Recognition: 2 theorem links
· Lean TheoremDocSeeker: Structured Visual Reasoning with Evidence Grounding for Long Document Understanding
Pith reviewed 2026-05-12 04:14 UTC · model grok-4.3
The pith
DocSeeker trains multimodal models to localize evidence pages before reasoning on long documents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
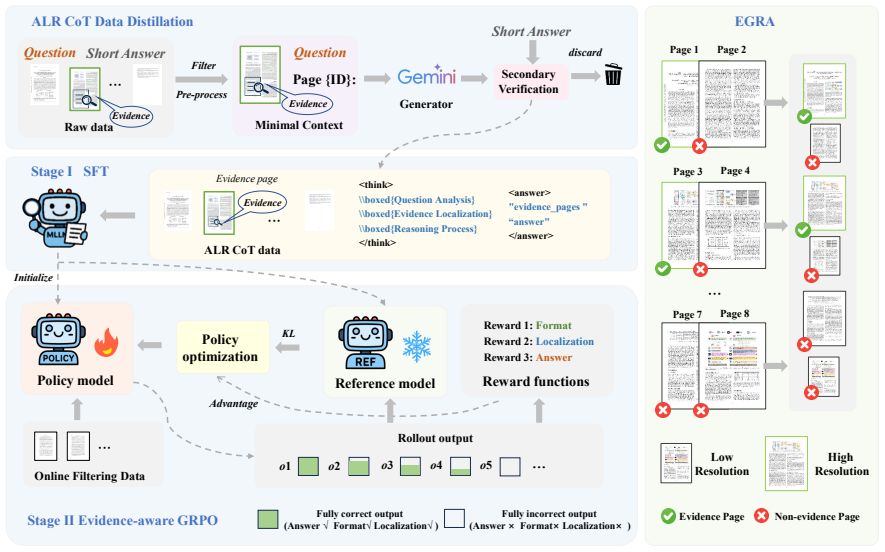
By requiring the model to first localize the specific evidence pages needed for a query and then reason from those pages, and by training this behavior through an initial supervised stage on knowledge-distilled examples followed by Evidence-aware Group Relative Policy Optimization that rewards both localization quality and answer accuracy, DocSeeker overcomes the low signal-to-noise ratio and weak supervision that normally degrade performance as document length grows.
What carries the argument
Evidence-aware Group Relative Policy Optimization (EGRPO), which jointly scores evidence localization and final-answer correctness inside the required Analysis-Localization-Reasoning workflow.
If this is right
- Performance stays high on both in-domain and out-of-domain long-document tasks.
- Models trained only on short pages generalize to ultra-long documents.
- The same model works naturally as a component inside visual retrieval-augmented generation pipelines.
- Evidence-Guided Resolution Allocation keeps memory costs manageable when training on many pages at once.
Where Pith is reading between the lines
- The method may let future systems avoid ever-larger context windows by retrieving and localizing evidence on demand instead.
- Similar evidence-localization training could apply to other long sequential inputs such as video or multi-turn conversations.
- Making the selected evidence explicit may improve user trust and allow easier debugging of incorrect answers.
- The approach could be combined with stronger base models to further raise the ceiling on long-document performance.
Load-bearing premise
High-quality structured reasoning traces can be created by knowledge distillation and that the subsequent policy optimization will improve both localization and accuracy without introducing new failure modes or requiring extensive tuning.
What would settle it
A collection of ultra-long documents in which the correct answer depends on evidence pages that the trained model systematically fails to select, producing no improvement over a baseline that receives the same pages without localization training.
Figures









read the original abstract
Existing Multimodal Large Language Models (MLLMs) suffer from significant performance degradation on the long document understanding task as document length increases. This stems from two fundamental challenges: 1) a low Signal-to-Noise Ratio (SNR), with crucial evidence buried in irrelevant pages; and 2) supervision scarcity, as datasets offering only final short answers provide a weak learning signal. In this paper, we address these challenges by proposing a paradigm that requires the model to execute a structured Analysis, Localization and Reasoning workflow. To instill this capability, we design a two-stage training framework: we first perform Supervised Fine-Tuning on high-quality data generated via an efficient knowledge distillation strategy. Subsequently, we employ an Evidence-aware Group Relative Policy Optimization which jointly optimizes for both evidence localization and answer accuracy. Additionally, we introduce a Evidence-Guided Resolution Allocation strategy to mitigate memory constraints of training on multi-pages documents. Extensive experiments demonstrate that DocSeeker achieves superior performance on both in-domain and out-of-domain tasks. We show it robustly generalizes from short-page training to ultra-long documents and is naturally synergistic with visual Retrieval-Augmented Generation systems, serving as a solid foundation for their implementation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DocSeeker, a framework for long document understanding in multimodal large language models (MLLMs). It proposes a structured Analysis, Localization, and Reasoning workflow trained in two stages: supervised fine-tuning on knowledge-distilled high-quality data, followed by Evidence-aware Group Relative Policy Optimization (GRPO) to jointly optimize evidence localization and answer accuracy. An Evidence-Guided Resolution Allocation strategy is introduced to address memory issues with multi-page documents. The authors claim that DocSeeker achieves superior performance on in-domain and out-of-domain tasks, robustly generalizes from short-page training to ultra-long documents, and is synergistic with visual Retrieval-Augmented Generation systems.
Significance. If the empirical results hold, this work has the potential to significantly advance the field by providing a structured approach to mitigate performance degradation in long-document MLLM tasks due to low signal-to-noise ratio and weak supervision. The two-stage training with GRPO for joint optimization of localization and reasoning is a novel contribution, and the synergy with RAG systems could have broad applications in document AI. The use of knowledge distillation for data generation is efficient and practical.
major comments (1)
- [§4.2] §4.2 (Evidence-aware Group Relative Policy Optimization): The central claim of superior performance and robust short-to-ultra-long generalization depends on the two-stage pipeline, specifically that SFT on distilled data followed by Evidence-aware GRPO will simultaneously improve evidence localization and final-answer accuracy. The manuscript supplies no ablations, reward-function details, or failure-case analysis showing that the group-relative formulation avoids reward hacking, over-penalization of valid long-context reasoning, or distribution shift between the distilled teacher and the student policy.
minor comments (2)
- [Abstract] The abstract asserts superior performance and generalization but supplies no quantitative metrics, baselines, ablation results, or experimental details; these should be summarized with specific numbers and comparisons to allow immediate assessment of the claims.
- [Throughout] Ensure all acronyms (MLLM, SNR, GRPO, RAG) are defined on first use and used consistently in the method and experiments sections.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the potential impact of DocSeeker and for their detailed feedback. We address the major comment point-by-point below.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Evidence-aware Group Relative Policy Optimization): The central claim of superior performance and robust short-to-ultra-long generalization depends on the two-stage pipeline, specifically that SFT on distilled data followed by Evidence-aware GRPO will simultaneously improve evidence localization and final-answer accuracy. The manuscript supplies no ablations, reward-function details, or failure-case analysis showing that the group-relative formulation avoids reward hacking, over-penalization of valid long-context reasoning, or distribution shift between the distilled teacher and the student policy.
Authors: We agree that the manuscript would benefit from more detailed analysis of the GRPO component to fully substantiate the claims. In the revised version, we will expand §4.2 with: (1) ablations comparing the full two-stage pipeline against SFT-only and GRPO-only variants, reporting both localization and accuracy metrics; (2) the complete specification of the reward function and the group-relative advantage estimation; and (3) a dedicated subsection on failure cases and robustness checks, including discussion of potential reward hacking, over-penalization, and distribution shift. These additions will provide empirical evidence that the Evidence-aware GRPO improves upon the SFT baseline without introducing the issues raised. revision: yes
Circularity Check
No circularity: empirical claims rest on experimental outcomes, not derivations
full rationale
The paper describes an empirical two-stage training pipeline (SFT on distilled data followed by Evidence-aware GRPO) and reports performance gains on in-domain/out-of-domain tasks plus short-to-long generalization. No mathematical derivations, equations, fitted parameters, or predictions are presented that could reduce to their own inputs by construction. Claims are framed as outcomes of the proposed workflow rather than first-principles results or self-referential definitions. No self-citation load-bearing steps or ansatz smuggling appear in the abstract or described methodology.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Knowledge distillation from an existing model can produce high-quality step-by-step reasoning data for long documents.
- domain assumption Joint optimization of evidence localization and answer accuracy via group relative policy optimization is feasible and beneficial.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel uncleartwo-stage training framework: Supervised Fine-Tuning on high-quality data generated via knowledge distillation ... Evidence-aware Group Relative Policy Optimization which jointly optimizes for both evidence localization and answer accuracy
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery unclearALR visual reasoning paradigm ... Page-Aware Input Representation ... Structured Reasoning Paradigm with Explicit Evidence Grounding
Reference graph
Works this paper leans on
-
[1]
Hi- erarchical multimodal transformers for multipage docvqa
Rubèn Tito, Dimosthenis Karatzas, and Ernest Valveny. Hi- erarchical multimodal transformers for multipage docvqa. Pattern Recognition, 144:109834, 2023. 1, 2, 5, 6, 19
work page 2023
-
[2]
Document understanding dataset and evaluation (dude)
Jordy Van Landeghem, Rubèn Tito, Łukasz Borchmann, Michał Pietruszka, Pawel Joziak, Rafal Powalski, Dawid Ju- rkiewicz, Mickaël Coustaty, Bertrand Anckaert, Ernest Val- veny, et al. Document understanding dataset and evaluation (dude). InIEEE/CVF International Conference on Computer Vision, page 19471–19483, 2023. 2, 5, 12
work page 2023
-
[3]
Wenjun Ke, Yifan Zheng, Yining Li, Hengyuan Xu, Dong Nie, Peng Wang, and Yao He. Large language models in document intelligence: A comprehensive survey, recent ad- vances, challenges and future trends.ACM Transactions on Information Systems, 2025. 1
work page 2025
-
[4]
arXiv preprint arXiv:2409.18839 , year=
Bin Wang, Chao Xu, Xiaomeng Zhao, Linke Ouyang, Fan Wu, Zhiyuan Zhao, Rui Xu, Kaiwen Liu, Yuan Qu, Fukai Shang, et al. Mineru: An open-source solution for precise document content extraction. InarXiv:2409.18839, 2024. 1
-
[5]
Dolphin: Document image parsing via heterogeneous anchor prompting
Hao Feng, Shu Wei, Xiang Fei, Wei Shi, Yingdong Han, Lei Liao, Jinghui Lu, Binghong Wu, Qi Liu, Chunhui Lin, et al. Dolphin: Document image parsing via heterogeneous anchor prompting. InarXiv:2505.14059, 2025
-
[6]
arXiv preprint arXiv:2506.05218 , year=
Zhang Li, Yuliang Liu, Qiang Liu, Zhiyin Ma, Ziyang Zhang, Shuo Zhang, Zidun Guo, Jiarui Zhang, Xinyu Wang, and Xiang Bai. Monkeyocr: Document parsing with a structure-recognition-relation triplet paradigm. In arXiv:2506.05218, 2025. 1
-
[7]
YL Liu, HL Li, X Bai, et al. A brief analysis of chatgpt: historical evolution current applications and future prospects [j].Journal of Image and Graphics, 28(04):893–902, 2023. 1
work page 2023
-
[8]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wen- bin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report. In arXiv:2502.13923, 2025. 1, 3, 5, 19
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shen- glong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models. In arXiv:2504.10479, 2025. 3, 5, 6, 19, 20
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
mplug- docowl2: High-resolution compressing for ocr-free multi- page document understanding
Anwen Hu, Haiyang Xu, Liang Zhang, Jiabo Ye, Ming Yan, Ji Zhang, Qin Jin, Fei Huang, and Jingren Zhou. mplug- docowl2: High-resolution compressing for ocr-free multi- page document understanding. InAnnual Meeting of the As- sociation for Computational Linguistics, pages 5817–5834,
-
[11]
Ocr-free document understanding transformer
Geewook Kim, Teakgyu Hong, Moonbin Yim, JeongYeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sang- doo Yun, Dongyoon Han, and Seunghyun Park. Ocr-free document understanding transformer. InEuropean Confer- ence on Computer Vision, pages 498–517. Springer, 2022
work page 2022
-
[12]
GLM-V Team, Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, Shuaiqi Duan, Weihan Wang, Yan Wang, Yean Cheng, Zehai He, Zhe Su, Zhen Yang, Ziyang Pan, Aohan Zeng, Baoxu Wang, Bin Chen, Boyan Shi, Changyu Pang, Chenhui Zhang, Da Yin, Fan Yang, Guoqing Chen, Jiazheng Xu, Jiale Zhu, Jiali Che...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Zhiyu Wu, Xiaokang Chen, Zizheng Pan, Xingchao Liu, Wen Liu, Damai Dai, Huazuo Gao, Yiyang Ma, Chengyue Wu, Bingxuan Wang, Zhenda Xie, Yu Wu, Kai Hu, Ji- awei Wang, Yaofeng Sun, Yukun Li, Yishi Piao, Kang Guan, Aixin Liu, Xin Xie, Yuxiang You, Kai Dong, Xingkai Yu, Haowei Zhang, Liang Zhao, Yisong Wang, and Chong Ruan. Deepseek-vl2: Mixture-of-experts vis...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Yuliang Liu, Biao Yang, Qiang Liu, Zhang Li, Zhiyin Ma, Shuo Zhang, and Xiang Bai. Textmonkey: An ocr-free large multimodal model for understanding document. In arXiv:2403.04473, 2024
-
[15]
Pix2struct: Screenshot parsing as pretraining for visual lan- guage understanding
Kenton Lee, Mandar Joshi, Iulia Raluca Turc, Hexiang Hu, Fangyu Liu, Julian Martin Eisenschlos, Urvashi Khandel- wal, Peter Shaw, Ming-Wei Chang, and Kristina Toutanova. Pix2struct: Screenshot parsing as pretraining for visual lan- guage understanding. InInternational Conference on Ma- chine Learning, pages 18893–18912. PMLR, 2023
work page 2023
-
[16]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. Minicpm-v: A gpt-4v level mllm on your phone. In arXiv:2408.01800, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Visrag: Vision-based retrieval-augmented generation on multi-modality documents
Shi Yu, Chaoyue Tang, Bokai Xu, Junbo Cui, Junhao Ran, Yukun Yan, Zhenghao Liu, Shuo Wang, Xu Han, Zhiyuan Liu, et al. Visrag: Vision-based retrieval-augmented gener- 9 ation on multi-modality documents. InarXiv:2410.10594,
-
[18]
Manuel Faysse, Hugues Sibille, Tony Wu, Bilel Omrani, Gautier Viaud, Céline Hudelot, and Pierre Colombo. Col- pali: Efficient document retrieval with vision language mod- els. InarXiv:2407.01449, 2024. 1, 3, 7, 19
-
[19]
Jiabo Ye, Anwen Hu, Haiyang Xu, Qinghao Ye, Ming Yan, Yuhao Dan, Chenlin Zhao, Guohai Xu, Chenliang Li, Junfeng Tian, et al. mplug-docowl: Modularized multi- modal large language model for document understanding. In arXiv:2307.02499, 2023. 1
-
[20]
PDF-WuKong: A Large Multimodal Model for Efficient Long PDF Reading with End-to-End Sparse Sampling
Xudong Xie, Hao Yan, Liang Yin, Yang Liu, Jing Ding, Minghui Liao, Yuliang Liu, Wei Chen, and Xiang Bai. Wukong: A large multimodal model for efficient long pdf reading with end-to-end sparse sampling. In arXiv:2410.05970, 2024. 1, 19
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Slidevqa: A dataset for document visual question answering on multiple images
Ryota Tanaka, Kyosuke Nishida, Kosuke Nishida, Taku Hasegawa, Itsumi Saito, and Kuniko Saito. Slidevqa: A dataset for document visual question answering on multiple images. InAAAI Conference on Artificial Intelligence, vol- ume 37, pages 13636–13645, 2023. 2, 5
work page 2023
-
[22]
MultimodalArXiv: A dataset for improving scientific comprehension of large vision-language models
Linjie Li, Yuxuan Wang, Rui Xu, Peiyi Wang, Xinyun Feng, Lingpeng Kong, and Qun Liu. MultimodalArXiv: A dataset for improving scientific comprehension of large vision-language models. InAnnual Meeting of the Asso- ciation for Computational Linguistics, pages 14369–14387, 2024
work page 2024
-
[23]
MVQA: A dataset for multimodal infor- mation retrieval in pdf-based visual question answering
Yihao Ding, Kaixuan Ren, Jiabin Huang, Siwen Luo, and Soyeon Caren Han. MVQA: A dataset for multimodal infor- mation retrieval in pdf-based visual question answering. In arXiv:2404.12720, 2024. 2
-
[24]
Mmlongbench-doc: Benchmarking long-context doc- ument understanding with visualizations
Yubo Ma, Yuhang Zang, Liangyu Chen, Meiqi Chen, Yizhu Jiao, Xinze Li, Xinyuan Lu, Ziyu Liu, Yan Ma, Xiaoyi Dong, et al. Mmlongbench-doc: Benchmarking long-context doc- ument understanding with visualizations. InAdvances in Neural Information Processing Systems, volume 37, pages 95963–96010, 2024. 3, 5
work page 2024
-
[25]
Chao Deng, Jiale Yuan, Pi Bu, Peijie Wang, Zhong-Zhi Li, Jian Xu, Xiao-Hui Li, Yuan Gao, Jun Song, Bo Zheng, et al. Longdocurl: a comprehensive multimodal long document benchmark integrating understanding, reasoning, and locat- ing. InAnnual Meeting of the Association for Computational Linguistics, pages 1135–1159, 2025. 3, 5
work page 2025
-
[26]
MMDocIR: Benchmarking multimodal retrieval for long documents
Kuicai Dong, Yujing Chang, Derrick Goh Xin Deik, Dexun Li, Ruiming Tang, and Yong Liu. MMDocIR: Benchmarking multimodal retrieval for long documents. InConference on Empirical Methods in Natural Language Processing, pages 30971–31005, 2025. 3
work page 2025
-
[27]
Yew Ken Chia, Liying Cheng, Hou Pong Chan, Maojia Song, Chaoqun Liu, Mahani Aljunied, Soujanya Poria, and Lidong Bing. M-LongDoc: A benchmark for multimodal super-long document understanding and a retrieval-aware tuning frame- work. InConference on Empirical Methods in Natural Lan- guage Processing, pages 9233–9250, 2025. 3
work page 2025
-
[28]
DocBench: A benchmark for evaluating LLM-based doc- ument reading systems
Anni Zou, Wenhao Yu, Hongming Zhang, Kaixin Ma, Deng Cai, Zhuosheng Zhang, Hai Zhao, and Dong Yu. DocBench: A benchmark for evaluating LLM-based doc- ument reading systems. InInternational Workshop on Knowledge-Augmented Methods for Natural Language Pro- cessing, pages 359–373, 2025. 3
work page 2025
-
[29]
Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer. In arXiv:2004.05150, 2020. 3, 19
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[30]
A simple yet effective layout token in large language models for document understanding
Zhaoqing Zhu, Chuwei Luo, Zirui Shao, Feiyu Gao, Hangdi Xing, Qi Zheng, and Ji Zhang. A simple yet effective layout token in large language models for document understanding. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14472–14482, 2025. 3, 19, 20
work page 2025
-
[31]
Unifying multimodal retrieval via document screenshot embedding
Xueguang Ma, Sheng-Chieh Lin, Minghan Li, Wenhu Chen, and Jimmy Lin. Unifying multimodal retrieval via document screenshot embedding. InConference on Empirical Methods in Natural Language Processing, pages 6492–6505, 2024. 3
work page 2024
-
[32]
Sv-rag: Lora-contextualizing adaptation of mllms for long document understanding
Jian Chen, Ruiyi Zhang, Yufan Zhou, Tong Yu, Franck Der- noncourt, Jiuxiang Gu, Ryan A Rossi, Changyou Chen, and Tong Sun. Sv-rag: Lora-contextualizing adaptation of mllms for long document understanding. InarXiv:2411.01106,
-
[33]
Vdocrag: Retrieval- augmented generation over visually-rich documents
Ryota Tanaka, Taichi Iki, Taku Hasegawa, Kyosuke Nishida, Kuniko Saito, and Jun Suzuki. Vdocrag: Retrieval- augmented generation over visually-rich documents. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24827–24837, 2025. 3, 6, 19, 20
work page 2025
-
[34]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems, volume 30, 2017. 3
work page 2017
-
[35]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, et al. An image is worth 16x16 words: Trans- formers for image recognition at scale. InarXiv:2010.11929,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[36]
Keith Stenning and Michiel Van Lambalgen.Human reason- ing and cognitive science. MIT Press, 2008. 3
work page 2008
-
[37]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richard- son, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card. InarXiv:2412.16720, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing rea- soning capability in llms via reinforcement learning. In arXiv:2501.12948, 2025. 3, 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blis- tein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodal- ity, long context, and next generation agentic capabilities. In arXiv:2507.06261, 2025. 4, 5, 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. InarXiv:2410.21276, 2024. 4, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Li Yujian and Liu Bo. A normalized levenshtein distance metric.IEEE Transactions on Pattern Analysis and Machine Intelligence, 29(6):1091–1095, 2007. 5 10
work page 2007
-
[42]
MM-Eureka: Exploring the Frontiers of Multimodal Reasoning with Rule-based Reinforcement Learning
Fanqing Meng, Lingxiao Du, Zongkai Liu, Zhixiang Zhou, Quanfeng Lu, Daocheng Fu, Tiancheng Han, Botian Shi, Wenhai Wang, Junjun He, et al. Mm-eureka: Exploring the frontiers of multimodal reasoning with rule-based reinforce- ment learning. InarXiv:2503.07365, 2025. 5
work page Pith review arXiv 2025
-
[43]
Cream: coarse-to- fine retrieval and multi-modal efficient tuning for document vqa
Jinxu Zhang, Yongqi Yu, and Yu Zhang. Cream: coarse-to- fine retrieval and multi-modal efficient tuning for document vqa. InACM International Conference on Multimedia, pages 925–934, 2024. 5, 6, 19
work page 2024
-
[44]
Jaemin Cho, Debanjan Mahata, Ozan Irsoy, Yujie He, and Mohit Bansal. M3docrag: Multi-modal retrieval is what you need for multi-page multi-document understanding. In arXiv:2411.04952, 2024. 5, 6, 19
-
[45]
Docopilot: Improving multimodal models for document-level understanding
Yuchen Duan, Zhe Chen, Yusong Hu, Weiyun Wang, Sheng- long Ye, Botian Shi, Lewei Lu, Qibin Hou, Tong Lu, Hong- sheng Li, et al. Docopilot: Improving multimodal models for document-level understanding. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4026– 4037, 2025. 5, 6, 19
work page 2025
-
[46]
Docvlm: Make your vlm an efficient reader
Mor Shpigel Nacson, Aviad Aberdam, Roy Ganz, Elad Ben Avraham, Alona Golts, Yair Kittenplon, Shai Mazor, and Ron Litman. Docvlm: Make your vlm an efficient reader. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 29005–29015, 2025. 5, 6, 19
work page 2025
-
[47]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond. In arXiv:2308.12966, 2023. 6
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of con- text. InarXiv:2403.05530, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
C-Pack: Packed Resources For General Chinese Embeddings
Shitao Xiao, Zheng Liu, Peitian Zhang, and Niklas Muen- nighoff. C-Pack: Packaged resources to advance general chi- nese embedding. InarXiv:2309.07597, 2023. 19
work page internal anchor Pith review arXiv 2023
-
[50]
Dongsheng Wang, Natraj Raman, Mathieu Sibue, Zhiqiang Ma, Petr Babkin, Simerjot Kaur, Yulong Pei, Armineh Nour- bakhsh, and Xiaomo Liu. DocLLM: A layout-aware gener- ative language model for multimodal document understand- ing. InarXiv:2401.00908, 2023. 19, 20 11 APPENDIX A. Details of Data Distillation A.1. Overview of the Distillation Pipeline To addres...
-
[51]
Locate the section: The \"ADJUDICATORY CASES\" section begins on page 3
-
[52]
Count cases on Page 3:- PCB 21-3, PCB 21-5 (One combined entry)- PCB 21-29, -PCB 21-47 (page 3: 3 cases)
-
[53]
Count cases on Page 4: - PCB 21-110 - PCB 21-114 - PCB 22-11…
-
[54]
Sum the counts: 3 (page 3) + 7 (page 4) + 1 (page 5) = 11. Therefore, there are 11 adjudicatory cases listed. </think> <answer> {\"evidence_pages\": [3, 4, 5], \"answer\": \"11\"} </answer> Answer correct but formatting mismatch Flawed reasoning Wrong Answer Question Figure 9. Failure cases in ALR CoT Data Distillation. 17 f Assume that in a survey conduc...
work page 2020
-
[55]
Most Americans see China as having dealt poorly with COVID-19
Analyze …; 2. Scan the document: …3. Locate the relevant chart: I see a bar chart titled “Most Americans see China as having dealt poorly with COVID-19” shows …; 4. Examine the chart's data: The chart has two categories: "Bad" and "Good." … ; 5. Extract the specific numbers: The question states … increased by 10 percentage points. Looking at the chart, th...
-
[56]
OCR-based Methods: These approaches,such as Lay- 19 What position is the man with the red shirt in the figure on the last page, directly answer 'bottom', 'middle' or 'top'? Case Study Answer: bottom Evidence_pages: [77] Evidence_sources: ['Figure’] Question Ground Truth … Page 1 Page 76 Page 77 … Page 40 Baseline Response: The image shows a group of peopl...
-
[57]
RAG-based Methods. To address the limitations of MLLMs in processing ultra-long documents, these meth- ods, such as Vis-RAG [17] and VDocRAG [33], introduce a retriever to select the Top-kmost relevant pages for sub- sequent reasoning
-
[58]
End-to-End Methods. These approaches, such as mPLUG-DocOwl2 [10] and InternVL3 [9], directly encode document images into visual tokens for processing, thereby preserving complete visual features. 20
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.