Recognition: unknown
IDEA: An Interpretable and Editable Decision-Making Framework for LLMs via Verbal-to-Numeric Calibration
Pith reviewed 2026-05-10 15:12 UTC · model grok-4.3
The pith
IDEA extracts LLM decision knowledge into an interpretable parametric model over factors to deliver exact calibration and editable human-AI collaboration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
IDEA extracts LLM decision knowledge into an interpretable parametric model over semantically meaningful factors. Through joint learning of verbal-to-numerical mappings and decision parameters via EM, correlated sampling that preserves factor dependencies, and direct parameter editing with mathematical guarantees, IDEA produces calibrated probabilities while enabling quantitative human-AI collaboration.
What carries the argument
Parametric model over semantically meaningful factors, with verbal-to-numeric mappings and decision weights learned jointly via EM and supported by correlated sampling.
If this is right
- Exact calibration of decision probabilities that prompting alone cannot achieve.
- Perfect exclusion of any chosen factor while leaving others unchanged.
- Direct, mathematically guaranteed editing of parameters to incorporate expert knowledge.
- Superior accuracy on decision benchmarks compared with DeepSeek R1 and GPT-5.2 when using the same base model.
- Quantitative human-AI collaboration through readable and adjustable factors.
Where Pith is reading between the lines
- The approach may allow domain experts to impose hard constraints on specific factors without retraining the underlying LLM.
- Low-dimensional factor spaces could compress LLM decision logic for deployment in resource-limited settings.
- The same verbal-to-numeric calibration technique might apply to multi-step planning or sequential decision tasks.
Load-bearing premise
LLM decision knowledge can be fully and accurately captured by a parametric model over semantically meaningful factors without significant loss or distortion of the original reasoning.
What would settle it
A new dataset where the extracted parametric model's probability outputs deviate from the original LLM's decisions or where editing a single parameter fails to produce the mathematically predicted change in calibrated probabilities.
Figures







read the original abstract
Large Language Models are increasingly deployed for decision-making, yet their adoption in high-stakes domains remains limited by miscalibrated probabilities, unfaithful explanations, and inability to incorporate expert knowledge precisely. We propose IDEA, a framework that extracts LLM decision knowledge into an interpretable parametric model over semantically meaningful factors. Through joint learning of verbal-to-numerical mappings and decision parameters via EM, correlated sampling that preserves factor dependencies, and direct parameter editing with mathematical guarantees, IDEA produces calibrated probabilities while enabling quantitative human-AI collaboration. Experiments across five datasets show IDEA with Qwen-3-32B (78.6%) outperforms DeepSeek R1 (68.1%) and GPT-5.2 (77.9%), achieving perfect factor exclusion and exact calibration -- precision unattainable through prompting alone. The implementation is publicly available at https://github.com/leonbig/IDEA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes IDEA, a framework to extract LLM decision knowledge into an interpretable parametric model over semantically meaningful factors. It jointly learns verbal-to-numeric mappings and decision parameters via EM, uses correlated sampling to preserve factor dependencies, and supports direct parameter editing with claimed mathematical guarantees. This yields calibrated probabilities and enables human-AI collaboration. Experiments on five datasets report that IDEA with Qwen-3-32B achieves 78.6% accuracy, outperforming DeepSeek R1 (68.1%) and GPT-5.2 (77.9%), with perfect factor exclusion and exact calibration unattainable by prompting.
Significance. If the extraction is faithful and the guarantees hold, IDEA could meaningfully improve interpretability, calibration, and editability of LLM decisions in high-stakes settings. The public code release at https://github.com/leonbig/IDEA is a clear strength that supports reproducibility.
major comments (2)
- [Experiments] Experiments section: The central claim of faithful extraction without distortion (enabling perfect exclusion and exact calibration) rests on aggregate accuracy comparisons alone. No per-example fidelity metrics, factor-contribution ablations, or agreement checks between the parametric model outputs and the original LLM's reasoning on individual instances are reported, leaving open whether performance gains reflect true capture of LLM knowledge or an approximation that scores well on the test sets.
- [Methods] Methods section on joint EM learning: The description of EM for verbal-to-numeric mappings and decision parameters does not clarify whether the resulting calibration and editing guarantees are derived independently or depend on parameters fitted directly to LLM outputs; this risks circularity in the reported 'exact calibration' results.
minor comments (2)
- [Abstract] Abstract: The five datasets are referenced but not named; adding their identities (and brief characteristics) would aid readers in assessing generalizability.
- [Discussion] The paper would benefit from an explicit limitations subsection discussing potential distortion in factor extraction for complex or implicit LLM reasoning chains.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments, which help clarify the presentation of our experimental validation and methodological details. We address each point below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The central claim of faithful extraction without distortion (enabling perfect exclusion and exact calibration) rests on aggregate accuracy comparisons alone. No per-example fidelity metrics, factor-contribution ablations, or agreement checks between the parametric model outputs and the original LLM's reasoning on individual instances are reported, leaving open whether performance gains reflect true capture of LLM knowledge or an approximation that scores well on the test sets.
Authors: We acknowledge that the current experiments emphasize aggregate accuracy and the mathematical properties of the model. The guarantees of exact calibration and perfect factor exclusion follow directly from the parametric form and EM optimization, which ensure the model computes normalized probabilities and supports precise edits independent of any single instance. To provide stronger evidence that performance gains reflect faithful extraction of LLM decision logic, we will add per-example agreement metrics between the parametric model and original LLM outputs, along with factor-contribution ablations, in the revised manuscript. revision: yes
-
Referee: [Methods] Methods section on joint EM learning: The description of EM for verbal-to-numeric mappings and decision parameters does not clarify whether the resulting calibration and editing guarantees are derived independently or depend on parameters fitted directly to LLM outputs; this risks circularity in the reported 'exact calibration' results.
Authors: The calibration and editing guarantees derive from the parametric model's structure, which by construction yields exact, normalized probabilities and allows direct parameter edits with provable effects on outputs. The EM procedure fits verbal-to-numeric mappings and decision parameters to maximize likelihood of the LLM's observed decisions, but 'exact calibration' refers to the resulting model's ability to produce well-calibrated probabilities (unlike direct LLM outputs). This is not circular, as the guarantees are properties of the model form rather than the fitting data. We will revise the methods section to explicitly separate the fitting process from these structural guarantees. revision: yes
Circularity Check
No significant circularity; derivation relies on external EM fitting and empirical benchmarks.
full rationale
The paper describes joint EM learning of verbal-to-numeric mappings and parameters, correlated sampling, and parameter editing with claimed mathematical guarantees, then reports aggregate accuracy gains (78.6% vs. baselines) plus perfect exclusion/calibration on five datasets. No equations are supplied in the manuscript excerpt that would allow a quoted reduction showing any prediction or guarantee is identical to the fitted inputs by construction. The performance claims are evaluated against independent baselines (DeepSeek R1, GPT-5.2) rather than being tautological to the fit itself. Self-citations are not invoked as load-bearing uniqueness theorems. The central extraction step therefore remains an independent modeling choice whose fidelity is tested externally rather than presupposed.
Axiom & Free-Parameter Ledger
free parameters (2)
- verbal-to-numerical mappings
- decision parameters
axioms (1)
- domain assumption LLM decision knowledge can be extracted into a parametric model over semantically meaningful factors
Forward citations
Cited by 1 Pith paper
-
FACT-E: Causality-Inspired Evaluation for Trustworthy Chain-of-Thought Reasoning
FACT-E uses controlled perturbations as an instrumental signal to measure intra-chain faithfulness in CoT reasoning and combines it with answer consistency to select trustworthy trajectories.
Reference graph
Works this paper leans on
-
[1]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Improving communication of uncertainty in the reports of the intergovernmental panel on climate change.Psychological Science, 20(3):299–308. Christopher J. C. Burges, Tal Shaked, Erin Renshaw, Ari Lazier, Matt Deeds, Nicole Hamilton, and Gre- gory N. Hullender. 2005. Learning to rank using gradient descent. InMachine Learning, Proceed- ings of the Twenty-...
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[2]
Language Models (Mostly) Know What They Know
Maximum likelihood from incomplete data via the em algorithm.Journal of the royal statistical society: series B (methodological), 39(1):1–22. Yu Feng, Ben Zhou, Weidong Lin, and Dan Roth. 2025. BIRD: A trustworthy bayesian inference framework for large language models. InThe Thirteenth Inter- national Conference on Learning Representations, ICLR 2025, Sin...
work page internal anchor Pith review arXiv 2025
-
[3]
COM2SENSE: A commonsense reasoning benchmark with complementary sentences. InFind- ings of the Association for Computational Linguistics: ACL/IJCNLP 2021, Online Event, August 1-6, 2021, Findings of ACL, pages 883–898. Association for Computational Linguistics. Yejun Soun, Jaemin Yoo, Minyong Cho, Jihyeong Jeon, and U Kang. 2022. Accurate stock movement p...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
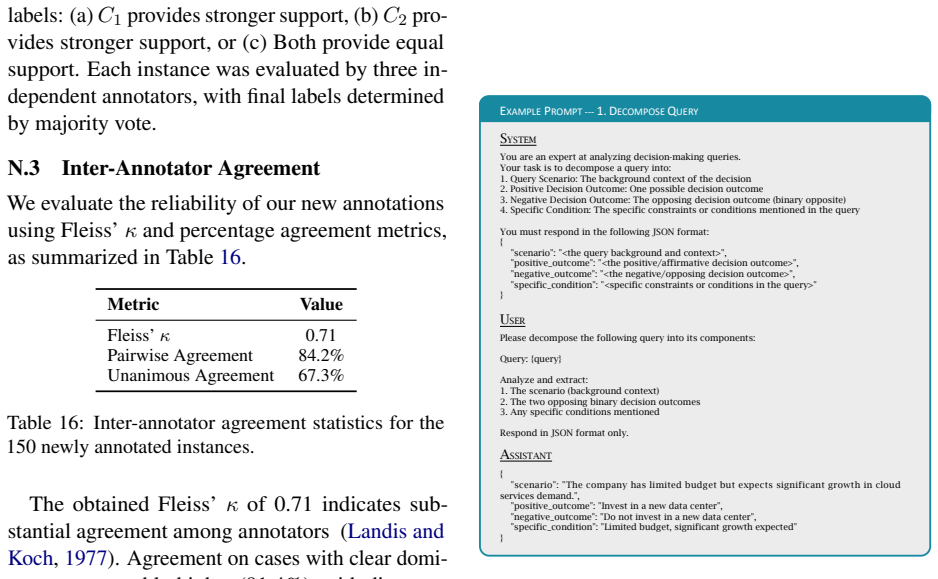
Query Scenario: The background context of the decision
-
[5]
Positive Decision Outcome: One possible decision outcome
-
[6]
Negative Decision Outcome: The opposing decision outcome (binary opposite)
-
[7]
scenario
Specific Condition: The specific constraints or conditions mentioned in the query You must respond in the following JSON format: { "scenario": "<the query background and context>", "positive_outcome": "<the positive/affirmative decision outcome>", "negative_outcome": "<the negative/opposing decision outcome>", "specific_condition": "<specific constraints ...
-
[8]
The scenario (background context)
-
[9]
The two opposing binary decision outcomes
-
[10]
scenario
Any specific conditions mentioned Respond in JSON format only. ASSISTANT { "scenario": "The company has limited budget but expects significant growth in cloud services demand.", "positive_outcome": "Invest in a new data center", "negative_outcome": "Do not invest in a new data center", "specific_condition": "Limited budget, significant growth expected" } ...
-
[11]
Be comprehensive and cover different aspects
-
[12]
Include specific conditions, factors, or circumstances
-
[13]
Focus on different aspects than the previous statements
Be distinct from other statements Format your response as: # <statement 1> # <statement 2> # <statement 3> # <statement 4> # <statement 5> USER Scenario: {scenario} Decision Outcome: {outcome} Generate 5 comprehensive statements explaining different conditions or factors that would support choosing this outcome. {If this is not the first call, the followi...
-
[14]
Each factor must be distinct and focus on a unique aspect
-
[15]
Factor values must be specific and directly reference elements from the statements
-
[16]
Avoid vague terms like 'the object' or 'the thing'
-
[17]
Market Demand
Each factor's two values MUST support different outcomes USER Scenario: {scenario} Positive Outcome: {positive_outcome} Supporting Statements: #1 {positive_statement_1} #2 {positive_statement_2} ... Negative Outcome: {negative_outcome} Supporting Statements: #1 {negative_statement_1} #2 {negative_statement_2} ... Extract distinct decision factors from the...
-
[18]
The positive_value supports the Positive Outcome
-
[19]
The negative_value supports the Negative Outcome
-
[20]
Market Demand
They support DIFFERENT outcomes Mark factors as invalid if both values support the same outcome or neither clearly supports an outcome. ASSISTANT { "Market Demand": { "positive_value_supports": "Positive", "negative_value_supports": "Negative", "valid": true }, "Legacy Systems": { "positive_value_supports": "Neutral", "negative_value_supports": "Neutral",...
-
[21]
Cover the same aspect or dimension
-
[22]
Are semantically similar
-
[23]
overlapping_groups
Have redundant values For overlapping factors, indicate which one to keep. ASSISTANT { "overlapping_groups": [ { "factors": ["Cost", "Financial Impact"], "keep": "Financial Impact", "reason": "Financial Impact covers both immediate cost and long-term ROI" } ], "unique_factors": ["Technical Feasibility"] } Figure 7: Prompting Example: CHECK OVERLAP- PING F...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.