Recognition: unknown
Detecting and Enhancing Intellectual Humility in Online Political Discourse
Pith reviewed 2026-05-10 14:16 UTC · model grok-4.3
The pith
Intellectual humility can be measured at scale and increased through interventions in online political discussions without reducing engagement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Using a codebook to annotate several hundred Reddit posts for intellectual humility and arrogance, the authors trained and validated a classifier that enables large-scale measurement. Observational analysis of political discussions revealed that environments with more or less humility tend to sustain similar levels in subsequent posts. A randomized control trial then showed that simple nudges can increase expressions of humility across different topics and conversational settings.
What carries the argument
A codebook that breaks intellectual humility and intellectual arrogance into annotatable dimensions, paired with a machine-learning classifier trained on labeled Reddit posts to detect these traits at scale.
Load-bearing premise
The codebook and resulting classifier capture the actual psychological trait of intellectual humility rather than merely surface patterns in the annotated sample.
What would settle it
A new experiment in which participants given the humility prompts show no measurable rise in willingness to consider opposing views or revise their positions when tested in follow-up discussions.
Figures








read the original abstract
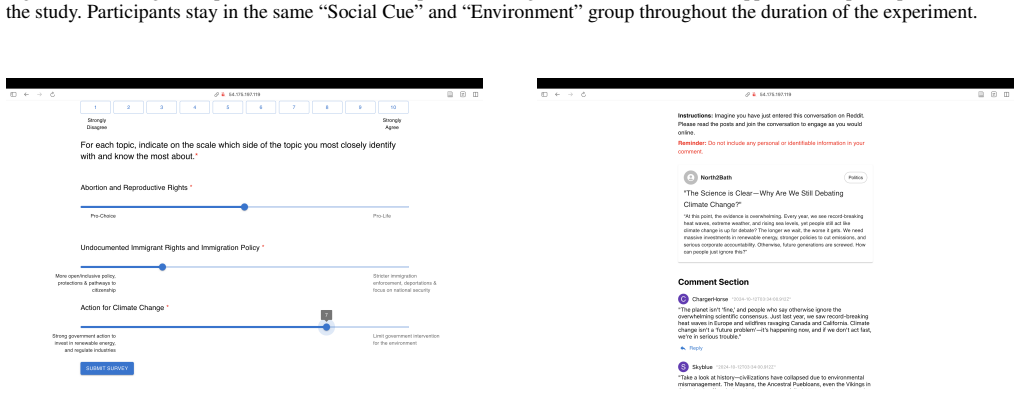
Intellectual humility (IH)-a recognition of one's own intellectual limitations-can reduce polarization and foster more understanding across lines of difference. Yet little work explores how IH can be systematically defined, measured, evaluated, and enhanced in spaces that often lack it the most: online political discussions. In this paper, we seek to bridge these gaps by exploring two questions: 1) how might preexisting levels of IH influence future expressions of IH during online political discourse? and 2) can online interventions enhance IH across different political topics and conversational environments? To pursue these questions, we define a codebook characterizing different dimensions of IH and intellectual arrogance (IA) and have researchers use it to annotate several hundred Reddit posts, which we then use to develop and validate a classifier to support IH analysis at scale. These tools subsequently enable two key contributions: i) an observational data analysis of how IH varies across different political discussions on Reddit, which reveals that more/less IH environments tend to contain future posts of a similar nature, and ii) a randomized control trial evaluating strategies for nudging discussion participants to demonstrate more IH in their posts, which reveals the possibility of enhancing IH in online discussions across a range of contentious topics. Our findings highlight the possibility of measuring and increasing IH online without necessarily reducing engagement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper defines a codebook for dimensions of intellectual humility (IH) and intellectual arrogance (IA), has researchers annotate several hundred Reddit posts from political discussions, trains and validates a classifier on these annotations, performs an observational analysis showing that IH levels persist across posts in the same discussion environments, and conducts a randomized controlled trial testing interventions to increase IH expression without reducing engagement. The central claims are that preexisting IH influences future expressions and that online nudges can enhance IH across topics.
Significance. If the classifier and codebook validly operationalize the psychological construct of IH (rather than surface linguistic features), the work offers a scalable measurement tool and evidence that IH can be increased in contentious online spaces without engagement costs. The combination of observational persistence findings and an RCT intervention is a methodological strength for computational social science on polarization. However, the absence of reported validation metrics means the practical significance cannot yet be assessed.
major comments (3)
- [Annotation and classifier validation] Annotation and classifier validation section: the manuscript states that researchers annotated several hundred Reddit posts to train and validate a classifier, but reports no inter-annotator agreement statistics (e.g., Cohen's kappa or Krippendorff's alpha) and no classifier performance metrics (precision, recall, F1, or confusion matrices). All subsequent observational and RCT results are interpreted through this classifier; without these numbers it is impossible to determine whether the tool captures the intended IH construct or merely annotator-specific lexical patterns in the Reddit sample.
- [RCT evaluation] RCT section: the trial claims interventions enhance IH across topics and environments, yet the abstract and visible description provide no details on per-condition sample sizes, effect sizes, handling of post-hoc exclusions, or whether the classifier was applied blindly to intervention vs. control posts. These omissions are load-bearing because the enhancement claim rests entirely on classifier-assigned IH scores.
- [Observational data analysis] Observational analysis section: the persistence result (more/less IH environments contain future posts of similar nature) is presented as evidence that IH levels influence future expressions, but without reporting the exact time windows, discussion-thread definitions, or robustness checks against topic confounds, it is unclear whether the pattern reflects genuine carry-over of IH or stable topic/participant effects.
minor comments (2)
- [Abstract] The abstract would benefit from stating the exact number of annotated posts, the classifier's reported performance, and the RCT sample size to allow readers to gauge scale immediately.
- [Codebook definition] Notation for IH vs. IA dimensions in the codebook could be clarified with an explicit table mapping each dimension to example annotations.
Simulated Author's Rebuttal
Thank you for the detailed and constructive feedback on our manuscript. We appreciate the opportunity to clarify and strengthen our presentation of the methods and results. Below, we respond point-by-point to the major comments, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Annotation and classifier validation] Annotation and classifier validation section: the manuscript states that researchers annotated several hundred Reddit posts to train and validate a classifier, but reports no inter-annotator agreement statistics (e.g., Cohen's kappa or Krippendorff's alpha) and no classifier performance metrics (precision, recall, F1, or confusion matrices). All subsequent observational and RCT results are interpreted through this classifier; without these numbers it is impossible to determine whether the tool captures the intended IH construct or merely annotator-specific lexical patterns in the Reddit sample.
Authors: We acknowledge that the current version of the manuscript does not include the inter-annotator agreement statistics or detailed classifier performance metrics. This was an oversight in our reporting. In the revised manuscript, we will add a dedicated subsection or expand the existing section to report Cohen's kappa (or Krippendorff's alpha) for the annotations, as well as precision, recall, F1 scores, and confusion matrices for the classifier. These metrics will help demonstrate that the classifier reliably captures the intended dimensions of intellectual humility rather than superficial patterns. revision: yes
-
Referee: [RCT evaluation] RCT section: the trial claims interventions enhance IH across topics and environments, yet the abstract and visible description provide no details on per-condition sample sizes, effect sizes, handling of post-hoc exclusions, or whether the classifier was applied blindly to intervention vs. control posts. These omissions are load-bearing because the enhancement claim rests entirely on classifier-assigned IH scores.
Authors: We agree that providing these details is crucial for evaluating the RCT results. In the revision, we will include the per-condition sample sizes, report effect sizes (e.g., Cohen's d or appropriate measures), describe how post-hoc exclusions were handled (if any), and explicitly state that the classifier was applied in a blinded manner to the posts from different conditions. We will also update the abstract to reference these key methodological details where space permits. revision: yes
-
Referee: [Observational data analysis] Observational analysis section: the persistence result (more/less IH environments contain future posts of similar nature) is presented as evidence that IH levels influence future expressions, but without reporting the exact time windows, discussion-thread definitions, or robustness checks against topic confounds, it is unclear whether the pattern reflects genuine carry-over of IH or stable topic/participant effects.
Authors: We will clarify these aspects in the revised manuscript. Specifically, we will specify the exact time windows used for the observational analysis, provide precise definitions of discussion threads, and include additional robustness checks (such as controlling for topic via fixed effects or topic modeling) to address potential confounds. This will strengthen the interpretation that the observed persistence reflects carry-over effects of IH levels. revision: yes
Circularity Check
No circularity: empirical pipeline relies on external annotations and RCT design
full rationale
The paper's core contributions are an annotation codebook drawn from prior psychological literature, human labeling of Reddit posts, training of a downstream classifier on those labels, an observational analysis of persistence in IH levels, and an RCT testing interventions. None of these steps reduce a claimed prediction or result to its own fitted outputs by construction. The classifier is validated against held-out human annotations rather than self-generated labels, and the RCT compares treatment arms against a control using the classifier as a measurement tool. No self-citation chains, uniqueness theorems, or ansatzes are invoked to force the central claims. The work is self-contained against external benchmarks (human annotations and randomized assignment) and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The codebook dimensions faithfully represent the psychological construct of intellectual humility.
- domain assumption The randomized prompts constitute a clean intervention that does not alter engagement or topic selection in ways that confound humility measurement.
Reference graph
Works this paper leans on
-
[1]
BERTopic: Neural topic modeling with a class-based TF-IDF procedure
A survey of expert views on misinformation: Defini- tions, determinants, solutions, and future of the field.Har- vard Kennedy School Misinformation Review. Argyle, L. P.; Bail, C. A.; Busby, E. C.; Gubler, J. R.; Howe, T.; Rytting, C.; Sorensen, T.; and Wingate, D. 2023. Lever- aging AI for democratic discourse: Chat interventions can improve online polit...
work page internal anchor Pith review arXiv 2023
-
[2]
Publisher: Annual Reviews. Jia, C.; Lam, M. S.; Mai, M. C.; Hancock, J.; and Bernstein, M. S. 2024. Embedding Democratic Values into Social Me- dia AIs via Societal Objective Functions.Proceedings of the ACM on Human-Computer Interaction, 8(CSCW1): 1–36. Jigsaw. 2017. Perspective API. Katsaros, M.; Yang, K.; and Fratamico, L. 2021. Reconsid- ering Tweets:...
-
[3]
Muradova, L.; and Arceneaux, K
The Impact of Generative AI on Social Media: An Experimental Study.arXiv preprint arXiv:2506.14295. Muradova, L.; and Arceneaux, K. 2022. Reflective political reasoning: Political disagreement and empathy.European Journal of Political Research, 61(3): 740–761. Niu, A.; Gao, C.; and Yu, C. 2025. The Influence of Intel- lectual Humility in External Successo...
-
[4]
Publisher: Public Library of Science
Modeling the emergence of affective polarization in the social media society.PLOS ONE, 16(10): e0258259. Publisher: Public Library of Science. van Loon, A.; Katta, S.; Bail, C.; Hillygus, S.; and V ol- fovsky, A. 2024. Designing Social Media to Promote Pro- ductive Political Dialogue on a New Research Platform. Vicario, D.; Bessi; Zollo; Petroni; Scala; C...
2024
-
[5]
For most authors... (a) Would answering this research question advance sci- ence without violating social contracts, such as violat- ing privacy norms, perpetuating unfair profiling, exac- erbating the socio-economic divide, or implying disre- spect to societies or cultures? Yes (b) Do your main claims in the abstract and introduction accurately reflect t...
-
[6]
Additionally, if your study involves hypotheses testing... (a) Did you clearly state the assumptions underlying all theoretical results? Yes (b) Have you provided justifications for all theoretical re- sults? Yes (c) Did you discuss competing hypotheses or theories that might challenge or complement your theoretical re- sults? Yes (d) Have you considered ...
-
[7]
(a) Did you state the full set of assumptions of all theoret- ical results? N/A (b) Did you include complete proofs of all theoretical re- sults? N/A
Additionally, if you are including theoretical proofs... (a) Did you state the full set of assumptions of all theoret- ical results? N/A (b) Did you include complete proofs of all theoretical re- sults? N/A
-
[8]
Additionally, if you ran machine learning experiments... (a) Did you include the code, data, and instructions needed to reproduce the main experimental results (ei- ther in the supplemental material or as a URL)? No — these will be finalized following anonymous peer review. (b) Did you specify all the training details (e.g., data splits, hyperparameters, ...
-
[9]
Additionally, if you are using existing assets (e.g., code, data, models) or curating/releasing new assets... (a) If your work uses existing assets, did you cite the cre- ators? Yes (b) Did you mention the license of the assets? N/A (c) Did you include any new assets in the supplemental material or as a URL? Yes (d) Did you discuss whether and how consent...
-
[10]
us vs. them
Additionally, if you used crowdsourcing or conducted re- search with human subjects... (a) Did you include the full text of instructions given to participants and screenshots? Yes (b) Did you describe any potential participant risks, with mentions of Institutional Review Board (IRB) ap- provals? Yes (c) Did you include the estimated hourly wage paid to pa...
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.