Bagher Zadeh, Paul Pu Liang, Soujanya Poria, Erik Cambria, and Louis-Philippe Morency. Multimodal lan- guage analysis in the wild: CMU-MOSEI dataset and inter- pretable dynamic fusion graph. InProceedings of the 56th Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), pages 2236–2246, 2018
2018
-
[2]
Iemo- cap: Interactive emotional dyadic motion capture database
Carlos Busso, Murtaza Bulut, Chi-Chun Lee, Abe Kazemzadeh, Emily Mower, Samuel Kim, Jeannette N Chang, Sungbok Lee, and Shrikanth S Narayanan. Iemo- cap: Interactive emotional dyadic motion capture database. Language resources and evaluation, 42:335–359, 2008
2008
-
[3]
Cr-gac: Cross-modal recombination via graph-attention col- laborative optimization for multimodal sentiment analysis
Haoran Chen, Jiapeng Liu, Zuhe Li, Yushan Pan, Hongwei Tao, Huaiguang Wu, Yunyang Wang, and Chenguang Yang. Cr-gac: Cross-modal recombination via graph-attention col- laborative optimization for multimodal sentiment analysis. Expert Systems with Applications, page 129805, 2025
2025
-
[4]
Hyperdi- mensional uncertainty quantification for multimodal uncer- tainty fusion in autonomous vehicles perception
Luke Chen, Junyao Wang, Trier Mortlock, Pramod Khar- gonekar, and Mohammad Abdullah Al Faruque. Hyperdi- mensional uncertainty quantification for multimodal uncer- tainty fusion in autonomous vehicles perception. InProceed- ings of the Computer Vision and Pattern Recognition Confer- ence, pages 22306–22316, 2025
2025
-
[5]
Revisiting modality imbalance in multimodal pedestrian detection
Arindam Das, Sudip Das, Ganesh Sistu, Jonathan Horgan, Ujjwal Bhattacharya, Edward Jones, Martin Glavin, and Ciar´an Eising. Revisiting modality imbalance in multimodal pedestrian detection. In2023 IEEE International Conference on Image Processing (ICIP), pages 1755–1759, 2023
2023
-
[6]
Covarep—a collaborative voice analysis repository for speech technologies
Gilles Degottex, John Kane, Thomas Drugman, Tuomo Raitio, and Stefan Scherer. Covarep—a collaborative voice analysis repository for speech technologies. In2014 ieee in- ternational conference on acoustics, speech and signal pro- cessing (icassp), pages 960–964, 2014
2014
-
[7]
Bert: Pre-training of deep bidirectional trans- formers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional trans- formers for language understanding. InProceedings of the 2019 conference of the North American chapter of the asso- ciation for computational linguistics: human language tech- nologies, volume 1 (long and short papers), pages 4171– 4186, 2019
2019
-
[8]
Zero-shot conversational stance detection: Dataset and approaches
Yuzhe Ding, Kang He, Bobo Li, Li Zheng, Haijun He, Fei Li, Chong Teng, and Donghong Ji. Zero-shot conversational stance detection: Dataset and approaches. InFindings of the Association for Computational Linguistics: ACL 2025, pages 3221–3235, 2025
2025
-
[9]
Pmr: Prototypical modal rebalance for multi- modal learning
Yunfeng Fan, Wenchao Xu, Haozhao Wang, Junxiao Wang, and Song Guo. Pmr: Prototypical modal rebalance for multi- modal learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20029– 20038, 2023
2023
-
[10]
Detached and interactive multimodal learn- ing
Yunfeng Fan, Wenchao Xu, Haozhao Wang, Junhong Liu, and Song Guo. Detached and interactive multimodal learn- ing. InProceedings of the 32nd ACM International Confer- ence on Multimedia, pages 5470–5478, 2024
2024
-
[11]
Emoe: Modality-specific enhanced dynamic emotion experts
Yiyang Fang, Wenke Huang, Guancheng Wan, Kehua Su, and Mang Ye. Emoe: Modality-specific enhanced dynamic emotion experts. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14314–14324, 2025
2025
-
[12]
Catch your emotion: Sharpening emo- tion perception in multimodal large language models
Yiyang Fang, Jian Liang, Wenke Huang, He Li, Kehua Su, and Mang Ye. Catch your emotion: Sharpening emo- tion perception in multimodal large language models. In Forty-second International Conference on Machine Learn- ing, 2025
2025
-
[13]
Missing the missing values: The ugly duckling of fairness in machine learning.International Journal of Intelligent Systems, 36(7):3217–3258, 2021
Mart ´ınez-Plumed Fernando, Ferri C`esar, Nieves David, and Hern´andez-Orallo Jos ´e. Missing the missing values: The ugly duckling of fairness in machine learning.International Journal of Intelligent Systems, 36(7):3217–3258, 2021
2021
-
[14]
Enhanced experts with uncertainty- aware routing for multimodal sentiment analysis
Zixian Gao, Disen Hu, Xun Jiang, Huimin Lu, Heng Tao Shen, and Xing Xu. Enhanced experts with uncertainty- aware routing for multimodal sentiment analysis. InPro- ceedings of the 32nd ACM International Conference on Mul- timedia, pages 9650–9659, 2024
2024
-
[15]
Embracing unimodal aleatoric un- certainty for robust multimodal fusion
Zixian Gao, Xun Jiang, Xing Xu, Fumin Shen, Yujie Li, and Heng Tao Shen. Embracing unimodal aleatoric un- certainty for robust multimodal fusion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26876–26885, 2024
2024
-
[16]
Wei Han, Hui Chen, and Soujanya Poria. Improving mul- timodal fusion with hierarchical mutual information maxi- mization for multimodal sentiment analysis.arXiv preprint arXiv:2109.00412, 2021
-
[17]
Misa: Modality-invariant and-specific representa- tions for multimodal sentiment analysis
Devamanyu Hazarika, Roger Zimmermann, and Soujanya Poria. Misa: Modality-invariant and-specific representa- tions for multimodal sentiment analysis. InProceedings of the 28th Association for Computing Machinery International Conference on Multimedia, pages 1122–1131, 2020
2020
-
[18]
Kang He, Boyu Chen, Yuzhe Ding, Fei Li, Chong Teng, and Donghong Ji. Pase: Prototype-aligned calibration and shapley-based equilibrium for multimodal sentiment analy- sis.arXiv preprint arXiv:2511.17585, 2025
-
[19]
DALR: Dual-level alignment learning for multimodal sentence representation learning
Kang He, Yuzhe Ding, Haining Wang, Fei Li, Chong Teng, and Donghong Ji. DALR: Dual-level alignment learning for multimodal sentence representation learning. InFindings of the Association for Computational Linguistics: ACL 2025, pages 3586–3601, 2025
2025
-
[20]
Adaptive unimodal regulation for balanced multimodal in- formation acquisition
Chengxiang Huang, Yake Wei, Zequn Yang, and Di Hu. Adaptive unimodal regulation for balanced multimodal in- formation acquisition. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 25854– 25863, 2025
2025
-
[21]
Multimodal prompting with missing modalities for vi- sual recognition
Yi-Lun Lee, Yi-Hsuan Tsai, Wei-Chen Chiu, and Chen-Yu Lee. Multimodal prompting with missing modalities for vi- sual recognition. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, pages 14943–14952, 2023
2023
-
[22]
Revisiting disentanglement and fusion on modality and context in conversational multi- modal emotion recognition
Bobo Li, Hao Fei, Lizi Liao, Yu Zhao, Chong Teng, Tat-Seng Chua, Donghong Ji, and Fei Li. Revisiting disentanglement and fusion on modality and context in conversational multi- modal emotion recognition. InProceedings of the 31st ACM International Conference on Multimedia, pages 5923–5934, 2023
2023
-
[23]
A unified self-distillation framework for multimodal sentiment analysis with uncertain missing modalities
Mingcheng Li, Dingkang Yang, Yuxuan Lei, Shunli Wang, Shuaibing Wang, Liuzhen Su, Kun Yang, Yuzheng Wang, Mingyang Sun, and Lihua Zhang. A unified self-distillation framework for multimodal sentiment analysis with uncertain missing modalities. InProceedings of the AAAI conference on artificial intelligence, pages 10074–10082, 2024
2024
-
[24]
Correlation-decoupled knowledge distillation for multimodal sentiment analy- sis with incomplete modalities
Mingcheng Li, Dingkang Yang, Xiao Zhao, Shuaibing Wang, Yan Wang, Kun Yang, Mingyang Sun, Dongliang Kou, Ziyun Qian, and Lihua Zhang. Correlation-decoupled knowledge distillation for multimodal sentiment analy- sis with incomplete modalities. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12458–12468, 2024
2024
-
[25]
Dpu: Dynamic prototype updating for multimodal out-of-distribution detection
Shawn Li, Huixian Gong, Hao Dong, Tiankai Yang, Zhengzhong Tu, and Yue Zhao. Dpu: Dynamic prototype updating for multimodal out-of-distribution detection. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 10193–10202, 2025
2025
-
[26]
Decoupled multi- modal distilling for emotion recognition
Yong Li, Yuanzhi Wang, and Zhen Cui. Decoupled multi- modal distilling for emotion recognition. InProceedings of the IEEE/CVF Conference on Computer vision and Pattern Recognition, pages 6631–6640, 2023
2023
-
[27]
Alignmamba: Enhancing multimodal mamba with local and global cross-modal alignment
Yan Li, Yifei Xing, Xiangyuan Lan, Xin Li, Haifeng Chen, and Dongmei Jiang. Alignmamba: Enhancing multimodal mamba with local and global cross-modal alignment. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 24774–24784, 2025
2025
-
[28]
Gcnet: Graph completion network for incomplete mul- timodal learning in conversation.IEEE Transactions on pat- tern analysis and machine intelligence, 45(7):8419–8432, 2023
Zheng Lian, Lan Chen, Licai Sun, Bin Liu, and Jianhua Tao. Gcnet: Graph completion network for incomplete mul- timodal learning in conversation.IEEE Transactions on pat- tern analysis and machine intelligence, 45(7):8419–8432, 2023
2023
-
[29]
Semi-iin: Semi-supervised intra-inter modal interaction learning net- work for multimodal sentiment analysis
Jinhao Lin, Yifei Wang, Yanwu Xu, and Qi Liu. Semi-iin: Semi-supervised intra-inter modal interaction learning net- work for multimodal sentiment analysis. InProceedings of the AAAI Conference on Artificial Intelligence, pages 1411– 1419, 2025
2025
-
[30]
Smil: Multimodal learning with severely missing modality
Mengmeng Ma, Jian Ren, Long Zhao, Sergey Tulyakov, Cathy Wu, and Xi Peng. Smil: Multimodal learning with severely missing modality. InProceedings of the AAAI Con- ference on Artificial Intelligence, pages 2302–2310, 2021
2021
-
[31]
Robust multiview multimodal driver monitoring system using masked multi- head self-attention
Yiming Ma, Victor Sanchez, Soodeh Nikan, Devesh Upad- hyay, Bhushan Atote, and Tanaya Guha. Robust multiview multimodal driver monitoring system using masked multi- head self-attention. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 2617–2625, 2023
2023
-
[32]
Visualizing data using t-sne.Journal of machine learning research, 9: 2579–2605, 2008
Laurens van der Maaten and Geoffrey Hinton. Visualizing data using t-sne.Journal of machine learning research, 9: 2579–2605, 2008
2008
-
[33]
Harnessing frozen unimodal encoders for flexible multimodal alignment
Mayug Maniparambil, Raiymbek Akshulakov, Yasser Ab- delaziz Dahou Djilali, Sanath Narayan, Ankit Singh, and Noel E O’Connor. Harnessing frozen unimodal encoders for flexible multimodal alignment. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 29847–29857, 2025
2025
-
[34]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Repre- sentation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[35]
Balanced multimodal learning via on-the-fly gradient modulation
Xiaokang Peng, Yake Wei, Andong Deng, Dong Wang, and Di Hu. Balanced multimodal learning via on-the-fly gradient modulation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8238–8247, 2022
2022
-
[36]
GloVe: Global vectors for word representation
Jeffrey Pennington, Richard Socher, and Christopher Man- ning. GloVe: Global vectors for word representation. InPro- ceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1532–1543, 2014
2014
-
[37]
Found in translation: Learn- ing robust joint representations by cyclic translations be- tween modalities
Hai Pham, Paul Pu Liang, Thomas Manzini, Louis-Philippe Morency, and Barnab´as P´oczos. Found in translation: Learn- ing robust joint representations by cyclic translations be- tween modalities. InProceedings of the AAAI conference on artificial intelligence, pages 6892–6899, 2019
2019
-
[38]
Convolutional mkl based multimodal emotion recogni- tion and sentiment analysis
Soujanya Poria, Iti Chaturvedi, Erik Cambria, and Amir Hus- sain. Convolutional mkl based multimodal emotion recogni- tion and sentiment analysis. In2016 IEEE 16th international conference on data mining (ICDM), pages 439–448, 2016
2016
-
[39]
Recursive joint cross- modal attention for multimodal fusion in dimensional emo- tion recognition
R Gnana Praveen and Jahangir Alam. Recursive joint cross- modal attention for multimodal fusion in dimensional emo- tion recognition. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, pages 4803–4813, 2024
2024
-
[40]
Multiemo: An attention- based correlation-aware multimodal fusion framework for emotion recognition in conversations
Tao Shi and Shao-Lun Huang. Multiemo: An attention- based correlation-aware multimodal fusion framework for emotion recognition in conversations. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14752–14766, 2023
2023
-
[41]
Cubemlp: An mlp-based model for multimodal sentiment analysis and depression estimation
Hao Sun, Hongyi Wang, Jiaqing Liu, Yen-Wei Chen, and Lanfen Lin. Cubemlp: An mlp-based model for multimodal sentiment analysis and depression estimation. InProceed- ings of the 30th ACM international conference on multime- dia, pages 3722–3729, 2022
2022
-
[42]
A multi-focus-driven multi-branch network for robust multi- modal sentiment analysis
Chuanqi Tao, Jiaming Li, Tianzi Zang, and Peng Gao. A multi-focus-driven multi-branch network for robust multi- modal sentiment analysis. InProceedings of the AAAI Con- ference on Artificial Intelligence, pages 1547–1555, 2025
2025
-
[43]
Enhance modality robustness in text-centric multimodal alignment with adversarial prompting
Yun-Da Tsai, Ting-Yu Yen, Keng-Te Liao, and Shou-De Lin. Enhance modality robustness in text-centric multimodal alignment with adversarial prompting. InProceedings of the AAAI Conference on Artificial Intelligence, pages 27740– 27747, 2025
2025
-
[44]
Multimodal transformer for unaligned multimodal language sequences
Yao-Hung Hubert Tsai, Shaojie Bai, Paul Pu Liang, J Zico Kolter, Louis-Philippe Morency, and Ruslan Salakhutdinov. Multimodal transformer for unaligned multimodal language sequences. InProceedings of the conference. Association for computational linguistics. Meeting, page 6558, 2019
2019
-
[45]
Cross-modal enhancement network for mul- timodal sentiment analysis.IEEE Transactions on Multime- dia, 25:4909–4921, 2022
Di Wang, Shuai Liu, Quan Wang, Yumin Tian, Lihuo He, and Xinbo Gao. Cross-modal enhancement network for mul- timodal sentiment analysis.IEEE Transactions on Multime- dia, 25:4909–4921, 2022
2022
-
[46]
Tetfn: A text enhanced transformer fusion network for multimodal sentiment analysis.Pattern Recog- nition, 136:109259, 2023
Di Wang, Xutong Guo, Yumin Tian, Jinhui Liu, LiHuo He, and Xuemei Luo. Tetfn: A text enhanced transformer fusion network for multimodal sentiment analysis.Pattern Recog- nition, 136:109259, 2023
2023
-
[47]
Refining and synthe- sis: A simple yet effective data augmentation framework for cross-domain aspect-based sentiment analysis
Haining Wang, Kang He, Bobo Li, Lei Chen, Fei Li, Xu Han, Chong Teng, and Donghong Ji. Refining and synthe- sis: A simple yet effective data augmentation framework for cross-domain aspect-based sentiment analysis. InFindings of the Association for Computational Linguistics: ACL 2024, pages 10318–10329, 2024
2024
-
[48]
Dlf: Disentangled-language-focused multi- modal sentiment analysis
Pan Wang, Qiang Zhou, Yawen Wu, Tianlong Chen, and Jingtong Hu. Dlf: Disentangled-language-focused multi- modal sentiment analysis. InProceedings of the AAAI Con- ference on Artificial Intelligence, pages 21180–21188, 2025
2025
-
[49]
What makes train- ing multi-modal classification networks hard? InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12695–12705, 2020
Weiyao Wang, Du Tran, and Matt Feiszli. What makes train- ing multi-modal classification networks hard? InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12695–12705, 2020
2020
-
[50]
Words can shift: Dy- namically adjusting word representations using nonverbal behaviors
Yansen Wang, Ying Shen, Zhun Liu, Paul Pu Liang, Amir Zadeh, and Louis-Philippe Morency. Words can shift: Dy- namically adjusting word representations using nonverbal behaviors. InProceedings of the AAAI conference on arti- ficial intelligence, pages 7216–7223, 2019
2019
-
[51]
Trans- modality: An end2end fusion method with transformer for multimodal sentiment analysis
Zilong Wang, Zhaohong Wan, and Xiaojun Wan. Trans- modality: An end2end fusion method with transformer for multimodal sentiment analysis. InProceedings of the web conference 2020, pages 2514–2520, 2020
2020
-
[52]
Enhancing multimodal sentiment analy- sis for missing modality through self-distillation and unified modality cross-attention
Yuzhe Weng, Haotian Wang, Tian Gao, Kewei Li, Shutong Niu, and Jun Du. Enhancing multimodal sentiment analy- sis for missing modality through self-distillation and unified modality cross-attention. InICASSP 2025-2025 IEEE Inter- national Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP), pages 1–5, 2025
2025
-
[53]
Characterizing and overcoming the greedy nature of learning in multi-modal deep neural net- works
Nan Wu, Stanislaw Jastrzebski, Kyunghyun Cho, and Krzysztof J Geras. Characterizing and overcoming the greedy nature of learning in multi-modal deep neural net- works. InInternational Conference on Machine Learning, pages 24043–24055, 2022
2022
-
[54]
Enriching multimodal sentiment analysis through textual emotional descriptions of visual-audio con- tent
Sheng Wu, Dongxiao He, Xiaobao Wang, Longbiao Wang, and Jianwu Dang. Enriching multimodal sentiment analysis through textual emotional descriptions of visual-audio con- tent. InProceedings of the AAAI Conference on Artificial Intelligence, pages 1601–1609, 2025
2025
-
[55]
Towards multi- modal sentiment analysis via hierarchical correlation model- ing with semantic distribution constraints
Qinfu Xu, Yiwei Wei, Chunlei Wu, Leiquan Wang, Shaozu Yuan, Jie Wu, Jing Lu, and Hengyang Zhou. Towards multi- modal sentiment analysis via hierarchical correlation model- ing with semantic distribution constraints. InProceedings of the AAAI Conference on Artificial Intelligence, pages 21788– 21796, 2025
2025
-
[56]
Confede: Contrastive feature decomposition for multimodal sentiment analysis
Jiuding Yang, Yakun Yu, Di Niu, Weidong Guo, and Yu Xu. Confede: Contrastive feature decomposition for multimodal sentiment analysis. InProceedings of the 61st Annual Meet- ing of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7617–7630, 2023
2023
-
[57]
Clgsi: a mul- timodal sentiment analysis framework based on contrastive learning guided by sentiment intensity
Yang Yang, Xunde Dong, and Yupeng Qiang. Clgsi: a mul- timodal sentiment analysis framework based on contrastive learning guided by sentiment intensity. InFindings of the Association for Computational Linguistics: NAACL 2024, pages 2099–2110, 2024
2024
-
[58]
Adapting bert for target-oriented multimodal sentiment classification
Jianfei Yu and Jing Jiang. Adapting bert for target-oriented multimodal sentiment classification. InProceedings of the 28th International Joint Conference on Artificial Intelli- gence, 2019
2019
-
[59]
Learning modality-specific representations with self-supervised multi- task learning for multimodal sentiment analysis
Wenmeng Yu, Hua Xu, Ziqi Yuan, and Jiele Wu. Learning modality-specific representations with self-supervised multi- task learning for multimodal sentiment analysis. InProceed- ings of the AAAI conference on artificial intelligence, pages 10790–10797, 2021
2021
-
[60]
Conki: Contrastive knowledge injection for multimodal sen- timent analysis
Yakun Yu, Mingjun Zhao, Shi-ang Qi, Feiran Sun, Baoxun Wang, Weidong Guo, Xiaoli Wang, Lei Yang, and Di Niu. Conki: Contrastive knowledge injection for multimodal sen- timent analysis. InFindings of the Association for Computa- tional Linguistics: ACL 2023, pages 13610–13624, 2023
2023
-
[61]
Transformer- based feature reconstruction network for robust multimodal sentiment analysis
Ziqi Yuan, Wei Li, Hua Xu, and Wenmeng Yu. Transformer- based feature reconstruction network for robust multimodal sentiment analysis. InProceedings of the 29th ACM interna- tional conference on multimedia, pages 4400–4407, 2021
2021
-
[62]
Mosi: multimodal corpus of sentiment intensity and subjectivity analysis in online opinion videos,
Amir Zadeh, Rowan Zellers, Eli Pincus, and Louis-Philippe Morency. Mosi: multimodal corpus of sentiment intensity and subjectivity analysis in online opinion videos.arXiv preprint arXiv:1606.06259, 2016
-
[63]
Chinese Men- talBERT: Domain-adaptive pre-training on social media for Chinese mental health text analysis
Wei Zhai, Hongzhi Qi, Qing Zhao, Jianqiang Li, Ziqi Wang, Han Wang, Bing Yang, and Guanghui Fu. Chinese Men- talBERT: Domain-adaptive pre-training on social media for Chinese mental health text analysis. InFindings of the As- sociation for Computational Linguistics: ACL 2024, pages 10574–10585, 2024
2024
-
[64]
arXiv preprint arXiv:2310.05804 , year=
Haoyu Zhang, Yu Wang, Guanghao Yin, Kejun Liu, Yuanyuan Liu, and Tianshu Yu. Learning language-guided adaptive hyper-modality representation for multimodal sen- timent analysis.arXiv preprint arXiv:2310.05804, 2023
-
[65]
Towards ro- bust multimodal sentiment analysis with incomplete data
Haoyu Zhang, Wenbin Wang, and Tianshu Yu. Towards ro- bust multimodal sentiment analysis with incomplete data. Advances in Neural Information Processing Systems, 37: 55943–55974, 2024
2024
-
[66]
Ecerc: evidence-cause atten- tion network for multi-modal emotion recognition in conver- sation
Tao Zhang and Zhenhua Tan. Ecerc: evidence-cause atten- tion network for multi-modal emotion recognition in conver- sation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2064–2077, 2025
2064
-
[67]
ESCoT: Towards interpretable emotional support di- alogue systems
Tenggan Zhang, Xinjie Zhang, Jinming Zhao, Li Zhou, and Qin Jin. ESCoT: Towards interpretable emotional support di- alogue systems. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13395–13412, 2024
2024
-
[68]
Modal feature optimization network with prompt for multimodal sentiment analysis
Xiangmin Zhang, Wei Wei, and Shihao Zou. Modal feature optimization network with prompt for multimodal sentiment analysis. InProceedings of the 31st International Confer- ence on Computational Linguistics, pages 4611–4621, 2025
2025
-
[69]
Glomo: Global-local modal fusion for multimodal sentiment analysis
Yan Zhuang, Yanru Zhang, Zheng Hu, Xiaoyue Zhang, Ji- awen Deng, and Fuji Ren. Glomo: Global-local modal fusion for multimodal sentiment analysis. InProceedings of the 32nd ACM International Conference on Multimedia, pages 1800–1809, 2024. Enhance-then-Balance Modality Collaboration for Robust Multimodal Sentiment Analysis Supplementary Material A. Experi...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.