Recognition: unknown
CoD-Lite: Real-Time Diffusion-Based Generative Image Compression
Pith reviewed 2026-05-10 15:03 UTC · model grok-4.3
The pith
Lightweight convolutions and compression-oriented pre-training enable real-time diffusion codecs for image compression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
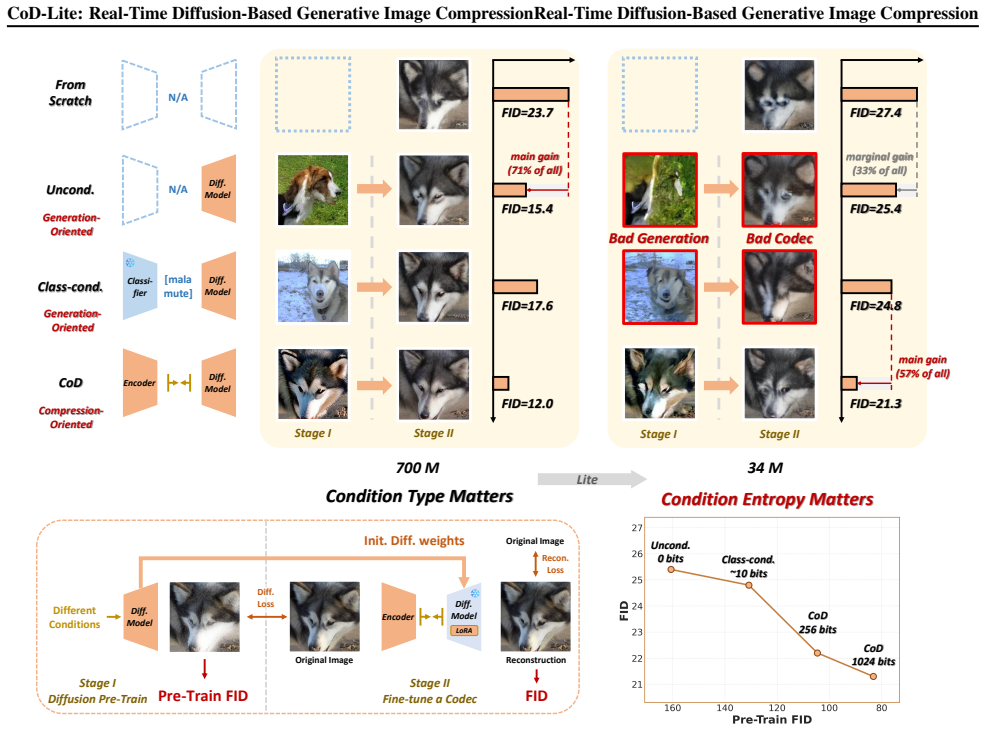
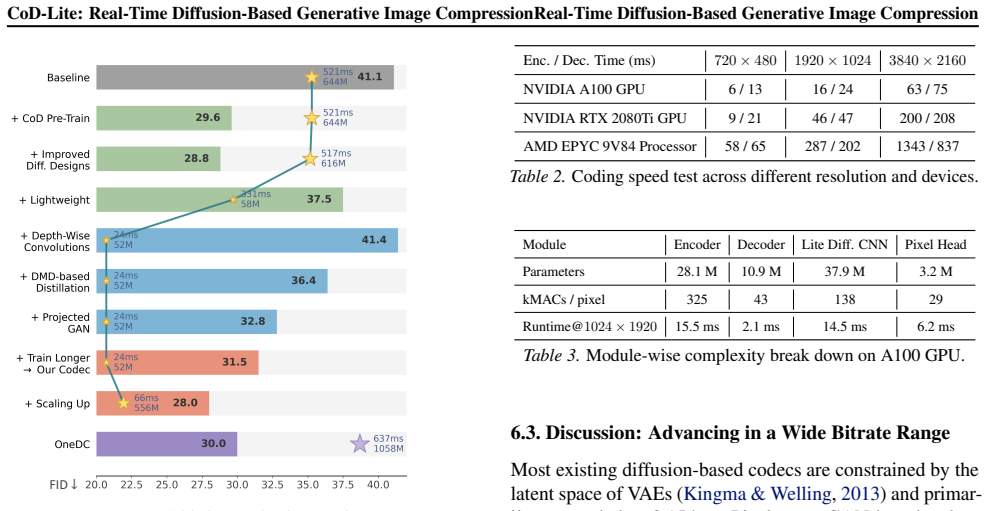
The authors establish that for lightweight diffusion codecs, compression-oriented pre-training outperforms generation-oriented pre-training at small scales, and lightweight convolutions suffice for compression when combined with distillation. This combination supports a one-step diffusion codec that delivers real-time performance at 1080p resolution while achieving lower bitrates at comparable perceptual quality.
What carries the argument
The one-step lightweight convolution diffusion codec, built on compression-oriented pre-training and distillation to replace global attention.
If this is right
- Real-time generative image compression at 1080p resolution becomes feasible without large transformer models.
- Bitrate requirements drop substantially while perceptual quality stays comparable to heavier generative methods.
- Small-scale diffusion models can be deployed in latency-sensitive applications such as live streaming or mobile capture.
- Architecture scaling alone is not required when the pre-training objective matches the compression task.
Where Pith is reading between the lines
- The same pre-training and convolution pattern could extend to video or 3D data where frame rates matter.
- Task-specific pre-training may reduce the data and compute needed to train efficient generative models in other constrained domains.
- Edge hardware could incorporate these codecs once the one-step inference is further optimized for lower power.
Load-bearing premise
The performance gains from compression-oriented pre-training and lightweight convolutions with distillation will hold for the tested model scales and datasets without further adjustments that change the reported outcomes.
What would settle it
Running the same lightweight model on a new dataset or without the compression pre-training and distillation steps, and observing that it no longer meets real-time speeds or achieves the bitrate savings at matching image quality.
Figures









read the original abstract
Recent advanced diffusion methods typically derive strong generative priors by scaling diffusion transformers. However, scaling fails to generalize when adapted for real-time compression scenarios that demand lightweight models. In this paper, we explore the design of real-time and lightweight diffusion codecs by addressing two pivotal questions. First, does diffusion pre-training benefit lightweight diffusion codecs? Through systematic analysis, we find that generation-oriented pre-training is less effective at small model scales whereas compression-oriented pre-training yields consistently better performance. Second, are transformers essential? We find that while global attention is crucial for standard generation, lightweight convolutions suffice for compression-oriented diffusion when paired with distillation. Guided by these findings, we establish a one-step lightweight convolution diffusion codec that achieves real-time $60$~FPS encoding and $42$~FPS decoding at 1080p. Further enhanced by distillation and adversarial learning, the proposed codec reduces bitrate by 85\% at a comparable FID to MS-ILLM, bridging the gap between generative compression and practical real-time deployment. Codes are released at https://github.com/microsoft/GenCodec/tree/main/CoD_Lite
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CoD-Lite, a one-step lightweight convolutional diffusion codec for real-time generative image compression. It claims that compression-oriented pre-training outperforms generation-oriented pre-training at small model scales, that lightweight convolutions plus distillation suffice in place of global attention, and that the resulting model achieves 60 FPS encoding and 42 FPS decoding at 1080p while reducing bitrate by 85% at comparable FID to MS-ILLM.
Significance. If the empirical findings on pre-training objectives and architecture substitutions are robust across scales and datasets, the work would meaningfully advance practical deployment of generative compression by demonstrating real-time viability without heavy transformers. The public code release supports reproducibility and is a clear strength.
major comments (2)
- [Abstract and §3] Abstract and §3 (pre-training analysis): the headline claim that compression-oriented pre-training is superior at small scales while generation-oriented pre-training is less effective rests on an unspecified 'systematic analysis.' No ablation tables, loss formulations, model-scale definitions, or dataset details are referenced, preventing verification that the 85% bitrate reduction is not an artifact of post-hoc choices.
- [Abstract and §4] Abstract and §4 (architecture and distillation): the assertion that lightweight convolutions with distillation can replace global attention without loss of the reported rate-distortion point is load-bearing for the real-time FPS and bitrate claims. No equations for the distillation objective, no comparison of attention vs. convolution operating points, and no error analysis are supplied to isolate this substitution from hyperparameter tuning.
minor comments (2)
- [Abstract] Abstract: the FPS figures (60 encoding, 42 decoding at 1080p) should be accompanied by hardware specifications and batch-size details for reproducibility.
- [Abstract] The GitHub link is welcome; ensure the released code includes the exact pre-training schedules, distillation hyperparameters, and evaluation scripts that produced the MS-ILLM comparison numbers.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and constructive feedback on our manuscript. We address the major comments point by point below, providing clarifications and committing to revisions where appropriate to improve the clarity and verifiability of our results.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (pre-training analysis): the headline claim that compression-oriented pre-training is superior at small scales while generation-oriented pre-training is less effective rests on an unspecified 'systematic analysis.' No ablation tables, loss formulations, model-scale definitions, or dataset details are referenced, preventing verification that the 85% bitrate reduction is not an artifact of post-hoc choices.
Authors: We appreciate the referee's point regarding the need for greater detail in our pre-training analysis. The systematic analysis is conducted in Section 3, where we compare different pre-training strategies at varying model scales. To address this concern, we will revise the manuscript to include comprehensive ablation tables, the exact loss formulations used for compression-oriented and generation-oriented pre-training, clear definitions of the model scales employed, and specifics on the datasets used. These additions will enable readers to verify that the reported performance improvements, including the substantial bitrate reductions, stem from the pre-training approach rather than post-hoc adjustments. revision: yes
-
Referee: [Abstract and §4] Abstract and §4 (architecture and distillation): the assertion that lightweight convolutions with distillation can replace global attention without loss of the reported rate-distortion point is load-bearing for the real-time FPS and bitrate claims. No equations for the distillation objective, no comparison of attention vs. convolution operating points, and no error analysis are supplied to isolate this substitution from hyperparameter tuning.
Authors: Thank you for this comment. We agree that providing more details on the architecture substitution and distillation process is essential. In the revised version, we will include the equations for the distillation objective, direct comparisons between attention-based and convolution-based models at equivalent operating points, and an error analysis to demonstrate that the performance is maintained without reliance on extensive hyperparameter tuning. This will better support the claims regarding real-time performance and bitrate savings. revision: yes
Circularity Check
No significant circularity; claims rest on empirical analysis
full rationale
The paper's derivation chain consists of two empirical findings obtained via 'systematic analysis' (generation-oriented pre-training inferior at small scales; lightweight convolutions sufficient with distillation) followed by construction of a one-step codec whose reported metrics (60 FPS encoding, 85% bitrate reduction at comparable FID) are presented as experimental outcomes. No equations, loss functions, or parameter-fitting steps are shown that would make any prediction equivalent to its inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems, and no ansatz is smuggled via prior work. The central performance numbers are therefore not forced reductions of the inputs but reported results from the described experiments.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Diffusion models can be trained for image compression tasks
Reference graph
Works this paper leans on
-
[1]
and Timofte, R
Agustsson, E. and Timofte, R. Ntire 2017 challenge on single image super-resolution: Dataset and study. In Proceedings of the IEEE conference on computer vision and pattern recognition workshops, pp. 126–135,
2017
-
[2]
Ball´e, J., Laparra, V ., and Simoncelli, E
URL https://openreview.net/forum? id=UnslcaZSnb. Ball´e, J., Laparra, V ., and Simoncelli, E. P. End-to-end optimized image compression. In5th International Con- ference on Learning Representations, ICLR 2017,
2017
-
[3]
arXiv preprint arXiv:1803.07422 (2018) 10
Demir, U. and Unal, G. Patch-based image inpainting with generative adversarial networks.arXiv preprint arXiv:1803.07422,
-
[4]
TinySR: Pruning Diffusion for Real-World Image Super-Resolution
Dong, L., Fan, Q., Yu, Y ., Zhang, Q., Chen, J., Luo, Y ., and Zou, C. Tinysr: Pruning diffusion for real-world image super-resolution.arXiv preprint arXiv:2508.17434,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Elata, N., Michaeli, T., and Elad, M
Accessed: 2025-11-08. Elata, N., Michaeli, T., and Elad, M. PSC: Posterior sampling-based compression. In15th International Con- ference on Sampling Theory and Applications,
2025
-
[6]
Oscar: One-step diffusion codec across multiple bit-rates.arXiv preprint arXiv:2505.16091,
Guo, J., Ji, Y ., Chen, Z., Liu, K., Liu, M., Rao, W., Li, W., Guo, Y ., and Zhang, Y . Oscar: One-step diffu- sion codec across multiple bit-rates.arXiv preprint arXiv:2505.16091,
-
[7]
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine
Jia, Z., Li, B., Li, J., Xie, W., Qi, L., Li, H., and Lu, Y . Towards practical real-time neural video compression. In Proceedings of the Computer Vision and Pattern Recog- nition Conference, pp. 12543–12552, 2025a. Jia, Z., Zheng, Z., Xue, N., Li, J., Li, B., Guo, Z., Zhang, X., Li, H., and Lu, Y . Cod: A diffusion foundation model for image compression....
-
[8]
Kuznetsova, A., Rom, H., Alldrin, N., Uijlings, J., Krasin, I., Pont-Tuset, J., Kamali, S., Popov, S., Malloci, M., Kolesnikov, A., et al. The open images dataset v4: Uni- fied image classification, object detection, and visual re- lationship detection at scale.International journal of computer vision, 128(7):1956–1981,
1956
-
[9]
B., Hassani, H., and Bidokhti, S
Lei, E., Uslu, Y . B., Hassani, H., and Bidokhti, S. S. Text + sketch: Image compression at ultra low rates. InICML 2023 Workshop Neural Compression: From Information Theory to Applications,
2023
-
[10]
Back to Basics: Let Denoising Generative Models Denoise
Li, T. and He, K. Back to basics: Let denoising generative models denoise.arXiv preprint arXiv:2511.13720,
work page internal anchor Pith review arXiv
-
[11]
DeCo: Frequency-Decoupled Pixel Diffusion for End-to-End Image Generation
URL https://arxiv.org/ abs/2511.19365. Mentzer, F., Toderici, G. D., Tschannen, M., and Agusts- son, E. High-fidelity generative image compression.Ad- vances in neural information processing systems, 33: 11913–11924,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Progressive Distillation for Fast Sampling of Diffusion Models
Salimans, T. and Ho, J. Progressive distillation for fast sampling of diffusion models.arXiv preprint arXiv:2202.00512,
work page internal anchor Pith review arXiv
-
[13]
Amit Vaisman, Guy Ohayon, Hila Manor, Michael Elad, and Tomer Michaeli
Accessed: 2025- 11-14. Theis, L., Salimans, T., Hoffman, M. D., and Mentzer, F. Lossy compression with gaussian diffusion.arXiv preprint arXiv:2206.08889,
-
[14]
Clic 2020: Challenge on learned image compression.Re- trieved March, 29:2021,
Toderici, G., Theis, L., Johnston, N., Agustsson, E., Mentzer, F., Ball ´e, J., Shi, W., and Timofte, R. Clic 2020: Challenge on learned image compression.Re- trieved March, 29:2021,
2020
-
[15]
Pixnerd: Pixel neural field diffusion.arXiv preprint arXiv:2507.23268,
Wang, S., Gao, Z., Zhu, C., Huang, W., and Wang, L. Pixnerd: Pixel neural field diffusion.arXiv preprint arXiv:2507.23268, 2025a. Wang, S., Tian, Z., Huang, W., and Wang, L. Ddt: Decoupled diffusion transformer.arXiv preprint arXiv:2504.05741, 2025b. Xu, T., Zhu, Z., He, D., Li, Y ., Guo, L., Wang, Y ., Wang, Z., Qin, H., Wang, Y ., Liu, J., and Zhang, Y ...
-
[16]
Evaluation Protocol.We construct an evaluation set of 1,000 images by randomly selecting one image per class from the ImageNet validation set
With a batch size of 16 and learning rate of 10−4, we first train with L1 and LPIPS losses for 200k steps, then incorporate PatchGAN adversarial loss for an additional100k steps. Evaluation Protocol.We construct an evaluation set of 1,000 images by randomly selecting one image per class from the ImageNet validation set. As shown in Figure 2, we report two...
2020
-
[17]
The results confirm that attention mass is heavily concentrated at short distances
presents quantitative analysis of attention patterns: Sub-figure (a):We aggregate attention scores across all point-pairs, blocks, and heads at timestep 0.5T , computing the weighted attention mass at each spatial distance. The results confirm that attention mass is heavily concentrated at short distances. Sub-figure (b):We select the top- K% attention sc...
-
[18]
The complete pre-training pipeline requires 284 A100 GPU hours, while fine-tuning at each target bitrate requires an additional 244 A100 GPU hours. B. More Experimental Results This section presents additional experimental results that complement the main paper, including extended rate- distortion/perception curves, high-resolution fine-tuning ex- perimen...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.