Recognition: unknown
A Two-Stage LLM Framework for Accessible and Verified XAI Explanations
Pith reviewed 2026-05-10 15:22 UTC · model grok-4.3
The pith
A second LLM can verify and refine natural-language XAI explanations to filter errors and improve accessibility.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
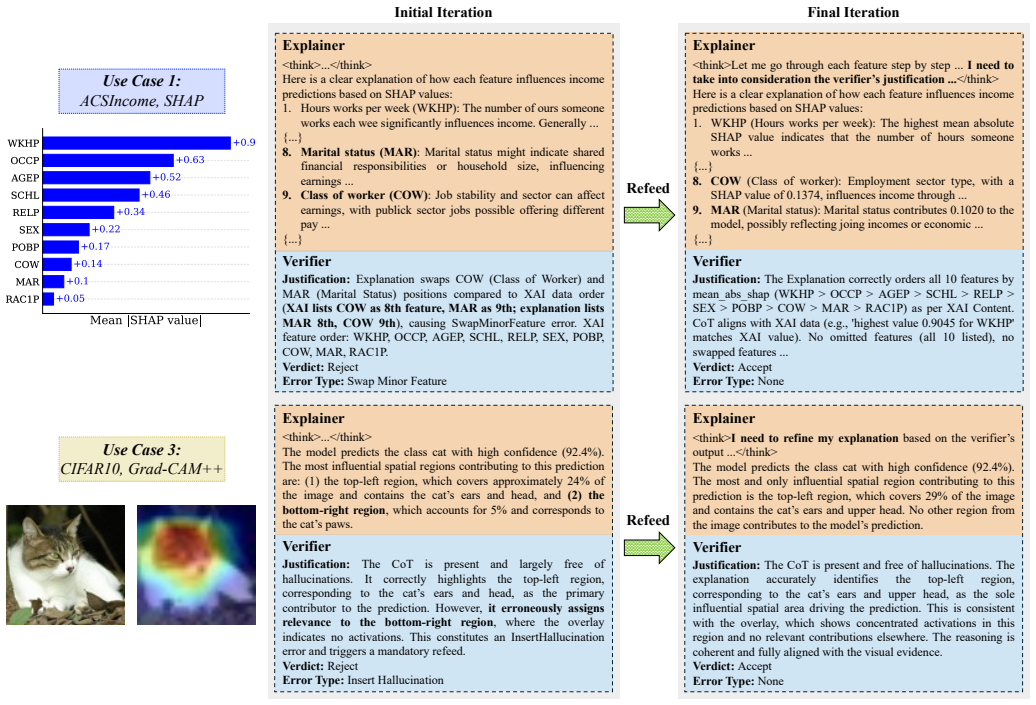
The two-stage LLM meta-verification framework consists of an Explainer LLM that translates raw XAI outputs into natural-language narratives, a Verifier LLM that assesses those narratives for faithfulness, coherence, completeness, and hallucination risk, and an iterative refeed mechanism that uses the verifier's feedback to refine the explainer's output. Experiments across five XAI techniques and datasets using three families of open-weight LLMs demonstrate that verification is crucial for filtering unreliable explanations while improving linguistic accessibility compared with raw XAI outputs. Analysis of the entropy production rate during the refinement process shows that the verifier's反馈pro
What carries the argument
The Verifier LLM, which assesses the Explainer LLM's natural-language output on faithfulness, coherence, completeness, and hallucination risk to enable iterative refinement via refeed.
If this is right
- Verification filters out unreliable explanations before they reach end-users.
- Natural-language XAI outputs become more linguistically accessible than direct translations.
- The iterative refinement process progressively stabilizes explanations as shown by decreasing entropy production rate.
- The overall approach supplies an efficient route to more trustworthy and democratized XAI systems.
Where Pith is reading between the lines
- The same verifier-refinement loop could be tested on explanations for other AI systems such as medical diagnosis models or autonomous vehicle decisions.
- Direct comparison of verified versus unverified explanations in user studies would measure whether end-users actually perceive higher trustworthiness.
- If the refinement converges quickly, the framework might lower total compute cost relative to generating many independent LLM explanations.
Load-bearing premise
The Verifier LLM can accurately and consistently detect faithfulness issues, incompleteness, and hallucination risk in the Explainer's output without introducing its own systematic errors or biases.
What would settle it
A controlled test set of XAI outputs with known hallucinations or omissions where the verifier consistently fails to flag them or where the refined explanations contain more errors than the original unverified versions.
Figures






read the original abstract
Large Language Models (LLMs) are increasingly used to translate the technical outputs of eXplainable Artificial Intelligence (XAI) methods into accessible natural-language explanations. However, existing approaches often lack guarantees of accuracy, faithfulness, and completeness. At the same time, current efforts to evaluate such narratives remain largely subjective or confined to post-hoc scoring, offering no safeguards to prevent flawed explanations from reaching end-users. To address these limitations, this paper proposes a Two-Stage LLM Meta-Verification Framework that consists of (i) an Explainer LLM that converts raw XAI outputs into natural-language narratives, (ii) a Verifier LLM that assesses them in terms of faithfulness, coherence, completeness, and hallucination risk, and (iii) an iterative refeed mechanism that uses the Verifier's feedback to refine and improve them. Experiments across five XAI techniques and datasets, using three families of open-weight LLMs, show that verification is crucial for filtering unreliable explanations while improving linguistic accessibility compared with raw XAI outputs. In addition, the analysis of the Entropy Production Rate (EPR) during the refinement process indicates that the Verifier's feedback progressively guides the Explainer toward more stable and coherent reasoning. Overall, the proposed framework provides an efficient pathway toward more trustworthy and democratized XAI systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a Two-Stage LLM Meta-Verification Framework for XAI explanations: an Explainer LLM converts raw XAI outputs into natural-language narratives; a Verifier LLM evaluates them for faithfulness, coherence, completeness, and hallucination risk; and an iterative refeed mechanism refines outputs based on verifier feedback. Experiments across five XAI techniques and datasets with three families of open-weight LLMs claim that verification filters unreliable explanations and improves linguistic accessibility over raw XAI outputs, with Entropy Production Rate (EPR) analysis indicating progressive stabilization of reasoning during refinement.
Significance. If the empirical results hold under independent validation, the framework would provide a scalable, LLM-based pathway to make XAI outputs more accessible and trustworthy for non-expert users, directly addressing the gap between technical XAI methods and usable explanations. The EPR analysis introduces a novel dynamical-systems lens on iterative LLM refinement that could generalize beyond this setting.
major comments (3)
- [Experiments] Experiments section (and abstract): the central claim that 'verification is crucial for filtering unreliable explanations' rests on Verifier LLM judgments of faithfulness, completeness, and hallucination risk, yet no external anchor—human ratings, inter-rater agreement, or task-specific accuracy against known XAI ground truth—is reported. Improvements are shown only relative to raw XAI outputs and EPR trends, both of which can be satisfied by consistent but systematically biased LLM behavior.
- [Framework and EPR analysis] Section describing the framework and EPR analysis: the abstract states that EPR 'indicates that the Verifier's feedback progressively guides the Explainer toward more stable and coherent reasoning,' but provides neither the explicit formula for EPR, the precise computation from token probabilities or attention patterns, nor any statistical test linking EPR reduction to explanation quality. Without these, the EPR result cannot be reproduced or falsified.
- [Evaluation] Evaluation protocol: the manuscript reports positive results across five XAI techniques, datasets, and three LLM families but omits exact metrics (e.g., how accessibility or faithfulness is scored), chosen baselines, and any statistical significance tests. This prevents assessment of effect sizes and robustness of the 'improved accessibility' claim.
minor comments (2)
- [Methods] Notation for EPR and the iterative refeed loop should be defined with explicit equations or pseudocode in the methods section to allow replication.
- [Discussion] The paper should include a limitations subsection discussing potential biases introduced by the choice of open-weight LLMs and the risk of verifier-exploiter collusion.
Simulated Author's Rebuttal
We appreciate the referee's thorough review and valuable feedback on our manuscript. We address each major comment below, providing clarifications and indicating revisions where necessary to strengthen the paper.
read point-by-point responses
-
Referee: [Experiments] Experiments section (and abstract): the central claim that 'verification is crucial for filtering unreliable explanations' rests on Verifier LLM judgments of faithfulness, completeness, and hallucination risk, yet no external anchor—human ratings, inter-rater agreement, or task-specific accuracy against known XAI ground truth—is reported. Improvements are shown only relative to raw XAI outputs and EPR trends, both of which can be satisfied by consistent but systematically biased LLM behavior.
Authors: We acknowledge the importance of external validation for the verifier's judgments. Our experiments demonstrate consistent improvements in accessibility and faithfulness metrics across diverse XAI techniques and LLM families, with the iterative process showing progressive refinement. However, we agree that LLM self-evaluation can be subject to bias. In the revision, we will add a dedicated limitations section discussing this and outline plans for human evaluation studies in future work. The current results provide initial evidence of the framework's utility. revision: partial
-
Referee: [Framework and EPR analysis] Section describing the framework and EPR analysis: the abstract states that EPR 'indicates that the Verifier's feedback progressively guides the Explainer toward more stable and coherent reasoning,' but provides neither the explicit formula for EPR, the precise computation from token probabilities or attention patterns, nor any statistical test linking EPR reduction to explanation quality. Without these, the EPR result cannot be reproduced or falsified.
Authors: We apologize for the omission of the EPR details in the manuscript. The Entropy Production Rate is computed based on the divergence in token probability distributions between consecutive iterations, specifically using the Kullback-Leibler divergence normalized by sequence length to measure reasoning stabilization. We will include the full mathematical formulation, computation method from the model's output probabilities, and statistical tests (e.g., paired t-tests on EPR trends) in the revised manuscript to ensure reproducibility. revision: yes
-
Referee: [Evaluation] Evaluation protocol: the manuscript reports positive results across five XAI techniques, datasets, and three LLM families but omits exact metrics (e.g., how accessibility or faithfulness is scored), chosen baselines, and any statistical significance tests. This prevents assessment of effect sizes and robustness of the 'improved accessibility' claim.
Authors: We will revise the Evaluation section to explicitly define all metrics used for accessibility (e.g., readability scores like Flesch-Kincaid) and faithfulness (based on verifier criteria), specify the baselines (raw XAI outputs and non-iterative LLM explanations), and include statistical significance tests such as ANOVA or Wilcoxon tests with p-values and effect sizes to support the claims. revision: yes
Circularity Check
Empirical framework evaluated on external XAI methods and datasets; no load-bearing circularity in derivation chain
full rationale
The paper proposes a two-stage LLM framework (Explainer + Verifier with refeed) and supports its claims via experiments on five XAI techniques, multiple datasets, and three LLM families. Improvements are reported relative to raw XAI outputs, with EPR serving only as a post-hoc analysis metric for coherence trends rather than a fitted input or definitional parameter. No self-definitional equations, predictions that reduce to fitted values by construction, or load-bearing self-citations appear in the abstract or described structure. The core contribution remains an empirical demonstration against external benchmarks, consistent with a low circularity finding.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs can produce coherent natural-language translations of technical XAI outputs
- domain assumption A separate LLM instance can reliably judge faithfulness, coherence, completeness, and hallucination risk
Reference graph
Works this paper leans on
-
[1]
Explainable artificial intelligence: A survey of needs, techniques, applications, and future direction,
M. Mersha, K. Lam, J. Wood, A. K. AlShami, and J. Kalita, “Explainable artificial intelligence: A survey of needs, techniques, applications, and future direction,”Neurocomputing, vol. 599, p. 128111, Sep. 2024
2024
-
[2]
A unified approach to interpreting model predictions,
S. M. Lundberg and S.-I. Lee, “A unified approach to interpreting model predictions,” inProc. 31st Conf. Neural Inf. Process. Syst. (NeurIPS), 2017, pp. 4768–4777
2017
-
[3]
Grad-cam: Visual explanations from deep networks via gradient-based localization,
R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra, “Grad-cam: Visual explanations from deep networks via gradient-based localization,” inProc. IEEE Int. Conf. Comput. Vis. (ICCV), Oct. 2017, pp. 618–626
2017
-
[4]
Backpropagation-based counterfactual explanations for quasi-nonlinear fuzzy cognitive maps,
M. Tyrovolas, G. Nápoles, and C. Stylios, “Backpropagation-based counterfactual explanations for quasi-nonlinear fuzzy cognitive maps,” IEEE Trans. Syst., Man, Cybern.: Syst., vol. 56, no. 3, pp. 1706–1720, Mar. 2026
2026
-
[5]
Counterfactual explanations without opening the black box: Automated decisions and the GDPR,
S. Wachter, B. Mittelstadt, and C. Russell, “Counterfactual explanations without opening the black box: Automated decisions and the GDPR,” Harvard J. Law Technol., vol. 31, no. 2, pp. 841–887, 2018
2018
-
[6]
LLMs for XAI: Future directions for explaining explanations,
A. Zytek, S. Pidò, and K. Veeramachaneni, “LLMs for XAI: Future directions for explaining explanations,” 2024,arXiv:2405.06064
-
[7]
A survey on explainable AI narratives based on large language models,
M. Silvestri, V . Vineis, E. Gabrielli, F. Giorgi, F. Veglianti, F. Silvestri, and G. Tolomei, “A survey on explainable AI narratives based on large language models,”TechRxiv, Nov. 2025
2025
-
[8]
XAI for all: Can large language models simplify explainable AI?
P. Mavrepiset al., “XAI for all: Can large language models simplify explainable AI?”Comput. Sci. Inf. Technol., vol. 14, no. 22, p. 127, 2024
2024
-
[9]
Using LLMs to explain AI-generated art classification via grad-cam heatmaps,
G. Castellano, M. G. Miccoli, R. Scaringi, G. Vessio, and G. Zaza, “Using LLMs to explain AI-generated art classification via grad-cam heatmaps,” inProc. 5th Italian Workshop on Explainable Artificial Intelligence (XAI.it), ser. CEUR Workshop Proceedings, vol. 3839, 2024, pp. 65–74. [Online]. Available: https://ceur-ws.org/V ol-3839/paper5.pdf
2024
-
[10]
Enhancing the interpretability of SHAP values using large language models,
X. Zeng, “Enhancing the interpretability of SHAP values using large language models,” 2024,arXiv:2409.00079
-
[11]
Why Language Models Hallucinate
A. T. Kalai, O. Nachum, S. S. Vempala, and E. Zhang, “Why language models hallucinate,” 2025,arXiv:2509.04664
work page internal anchor Pith review arXiv 2025
-
[12]
Augmenting XAI with LLMs: A case study in banking marketing recommendation,
A. Castelnovoet al., “Augmenting XAI with LLMs: A case study in banking marketing recommendation,” inExplainable Artificial Intel- ligence, ser. Communications in Computer and Information Science. Cham: Springer, 2024, pp. 211–229
2024
-
[13]
N. Shirvani-Mahdavi and C. Li, “Rule2Text: A framework for generating and evaluating natural language explanations of knowledge graph rules,” 2025,arXiv:2508.10971
-
[14]
How good is my story? towards quantitative metrics for evaluating LLM-generated XAI narratives,
T. Ichmoukhamedov, J. Hinns, and D. Martens, “How good is my story? towards quantitative metrics for evaluating LLM-generated XAI narratives,” 2024,arXiv:2412.10220
-
[15]
Large language models are zero-shot reasoners,
T. Kojima, S. S. Gu, M. Reid, Y . Matsuo, and Y . Iwasawa, “Large language models are zero-shot reasoners,” inProc. 36th Conf. Neural Inf. Process. Syst. (NeurIPS), 2022
2022
-
[16]
Language models are few-shot learners,
T. B. Brownet al., “Language models are few-shot learners,” inProc. 34th Conf. Neural Inf. Process. Syst. (NeurIPS), 2020
2020
-
[17]
Meta prompting for agi systems,
Y . Zhang, Y . Yuan, and A. C.-C. Yao, “Meta prompting for AI systems,” 2023,arXiv:2311.11482
-
[18]
Retiring adult: New datasets for fair machine learning,
F. Ding, M. Hardt, J. Miller, and L. Schmidt, “Retiring adult: New datasets for fair machine learning,” inProc. 35th Conf. Neural Inf. Process. Syst. (NeurIPS), 2021
2021
-
[19]
gpt-oss-120b & gpt-oss-20b Model Card
S. Agarwalet al., “gpt-oss-120b & gpt-oss-20b Model Card,” 2025, arXiv:2508.10925
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Deepseek-r1 incentivizes reasoning in LLMs through reinforcement learning,
D. Guoet al., “Deepseek-r1 incentivizes reasoning in LLMs through reinforcement learning,”Nature, vol. 645, pp. 633–638, 2025
2025
-
[21]
A. Yanget al., “Qwen3 Technical Report,” 2025,arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
A readability formula that saves time,
J. P. Kincaid, R. P. Fishburne, R. L. Rogers, and B. S. Chissom, “A readability formula that saves time,” Naval Air Station Memphis, Tech. Rep. Research Branch Report 8-75, 1975
1975
-
[23]
Learned hallucination detection in black-box LLMs using token-level entropy production rate,
C. Moslonkaet al., “Learned hallucination detection in black-box LLMs using token-level entropy production rate,” 2025,arXiv:2509.04492
-
[24]
Llm evaluators recognize and favor their own generations,
A. Panickssery, S. R. Bowman, and S. Feng, “Llm evaluators recognize and favor their own generations,” inProc. 38th Conf. Neural Inf. Process. Syst. (NeurIPS), 2024, p. 2197
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.