Recognition: unknown
Human-Centric Topic Modeling with Goal-Prompted Contrastive Learning and Optimal Transport
Pith reviewed 2026-05-10 14:50 UTC · model grok-4.3
The pith
Integrating human goals via LLM prompting and optimal transport produces topics more aligned with user intent while improving coherence and diversity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that goal candidates extracted from documents via LLM-based prompting can be integrated into topic discovery through optimal transport in a contrastive learning framework, enabling the GCTM-OT model to generate topics that respect explicit human objectives while achieving strong statistical quality.
What carries the argument
GCTM-OT, the goal-prompted contrastive topic model with optimal transport that aligns topic representations to LLM-derived goal candidates during learning.
Where Pith is reading between the lines
- The same prompting-plus-transport pattern could extend to other unsupervised tasks such as document clustering or summarization where user intent matters.
- Interactive systems become possible in which users review initial topics and refine goals for subsequent rounds.
- Testing the approach on non-social-media corpora would reveal whether the benefits hold beyond forum-style data.
- Optimal transport may prove useful more broadly for bridging LLM semantics with classical statistical models.
Load-bearing premise
LLM-based prompting reliably extracts accurate and useful goal candidates from documents without introducing systematic bias or errors.
What would settle it
Replacing the LLM goal extraction step with random or incorrect goal inputs and observing whether the reported gains in goal alignment, coherence, and diversity disappear on the same datasets.
Figures




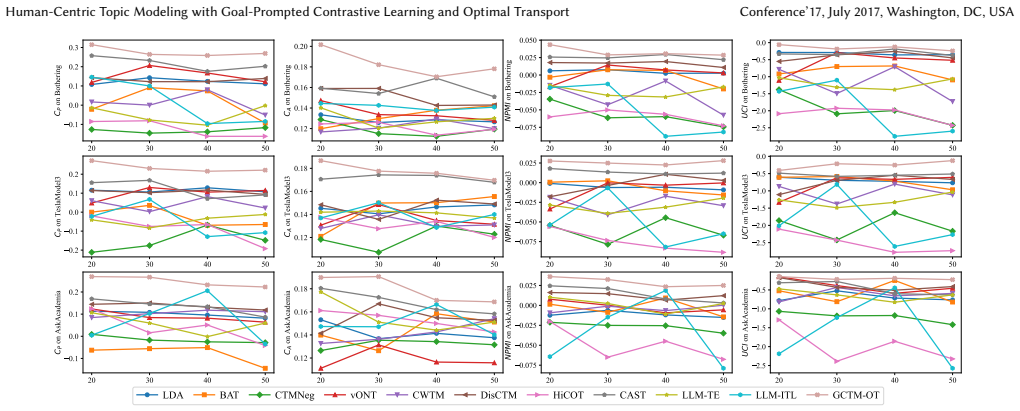

read the original abstract
Existing topic modeling methods, from LDA to recent neural and LLM-based approaches, which focus mainly on statistical coherence, often produce redundant or off-target topics that miss the user's underlying intent. We introduce Human-centric Topic Modeling, \emph{Human-TM}), a novel task formulation that integrates a human-provided goal directly into the topic modeling process to produce interpretable, diverse and goal-oriented topics. To tackle this challenge, we propose the \textbf{G}oal-prompted \textbf{C}ontrastive \textbf{T}opic \textbf{M}odel with \textbf{O}ptimal \textbf{T}ransport (GCTM-OT), which first uses LLM-based prompting to extract goal candidates from documents, then incorporates these into semantic-aware contrastive learning via optimal transport for topic discovery. Experimental results on three public subreddit datasets show that GCTM-OT outperforms state-of-the-art baselines in topic coherence and diversity while significantly improving alignment with human-provided goals, paving the way for more human-centric topic discovery systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Human-Centric Topic Modeling (Human-TM) as a new task formulation that directly incorporates a human-provided goal into topic discovery to produce interpretable, diverse, and goal-oriented topics. It proposes GCTM-OT, which extracts goal candidates from documents via LLM-based prompting and then applies semantic-aware contrastive learning regularized by optimal transport. Experiments on three public subreddit datasets report that GCTM-OT outperforms state-of-the-art baselines on topic coherence, diversity, and alignment with human-provided goals.
Significance. If the experimental claims hold after addressing validation concerns, the work would advance topic modeling by moving beyond purely statistical coherence toward explicit human-intent alignment, a timely direction given LLM prevalence. The technical choice to combine contrastive learning with optimal transport for goal incorporation is a clear strength, offering a principled mechanism for semantic alignment that could be adopted more broadly. The use of public datasets also supports reproducibility.
major comments (1)
- [Section 3] Section 3 (goal candidate extraction via LLM prompting): No independent validation of the extracted goal candidates is described (e.g., no human inter-annotator agreement, no semantic similarity to explicit human goals, or ablation on prompt quality). Because the headline experimental result (improved alignment with human-provided goals) depends on these candidates feeding into the contrastive + OT stages, any measured gains risk being circular or LLM-artifactual rather than reflective of true human intent. This is load-bearing for the central claim in the abstract and results.
minor comments (1)
- [Abstract] Abstract: The claim of outperformance would be clearer if the specific baselines, coherence/diversity metrics (e.g., NPMI, topic diversity formula), and any statistical significance tests were named rather than left at the level of 'outperforms state-of-the-art baselines'.
Simulated Author's Rebuttal
We are grateful to the referee for the thoughtful review and the recommendation for major revision. The feedback on validating the goal candidate extraction is well-taken, and we will incorporate the necessary changes to address this concern. Below we provide a point-by-point response.
read point-by-point responses
-
Referee: [Section 3] Section 3 (goal candidate extraction via LLM prompting): No independent validation of the extracted goal candidates is described (e.g., no human inter-annotator agreement, no semantic similarity to explicit human goals, or ablation on prompt quality). Because the headline experimental result (improved alignment with human-provided goals) depends on these candidates feeding into the contrastive + OT stages, any measured gains risk being circular or LLM-artifactual rather than reflective of true human intent. This is load-bearing for the central claim in the abstract and results.
Authors: We thank the referee for highlighting this important aspect. We concur that without explicit validation, there is a risk that the observed improvements in goal alignment could stem from LLM-specific patterns rather than robust human intent capture. To address this, we will revise the manuscript to include a dedicated validation subsection in Section 3. Specifically, we will conduct a human evaluation where multiple annotators rate the relevance of extracted goal candidates to the original documents and compute inter-annotator agreement using Cohen's kappa. We will also perform an ablation study on different prompting strategies and report their impact on downstream topic quality. Furthermore, we will measure the semantic similarity (using sentence embeddings) between the LLM-extracted candidates and the human-provided goals used in our alignment evaluation, to quantify how well the extraction approximates true human intent. These revisions will be added to strengthen the empirical support for our central claims. revision: yes
Circularity Check
No significant circularity; derivation relies on standard components without self-referential reduction
full rationale
The paper formulates Human-TM as integrating human-provided goals into topic modeling via LLM prompting for goal candidates, followed by contrastive learning and optimal transport. No equations or steps reduce a claimed output (e.g., topic coherence, diversity, or goal alignment) to a fitted parameter or self-citation by construction. The experimental claims rest on comparisons to baselines on public datasets, with no evidence that alignment metrics are tautologically defined from the LLM extraction step itself. Self-citations, if present, are not load-bearing for the core pipeline. This is a standard methodological proposal with independent empirical evaluation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aly Abdelrazek, Yomna Eid, Eman Gawish, Walaa Medhat, and Ahmed Hassan Yousef. 2023. Topic modeling algorithms and applications: A survey.Information Systems112 (2023), 102131
2023
-
[2]
Suman Adhya, Avishek Lahiri, Debarshi Kumar Sanyal, and Partha Pratim Das
-
[3]
InPro- ceedings of the 19th International Conference on Natural Language Processing, ICON 2022, New Delhi, India, December 15-18, 2022
Improving Contextualized Topic Models with Negative Sampling. InPro- ceedings of the 19th International Conference on Natural Language Processing, ICON 2022, New Delhi, India, December 15-18, 2022. Association for Computa- tional Linguistics, 128–138
2022
-
[4]
Blei, Andrew Y
David M. Blei, Andrew Y. Ng, and Michael I. Jordan. 2003. Latent Dirichlet Allocation.Journal of Machine Learning Research3 (2003), 993–1022
2003
-
[5]
Tom B Brown. 2020. Language models are few-shot learners.arXiv preprint arXiv:2005.14165(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[6]
Aaron Carass, Snehashis Roy, Adrian Gherman, Jacob C Reinhold, Andrew Jesson, Tal Arbel, Oskar Maier, Heinz Handels, Mohsen Ghafoorian, Bram Platel, et al
-
[7]
Evaluating white matter lesion segmentations with refined Sørensen-Dice analysis.Scientific reports10, 1 (2020), 8242
2020
- [8]
-
[9]
Ching-Yao Chuang, Joshua Robinson, Yen-Chen Lin, Antonio Torralba, and Ste- fanie Jegelka. 2020. Debiased Contrastive Learning. InAdvances in Neural Infor- mation Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual
2020
-
[10]
Marco Cuturi. 2013. Sinkhorn Distances: Lightspeed Computation of Optimal Transport. InAdvances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems 2013. Proceedings of a meeting held December 5-8, 2013, Lake Tahoe, Nevada, United States. 2292–2300
2013
-
[11]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Associa- tion for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, ...
2019
-
[12]
Kennedy Edemacu and Xintao Wu. 2025. Privacy Preserving Prompt Engineering: A Survey.Comput. Surveys57, 10 (2025), 255:1–255:36
2025
-
[13]
Zheng Fang, Yulan He, and Rob Procter. 2024. CWTM: Leveraging Contextualized Word Embeddings from BERT for Neural Topic Modeling. InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation, LREC/COLING 2024, 20-25 May, 2024, Torino, Italy. ELRA and ICCL, 4273–4286
2024
-
[14]
Fiona Fui-Hoon Nah, Ruilin Zheng, Jingyuan Cai, Keng Siau, and Langtao Chen
-
[15]
277–304 pages
Generative AI and ChatGPT: Applications, challenges, and AI-human collaboration. 277–304 pages
-
[16]
David W Goodall. 1967. The distribution of the matching coefficient.Biometrics (1967), 647–656
1967
-
[17]
Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde- Farley, Sherjil Ozair, Aaron C
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde- Farley, Sherjil Ozair, Aaron C. Courville, and Yoshua Bengio. 2014. Generative Adversarial Nets. InAdvances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, December 8-13 2014, Montreal, Quebec, Canada. 2672–2680
2014
-
[18]
Borgwardt, Malte J
Arthur Gretton, Karsten M. Borgwardt, Malte J. Rasch, Bernhard Schölkopf, and Alexander J. Smola. 2012. A Kernel Two-Sample Test.Journal of Machine Learning Research13 (2012), 723–773
2012
-
[19]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. 2015. Adam: A Method for Stochastic Opti- mization. In3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings
2015
-
[20]
Kingma and Max Welling
Diederik P. Kingma and Max Welling. 2014. Auto-Encoding Variational Bayes. In 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, April 14-16, 2014, Conference Track Proceedings
2014
-
[21]
Sven Kosub. 2019. A note on the triangle inequality for the Jaccard distance. Pattern Recognition Letters120 (2019), 36–38
2019
-
[22]
Jiayu Lin. 2016. On the dirichlet distribution.Department of Mathematics and Statistics, Queens University40 (2016)
2016
-
[23]
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv:1907.11692
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[24]
van der Veer, Lamiece Hassan, Chenghua Lin, and Goran Nenadic
Yanan Ma, Chenghao Xiao, Chenhan Yuan, Sabine N. van der Veer, Lamiece Hassan, Chenghua Lin, and Goran Nenadic. 2025. CAST: Corpus-Aware Self- similarity Enhanced Topic modelling. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL 2025 - Volume 1:...
2025
-
[25]
Yishu Miao, Lei Yu, and Phil Blunsom. 2016. Neural Variational Inference for Text Processing. InProceedings of the 33nd International Conference on Machine Learning, ICML 2016, New York City, NY, USA, June 19-24, 2016 (JMLR Workshop and Conference Proceedings, Vol. 48). JMLR.org, 1727–1736
2016
-
[26]
Yida Mu, Chun Dong, Kalina Bontcheva, and Xingyi Song. 2024. Large Language Models Offer an Alternative to the Traditional Approach of Topic Modelling. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation, LREC/COLING 2024, 20-25 May, 2024, Torino, Italy. ELRA and ICCL, 10160–10171
2024
-
[27]
Giorgio Patrini, Rianne van den Berg, Patrick Forré, Marcello Carioni, Samarth Bhargav, Max Welling, Tim Genewein, and Frank Nielsen. 2019. Sinkhorn AutoEn- coders. InProceedings of the Thirty-Fifth Conference on Uncertainty in Artificial Intelligence, UAI 2019, Tel A viv, Israel, July 22-25, 2019 (Proceedings of Machine Learning Research, Vol. 115). AUAI...
2019
-
[28]
Gabriel Peyré and Marco Cuturi. 2019. Computational Optimal Transport.Foun- dations and Trends in Machine Learning11, 5-6 (2019), 355–607
2019
-
[29]
Chau Pham, Alexander Miserlis Hoyle, Simeng Sun, Philip Resnik, and Mohit Iyyer. 2024. TopicGPT: A Prompt-based Topic Modeling Framework. InProceed- ings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), NAACL 2024, Mexico City, Mexico, June 16-21, 20...
2024
-
[30]
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners.OpenAI blog 1, 8 (2019), 9
2019
-
[31]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Confer- ence on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3-7, 2019. Association for Computational L...
2019
-
[32]
Michael Röder, Andreas Both, and Alexander Hinneburg. 2015. Exploring the Space of Topic Coherence Measures. InProceedings of the Eighth ACM Interna- tional Conference on Web Search and Data Mining, WSDM 2015, Shanghai, China, February 2-6, 2015. ACM, 399–408
2015
-
[33]
Pranab Sahoo, Ayush Kumar Singh, Sriparna Saha, Vinija Jain, Samrat Mondal, and Aman Chadha. 2024. A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications.CoRRabs/2402.07927 (2024)
work page internal anchor Pith review arXiv 2024
-
[34]
Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, and Tie-Yan Liu. 2020. MPNet: Masked and Permuted Pre-training for Language Understanding. InAdvances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual. Human-Centric Topic Modeling with Goal-Prompted Contrastiv...
2020
-
[35]
Marek Strong, Rami Aly, and Andreas Vlachos. 2024. Zero-Shot Fact Verification via Natural Logic and Large Language Models. InFindings of the Association for Computational Linguistics: EMNLP 2024, Miami, Florida, USA, November 12-16,
2024
-
[36]
Association for Computational Linguistics, 17021–17035
-
[37]
George R Terrell and David W Scott. 1992. Variable kernel density estimation. The Annals of Statistics(1992), 1236–1265
1992
-
[38]
Hoang Tran Vuong, Tue Le, Tu Vu, Tung Nguyen, Linh Ngo Van, Sang Dinh, and Thien Huu Nguyen. 2025. HiCOT: Improving Neural Topic Models via Optimal Transport and Contrastive Learning. InFindings of the Association for Computational Linguistics: ACL 2025. 13894–13920
2025
-
[39]
Wallach, David M
Hanna M. Wallach, David M. Mimno, and Andrew McCallum. 2009. Rethinking LDA: Why Priors Matter. InAdvances in Neural Information Processing Systems 22: 23rd Annual Conference on Neural Information Processing Systems 2009. Proceedings of a meeting held 7-10 December 2009, Vancouver, British Columbia, Canada. Curran Associates, Inc., 1973–1981
2009
-
[40]
White, Longqi Yang, Reid Andersen, Georg Buscher, Dhruv Joshi, and Nagu Rangan
Mengting Wan, Tara Safavi, Sujay Kumar Jauhar, Yujin Kim, Scott Counts, Jennifer Neville, Siddharth Suri, Chirag Shah, Ryen W. White, Longqi Yang, Reid Andersen, Georg Buscher, Dhruv Joshi, and Nagu Rangan. 2024. TnT-LLM: Text Mining at Scale with Large Language Models. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining...
2024
-
[41]
Rui Wang, Xuemeng Hu, Deyu Zhou, Yulan He, Yuxuan Xiong, Chenchen Ye, and Haiyang Xu. 2020. Neural Topic Modeling with Bidirectional Adversarial Training. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, July 5-10, 2020. Association for Computational Linguistics, 340–350
2020
-
[42]
Rui Wang, Xing Liu, Yanan Wang, Shuyu Chang, Yuanzhi Yao, and Haiping Huang
-
[43]
InProceedings of the Eighteenth ACM International Conference on Web Search and Data Mining, WSDM 2025, Hannover, Germany, March 10-14,
Mining Topics towards ChatGPT Using a Disentangled Contextualized- neural Topic Model. InProceedings of the Eighteenth ACM International Conference on Web Search and Data Mining, WSDM 2025, Hannover, Germany, March 10-14,
2025
-
[44]
Rui Wang, Deyu Zhou, and Yulan He. 2019. ATM: Adversarial-neural Topic Model.Information Processing & Management56, 6 (2019)
2019
-
[45]
Rui Wang, Deyu Zhou, and Yulan He. 2019. Open Event Extraction from Online Text using a Generative Adversarial Network. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3-7, 2019. Association for ...
2019
-
[46]
Rui Wang, Deyu Zhou, Haiping Huang, and Yongquan Zhou. 2025. MIT: Mutual Information Topic Model for Diverse Topic Extraction.IEEE Transactions on Neural Networks and Learning Systems36, 2 (2025), 2523–2537
2025
-
[47]
Tongzhou Wang and Phillip Isola. 2020. Understanding Contrastive Represen- tation Learning through Alignment and Uniformity on the Hypersphere. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event (Proceedings of Machine Learning Research, Vol. 119). PMLR, 9929–9939
2020
-
[48]
Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. 2020. MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre- Trained Transformers. InAdvances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual
2020
-
[49]
Zihan Wang, Jingbo Shang, and Ruiqi Zhong. 2023. Goal-Driven Explainable Clustering via Language Descriptions. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023. Association for Computational Linguistics, 10626–10649
2023
-
[50]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. InAdvances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, Novem...
2022
-
[51]
Xiaobao Wu, Thong Nguyen, and Anh Tuan Luu. 2024. A survey on neural topic models: methods, applications, and challenges.Artificial Intelligence Review57, 2 (2024), 18
2024
-
[52]
Weijie Xu, Xiaoyu Jiang, Srinivasan Sengamedu Hanumantha Rao, Francis Ian- nacci, and Jinjin Zhao. 2023. vONTSS: vMF based semi-supervised neural topic modeling with optimal transport. InFindings of the Association for Computa- tional Linguistics: ACL 2023, Toronto, Canada, July 9-14, 2023. Association for Computational Linguistics, 4433–4457
2023
-
[53]
Xiaohao Yang, He Zhao, Weijie Xu, Yuanyuan Qi, Jueqing Lu, Dinh Phung, and Lan Du. 2025. Neural Topic Modeling with Large Language Models in the Loop. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2025, Vienna, Austria, July 27 - August 1,
2025
-
[54]
Association for Computational Linguistics, 1377–1401
-
[55]
Dejian Yu and Bo Xiang. 2023. Discovering topics and trends in the field of Arti- ficial Intelligence: Using LDA topic modeling.Expert Systems with Applications 225 (2023), 120114
2023
-
[56]
Yuwei Zhang, Zihan Wang, and Jingbo Shang. 2023. ClusterLLM: Large Language Models as a Guide for Text Clustering. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023. Association for Computational Linguistics, 13903–13920
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.