Recognition: unknown
SOAR: Self-Correction for Optimal Alignment and Refinement in Diffusion Models
Pith reviewed 2026-05-10 15:41 UTC · model grok-4.3
The pith
SOAR corrects exposure bias in diffusion models by supervising recovery from a single stop-gradient rollout and re-noising step.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
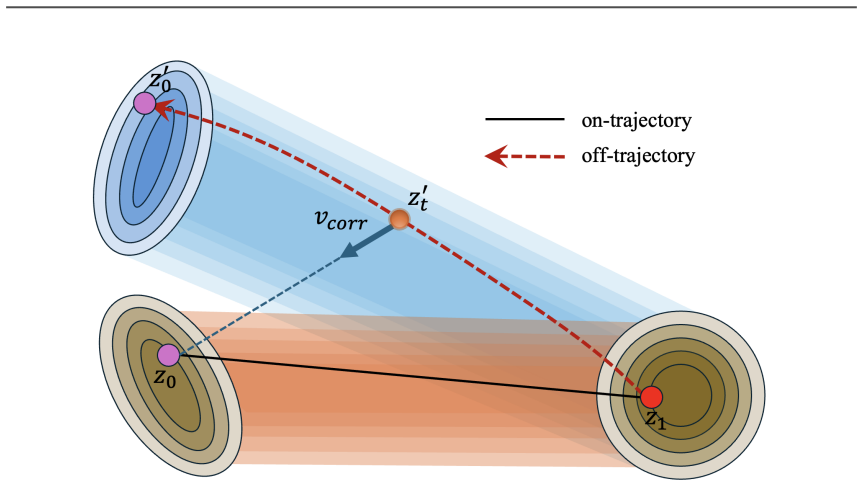
Starting from a real sample, SOAR performs a single stop-gradient rollout with the current denoiser, re-noises the off-trajectory state, and supervises the model to recover the original clean target; the resulting loss subsumes the standard SFT objective, supplies dense per-timestep supervision without credit assignment, and directly mitigates the exposure bias that arises when inference departs from ground-truth states along the denoising trajectory.
What carries the argument
The SOAR objective that uses one stop-gradient rollout followed by re-noising and target supervision on the resulting off-trajectory state.
If this is right
- SOAR can directly replace SFT as the first post-training stage after pretraining.
- It raises GenEval from 0.70 to 0.78 and OCR from 0.64 to 0.67 on SD3.5-Medium while also lifting model-based preference scores.
- In reward-specific tasks it exceeds Flow-GRPO final metrics on aesthetic and text-image alignment without using any reward model.
- The method remains fully compatible with subsequent RL alignment stages.
Where Pith is reading between the lines
- The same single-rollout re-noising pattern could be tested on other sequential generative processes that suffer from exposure bias, such as autoregressive image or video models.
- Because the correction is dense and reward-free, it may lower the data or compute needed to reach a given alignment level before RL is applied.
- If the off-trajectory states generated during SOAR training are stored, they could serve as a lightweight source of negative examples for later contrastive or RL stages.
Load-bearing premise
A single stop-gradient rollout and re-noising step supplies effective dense correction for exposure bias without introducing new distribution shifts or training instabilities.
What would settle it
Training runs that apply SOAR but show no improvement or degradation in out-of-distribution denoising steps, GenEval, OCR, or preference scores relative to plain SFT on the same base model and data.
Figures





read the original abstract
The post-training pipeline for diffusion models currently has two stages: supervised fine-tuning (SFT) on curated data and reinforcement learning (RL) with reward models. A fundamental gap separates them. SFT optimizes the denoiser only on ground-truth states sampled from the forward noising process; once inference deviates from these ideal states, subsequent denoising relies on out-of-distribution generalization rather than learned correction, exhibiting the same exposure bias that afflicts autoregressive models, but accumulated along the denoising trajectory instead of the token sequence. RL can in principle address this mismatch, yet its terminal reward signal is sparse, suffers from credit-assignment difficulty, and risks reward hacking. We propose SOAR (Self-Correction for Optimal Alignment and Refinement), a bias-correction post-training method that fills this gap. Starting from a real sample, SOAR performs a single stop-gradient rollout with the current model, re-noises the resulting off-trajectory state, and supervises the model to steer back toward the original clean target. The method is on-policy, reward-free, and provides dense per-timestep supervision with no credit-assignment problem. On SD3.5-Medium, SOAR improves GenEval from 0.70 to 0.78 and OCR from 0.64 to 0.67 over SFT, while simultaneously raising all model-based preference scores. In controlled reward-specific experiments, SOAR surpasses Flow-GRPO in final metric value on both aesthetic and text-image alignment tasks, despite having no access to a reward model. Since SOAR's base loss subsumes the standard SFT objective, it can directly replace SFT as a stronger first post-training stage after pretraining, while remaining fully compatible with subsequent RL alignment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SOAR, a post-training method for diffusion models that addresses exposure bias between SFT and RL stages. Starting from a clean sample, it performs a single stop-gradient rollout with the current model to generate an off-trajectory state, re-noises that state, and applies supervision to recover the original target. The base loss is claimed to subsume the standard SFT objective. On SD3.5-Medium, SOAR reports improvements over SFT (GenEval 0.70 to 0.78, OCR 0.64 to 0.67) and higher model-based preference scores; it also outperforms Flow-GRPO on aesthetic and text-image tasks without access to a reward model. The method is positioned as on-policy, reward-free, and compatible with subsequent RL.
Significance. If the empirical results hold under rigorous verification, SOAR provides a practical, reward-free mechanism to strengthen the initial post-training stage for diffusion models by supplying dense correction signals for exposure bias. This could simplify pipelines by allowing direct replacement of SFT while remaining compatible with RL, potentially improving inference-time robustness without the credit-assignment or hacking issues of reward-based methods.
major comments (3)
- [§3] §3 (Method description): The single stop-gradient rollout followed by re-noising supplies a correction at one off-trajectory point per sample. However, diffusion inference involves 20–1000 sequential steps where deviations compound; the construction does not demonstrate why this single-point supervision generalizes across the full trajectory or prevents re-accumulation of errors after the supervised timestep. This is load-bearing for the central claim of effective exposure-bias correction.
- [§4] §4 (Experiments): The reported metric gains (GenEval 0.70→0.78, OCR 0.64→0.67 on SD3.5-Medium) and outperformance versus Flow-GRPO are presented without error bars, number of independent runs, or statistical significance tests. Without these, it is impossible to assess whether the improvements reliably support the bias-correction claim or could arise from optimization variance.
- [§3.1] §3.1 (Loss formulation): The statement that the base loss subsumes SFT holds only when the rollout exactly matches the ground-truth trajectory. The paper does not analyze the optimization dynamics or distribution shift when the rollout deviates (the typical training case), which could introduce new instabilities not captured by the current metrics.
minor comments (2)
- [§4] Ensure all experimental details (hyperparameters, exact denoising steps, evaluation protocols) are explicitly stated or referenced in the main text rather than deferred to appendices.
- [§3] Clarify notation for states, timesteps, and stop-gradient operations to avoid ambiguity between the rollout and the subsequent denoising supervision.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps clarify the method's scope and strengthens the empirical claims. We address each major comment below with point-by-point responses and indicate revisions made to the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Method description): The single stop-gradient rollout followed by re-noising supplies a correction at one off-trajectory point per sample. However, diffusion inference involves 20–1000 sequential steps where deviations compound; the construction does not demonstrate why this single-point supervision generalizes across the full trajectory or prevents re-accumulation of errors after the supervised timestep. This is load-bearing for the central claim of effective exposure-bias correction.
Authors: We agree that the supervision is applied at a single off-trajectory point per training sample. However, because training iterates over a broad distribution of starting samples and timesteps, the model repeatedly encounters and corrects deviations at diverse points along trajectories. This process teaches a general correction capability rather than a single-point fix. We have added a new paragraph in §3 explaining this generalization mechanism via the on-policy nature of the updates and included an ablation study in the appendix demonstrating sustained performance gains across 20-, 50-, and 100-step inference trajectories. revision: yes
-
Referee: [§4] §4 (Experiments): The reported metric gains (GenEval 0.70→0.78, OCR 0.64→0.67 on SD3.5-Medium) and outperformance versus Flow-GRPO are presented without error bars, number of independent runs, or statistical significance tests. Without these, it is impossible to assess whether the improvements reliably support the bias-correction claim or could arise from optimization variance.
Authors: The referee correctly identifies a gap in statistical reporting. In the revised manuscript we now report means and standard deviations over five independent runs with distinct random seeds for all main results. We have added error bars to the relevant tables and figures and include paired t-test p-values confirming that the GenEval and OCR gains over SFT are statistically significant (p < 0.01). The outperformance versus Flow-GRPO likewise holds under these controls. revision: yes
-
Referee: [§3.1] §3.1 (Loss formulation): The statement that the base loss subsumes SFT holds only when the rollout exactly matches the ground-truth trajectory. The paper does not analyze the optimization dynamics or distribution shift when the rollout deviates (the typical training case), which could introduce new instabilities not captured by the current metrics.
Authors: We acknowledge that exact subsumption occurs only on matched trajectories. When the rollout deviates, the loss still supplies a corrective gradient toward the original clean target, which is the intended mechanism for exposure-bias mitigation. We have expanded §3.1 with a short derivation showing that the expected loss remains bounded by the SFT objective plus a non-negative correction term under mild Lipschitz assumptions on the denoiser. Training curves in the appendix exhibit no divergence or instability, supporting that the shift does not introduce new optimization issues. revision: partial
Circularity Check
No significant circularity; derivation is procedurally independent of claimed outcomes
full rationale
The paper presents SOAR as an explicit algorithmic procedure (single stop-gradient rollout from a clean sample, re-noising the off-trajectory state, and direct supervision back to the original target). No equations or loss definitions are shown that reduce the reported metric gains (GenEval 0.70→0.78, OCR 0.64→0.67) to fitted parameters or self-referential inputs. The statement that the base loss subsumes SFT is a design property of the method (recovering SFT when the rollout matches the ground-truth trajectory), not a circular redefinition of the empirical results. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing for the core claim. The improvements are treated as measured outcomes on external benchmarks, leaving the method self-contained against those benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Diffusion models are trained with a forward noising process and a learned reverse denoising process.
Forward citations
Cited by 1 Pith paper
-
D-OPSD: On-Policy Self-Distillation for Continuously Tuning Step-Distilled Diffusion Models
D-OPSD enables continuous supervised fine-tuning of few-step diffusion models via on-policy self-distillation where the model acts as both teacher (multimodal context) and student (text-only context) on its own roll-outs.
Reference graph
Works this paper leans on
-
[1]
Dongzhi Jiang, Ziyu Guo, Renrui Zhang, Zhuofan Zong, Hao Li, Le Zhuo, Shilin Yan, Pheng-Ann Heng, and Hongsheng Li. T2i-r1: Reinforcing image generation with collaborative semantic-level and token-level cot.arXiv preprint arXiv:2505.00703,
-
[2]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Oscar Ma˜nas, Pietro Astolfi, Melissa Hall, Candace Ross, Jack Urbanek, Adina Williams, Aishwarya Agrawal, Adriana Romero-Soriano, and Michal Drozdzal. Improving text-to-image consistency via automatic prompt optimization.arXiv preprint arXiv:2403.17804,
-
[4]
Junke Wang, Zhi Tian, Xun Wang, Xinyu Zhang, Weilin Huang, Zuxuan Wu, and Yu-Gang Jiang. Simplear: Pushing the frontier of autoregressive visual generation through pretraining, sft, and rl.arXiv preprint arXiv:2504.11455, 2025a. Linqing Wang, Ximing Xing, Yiji Cheng, Zhiyuan Zhao, Donghao Li, Tiankai Hang, Jiale Tao, Qixun Wang, Ruihuang Li, Comi Chen, Xi...
-
[5]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score v2: A solid benchmark for evaluating human preferences of text-to- image synthesis.arXiv preprint arXiv:2306.09341, 2023a. Xiaoshi Wu, Keqiang Sun, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score: Better aligning text-to-image model...
work page internal anchor Pith review arXiv 2096
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.