Recognition: unknown
MISID: A Multimodal Multi-turn Dataset for Complex Intent Recognition in Strategic Deception Games
Pith reviewed 2026-05-10 14:37 UTC · model grok-4.3
The pith
MISID dataset reveals MLLM failures in multi-turn deception and FRACTAM improves intent inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce MISID, a multimodal multi-turn multi-participant dataset for complex intent recognition sourced from strategic deception games and equipped with a fine-grained two-tier multi-dimensional annotation scheme for long-context discourse and causal tracking. Systematic evaluation of state-of-the-art MLLMs on MISID exposes critical deficiencies such as text-prior visual hallucination, impaired cross-modal synergy, and limited capacity for chaining causal cues. We therefore propose FRACTAM, which follows a Decouple-Anchor-Reason paradigm to extract pure unimodal factual representations, apply two-stage retrieval for long-range factual anchoring, and construct explicit cross-modal证据链, as
What carries the argument
The Decouple-Anchor-Reason paradigm that first decouples modalities to obtain unbiased factual representations, then anchors long-range facts via two-stage retrieval, and finally constructs explicit cross-modal evidence chains for intent inference.
If this is right
- Current MLLMs exhibit text-prior visual hallucination, impaired cross-modal synergy, and weak causal chaining on complex strategic tasks.
- FRACTAM raises hidden intent detection and inference accuracy on the MISID benchmark.
- Perceptual accuracy stays robust while inference improves under the new framework.
- The two-tier annotation supports evidence-based causal tracking across extended multimodal discourse.
Where Pith is reading between the lines
- The same anchoring and evidence-chain technique could be tested on real-world negotiation transcripts or security interview recordings to check generalization beyond games.
- If the two-tier scheme proves reliable, it could be adapted to label long video or audio archives for intent in other high-stakes domains.
- The emphasis on pure unimodal facts before fusion suggests a route to reduce hallucination in any long-context multimodal model, not only intent recognition.
Load-bearing premise
High-stakes social strategy games accurately mirror the structure and cues of real-world extended deceptive narratives and the two-tier annotation scheme reliably captures causal intent.
What would settle it
If FRACTAM applied to MISID produces no measurable gain in hidden intent detection accuracy over unmodified MLLMs, or if inter-annotator agreement on the causal-tracking tier proves low, the performance claims would be falsified.
Figures

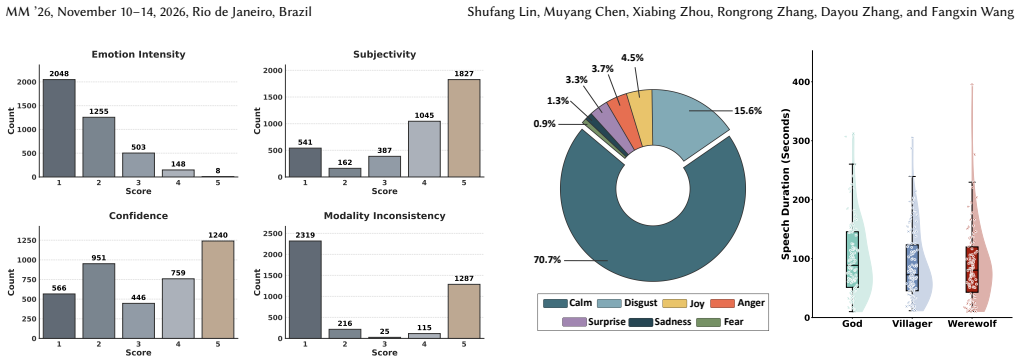

read the original abstract
Understanding human intent in complex multi-turn interactions remains a fundamental challenge in human-computer interaction and behavioral analysis. While existing intent recognition datasets focus mainly on single utterances or simple dialogues, real-world scenarios often involve sophisticated strategic interactions where participants must maintain complex deceptive narratives over extended periods. To address this gap, we introduce MISID, a comprehensive multimodal, multi-turn, and multi-participant benchmark for intent recognition. Sourced from high-stakes social strategy games, MISID features a fine-grained, two-tier multi-dimensional annotation scheme tailored for long-context discourse analysis and evidence-based causal tracking. Our systematic evaluation of state-of-the-art Multimodal Large Language Models (MLLMs) on MISID reveals critical deficiencies in complex scenarios, including text-prior visual hallucination, impaired cross-modal synergy, and limited capacity in chaining causal cues. Consequently, we propose FRACTAM as a baseline framework. Using a ``Decouple-Anchor-Reason'' paradigm, FRACTAM reduces text bias by extracting pure unimodal factual representations, employs two-stage retrieval for long-range factual anchoring, and constructs explicit cross-modal evidence chains. Extensive experiments demonstrate that FRACTAM enhances mainstream models' performance in complex strategic tasks, improving hidden intent detection and inference while maintaining robust perceptual accuracy. Our dataset is available at https://naislab.cn/datasets/MISID.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MISID, a multimodal multi-turn dataset sourced from high-stakes social strategy games, featuring a fine-grained two-tier multi-dimensional annotation scheme for long-context discourse analysis and evidence-based causal tracking of deceptive intents. It evaluates state-of-the-art MLLMs on the dataset, identifying deficiencies such as text-prior visual hallucination, impaired cross-modal synergy, and limited causal cue chaining. The authors propose FRACTAM, a Decouple-Anchor-Reason baseline framework that extracts unimodal factual representations, uses two-stage retrieval for factual anchoring, and builds explicit cross-modal evidence chains, with experiments claiming improved hidden intent detection and inference while preserving perceptual accuracy.
Significance. If the annotations are shown to be reliable proxies for causal structure, MISID would provide a valuable new benchmark for multimodal intent recognition in extended strategic interactions, addressing a gap in existing single-turn or simple-dialogue datasets. The FRACTAM framework offers a practical paradigm for reducing text bias in MLLMs on complex tasks. Dataset release and reproducible baseline experiments are positive contributions that could spur further work in behavioral analysis and HCI.
major comments (1)
- [Dataset construction and annotation] The two-tier annotation scheme (described in the abstract and dataset construction) is load-bearing for all empirical claims, yet the manuscript reports no inter-annotator agreement metrics, adjudication protocol, or external validation against known ground-truth intents. Without these, the reported MLLM deficiencies and FRACTAM gains on hidden-intent detection cannot be interpreted as reflecting true causal structure rather than annotator noise or bias.
minor comments (1)
- [Abstract] The abstract states that FRACTAM 'enhances mainstream models' performance' but does not name the specific metrics (e.g., F1, accuracy) or statistical significance tests used in the 'extensive experiments.'
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, particularly on the critical role of annotation reliability for the MISID dataset. We address the major comment below and commit to revisions that strengthen the manuscript.
read point-by-point responses
-
Referee: The two-tier annotation scheme (described in the abstract and dataset construction) is load-bearing for all empirical claims, yet the manuscript reports no inter-annotator agreement metrics, adjudication protocol, or external validation against known ground-truth intents. Without these, the reported MLLM deficiencies and FRACTAM gains on hidden-intent detection cannot be interpreted as reflecting true causal structure rather than annotator noise or bias.
Authors: We agree that the lack of reported inter-annotator agreement (IAA) metrics and a detailed adjudication protocol is a notable gap, given the centrality of the two-tier scheme to all empirical claims. The manuscript describes the annotation process at a high level but does not quantify agreement or fully specify how disagreements were resolved. In the revised version, we will expand the dataset construction section to include IAA metrics (such as Fleiss' kappa across annotators for both tiers), a complete description of the multi-annotator workflow and adjudication protocol, and any available cross-checks against game logs or other observable evidence. These additions will support interpreting the MLLM deficiencies and FRACTAM improvements as reflecting genuine model limitations rather than annotation artifacts. On external validation against independent ground-truth intents, we note that the deceptive intents in this benchmark are inherently inferred from the multimodal interactions and evidence chains; the annotations constitute the primary ground truth by design, and no separate external oracle exists beyond the provided game data. revision: yes
Circularity Check
No circularity: empirical dataset release and baseline method with independent evaluation
full rationale
The paper introduces the MISID dataset from high-stakes games, describes a two-tier annotation scheme for causal tracking, evaluates MLLMs on deficiencies like text-prior hallucination, and proposes FRACTAM via a Decouple-Anchor-Reason paradigm as an empirical baseline. No mathematical derivations, equations, fitted parameters, or predictions are present that reduce to self-defined inputs. No self-citations appear in the abstract or described content, and the central claims rest on direct experimental comparisons rather than tautological reductions or imported uniqueness theorems. The work is self-contained as a dataset contribution plus method proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Anthropic. 2025. Claude Sonnet 4.5 System Card. https://www.anthropic.com/ claude-sonnet-4-5-system-card
2025
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al . 2025. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Shaojie Bai, J Zico Kolter, and Vladlen Koltun. 2018. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling.arXiv preprint arXiv:1803.01271(2018)
work page internal anchor Pith review arXiv 2018
-
[4]
Emanuele Bastianelli, Andrea Vanzo, Pawel Swietojanski, and Verena Rieser. 2020. SLURP: A spoken language understanding resource package. InProceedings of the Conference on Empirical Methods in Natural Language Processing. 7252–7262
2020
-
[5]
Yonatan Bisk, Ari Holtzman, Jesse Thomason, Jacob Andreas, Yoshua Bengio, Joyce Chai, Mirella Lapata, Angeliki Lazaridou, Jonathan May, Aleksandr Nis- nevich, et al. 2020. Experience grounds language. InProceedings of the Conference on Empirical Methods in Natural Language Processing. 8718–8735
2020
-
[6]
Hervé Bredin. 2023. pyannote. audio 2.1 speaker diarization pipeline: principle, benchmark, and recipe. InProceedings of the Interspeech Conference. ISCA, 1983– 1987
2023
-
[7]
1987.Politeness: Some universals in language usage
Penelope Brown. 1987.Politeness: Some universals in language usage. Vol. 4. Cambridge university press
1987
-
[8]
David B Buller and Judee K Burgoon. 1996. Interpersonal deception theory. Communication Theory6, 3 (1996), 203–242
1996
-
[9]
Santiago Castro, Devamanyu Hazarika, Verónica Pérez-Rosas, Roger Zimmer- mann, Rada Mihalcea, and Soujanya Poria. 2019. Towards multimodal sarcasm detection (an _obviously_ perfect paper). InProceedings of the Annual Meeting of the Association for Computational Linguistics. 4619–4629
2019
-
[10]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multi- modality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Gordon V Cormack, Charles LA Clarke, and Stefan Buettcher. 2009. Reciprocal rank fusion outperforms condorcet and individual rank learning methods. InPro- ceedings of the international ACM SIGIR Conference on Research and Development in Information Retrieval. 758–759
2009
-
[12]
Martin Ester, Hans-Peter Kriegel, Jörg Sander, and Xiaowei Xu. 1996. A density- based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining. 226–231
1996
-
[13]
Robert Geirhos, Jörn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A Wichmann. 2020. Shortcut learn- ing in deep neural networks.Nature Machine Intelligence2, 11 (2020), 665–673
2020
-
[14]
Daniela Gerz, Pei-Hao Su, Razvan Kusztos, Avishek Mondal, Michał Lis, Eshan Singhal, Nikola Mrkšić, Tsung-Hsien Wen, and Ivan Vulić. 2021. Multilingual and cross-lingual intent detection from spoken data. InProceedings of the Conference on Empirical Methods in Natural Language Processing. 7468–7475
2021
-
[15]
Deepanway Ghosal, Navonil Majumder, Soujanya Poria, Niyati Chhaya, and Alexander Gelbukh. 2019. Dialoguegcn: A graph convolutional neural network for emotion recognition in conversation. InProceedings of the Conference on Empirical Methods in Natural Language Processing and the International Joint Conference on Natural Language Processing. 154–164
2019
-
[16]
Google DeepMind. 2025. Gemini 3 Flash: Frontier Intelligence Built for Speed. https://blog.google/products-and-platforms/products/gemini/gemini-3-flash/
2025
-
[17]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. 2025. Deepseek-r1: Incen- tivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Viresh Gupta, Mohit Agarwal, Manik Arora, Tanmoy Chakraborty, Richa Singh, and Mayank Vatsa. 2019. Bag-of-lies: A multimodal dataset for deception detec- tion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. 83–90
2019
-
[19]
Bayesian
John C Harsanyi. 1967. Games with incomplete information played by “Bayesian” players, I–III Part I. The basic model.Management Science14, 3 (1967), 159–182
1967
-
[20]
He He, Derek Chen, Anusha Balakrishnan, and Percy Liang. 2018. Decoupling strategy and generation in negotiation dialogues. InProceedings of the Conference on Empirical Methods in Natural Language Processing. 2333–2343
2018
-
[21]
Julia Hirschberg, Stefan Benus, Jason M Brenier, Frank Enos, Sarah Friedman, Sarah Gilman, Cynthia Girand, Martin Graciarena, Andreas Kathol, Laura A Michaelis, Bryan L Pellom, Elizabeth Shriberg, and Andreas Stolcke. 2005. Dis- tinguishing deceptive from non-deceptive speech. InProceedings of the Annual Conference of the International Speech Communicatio...
2005
-
[22]
Sepp Hochreiter and Jürgen Schmidhuber. 1997. Long short-term memory.Neural Computation9, 8 (1997), 1735–1780
1997
-
[23]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. 2024. Gpt-4o system card.arXiv preprint arXiv:2410.21276(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Julia Kruk, Jonah Lubin, Karan Sikka, Xiao Lin, Dan Jurafsky, and Ajay Divakaran
-
[25]
InProceedings of the Conference on Empirical Methods in Natural Language Processing and the International Joint Conference on Natural Language Processing
Integrating text and image: Determining multimodal document intent in instagram posts. InProceedings of the Conference on Empirical Methods in Natural Language Processing and the International Joint Conference on Natural Language Processing. 4622–4632
-
[26]
David La Barbera, Gian Carlo Milanese, Georgios Peikos, Gabriella Pasi, and Marco Viviani. 2025. Beyond binary classification: ranking for information access in misinformation contexts. InProceeding of the National Conference on Artificial Intelligence (CEUR Workshop Proceedings, Vol. 4121). 1–7
2025
- [27]
-
[28]
Jiapeng Li, Ping Wei, Wenjuan Han, and Lifeng Fan. 2023. Intentqa: Context-aware video intent reasoning. InProceedings of the IEEE/CVF International Conference on Computer Vision. 11963–11974
2023
-
[29]
Yulong Li, Yuxuan Zhang, Rui Chen, Feilong Tang, Zhixiang Lu, Ming Hu, Jiang- hao Wu, Haochen Xue, Mian Zhou, Chong Li, et al. 2025. Genesis: A Large-Scale Benchmark for Multimodal Large Language Model in Emotional Causality Anal- ysis. InProceedings of the ACM International Conference on Multimedia. 12651– 12658
2025
-
[30]
Zheng Lian, Bin Liu, and Jianhua Tao. 2021. CTNet: Conversational transformer network for emotion recognition.IEEE/ACM Transactions on Audio, Speech, and Language Processing29 (2021), 985–1000
2021
-
[31]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Cheng- gang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. 2024. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [32]
-
[33]
Shuhua Liu, Lanting Li, Ming Fang, Chih-Cheng Hung, and Shihao Yang. 2022. Research on Implicit Intent Recognition Method Based on Prompt Learning. A vailable at SSRN 4164522(2022)
2022
-
[34]
Adyasha Maharana, Quan Hung Tran, Franck Dernoncourt, Seunghyun Yoon, Trung Bui, Walter Chang, and Mohit Bansal. 2022. Multimodal intent discovery from livestream videos. InFindings of the Association for Computational Linguistics. 476–489
2022
-
[35]
Kyle Mahowald, Anna A Ivanova, Idan A Blank, Nancy Kanwisher, Joshua B Tenenbaum, and Evelina Fedorenko. 2024. Dissociating language and thought in large language models.Trends in Cognitive Sciences28, 6 (2024), 517–540
2024
-
[36]
Vlad Niculae, Srijan Kumar, Jordan Boyd-Graber, and Cristian Danescu-Niculescu- Mizil. 2015. Linguistic harbingers of betrayal: A case study on an online strategy game. InProceedings of the Annual Meeting of the Association for Computational Linguistics and the International Joint Conference on Natural Language Processing. 1650–1659
2015
-
[37]
OpenAI. 2025. GPT-5.1 Instant and GPT-5.1 Thinking System Card Addendum. https://openai.com/index/gpt-5-system-card-addendum-gpt-5-1/
2025
-
[38]
Verónica Pérez-Rosas, Mohamed Abouelenien, Rada Mihalcea, and Mihai Burzo
-
[39]
InProceedings of the ACM on International Conference on Multimodal Interaction
Deception detection using real-life trial data. InProceedings of the ACM on International Conference on Multimodal Interaction. 59–66
-
[40]
Verónica Pérez-Rosas and Rada Mihalcea. 2015. Experiments in open domain deception detection. InProceedings of the Conference on Empirical Methods in Natural Language Processing. 1120–1125
2015
-
[41]
Steven Pinker, Martin A Nowak, and James J Lee. 2008. The logic of indirect speech.Proceedings of the National Academy of Sciences105, 3 (2008), 833–838
2008
-
[42]
Alexis Plaquet and Hervé Bredin. 2023. Powerset multi-class cross entropy loss for neural speaker diarization. InProceedings of the Interspeech Conference. ISCA, 3222–3226
2023
-
[43]
Soujanya Poria, Devamanyu Hazarika, Navonil Majumder, Gautam Naik, Erik Cambria, and Rada Mihalcea. 2019. Meld: A multimodal multi-party dataset for emotion recognition in conversations. InProceedings of the Annual Meeting of the Association for Computational Linguistics. 527–536
2019
-
[44]
Yao Qian, Ximo Bianv, Yu Shi, Naoyuki Kanda, Leo Shen, Zhen Xiao, and Michael Zeng. 2021. Speech-language pre-training for end-to-end spoken language under- standing. InProceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing. IEEE, 7458–7462
2021
-
[45]
Tulika Saha, Aditya Patra, Sriparna Saha, and Pushpak Bhattacharyya. 2020. Towards emotion-aided multi-modal dialogue act classification. InProceedings of the Annual Meeting of the Association for Computational Linguistics. 4361–4372
2020
-
[46]
Maarten Sap, Ronan Le Bras, Daniel Fried, and Yejin Choi. 2022. Neural theory- of-mind? on the limits of social intelligence in large lms. InProceedings of the Conference on Empirical Methods in Natural Language Processing. 3762–3780
2022
-
[47]
Vasanth Sarathy, Alexander Tsuetaki, Antonio Roque, and Matthias Scheutz. 2020. Reasoning requirements for indirect speech act interpretation. InProceedings of the International Conference on Computational Linguistics. 4937–4948
2020
-
[48]
Jocelyn Shen, Amina Luvsanchultem, Jessica Kim, Kynnedy Smith, Valdemar Danry, Kantwon Rogers, Sharifa Alghowinem, Hae Won Park, Maarten Sap, and Cynthia Breazeal. 2026. The Hidden Puppet Master: A Theoretical and Real-World MM ’26, November 10–14, 2026, Rio de Janeiro, Brazil Shufang Lin, Muyang Chen, Xiabing Zhou, Rongrong Zhang, Dayou Zhang, and Fangxi...
-
[49]
Weizhou Shen, Siyue Wu, Yunyi Yang, and Xiaojun Quan. 2021. Directed acyclic graph network for conversational emotion recognition. InProceedings of the An- nual Meeting of the Association for Computational Linguistics and the International Joint Conference on Natural Language Processing. 1551–1560
2021
-
[50]
Yuanchen Shi, Fang Kong, and Longyin Zhang. 2025. Impact of Stickers on Multimodal Sentiment and Intent in Social Media: A New Task, Dataset and Baseline. InProceedings of the ACM International Conference on Multimedia. 5637– 5646
2025
-
[51]
Gopendra Vikram Singh, Mauajama Firdaus, Asif Ekbal, and Pushpak Bhat- tacharyya. 2022. Emoint-trans: A multimodal transformer for identifying emo- tions and intents in social conversations.IEEE/ACM Transactions on Audio, Speech, and Language Processing31 (2022), 290–300
2022
-
[52]
Felix Soldner, Verónica Pérez-Rosas, and Rada Mihalcea. 2019. Box of lies: Mul- timodal deception detection in dialogues. InProceedings of the Conference of the North American Chapter of the Association for Computational Linguistics. 1768–1777
2019
-
[53]
Michael Spence. 1978. Job market signaling. InUncertainty in economics. Elsevier, 281–306
1978
-
[54]
Qwen Team. 2026. Qwen 3.5: Scaling Native Multimodal Agents with Efficient Architectures. https://qwen.ai/blog?id=qwen3.5
2026
-
[55]
Fanfan Wang, Zixiang Ding, Rui Xia, Zhaoyu Li, and Jianfei Yu. 2022. Multimodal emotion-cause pair extraction in conversations.IEEE Transactions on Affective Computing14, 3 (2022), 1832–1844
2022
- [56]
-
[57]
xAI. 2025. Grok 4.1 Model Card. https://data.x.ai/2025-11-17-grok-4-1-model- card.pdf
2025
-
[58]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
Shaozu Yuan, Xin Shen, Yuming Zhao, Hang Liu, Zhiling Yan, Ruixue Liu, and Meng Chen. 2022. MCIC: multimodal conversational intent classification for E-commerce customer service. InProceedings of the CCF International Conference on Natural Language Processing and Chinese Computing. Springer, 749–761
2022
-
[60]
Z.ai. 2025. GLM-4.7 Model Card. https://build.nvidia.com/z-ai/glm4_7/ modelcard
2025
-
[61]
Dongyu Zhang, Minghao Zhang, Heting Zhang, Liang Yang, and Hongfei Lin
-
[62]
InProceed- ings of the Annual Meeting of the Association for Computational Linguistics and the International Joint Conference on Natural Language Processing
MultiMET: A multimodal dataset for metaphor understanding. InProceed- ings of the Annual Meeting of the Association for Computational Linguistics and the International Joint Conference on Natural Language Processing. 3214–3225
-
[63]
Hanlei Zhang, Xin Wang, Hua Xu, Qianrui Zhou, Kai Gao, Jianhua Su, Jinyue Zhao, Wenrui Li, and Yanting Chen. 2024. MIntRec2.0: A Large-scale Bench- mark Dataset for Multimodal Intent Recognition and Out-of-scope Detection in Conversations. InProceedings of the International Conference on Learning Repre- sentations
2024
-
[64]
Hanlei Zhang, Hua Xu, Xin Wang, Qianrui Zhou, Shaojie Zhao, and Jiayan Teng
-
[65]
InProceedings of the ACM International Conference on Multimedia
Mintrec: A new dataset for multimodal intent recognition. InProceedings of the ACM International Conference on Multimedia. 1688–1697
-
[66]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, et al. 2025. Qwen3 embedding: Advancing text embedding and reranking through foundation models.arXiv preprint arXiv:2506.05176(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
Xuhui Zhou, Hao Zhu, Leena Mathur, Ruohong Zhang, Haofei Yu, Zhengyang Qi, Louis-Philippe Morency, Yonatan Bisk, Daniel Fried, Graham Neubig, and Maarten Sap. 2024. SOTOPIA: Interactive Evaluation for Social Intelligence in Language Agents. InProceedings of the International Conference on Learning Rep- resentations. OpenReview.net. https://openreview.net/...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.