Recognition: unknown
TCL: Enabling Fast and Efficient Cross-Hardware Tensor Program Optimization via Continual Learning
Pith reviewed 2026-05-10 15:42 UTC · model grok-4.3
The pith
TCL speeds up tensor program tuning by over 12x on CPU and GPU while improving inference latency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TCL is a compiler framework for cross-hardware tensor program optimization built on an RDU Sampler that selects only 10 percent of programs while preserving cost-model accuracy, a Mamba-based cost model that models long-range dependencies efficiently, and a continuous knowledge distillation method that transfers knowledge progressively across platforms; together these components deliver substantially faster tuning and modestly better inference latency than Tenset-MLP on both CPU and GPU.
What carries the argument
The RDU Sampler, which jointly scores tensor programs for representativeness, diversity, and uncertainty to enable data-efficient active learning that trains accurate cost models from far fewer examples.
If this is right
- Tuning time drops by roughly 16x on CPU and 12x on GPU for typical deep learning models.
- Final optimized programs run with 13-20 percent lower latency than those produced by the prior Tenset-MLP baseline.
- Data collection cost for cost-model training falls to roughly one-tenth of previous requirements.
- Knowledge can be transferred to new hardware platforms without retraining from scratch or suffering parameter explosion.
- The same three-component structure supports progressive improvement as additional hardware targets are encountered.
Where Pith is reading between the lines
- The continual-distillation design may allow incremental updates when entirely new hardware families appear without discarding prior knowledge.
- Because only a small program subset is needed, the approach could be applied in resource-constrained environments such as edge-device optimization loops.
- The method's emphasis on uncertainty sampling suggests it could be combined with online feedback from actual hardware runs to further refine the cost model over time.
Load-bearing premise
Selecting only 10 percent of tensor programs with the RDU criteria keeps the cost model's accuracy close enough to the full-data version that optimization quality does not degrade on new programs or platforms.
What would settle it
Train the cost model once on the full dataset and once on the RDU-selected 10 percent subset, then compare both the prediction error on held-out tensor programs and the final tuned inference latency; a large gap in either metric would falsify the efficiency claim.
Figures


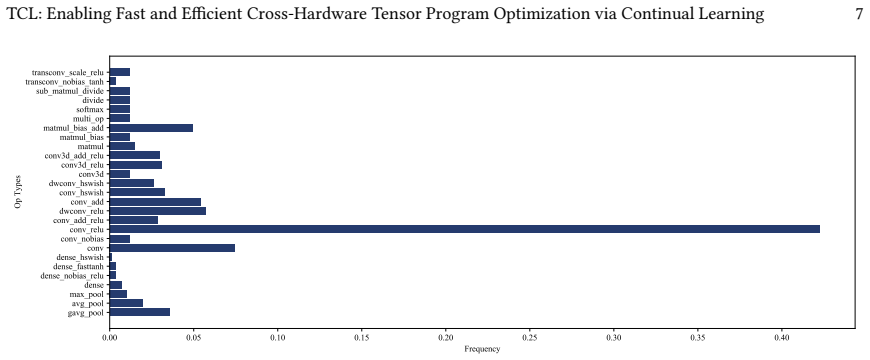



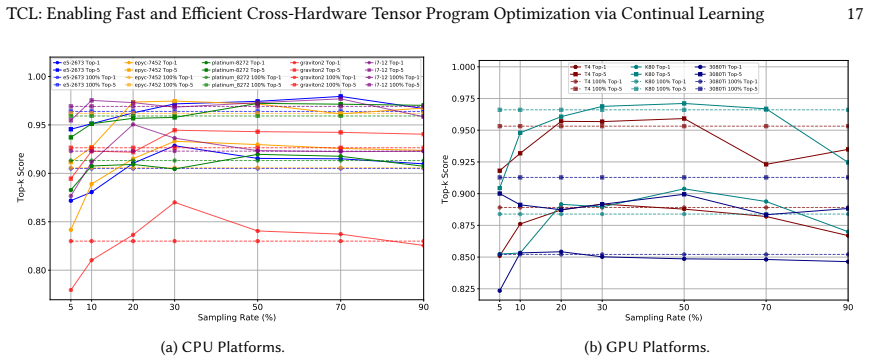

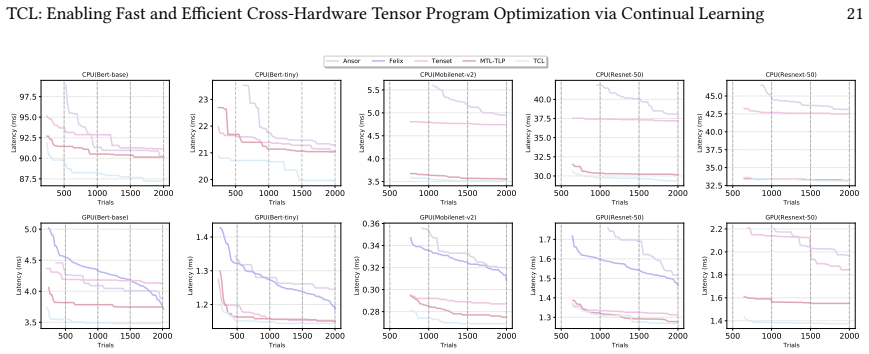




read the original abstract
Deep learning (DL) compilers rely on cost models and auto-tuning to optimize tensor programs for target hardware. However, existing approaches depend on large offline datasets, incurring high collection costs and offering suboptimal transferability across platforms. In this paper, we introduce TCL, a novel efficient and transferable compiler framework for fast tensor program optimization across diverse hardware platforms to address these challenges. Specifically, TCL is built on three core enablers: (1) the RDU Sampler, a data-efficient active learning strategy that selects only 10% of tensor programs by jointly optimizing Representativeness, Diversity, and Uncertainty, substantially reducing data collection costs while maintaining near-original model accuracy; (2) a new Mamba-based cost model that efficiently captures long-range schedule dependencies while achieving a favorable trade-off between prediction accuracy and computational cost through reduced parameterization and lightweight sequence modeling; and (3) a continuous knowledge distillation framework that effectively and progressively transfers knowledge across multiple hardware platforms while avoiding the parameter explosion and data dependency issues typically caused by traditional multi-task learning. Extensive experiments validate the effectiveness of each individual enabler and the holistic TCL framework. When optimizing a range of mainstream DL models on both CPU and GPU platforms, TCL achieves, on average, 16.8x and 12.48x faster tuning time, and 1.20x and 1.13x lower inference latency, respectively, compared to Tenset-MLP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TCL, a framework for efficient cross-hardware tensor program optimization in deep learning compilers. It consists of three main components: the RDU Sampler for selecting only 10% of tensor programs using representativeness, diversity, and uncertainty to reduce data collection costs while preserving accuracy; a Mamba-based cost model for efficient long-range dependency capture with reduced parameterization; and a continuous knowledge distillation approach for progressive knowledge transfer across hardware platforms. The paper reports that on mainstream DL models for CPU and GPU, TCL achieves 16.8x and 12.48x faster tuning time, and 1.20x and 1.13x lower inference latency compared to Tenset-MLP.
Significance. If the empirical results hold under rigorous validation, TCL could meaningfully advance DL compiler optimization by reducing the high costs of offline data collection and improving transferability across hardware. The combination of active learning sampling, lightweight sequence modeling via Mamba, and continual distillation targets practical bottlenecks in auto-tuning, with potential for broader adoption if the speedups and latency gains prove robust.
major comments (2)
- [Abstract] The central tuning-time claims (16.8× on CPU, 12.48× on GPU) rest on the RDU sampler's 10% selection preserving near-original cost-model accuracy. The abstract asserts this but supplies no quantitative bounds (MAPE, Kendall-τ, or similar) on held-out programs or unseen hardware platforms, nor an ablation isolating sampler-induced ranking errors from the Mamba and distillation components. Without these, it is impossible to confirm that the reported latency gains are not eroded by mis-ranked candidates.
- [Experiments] The abstract presents concrete average speedups and latency reductions but omits all details on statistical significance, run-to-run variance, data splits, or ablation controls. This absence directly affects the soundness of the cross-hardware performance assertions and prevents assessment of whether the gains are reliable or platform-specific artifacts.
minor comments (1)
- [Abstract] The baseline 'Tenset-MLP' is referenced without a brief description or citation; adding one sentence would improve readability for readers unfamiliar with the prior work.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The two major comments identify areas where additional quantitative detail and statistical rigor would strengthen the presentation of our results. We address each point below and commit to revisions that directly incorporate the requested information without altering the core claims or methodology.
read point-by-point responses
-
Referee: [Abstract] The central tuning-time claims (16.8× on CPU, 12.48× on GPU) rest on the RDU sampler's 10% selection preserving near-original cost-model accuracy. The abstract asserts this but supplies no quantitative bounds (MAPE, Kendall-τ, or similar) on held-out programs or unseen hardware platforms, nor an ablation isolating sampler-induced ranking errors from the Mamba and distillation components. Without these, it is impossible to confirm that the reported latency gains are not eroded by mis-ranked candidates.
Authors: We agree that the abstract would be improved by explicit quantitative bounds on the RDU sampler. The current abstract summarizes end-to-end outcomes but does not report MAPE, Kendall-τ, or a dedicated isolation ablation. In the revised manuscript we will add a concise statement to the abstract citing the sampler's held-out Kendall-τ (reported in Section 4.2) and will insert a new ablation table in the experiments section that isolates the sampler's contribution to final ranking quality and latency from the Mamba cost model and distillation stages. These additions will allow readers to verify that any sampler-induced ranking discrepancies do not materially erode the reported speedups. revision: yes
-
Referee: [Experiments] The abstract presents concrete average speedups and latency reductions but omits all details on statistical significance, run-to-run variance, data splits, or ablation controls. This absence directly affects the soundness of the cross-hardware performance assertions and prevents assessment of whether the gains are reliable or platform-specific artifacts.
Authors: We concur that the experiments section would benefit from explicit statistical details. While averages across models are reported, the manuscript does not currently include run-to-run standard deviations, precise data-split descriptions, or expanded ablation controls. In the revision we will add: (i) standard deviations computed over five independent tuning runs per model, (ii) a description of the 80/20 random splits used for cost-model training together with 5-fold cross-validation results, and (iii) additional ablation tables that systematically vary each TCL component while holding the others fixed. These changes will demonstrate consistency across CPU and GPU and rule out platform-specific artifacts. revision: yes
Circularity Check
No circularity: empirical comparisons to external baseline
full rationale
The paper's central claims consist of measured speedups (16.8×/12.48× tuning time, 1.20×/1.13× latency) obtained by running TCL against the external Tenset-MLP baseline on mainstream DL models for CPU and GPU. The three enablers (RDU sampler, Mamba cost model, continual distillation) are introduced as engineering choices whose effectiveness is shown via ablation studies and end-to-end experiments; none of the reported quantities is obtained by fitting a parameter to a subset and then relabeling the fit as a prediction, nor is any load-bearing premise justified solely by a self-citation whose content reduces to the present result. The derivation chain therefore remains self-contained against external benchmarks and contains no self-definitional, fitted-input, or self-citation circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems
Abadi, M., Agarwal, A., Barham, P., Brevdo, E., Chen, Z., Citro, C., Corrado, G. S., Davis, A., Dean, J., Devin, M., et al.Tensorflow: Large-scale machine learning on heterogeneous distributed systems.arXiv preprint arXiv:1603.04467(2016)
work page Pith review arXiv 2016
-
[2]
InProceedings of the 29th ACM/IEEE International Symposium on Low Power Electronics and Design(2024), pp
Aghapour, E., Shen, Y., Sapra, D., Pimentel, A., and Pathania, A.Piqi: Partially quantized dnn inference on hmpsocs. InProceedings of the 29th ACM/IEEE International Symposium on Low Power Electronics and Design(2024), pp. 1–6
2024
- [3]
-
[4]
In2019 IEEE/ACM International Symposium on Code Generation and Optimization (CGO)(Washington, DC, USA, 2019), IEEE/ACM, pp
Baghdadi, R., et al.Tiramisu: A polyhedral compiler for expressing fast and portable code. In2019 IEEE/ACM International Symposium on Code Generation and Optimization (CGO)(Washington, DC, USA, 2019), IEEE/ACM, pp. 193–205
2019
-
[5]
[6]Bemporad, A.Active learning for regression by inverse distance weighting.Information Sciences 626(2023), 275–292
Baghdadi, R., et al.A deep learning based cost model for automatic code optimization.Proceedings of Machine Learning and Systems 3(2021), 181–193. [6]Bemporad, A.Active learning for regression by inverse distance weighting.Information Sciences 626(2023), 275–292
2021
-
[6]
InThe Eleventh International Conference on Learning Representations(Kigali, Rwanda, 2022), OpenReview.net
Bi, J., Li, X., Guo, Q., Zhang, R., Wen, Y., Hu, X., Du, Z., Song, X., Hao, Y., and Chen, Y.Balto: fast tensor program optimization with diversity-based active learning. InThe Eleventh International Conference on Learning Representations(Kigali, Rwanda, 2022), OpenReview.net
2022
-
[7]
In Proceedings of the IEEE/CVF International Conference on Computer Vision(2025), pp
Bi, Q., Shen, Y., Yi, J., and Xia, G.-S.Adadcp: Learning an adapter with discrete cosine prior for clear-to-adverse domain generalization. In Proceedings of the IEEE/CVF International Conference on Computer Vision(2025), pp. 12997–13008
2025
-
[8]
{TVM}: An automated {End-to-End} optimizing compiler for deep learning
Chen, T., et al. {TVM}: An automated {End-to-End} optimizing compiler for deep learning. In13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18)(Carlsbad, CA, USA, 2018), USENIX, pp. 578–594
2018
-
[9]
cuDNN: Efficient primitives for deep learning,
Chen, T., Zheng, L., Yan, E., Jiang, Z., Moreau, T., Ceze, L., Guestrin, C., and Krishnamurthy, A.Learning to optimize tensor programs. Advances in Neural Information Processing Systems 31(2018), 3393–3404. [11]Chetlur, S., et al.cudnn: Efficient primitives for deep learning.arXiv preprint arXiv:1410.0759(2014). [12]Chollet, F., et al.Keras.GitHub(2015)
-
[10]
[14]Foley, D., and Danskin, J.Ultra-performance pascal gpu and nvlink interconnect.IEEE Micro 37, 2 (2017), 7–17
Ding, C., Zheng, M., Chen, F., Zhang, Y., Zhuang, X., Fan, E., Wen, D., Zhang, L., Wei, W., and Zhang, Y.Hyperspectral image classification promotion using clustering inspired active learning.Remote Sensing 14, 3 (2022), 596. [14]Foley, D., and Danskin, J.Ultra-performance pascal gpu and nvlink interconnect.IEEE Micro 37, 2 (2017), 7–17
2022
-
[11]
InInternational conference on machine learning(2017), PMLR, pp
Gal, Y., Islam, R., and Ghahramani, Z.Deep bayesian active learning with image data. InInternational conference on machine learning(2017), PMLR, pp. 1183–1192
2017
-
[12]
InProceedings of the International Conference on Parallel Architectures and Compilation Techniques(New York, NY, USA, 2022), ACM, pp
Gibson, P., and Cano, J.Transfer-tuning: Reusing auto-schedules for efficient tensor program code generation. InProceedings of the International Conference on Parallel Architectures and Compilation Techniques(New York, NY, USA, 2022), ACM, pp. 28–39
2022
-
[13]
Gourdoumanis, G. R., Oikonomou, F., Pantazi-Kypraiou, M., Stoikos, P., Axelou, O., Tziouvaras, A., Karakonstantis, G., Aladwani, T., Anagnostopoulos, C., Shen, Y., et al.Multi-partner project: Coin-3d–collaborative innovation in 3d vlsi reliability.arXiv preprint arXiv:2601.14347 (2026). [18]Gu, A.Modeling Sequences with Structured State Spaces. Stanford ...
-
[14]
Efficiently Modeling Long Sequences with Structured State Spaces
Gu, A., Dao, T., Ermon, S., Rudra, A., and Ré, C.Hippo: Recurrent memory with optimal polynomial projections.Advances in neural information processing systems 33(2020), 1474–1487. [21]Gu, A., Goel, K., and Ré, C.Efficiently modeling long sequences with structured state spaces.arXiv preprint arXiv:2111.00396(2021)
work page internal anchor Pith review arXiv 2020
-
[15]
Guo, X., Jiang, Q., Shen, Y., Pimentel, A. D., and Stefanov, T.Easter: Learning to split transformers at the edge robustly.IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems 43, 11 (2024), 3626–3637. Manuscript submitted to ACM TCL: Enabling Fast and Efficient Cross-Hardware Tensor Program Optimization via Continual Learning 25
2024
-
[16]
Hemmer, P., Kühl, N., and Schöffer, J.Deal: Deep evidential active learning for image classification.Deep Learning Applications, Volume 3(2022), 171–192
2022
-
[17]
InProceedings of the Nineteenth European Conference on Computer Systems(Athens, Greece, 2024), ACM, pp
Hu, H., Su, J., Zhao, J., Peng, Y., Zhu, Y., Lin, H., and Wu, C.Cdmpp: A device-model agnostic framework for latency prediction of tensor programs. InProceedings of the Nineteenth European Conference on Computer Systems(Athens, Greece, 2024), ACM, pp. 1054–1074
2024
-
[18]
Huang, J.-H., Zhu, H., Shen, Y., Rudinac, S., Pacces, A. M., and Kanoulas, E.A novel evaluation framework for image2text generation.arXiv preprint arXiv:2408.01723(2024). [26]Intel.oneAPI Deep Neural Network Library (oneDNN), 2024
-
[19]
InProceedings of the 22nd ACM international conference on Multimedia(2014), pp
Jia, Y., Shelhamer, E., Donahue, J., Karayev, S., Long, J., Girshick, R., Guadarrama, S., and Darrell, T.Caffe: Convolutional architecture for fast feature embedding. InProceedings of the 22nd ACM international conference on Multimedia(2014), pp. 675–678
2014
-
[20]
Jia, Z., Tillman, B., Maggioni, M., and Scarpazza, D. P.Dissecting the graphcore ipu architecture via microbenchmarking.arXiv preprint arXiv:1912.03413(2019)
-
[21]
P., et al.In-datacenter performance analysis of a tensor processing unit
Jouppi, N. P., et al.In-datacenter performance analysis of a tensor processing unit. InProceedings of the 44th annual international symposium on computer architecture(Toronto, ON, Canada, 2017), ACM/IEEE, pp. 1–12
2017
-
[22]
Kirkpatrick, J., Pascanu, R., Rabinowitz, N., Veness, J., Desjardins, G., Rusu, A. A., Milan, K., Quan, J., Ramalho, T., Grabska-Barwinska, A., et al.Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences 114, 13 (2017), 3521–3526
2017
-
[23]
C.Unlabeled data selection for active learning in image classification.Scientific Reports 14, 1 (2024), 424
Li, X., W ang, X., Chen, X., Lu, Y., Fu, H., and Wu, Y. C.Unlabeled data selection for active learning in image classification.Scientific Reports 14, 1 (2024), 424
2024
-
[24]
I.Transferable representation learning with deep adaptation networks.IEEE transactions on pattern analysis and machine intelligence 41, 12 (2018), 3071–3085
Long, M., Cao, Y., Cao, Z., W ang, J., and Jordan, M. I.Transferable representation learning with deep adaptation networks.IEEE transactions on pattern analysis and machine intelligence 41, 12 (2018), 3071–3085
2018
-
[25]
T., Adams, A., Sharlet, D., Ragan-Kelley, J., and Fatahalian, K.Automatically scheduling halide image processing pipelines
Mullapudi, R. T., Adams, A., Sharlet, D., Ragan-Kelley, J., and Fatahalian, K.Automatically scheduling halide image processing pipelines. ACM Transactions on Graphics (TOG) 35, 4 (2016), 1–11
2016
-
[26]
PyTorch: An Imperative Style, High-Performance Deep Learning Library
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., et al.Pytorch: An imperative style, high-performance deep learning library. arxiv 2019.arXiv preprint arXiv:1912.01703 10(1912)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[27]
InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2(Rotterdam, Netherlands, 2025), ACM, pp
Qiao, L., Shi, J., Hao, X., Fang, X., Zhang, S., Zhao, M., Zhu, Z., Chen, J., An, H., Tang, X., et al.Pruner: A draft-then-verify exploration mechanism to accelerate tensor program tuning. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2(Rotterdam, Netherlands, 2025),...
2025
- [28]
-
[29]
InProceedings of the 31st ACM SIGPLAN International Conference on Compiler Construction(Seoul South Korea, 2022), ACM, pp
Ryu, J., Park, E., and Sung, H.One-shot tuner for deep learning compilers. InProceedings of the 31st ACM SIGPLAN International Conference on Compiler Construction(Seoul South Korea, 2022), ACM, pp. 89–103
2022
- [30]
-
[31]
D., and Pathania, A.Macp: Minimal yet mighty adaptation via hierarchical cosine projection
Shen, Y., Bi, Q., Huang, J.-H., Zhu, H., Pimentel, A. D., and Pathania, A.Macp: Minimal yet mighty adaptation via hierarchical cosine projection. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)(2025), pp. 20602–20618
2025
-
[32]
D., and Pathania, A.Ssh: Sparse spectrum adaptation via discrete hartley transformation
Shen, Y., Bi, Q., Huang, J.-H., Zhu, H., Pimentel, A. D., and Pathania, A.Ssh: Sparse spectrum adaptation via discrete hartley transformation. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)(2025), pp. 10400–10415
2025
-
[33]
D., and Pathania, A.Efficient multimodal spatial reasoning via dynamic and asymmetric routing
Shen, Y., Bi, Q., W ang, Z., Y ang, Z., W ang, C., Zhang, Z., Tiwari, P., Pimentel, A. D., and Pathania, A.Efficient multimodal spatial reasoning via dynamic and asymmetric routing. InThe Fourteenth International Conference on Learning Representations(2026)
2026
-
[34]
D.Thermal management for 3d-stacked systems via unified core-memory power regulation.ACM Transactions on Embedded Computing Systems 22, 5s (2023), 1–26
Shen, Y., Schreuders, L., Pathania, A., and Pimentel, A. D.Thermal management for 3d-stacked systems via unified core-memory power regulation.ACM Transactions on Embedded Computing Systems 22, 5s (2023), 1–26
2023
-
[35]
J.Tbal: Two-stage batch-mode active learning for image classification.Signal Processing: Image Communication 106(2022), 116731
Shen, Y., Song, Y., Wu, C.-h., and Kuo, C.-C. J.Tbal: Two-stage batch-mode active learning for image classification.Signal Processing: Image Communication 106(2022), 116731
2022
-
[36]
D.Tcps: a task and cache-aware partitioned scheduler for hard real-time multi-core systems
Shen, Y., Xiao, J., and Pimentel, A. D.Tcps: a task and cache-aware partitioned scheduler for hard real-time multi-core systems. InProceedings of the 23rd ACM SIGPLAN/SIGBED International Conference on Languages, Compilers, and Tools for Embedded Systems(2022), pp. 37–49
2022
-
[37]
In Proceedings of the 2025 International Conference on Artificial Intelligence and Computational Intelligence(2025), pp
Shen, Y., Zhang, H., Shen, Y., Wang, L., Shi, C., Du, S., and Tao, Y.Altgen: Ai-driven alt text generation for enhancing epub accessibility. In Proceedings of the 2025 International Conference on Artificial Intelligence and Computational Intelligence(2025), pp. 78–83
2025
-
[38]
Steiner, B., Cummins, C., He, H., and Leather, H.Value learning for throughput optimization of deep learning workloads.Proceedings of Machine Learning and Systems 3(2021), 323–334
2021
-
[39]
IEEE Transactions on Neural Networks and Learning Systems 33, 4 (2020), 1364–1384
Tampuu, A., Matiisen, T., Semikin, M., Fishman, D., and Muhammad, N.A survey of end-to-end driving: Architectures and training methods. IEEE Transactions on Neural Networks and Learning Systems 33, 4 (2020), 1364–1384
2020
-
[40]
M., Emani, M., and Chapman, B.Transfer learning across heterogeneous features for efficient tensor program generation
Verma, G., Raskar, S., Xie, Z., Malik, A. M., Emani, M., and Chapman, B.Transfer learning across heterogeneous features for efficient tensor program generation. InProceedings of the 2nd International Workshop on Extreme Heterogeneity Solutions(Montreal, QC, Canada, 2023), ACM, pp. 1–6
2023
-
[41]
InThe Thirty-ninth Annual Conference on Neural Information Processing Systems(2025)
W ang, C., He, S., Fang, X., Hu, Z., Huang, J.-H., Shen, Y., and Tiwari, P.Reasoning beyond points: A visual introspective approach for few-shot 3d segmentation. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems(2025). Manuscript submitted to ACM 26 C. Shen et al
2025
-
[42]
InProceedings of the 27th ACM international conference on information and knowledge management(Torino,Italy, 2018), ACM, pp
W ang, X., Li, C., Golbandi, N., Bendersky, M., and Najork, M.The lambdaloss framework for ranking metric optimization. InProceedings of the 27th ACM international conference on information and knowledge management(Torino,Italy, 2018), ACM, pp. 1313–1322
2018
-
[43]
M., Wolff, J., Shen, Y., Pathania, A., Grelck, C., and Pimentel, A
W asala, S. M., Wolff, J., Shen, Y., Pathania, A., Grelck, C., and Pimentel, A. D.Energy-efficient qos-aware scheduling for s-nuca many-cores. In2025 26th International Symposium on Quality Electronic Design (ISQED)(2025), IEEE, pp. 1–8. [52]Weiss, K., Khoshgoftaar, T. M., and W ang, D.A survey of transfer learning.Journal of Big data 3(2016), 1–40. [53]W...
2025
-
[44]
In2020 IEEE 38th International Conference on Computer Design (ICCD)(Hartford, Massachusetts, USA, 2020), IEEE, pp
Zeng, X., Zhi, T., Du, Z., Guo, Q., Sun, N., and Chen, Y.Alt: optimizing tensor compilation in deep learning compilers with active learning. In2020 IEEE 38th International Conference on Computer Design (ICCD)(Hartford, Massachusetts, USA, 2020), IEEE, pp. 623–630
2020
-
[45]
InProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2(Vancouver, BC, Canada, 2023), ACM, pp
Zhai, Y., Zhang, Y., Liu, S., Chu, X., Peng, J., Ji, J., and Zhang, Y.Tlp: A deep learning-based cost model for tensor program tuning. InProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2(Vancouver, BC, Canada, 2023), ACM, pp. 833–845. [56]Zhang, Y., and Y ang, Q.An overv...
2023
-
[46]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing(2025), pp
Zhang, Z., Shen, Y., Cao, C., and Shutova, E.Neuroada: Activating each neuron’s potential for parameter-efficient fine-tuning. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing(2025), pp. 10960–10977
2025
-
[47]
InProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3(2024), pp
Zhao, Y., Sharif, H., Adve, V., and Misailovic, S.Felix: Optimizing tensor programs with gradient descent. InProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3(2024), pp. 367–381
2024
-
[48]
InProceedings of the 24th International Workshop on Mobile Computing Systems and Applications(Newport Beach, CA, USA, 2023), ACM, pp
Zhao, Z., Shuai, X., Ling, N., Guan, N., Y an, Z., and Xing, G.Moses: Exploiting cross-device transferable features for on-device tensor program optimization. InProceedings of the 24th International Workshop on Mobile Computing Systems and Applications(Newport Beach, CA, USA, 2023), ACM, pp. 22–28
2023
-
[49]
In14th USENIX symposium on operating systems design and implementation (OSDI 20)(Banff, Alberta, Canada, 2020), USENIX, pp
Zheng, L., et al.Ansor: Generating {High-Performance} tensor programs for deep learning. In14th USENIX symposium on operating systems design and implementation (OSDI 20)(Banff, Alberta, Canada, 2020), USENIX, pp. 863–879
2020
-
[50]
InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 1)(Online Conference, Canada, 2021), Curran Associates, Inc
Zheng, L., et al.Tenset: A large-scale program performance dataset for learned tensor compilers. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 1)(Online Conference, Canada, 2021), Curran Associates, Inc
2021
-
[51]
InProceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems(Lausanne, Switzerland, 2020), ACM, pp
Zheng, S., Liang, Y., W ang, S., Chen, R., and Sheng, K.Flextensor: An automatic schedule exploration and optimization framework for tensor computation on heterogeneous system. InProceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems(Lausanne, Switzerland, 2020), ACM, pp. 859–873
2020
-
[52]
Manuscript submitted to ACM
Zhu, H., Huang, J.-H., Shen, Y., Rudinac, S., and Kanoulas, E.Interactive image retrieval meets query rewriting with large language and vision language models.ACM Transactions on Multimedia Computing, Communications and Applications 21, 10 (2025), 1–23. Manuscript submitted to ACM
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.