Recognition: unknown
Challenging Vision-Language Models with Physically Deployable Multimodal Semantic Lighting Attacks
Pith reviewed 2026-05-10 15:55 UTC · model grok-4.3
The pith
Controllable adversarial lighting provides the first physically realizable attacks that disrupt semantic alignment in vision-language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
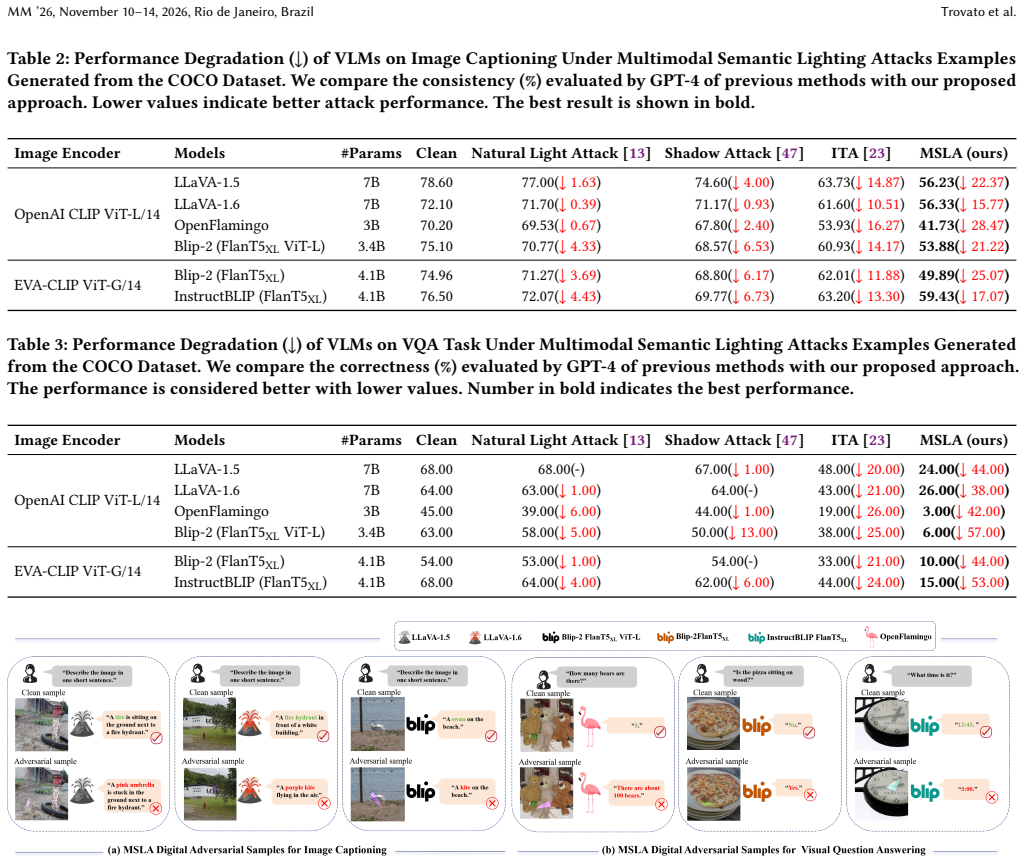
MSLA is the first physically deployable adversarial attack framework against VLMs. It employs controllable adversarial lighting to disrupt multimodal semantic understanding in real scenes by attacking semantic alignment rather than only task-specific outputs. This degrades zero-shot classification performance of mainstream CLIP variants while inducing severe semantic hallucinations in advanced VLMs such as LLaVA and BLIP across image captioning and visual question answering tasks. Extensive experiments in both digital and physical domains demonstrate that MSLA is effective, transferable, and practically realizable.
What carries the argument
Multimodal Semantic Lighting Attacks (MSLA), a framework that generates controllable adversarial lighting patterns to target and break the semantic alignment between visual inputs and language representations in VLMs.
If this is right
- Zero-shot classification accuracy drops in CLIP-based models when exposed to the lighting patterns.
- Advanced VLMs such as LLaVA and BLIP produce semantic hallucinations during captioning and VQA under the same physical attacks.
- The attacks transfer across different VLM architectures and remain effective when moved from digital simulation to physical realization.
- Standard robustness evaluations limited to digital perturbations miss this class of real-world semantic threats.
Where Pith is reading between the lines
- Any real-world VLM deployment that relies on natural or ambient lighting may need explicit testing against deliberate illumination changes.
- Camera preprocessing pipelines could be modified to detect or neutralize the specific spatial-frequency signatures of these lighting patterns.
- Similar lighting-based interference might affect other multimodal systems that combine vision with language or other sensors.
- Physical-world robustness benchmarks for VLMs should include controllable environmental variables such as lighting as a standard test axis.
Load-bearing premise
Adversarial lighting patterns can be generated and realized with enough precision in uncontrolled physical environments that the resulting camera images reliably reach the model with the intended semantic disruption.
What would settle it
A controlled physical trial in which the proposed lighting patterns are projected onto real scenes yet the target VLMs produce accurate classifications, captions, and VQA answers with no measurable degradation or hallucinations.
Figures







read the original abstract
Vision-Language Models (VLMs) have shown remarkable performance, yet their security remains insufficiently understood. Existing adversarial studies focus almost exclusively on the digital setting, leaving physical-world threats largely unexplored. As VLMs are increasingly deployed in real environments, this gap becomes critical, since adversarial perturbations must be physically realizable. Despite this practical relevance, physical attacks against VLMs have not been systematically studied. Such attacks may induce recognition failures and further disrupt multimodal reasoning, leading to severe semantic misinterpretation in downstream tasks. Therefore, investigating physical attacks on VLMs is essential for assessing their real-world security risks. To address this gap, we propose Multimodal Semantic Lighting Attacks (MSLA), the first physically deployable adversarial attack framework against VLMs. MSLA uses controllable adversarial lighting to disrupt multimodal semantic understanding in real scenes, attacking semantic alignment rather than only task-specific outputs. Consequently, it degrades zero-shot classification performance of mainstream CLIP variants while inducing severe semantic hallucinations in advanced VLMs such as LLaVA and BLIP across image captioning and visual question answering (VQA). Extensive experiments in both digital and physical domains demonstrate that MSLA is effective, transferable, and practically realizable. Our findings provide the first evidence that VLMs are highly vulnerable to physically deployable semantic attacks, exposing a previously overlooked robustness gap and underscoring the urgent need for physical-world robustness evaluation of VLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Multimodal Semantic Lighting Attacks (MSLA), the first physically deployable adversarial attack framework against Vision-Language Models (VLMs). It uses controllable adversarial lighting to disrupt multimodal semantic understanding in real scenes, degrading zero-shot classification performance in CLIP variants and inducing semantic hallucinations in models such as LLaVA and BLIP for image captioning and VQA tasks. The central claims of effectiveness, transferability across models, and practical realizability rest on extensive digital and physical experiments.
Significance. If the physical experiments hold, this would be a notable contribution as the first systematic study of physically realizable semantic attacks on VLMs, exposing a robustness gap in models increasingly deployed in real-world settings. The empirical focus on semantic alignment (rather than task-specific outputs) and the inclusion of physical deployment experiments are strengths that could inform future robustness evaluations.
major comments (3)
- [Physical Experiments] Physical Experiments section (likely §5 or equivalent): The central claim that MSLA perturbations remain effective after physical capture and standard camera preprocessing lacks sufficient controls and quantitative reporting (e.g., success rates with error bars, ablation on environmental factors like ambient light or camera models). This is load-bearing for the 'practically realizable' assertion and transferability results.
- [Results and Evaluation] Results and Evaluation section: No baseline comparisons are provided against prior physical adversarial attacks (e.g., patch-based or lighting-based methods from the literature) or digital-only attacks, making it difficult to assess the incremental improvement or novelty of the semantic lighting approach over existing work.
- [Method] Method section (likely §3 or §4): The optimization procedure for generating lighting perturbations is described at a high level but lacks specifics on the objective function, constraints for physical realizability (e.g., hardware limits on light intensity or spectrum), and how semantic alignment is explicitly targeted in the loss, which is central to the multimodal attack claim.
minor comments (3)
- [Figures] Figure captions and legends could be expanded to include exact experimental conditions (e.g., lighting hardware, distance, angle) for reproducibility.
- [Abstract/Introduction] The abstract and introduction claim 'extensive experiments' but the text would benefit from a summary table aggregating key metrics (accuracy drops, hallucination rates) across models and settings.
- [Method] Notation for lighting parameters (e.g., intensity, color channels) should be defined consistently in the method and used in equations.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We appreciate the opportunity to address the concerns raised and strengthen the presentation of our work on MSLA. Below we respond point-by-point to the major comments, indicating the revisions we will incorporate.
read point-by-point responses
-
Referee: [Physical Experiments] Physical Experiments section (likely §5 or equivalent): The central claim that MSLA perturbations remain effective after physical capture and standard camera preprocessing lacks sufficient controls and quantitative reporting (e.g., success rates with error bars, ablation on environmental factors like ambient light or camera models). This is load-bearing for the 'practically realizable' assertion and transferability results.
Authors: We agree that expanded quantitative reporting and additional controls would better substantiate the physical realizability claims. In the revised manuscript we will report success rates with standard error bars across repeated physical trials. We will also add ablations examining the effects of varying ambient light levels and different camera models. These additions will directly address the load-bearing aspects of the physical experiments while preserving the existing experimental design. revision: yes
-
Referee: [Results and Evaluation] Results and Evaluation section: No baseline comparisons are provided against prior physical adversarial attacks (e.g., patch-based or lighting-based methods from the literature) or digital-only attacks, making it difficult to assess the incremental improvement or novelty of the semantic lighting approach over existing work.
Authors: We acknowledge that explicit baseline comparisons are necessary to contextualize the novelty and incremental gains of MSLA. In the revised version we will include comparisons against representative prior physical attacks (patch-based and lighting-based) as well as digital-only adversarial methods on VLMs. These will be presented in terms of semantic disruption, cross-model transferability, and physical deployability to clarify the advantages of targeting multimodal semantic alignment via controllable lighting. revision: yes
-
Referee: [Method] Method section (likely §3 or §4): The optimization procedure for generating lighting perturbations is described at a high level but lacks specifics on the objective function, constraints for physical realizability (e.g., hardware limits on light intensity or spectrum), and how semantic alignment is explicitly targeted in the loss, which is central to the multimodal attack claim.
Authors: We will expand the Method section to include the precise mathematical formulation of the objective function, the explicit constraints used to enforce physical realizability (including hardware-specific bounds on intensity and spectrum), and the mechanism by which the loss directly targets disruption of semantic alignment between visual and textual embeddings. These details are central to the contribution and we thank the referee for highlighting the need for greater specificity. revision: yes
Circularity Check
No significant circularity; empirical demonstration only
full rationale
The paper presents an empirical attack framework (MSLA) supported by digital and physical experiments rather than any mathematical derivation chain. No equations, fitted parameters, self-referential definitions, or load-bearing self-citations appear in the abstract or described structure. The central claims rest on experimental results showing effectiveness and realizability, which are externally falsifiable and do not reduce to the inputs by construction. This is the standard case of a self-contained empirical proposal with no circularity.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Multimodal Semantic Lighting Attacks (MSLA)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Sani Abba, Ali Mohammed Bizi, Jeong-A Lee, Souley Bakouri, and Maria Liz Crespo. 2024. Real-time object detection, tracking, and monitoring framework for security surveillance systems.Heliyon10, 15 (2024)
2024
-
[2]
Haider Al-Tahan, Quentin Garrido, Randall Balestriero, Diane Bouchacourt, Caner Hazirbas, and Mark Ibrahim. 2024. Unibench: Visual reasoning requires rethink- ing vision-language beyond scaling.Advances in Neural Information Processing Systems37 (2024), 82411–82437
2024
-
[3]
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al
-
[4]
Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems35 (2022), 23716–23736
2022
-
[5]
Anas Awadalla, Irena Gao, Josh Gardner, Jack Hessel, Yusuf Hanafy, Wanrong Zhu, Kalyani Marathe, Yonatan Bitton, Samir Gadre, Shiori Sagawa, et al. 2023. Openflamingo: An open-source framework for training large autoregressive vision-language models.arXiv preprint arXiv:2308.01390(2023)
work page internal anchor Pith review arXiv 2023
-
[6]
Xinlei Chen, Hao Fang, Tsung-Yi Lin, Ramakrishna Vedantam, Saurabh Gupta, Pi- otr Dollár, and C Lawrence Zitnick. 2015. Microsoft coco captions: Data collection and evaluation server.arXiv preprint arXiv:1504.00325(2015)
work page internal anchor Pith review arXiv 2015
-
[7]
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al . 2024. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 24185–24198
2024
-
[8]
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuhmann, Ludwig Schmidt, and Jenia Jitsev
-
[9]
In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Reproducible scaling laws for contrastive language-image learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2818–2829
-
[10]
Xuanming Cui, Alejandro Aparcedo, Young Kyun Jang, and Ser-Nam Lim. 2024. On the robustness of large multimodal models against image adversarial at- tacks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 24625–24634
2024
-
[11]
Ranjie Duan, Xiaofeng Mao, A. K. Qin, Yuefeng Chen, Shaokai Ye, Yuan He, and Yun Yang. 2021. Adversarial Laser Beam: Effective Physical-World Attack to DNNs in a Blink. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 16062–16071
2021
-
[12]
Junbin Fang, You Jiang, Canjian Jiang, Zoe L Jiang, Chuanyi Liu, and Siu-Ming Yiu. 2024. State-of-the-art optical-based physical adversarial attacks for deep learning computer vision systems.Expert Systems with Applications250 (2024), 123761
2024
-
[13]
Abhiram Gnanasambandam, Alex M Sherman, and Stanley H Chan. 2021. Optical adversarial attack. InProceedings of the IEEE/CVF international conference on computer vision. 92–101
2021
-
[14]
John H Holland. 1992. Genetic algorithms.Scientific american267, 1 (1992), 66–73
1992
-
[15]
Teng-Fang Hsiao, Bo-Lun Huang, Zi-Xiang Ni, Yan-Ting Lin, Hong-Han Shuai, Yung-Hui Li, and Wen-Huang Cheng. 2024. Natural light can also be danger- ous: Traffic sign misinterpretation under adversarial natural light attacks. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 3915–3924
2024
-
[16]
Bingyao Huang and Haibin Ling. 2022. Spaa: Stealthy projector-based adversarial attacks on deep image classifiers. In2022 IEEE Conference on Virtual Reality and 3D User Interfaces (VR). IEEE, 534–542
2022
-
[17]
Gabriel Ilharco, Mitchell Wortsman, Nicholas Carlini, Rohan Anil, Matthias Minderer, Xiaohua Zhai, Alexey Dosovitskiy, Lucas Beyer, Kunal Talwar, Andreas Steiner, et al. 2021. OpenCLIP: An open source implementation of CLIP.GitHub repository(2021)
2021
-
[18]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning. PMLR, 19730–19742
2023
-
[19]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. 2022. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InInternational conference on machine learning. PMLR, 12888–12900
2022
-
[20]
Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, and Kai-Wei Chang
-
[21]
H., Yatskar, M., Yin, D., Hsieh, C., and Chang, K
Visualbert: A simple and performant baseline for vision and language. arXiv preprint arXiv:1908.03557(2019)
-
[22]
Daizong Liu, Mingyu Yang, Xiaoye Qu, Pan Zhou, Yu Cheng, and Wei Hu. 2025. A survey of attacks on large vision–language models: Resources, advances, and future trends.IEEE Transactions on Neural Networks and Learning Systems(2025)
2025
-
[23]
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. 2024. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 26296–26306
2024
-
[24]
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. 2024. Llavanext: Improved reasoning, ocr, and world knowledge
2024
-
[25]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual in- struction tuning.Advances in neural information processing systems36 (2023), 34892–34916
2023
-
[26]
Hanqing Liu, Shouwei Ruan, Yao Huang, Shiji Zhao, and Xingxing Wei. 2025. When Lighting Deceives: Exposing Vision-Language Models’ Illumination Vul- nerability Through Illumination Transformation Attack. InProceedings of the IEEE/CVF International Conference on Computer Vision. 10485–10495
2025
-
[27]
Jiasen Lu, Dhruv Batra, Devi Parikh, and Stefan Lee. 2019. Vilbert: Pretrain- ing task-agnostic visiolinguistic representations for vision-and-language tasks. Advances in neural information processing systems32 (2019)
2019
- [28]
-
[29]
Tianrui Qin, Xuan Wang, Juanjuan Zhao, Kejiang Ye, Cheng-zhong Xu, and Xitong Gao. 2025. On the Adversarial Robustness of Visual-Language Chat Models. InProceedings of the 2025 International Conference on Multimedia Retrieval. 1118–1127
2025
-
[30]
Jingxiang Qu, Ryan Wen Liu, Yuan Gao, Yu Guo, Fenghua Zhu, and Fei-Yue Wang. 2024. Double domain guided real-time low-light image enhancement for ultra-high-definition transportation surveillance.IEEE Transactions on Intelligent Transportation Systems25, 8 (2024), 9550–9562
2024
-
[31]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. InInternational conference on machine learning. PmLR, 8748–8763
2021
-
[32]
Shouwei Ruan, Yinpeng Dong, Hanqing Liu, Yao Huang, Hang Su, and Xingxing Wei. 2024. Omniview-tuning: Boosting viewpoint invariance of vision-language pre-training models. InEuropean Conference on Computer Vision. Springer, 309– 327
2024
-
[33]
Shouwei Ruan, Yinpeng Dong, Hang Su, Jianteng Peng, Ning Chen, and Xingx- ing Wei. 2023. Towards viewpoint-invariant visual recognition via adversarial training. InProceedings of the IEEE/CVF International Conference on Computer Vision. 4709–4719
2023
-
[34]
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. 2022. Laion-5b: An open large-scale dataset for training next generation image-text models.Advances in neural information processing systems 35 (2022), 25278–25294
2022
-
[35]
Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedan- tam, Devi Parikh, and Dhruv Batra. 2017. Grad-cam: Visual explanations from deep networks via gradient-based localization. InProceedings of the IEEE interna- tional conference on computer vision. 618–626
2017
-
[36]
Quan Sun, Yuxin Fang, Ledell Wu, Xinlong Wang, and Yue Cao. 2023. Eva-clip: Improved training techniques for clip at scale.arXiv preprint arXiv:2303.15389 (2023)
work page internal anchor Pith review arXiv 2023
-
[37]
Yitong Sun, Yao Huang, and Xingxing Wei. 2024. Embodied laser attack: Leverag- ing scene priors to achieve agent-based robust non-contact attacks. InProceedings of the 32nd ACM International Conference on Multimedia. 5902–5910
2024
-
[38]
Xiaoyu Tian, Junru Gu, Bailin Li, Yicheng Liu, Yang Wang, Zhiyong Zhao, Kun Zhan, Peng Jia, Xianpeng Lang, and Hang Zhao. 2024. Drivevlm: The conver- gence of autonomous driving and large vision-language models.arXiv preprint arXiv:2402.12289(2024)
work page internal anchor Pith review arXiv 2024
-
[39]
Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie. 2024. Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 9568–9578
2024
-
[40]
Donghua Wang, Wen Yao, Tingsong Jiang, Chao Li, and Xiaoqian Chen. 2023. Rfla: A stealthy reflected light adversarial attack in the physical world. InProceedings of the IEEE/CVF international conference on computer vision. 4455–4465
2023
- [41]
- [42]
- [43]
-
[44]
Ziyi Yin, Muchao Ye, Tianrong Zhang, Tianyu Du, Jinguo Zhu, Han Liu, Jinghui Chen, Ting Wang, and Fenglong Ma. 2023. Vlattack: Multimodal adversarial attacks on vision-language tasks via pre-trained models.Advances in Neural Information Processing Systems36 (2023), 52936–52956
2023
-
[45]
Jiaming Zhang, Qi Yi, and Jitao Sang. 2022. Towards adversarial attack on vision-language pre-training models. InProceedings of the 30th ACM International Conference on Multimedia. 5005–5013
2022
-
[46]
Tianyuan Zhang, Lu Wang, Xinwei Zhang, Yitong Zhang, Boyi Jia, Siyuan Liang, Shengshan Hu, Qiang Fu, Aishan Liu, and Xianglong Liu. 2024. Visual adver- sarial attack on vision-language models for autonomous driving.arXiv preprint arXiv:2411.18275(2024). MM ’26, November 10–14, 2026, Rio de Janeiro, Brazil Trovato et al
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Yichi Zhang, Yao Huang, Yitong Sun, Chang Liu, Zhe Zhao, Zhengwei Fang, Yifan Wang, Huanran Chen, Xiao Yang, Xingxing Wei, Hang Su, Yinpeng Dong, and Jun Zhu. 2024. MultiTrust: A Comprehensive Benchmark Towards Trustworthy Multimodal Large Language Models. InAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U...
2024
-
[48]
Yunqing Zhao, Tianyu Pang, Chao Du, Xiao Yang, Chongxuan Li, Ngai-Man Man Cheung, and Min Lin. 2023. On evaluating adversarial robustness of large vision- language models.Advances in Neural Information Processing Systems36 (2023), 54111–54138
2023
-
[49]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems36 (2023), 46595–46623
2023
-
[50]
Yiqi Zhong, Xianming Liu, Deming Zhai, Junjun Jiang, and Xiangyang Ji. 2022. Shadows can be dangerous: Stealthy and effective physical-world adversarial attack by natural phenomenon. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 15345–15354
2022
-
[51]
Luowei Zhou, Hamid Palangi, Lei Zhang, Houdong Hu, Jason Corso, and Jianfeng Gao. 2020. Unified vision-language pre-training for image captioning and vqa. In Proceedings of the AAAI conference on artificial intelligence, Vol. 34. 13041–13049
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.