Recognition: 2 theorem links
· Lean TheoremOSC: Hardware Efficient W4A4 Quantization via Outlier Separation in Channel Dimension
Pith reviewed 2026-05-10 16:11 UTC · model grok-4.3
The pith
Activation outliers cluster persistently in fixed channels across tokens, enabling a dual-path W4A4 quantization that limits accuracy loss while delivering hardware speedup.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
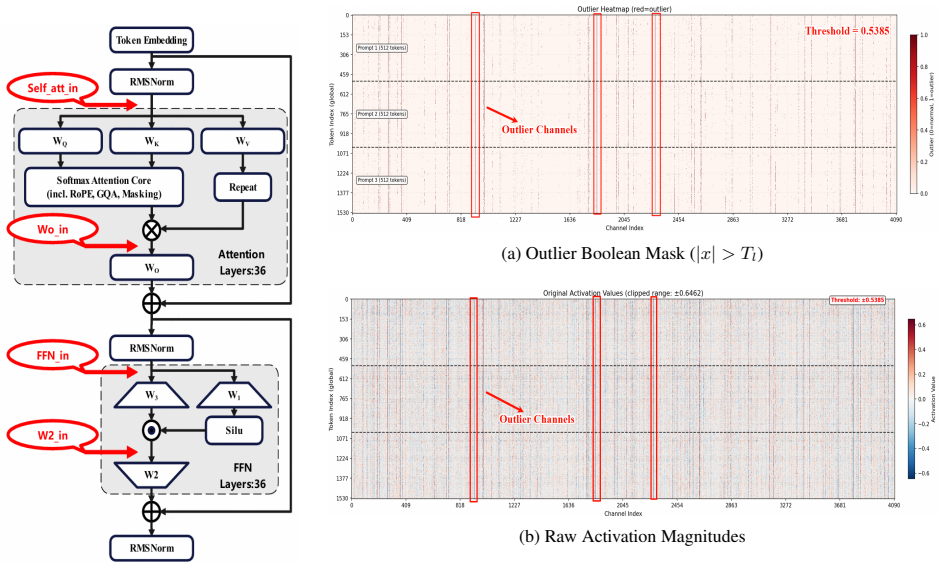
We systematically investigate the spatial distribution of outliers and demonstrate a token-persistent structural clustering effect, where high-magnitude outliers consistently occupy fixed channels across tokens. Building on this insight, we propose OSC, a hardware-efficient framework for outlier suppression. During inference, OSC executes a dual-path computation consisting of a low-precision 4-bit GEMM path and a high-precision 16-bit branch GEMM path. OSC uses an offline group-wise strategy to identify the channels where outliers are located and then performs structured sub-tensor extraction to coalesce these scattered activation channels into a compact dense tensor online.
What carries the argument
Offline group-wise identification of outlier channels combined with online structured sub-tensor extraction that gathers scattered high-magnitude activations into one compact dense tensor for separate high-precision GEMM.
If this is right
- Average accuracy drop is restricted to 2.19 points on Qwen3-8B and 1.12 points on Qwen3-30B under W4A4 quantization.
- Peak speedup reaches 1.78 times the W8A8 GEMM baseline on a modern AI accelerator.
- Outlier protection occurs through regularized, high-throughput GEMM operations that fit directly into 4-bit micro-scaling hardware.
- A fallback to FP8 is applied for inputs such as W2 where outlier clustering is weaker.
Where Pith is reading between the lines
- The same clustering pattern may appear in other transformer-based models, allowing OSC-style separation to become a reusable preprocessing step for low-bit deployment.
- Accelerator designers could add native support for the sub-tensor extraction step, further lowering any remaining overhead.
- Pairing OSC with weight-only compression methods could compound memory and speed gains beyond what either technique achieves alone.
Load-bearing premise
High-magnitude outliers stay clustered inside the same fixed channels from token to token, so offline identification remains reliable and online extraction adds little overhead or accuracy cost.
What would settle it
Inference on a model in which outlier channel locations shift substantially between tokens, producing either an accuracy drop larger than two points or a realized speedup below 1.5 times the W8A8 baseline because of extraction overhead.
Figures


read the original abstract
While 4-bit quantization is essential for high-throughput deployment of Large Language Models, activation outliers often lead to significant accuracy degradation due to the restricted dynamic range of low-bit formats. In this paper, we systematically investigate the spatial distribution of outliers and demonstrate a token-persistent structural clustering effect, where high-magnitude outliers consistently occupy fixed channels across tokens. Building on this insight, we propose OSC, a hardware-efficient framework for outlier suppression. During inference, OSC executes a dual-path computation consisting of a low-precision 4-bit General Matrix Multiplication (GEMM) path and a high-precision 16-bit branch GEMM path. Specifically, OSC uses an offline group-wise strategy to identify the channels where outliers are located and then performs structured sub-tensor extraction to coalesce these scattered activation channels into a compact dense tensor online. This mechanism implements outlier protection through regularized and high-throughput GEMM operations, achieving a seamless fit with modern 4-bit micro-scaling hardware. Furthermore, for the inputs of W2 where outlier clustering is less pronounced, we integrate a fallback strategy to FP8. Evaluation on Qwen3-8B and Qwen3-30B restricts the average accuracy drop to 2.19 and 1.12 points, respectively. Notably, OSC is highly hardware-friendly, achieving a peak speedup of 1.78x over the W8A8 GEMM baseline on a modern AI accelerator.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that activation outliers in LLMs exhibit a token-persistent structural clustering in fixed channels, which enables OSC: an offline group-wise identification of outlier channels followed by online structured sub-tensor extraction. This supports a dual-path W4A4 inference (4-bit GEMM for the bulk plus a compact 16-bit branch GEMM for outliers), with an FP8 fallback for W2 inputs. On Qwen3-8B and Qwen3-30B the method limits average accuracy drop to 2.19 and 1.12 points while delivering up to 1.78x speedup over a W8A8 GEMM baseline on modern AI accelerators.
Significance. If the clustering pattern proves general, OSC offers a practical route to hardware-efficient W4A4 quantization that aligns with existing micro-scaling accelerators via regular GEMM operations rather than irregular outlier handling. The concrete accuracy and speedup numbers on 8B/30B models constitute a tangible contribution to the deployment literature.
major comments (3)
- [Abstract (outlier distribution investigation)] The central claim rests on the empirical observation of token-persistent fixed-channel outlier clustering (abstract). No channel-overlap statistics across tokens, no sensitivity analysis to input distribution or model scale, and no results outside the Qwen3 family are supplied; without these the offline identification step cannot be shown to be reliable for arbitrary workloads.
- [Abstract (evaluation paragraph)] Evaluation reports accuracy drops of 2.19 / 1.12 points and 1.78x speedup, yet supplies no baseline implementation details, no statistical significance tests, and no description of how the group-wise outlier thresholds were selected (abstract). These omissions make the quantitative claims difficult to reproduce or compare.
- [Abstract (W2 fallback sentence)] The FP8 fallback for W2 inputs is introduced without an ablation on its frequency, accuracy impact, or effect on the claimed W4A4 regime (abstract). This post-hoc adjustment risks undermining the uniformity of the quantization scheme.
minor comments (1)
- [Abstract] The phrasing 'restricts the average accuracy drop' in the abstract is unclear; a direct statement such as 'achieves an average accuracy drop of only' would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing clarifications and indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract (outlier distribution investigation)] The central claim rests on the empirical observation of token-persistent fixed-channel outlier clustering (abstract). No channel-overlap statistics across tokens, no sensitivity analysis to input distribution or model scale, and no results outside the Qwen3 family are supplied; without these the offline identification step cannot be shown to be reliable for arbitrary workloads.
Authors: We agree that the abstract, being a concise summary, does not include these supporting details. The manuscript demonstrates the clustering effect through the effectiveness of the offline identification and resulting accuracy preservation, but we acknowledge the absence of explicit overlap statistics, sensitivity analysis, and cross-family results. In the revised version we will expand the main text with channel-overlap measurements across tokens, sensitivity tests on varied inputs and scales within Qwen3, and an explicit discussion of the evaluation scope. We will also update the abstract to reference these additions. revision: yes
-
Referee: [Abstract (evaluation paragraph)] Evaluation reports accuracy drops of 2.19 / 1.12 points and 1.78x speedup, yet supplies no baseline implementation details, no statistical significance tests, and no description of how the group-wise outlier thresholds were selected (abstract). These omissions make the quantitative claims difficult to reproduce or compare.
Authors: The abstract is intentionally high-level; the full manuscript describes the W8A8 GEMM baseline, the group-wise percentile-based threshold selection on calibration data, and reports averaged results. However, we agree that explicit implementation details, threshold methodology, and statistical significance testing are not sufficiently highlighted. We will add a brief description of threshold selection to the abstract and include baseline details plus significance tests in the experiments section of the revision. revision: yes
-
Referee: [Abstract (W2 fallback sentence)] The FP8 fallback for W2 inputs is introduced without an ablation on its frequency, accuracy impact, or effect on the claimed W4A4 regime (abstract). This post-hoc adjustment risks undermining the uniformity of the quantization scheme.
Authors: We agree that the fallback requires further justification to preserve the uniformity of the W4A4 claim. The manuscript presents it as a targeted extension for W2 inputs where clustering is weaker. In the revision we will add an ablation study quantifying the fallback frequency, its accuracy contribution, and its negligible effect on the primary W4A4 path. We will also revise the abstract to clarify the fallback's optional and limited nature. revision: yes
Circularity Check
No circularity; empirical observation and direct measurement form an independent chain.
full rationale
The paper begins from an empirical investigation of activation outlier spatial distributions, reports an observed token-persistent channel clustering pattern, and then constructs the OSC dual-path inference mechanism around offline channel identification and online sub-tensor extraction. All reported results (accuracy drops of 2.19/1.12 points and 1.78x speedup) are direct experimental measurements on Qwen3 models against external baselines, not quantities algebraically defined in terms of the method's own fitted parameters or prior self-citations. No equations, uniqueness theorems, or ansatzes are introduced that reduce to the inputs by construction; the derivation remains open to external falsification via the reported hardware and accuracy benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
token-persistent structural clustering effect, where high-magnitude outliers consistently occupy fixed channels across tokens... offline group-wise strategy to identify the channels... structured sub-tensor extraction
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Clustering Density Ck = N(k)_hit / N(k)_total... dual-path hybrid-precision GEMM
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
DeepSeek-AI et al. DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models.arXiv preprint arXiv:2512.02556, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Aaron Grattafiori et al. The Llama 3 Herd of Models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Artificial intelligence index report 2025.arXiv preprint arXiv:2504.07139, 2025
Nestor Maslej et al. Artificial Intelligence Index Report 2025. Technical report, Stanford Institute for Human- Centered AI (HAI), 2025. arXiv:2504.07139
-
[4]
The Case for 4-bit Precision: Unified Optimization of 4-bit Quantization of Large Language Models
Tim Dettmers and Luke Zettlemoyer. The Case for 4-bit Precision: Unified Optimization of 4-bit Quantization of Large Language Models. InProceedings of the 40th International Conference on Machine Learning (ICML), pages 7749–7774, 2023
2023
-
[5]
arXiv preprint arXiv:2310.10537 , year=
Bita Darvish Rouhani et al. Microscaling Data Formats for Deep Learning.arXiv preprint arXiv:2310.10537, 2023
-
[6]
NVIDIA Blackwell Architecture Whitepaper
NVIDIA. NVIDIA Blackwell Architecture Whitepaper. White paper, NVIDIA Corporation, 2024
2024
-
[7]
HiFloat4 Format for Language Model Inference.arXiv preprint arXiv:2602.11287, 2026
Yuanyong Luo et al. HiFloat4 Format for Language Model Inference.arXiv preprint arXiv:2602.11287, 2026
-
[8]
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
Tim Dettmers, Mike Lewis, et al. LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[9]
SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression
Tim Dettmers, Ruslan Svirschevski, et al. SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression. InThe 12th International Conference on Learning Representations (ICLR), 2024
2024
-
[10]
OliVe: Accelerating Large Language Models via Hardware-friendly Outlier-Victim Pair Quantization
Cong Guo et al. OliVe: Accelerating Large Language Models via Hardware-friendly Outlier-Victim Pair Quantization. InProceedings of the 50th Annual International Symposium on Computer Architecture (ISCA), 2023
2023
-
[11]
SmoothQuant: Accurate and Efficient Post-Training Quantization for Real-Time LLM Serving
Guangxuan Xiao, Ji Lin, et al. SmoothQuant: Accurate and Efficient Post-Training Quantization for Real-Time LLM Serving. InProceedings of the 40th International Conference on Machine Learning (ICML), 2023
2023
-
[12]
QuaRot: Outlier-Free 4-Bit Inference in Rotated LLMs
Saleh Ashkboos, Amirkeivan Mohtashami, et al. QuaRot: Outlier-Free 4-Bit Inference in Rotated LLMs. In Advances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[13]
An Yang et al. Qwen3 Technical Report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers
Zhewei Yao, Reza Yazdani Aminabadi, et al. ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[15]
Measuring Massive Multitask Language Understanding
Dan Hendrycks et al. Measuring Massive Multitask Language Understanding.arXiv preprint arXiv:2009.03300, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[16]
Training Verifiers to Solve Math Word Problems
Karl Cobbe et al. Training Verifiers to Solve Math Word Problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[17]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark et al. Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge.arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[18]
Mingjie Sun, Xinlei Chen, and Zhuang Liu. Massive Activations in Large Language Models.arXiv preprint arXiv:2402.17762, 2024
-
[19]
AWQ: Activation-aware Weight Quantization for On-Device LLM Compression and Acceleration
Ji Lin, Jiaming Tang, et al. AWQ: Activation-aware Weight Quantization for On-Device LLM Compression and Acceleration. InProceedings of the 6th Conference on Machine Learning and Systems (MLSys), 2024. 12
2024
-
[20]
SpinQuant: LLM Quantization with Learned Rotations
Zechun Liu, Changsheng Zhao, et al. SpinQuant: LLM Quantization with Learned Rotations. InThe 13th International Conference on Learning Representations (ICLR), 2025
2025
-
[21]
Flatquant: Flatness matters for LLM quantization.CoRR, abs/2410.09426, 2024
Yuxuan Sun et al. FlatQuant: Flatness Matters for LLM Quantization.arXiv preprint arXiv:2410.09426, 2025
-
[22]
Atom: Low-bit Quantization for Efficient and Accurate LLM Serving
Yilong Zhao, Lohit Lin, et al. Atom: Low-bit Quantization for Efficient and Accurate LLM Serving. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[23]
Yuxiang Chen, Haocheng Xi, et al. TetraJet-v2: Accurate NVFP4 Training for Large Language Models.arXiv preprint arXiv:2510.27527, 2025. 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.