Recognition: unknown
Don't Show Pixels, Show Cues: Unlocking Visual Tool Reasoning in Language Models via Perception Programs
Pith reviewed 2026-05-10 15:26 UTC · model grok-4.3
The pith
Converting vision tool outputs into language summaries unlocks accurate visual reasoning in multimodal models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that the bottleneck in visual tool reasoning for MLLMs is the pixel-level representation of tool outputs, which is misaligned with language-native strengths. By introducing Perception Programs that convert these outputs into compact language summaries, models can effectively parse and reason over the visual cues, achieving substantial accuracy improvements across six perception-centric tasks without training or model changes.
What carries the argument
Perception Programs (P²), a method that rewrites dense tool outputs such as depth maps and optical flow into compact, structured language-native summaries that MLLMs can directly use for reasoning.
Load-bearing premise
The compact language summaries produced by Perception Programs preserve all task-critical visual information from the original tool outputs without introducing systematic errors or omissions.
What would settle it
A controlled test on a perception task where a single critical detail is lost in the textual summary but remains visible in the raw tool output, and P² accuracy falls below the raw-pixel baseline.
Figures






read the original abstract
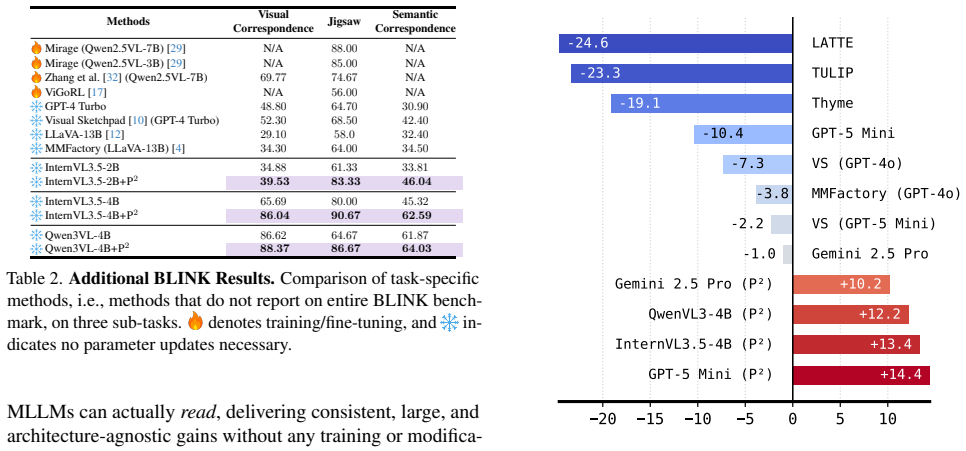
Multimodal language models (MLLMs) are increasingly paired with vision tools (e.g., depth, flow, correspondence) to enhance visual reasoning. However, despite access to these tool-generated visual cues, MLLMs often fail to benefit from them. Existing approaches typically feed raw tool outputs into the model, but these dense, pixel-level representations are misaligned with the language-native reasoning strengths of LLMs, leading to weak perception and reliance on language priors. We argue that, in problems where vision tools can provide the necessary visual cues, the bottleneck is not more tool calls or larger MLLMs, it is how tool outputs are represented. We introduce Perception Programs (P$^2$), a training-free, model-agnostic method that rewrites tool outputs into compact, structured, language-native summaries that MLLMs can directly parse and reason over. Across six perception-centric tasks in BLINK, P$^2$ consistently yields large improvements over base models and raw tool-augmented baselines. With GPT-5 Mini as the base model, P$^2$ raises its accuracy from 41.35\% to 86.47\% on multi-view reasoning, from 52.42\% to 81.45\% on relative depth, and achieves a 22\% average gain across tasks, setting new state-of-the-art results. Even on smaller MLLMs, e.g., InternVL3.5-4B and Qwen3VL-4B, we observe 15-40\% absolute gains from P$^2$, surpassing prior agentic, supervised, and RL-based tool-use methods-without any training or model modifications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that MLLMs fail to benefit from vision tool outputs (depth, flow, correspondence) when fed as raw pixels because these are misaligned with language-native reasoning; instead, Perception Programs (P²) convert tool outputs into compact structured language summaries, yielding large gains on BLINK tasks (e.g., +45% on multi-view reasoning and +29% on relative depth with GPT-5 Mini) without training or model changes, outperforming agentic, supervised, and RL baselines.
Significance. If the empirical results hold after addressing the representation-faithfulness concern, the work would demonstrate that output representation—not additional tools, scale, or training—is the primary bottleneck for tool-augmented visual reasoning in MLLMs. The training-free, model-agnostic nature and consistent gains across model sizes (including 4B-scale MLLMs) would be a notable practical contribution, shifting focus from complex agent loops to simpler cue reformatting.
major comments (2)
- [Method and Experiments] The central claim that language summaries unlock visual reasoning rests on the untested assumption that they preserve all task-critical information from raw tool outputs. The paper does not report any quantitative comparison (e.g., information loss metrics or human verification) between the original pixel/tool data and the generated summaries on the relative-depth or multi-view tasks, leaving open the possibility that gains arise from noise reduction rather than faithful cue encoding.
- [Experiments] Table 1 (or equivalent results table) reports 22% average gain and SOTA numbers, but lacks error bars, statistical significance tests, or details on how many runs were averaged; given the headline deltas (e.g., 41.35% → 86.47%), this weakens confidence that the improvements are robust rather than sensitive to prompt or summarizer variance.
minor comments (2)
- [Abstract] The abstract and introduction use “GPT-5 Mini” without clarifying whether this is a hypothetical or specific released model; add a footnote or citation for reproducibility.
- [Method] Clarify the exact template or prompting strategy used to generate the structured summaries (e.g., fixed code vs. LLM calls) in the method section, as this affects claims of being fully training-free and model-agnostic.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments identify key areas for strengthening our claims and evaluation. We respond point-by-point to the major comments below and outline revisions to address them directly.
read point-by-point responses
-
Referee: [Method and Experiments] The central claim that language summaries unlock visual reasoning rests on the untested assumption that they preserve all task-critical information from raw tool outputs. The paper does not report any quantitative comparison (e.g., information loss metrics or human verification) between the original pixel/tool data and the generated summaries on the relative-depth or multi-view tasks, leaving open the possibility that gains arise from noise reduction rather than faithful cue encoding.
Authors: We appreciate this observation on the need for explicit validation of information preservation. Our Perception Programs are constructed to extract and verbalize only the task-relevant cues (e.g., explicit relative depth orderings or correspondence relations) while discarding extraneous pixel details, which aligns with the observed large gains that would be unlikely from noise reduction alone. That said, we did not include direct quantitative information-loss metrics or human verification in the original submission. In the revision we will add a dedicated analysis subsection that reports human-rated faithfulness scores on sampled outputs for the relative-depth and multi-view tasks, together with a comparison of task-critical elements retained versus discarded from the raw tool data. revision: yes
-
Referee: [Experiments] Table 1 (or equivalent results table) reports 22% average gain and SOTA numbers, but lacks error bars, statistical significance tests, or details on how many runs were averaged; given the headline deltas (e.g., 41.35% → 86.47%), this weakens confidence that the improvements are robust rather than sensitive to prompt or summarizer variance.
Authors: We agree that error bars, statistical significance testing, and explicit details on run averaging are necessary to demonstrate robustness, especially given potential variance from the summarization step. The original results were obtained from single runs per configuration. In the revised manuscript we will augment Table 1 (and all main result tables) with standard deviations computed over five independent runs that vary the summarizer prompt phrasing and random seeds where applicable. We will also report the results of paired statistical significance tests (e.g., McNemar’s test) between P² and the raw-tool baselines, and we will clarify the exact averaging procedure in the experimental section. revision: yes
Circularity Check
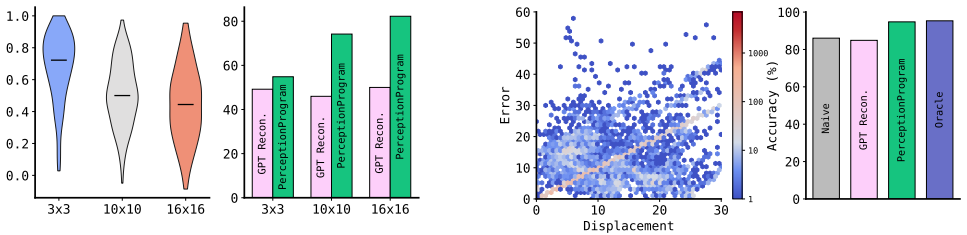
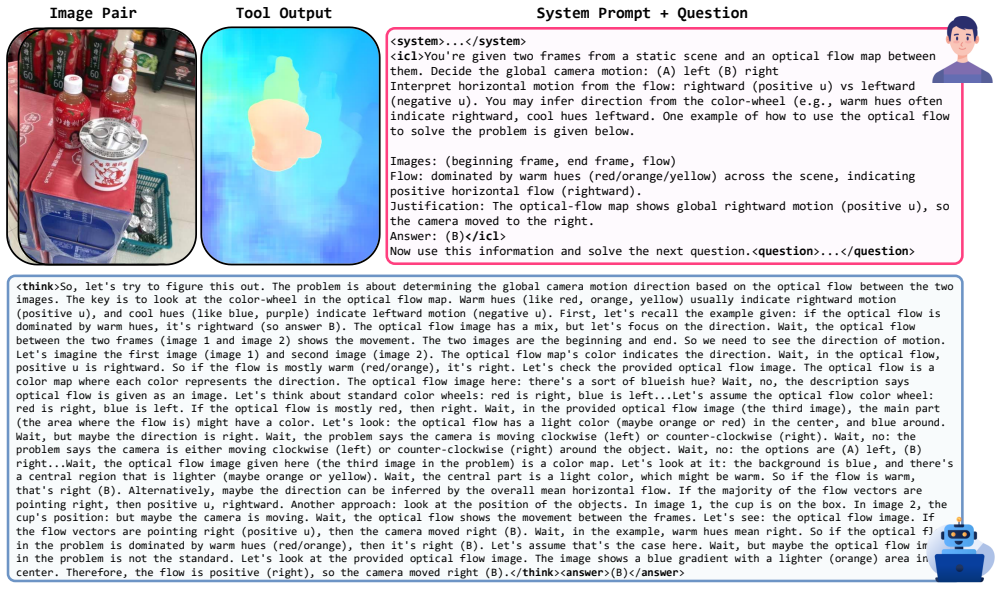
No circularity: empirical gains from Perception Programs rest on external benchmarks
full rationale
The paper introduces Perception Programs as a training-free conversion of tool outputs (depth maps, flow, etc.) into compact language summaries, then reports accuracy lifts on the BLINK benchmark suite against raw-tool and prior baselines. No equations, fitted parameters, self-definitional loops, or load-bearing self-citations appear in the derivation chain. All performance numbers are measured on held-out tasks and compared to independent methods, so the central claim remains externally falsifiable and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Perception Programs (P²)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Per- ception tokens enhance visual reasoning in multimodal lan- guage models
Mahtab Bigverdi, Zelun Luo, Cheng-Yu Hsieh, Ethan Shen, Dongping Chen, Linda G Shapiro, and Ranjay Krishna. Per- ception tokens enhance visual reasoning in multimodal lan- guage models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 3836–3845, 2025. 1, 2, 3, 5, 7, 4
2025
-
[2]
arXiv preprint arXiv:2504.13180 , year=
Jang Hyun Cho, Andrea Madotto, Effrosyni Mavroudi, Tri- antafyllos Afouras, Tushar Nagarajan, Muhammad Maaz, Yale Song, Tengyu Ma, Shuming Hu, Suyog Jain, et al. Per- ceptionlm: Open-access data and models for detailed visual understanding.arXiv preprint arXiv:2504.13180, 2025. 2, 5, 6
-
[3]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long con- text, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 5, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Wan-Cyuan Fan, Tanzila Rahman, and Leonid Sigal. Mmfac- tory: A universal solution search engine for vision-language tasks.arXiv preprint arXiv:2412.18072, 2024. 3, 5, 6, 7, 2
-
[5]
GRIT: Teaching MLLMs to Think with Images
Yue Fan, Xuehai He, Diji Yang, Kaizhi Zheng, Ching-Chen Kuo, Yuting Zheng, Sravana Jyothi Narayanaraju, Xinze Guan, and Xin Eric Wang. Grit: Teaching mllms to think with images.arXiv preprint arXiv:2505.15879, 2025. 3
work page internal anchor Pith review arXiv 2025
-
[6]
Hidden in plain sight: Vlms overlook their visual repre- sentations, 2025
Stephanie Fu, Tyler Bonnen, Devin Guillory, and Trevor Dar- rell. Hidden in plain sight: Vlms overlook their visual repre- sentations, 2025. 1, 2, 3
2025
-
[7]
Llmdet: Learning strong open-vocabulary object detectors under the supervision of large language models
Shenghao Fu, Qize Yang, Qijie Mo, Junkai Yan, Xihan Wei, Jingke Meng, Xiaohua Xie, and Wei-Shi Zheng. Llmdet: Learning strong open-vocabulary object detectors under the supervision of large language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14987–14997, 2025. 5
2025
-
[8]
Blink: Multimodal large language mod- els can see but not perceive
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. Blink: Multimodal large language mod- els can see but not perceive. InEuropean Conference on Computer Vision, pages 148–166. Springer, 2024. 1, 2, 5, 6, 8
2024
-
[9]
Visual program- ming: Compositional visual reasoning without training
Tanmay Gupta and Aniruddha Kembhavi. Visual program- ming: Compositional visual reasoning without training. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14953–14962, 2023. 2, 3
2023
-
[10]
Vi- sual sketchpad: Sketching as a visual chain of thought for multimodal language models.Advances in Neural Informa- tion Processing Systems, 37:139348–139379, 2024
Yushi Hu, Weijia Shi, Xingyu Fu, Dan Roth, Mari Ostendorf, Luke Zettlemoyer, Noah A Smith, and Ranjay Krishna. Vi- sual sketchpad: Sketching as a visual chain of thought for multimodal language models.Advances in Neural Informa- tion Processing Systems, 37:139348–139379, 2024. 3, 5, 6, 7, 8, 1, 2, 4
2024
-
[11]
Zebra-cot: A dataset for interleaved vision language reasoning
Ang Li, Charles Wang, Deqing Fu, Kaiyu Yue, Zikui Cai, Wang Bill Zhu, Ollie Liu, Peng Guo, Willie Neiswanger, Furong Huang, et al. Zebra-cot: A dataset for interleaved vision language reasoning.arXiv preprint arXiv:2507.16746,
-
[12]
Llava-plus: Learning to use tools for creating multimodal agents
Shilong Liu, Hao Cheng, Haotian Liu, Hao Zhang, Feng Li, Tianhe Ren, Xueyan Zou, Jianwei Yang, Hang Su, Jun Zhu, et al. Llava-plus: Learning to use tools for creating multimodal agents. InEuropean conference on computer vision, pages 126–142. Springer, 2024. 7
2024
-
[13]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, and Lei Zhang. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuropean Conference on Computer Vision, pages 38–55. Springer, 2024. 8
2024
-
[14]
Latte: Learning to think with vision specialists
Zixian Ma, Jianguo Zhang, Zhiwei Liu, Jieyu Zhang, Jun- tao Tan, Manli Shu, Juan Carlos Niebles, Shelby Heinecke, Huan Wang, Caiming Xiong, Ranjay Krishna, and Silvio Savarese. Latte: Learning to think with vision specialists. InProceedings of the Conference on Empirical Methods in Natural Language Processing, 2025. 2, 3, 5, 6, 8
2025
-
[15]
Gpt-5 system card, 2025
OpenAI. Gpt-5 system card, 2025. 5, 6, 1
2025
-
[16]
Per- ception test: A diagnostic benchmark for multimodal video models.Advances in Neural Information Processing Systems, 36:42748–42761, 2023
Viorica Patraucean, Lucas Smaira, Ankush Gupta, Adria Re- casens, Larisa Markeeva, Dylan Banarse, Skanda Koppula, Mateusz Malinowski, Yi Yang, Carl Doersch, et al. Per- ception test: A diagnostic benchmark for multimodal video models.Advances in Neural Information Processing Systems, 36:42748–42761, 2023. 1
2023
-
[17]
Grounded reinforcement learning for visual reasoning.arXiv preprint arXiv:2505.23678, 2025
Gabriel Sarch, Snigdha Saha, Naitik Khandelwal, Ayush Jain, Michael J Tarr, Aviral Kumar, and Katerina Fragkiadaki. Grounded reinforcement learning for visual reasoning.arXiv preprint arXiv:2505.23678, 2025. 2, 5, 7
-
[18]
Loftr: Detector-free local feature matching with transformers
Jiaming Sun, Zehong Shen, Yuang Wang, Hujun Bao, and Xi- aowei Zhou. Loftr: Detector-free local feature matching with transformers. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8922–8931,
-
[19]
Vipergpt: Vi- sual inference via python execution for reasoning
D´ıdac Sur´ıs, Sachit Menon, and Carl V ondrick. Vipergpt: Vi- sual inference via python execution for reasoning. InProceed- ings of the IEEE/CVF international conference on computer vision, pages 11888–11898, 2023. 2, 3
2023
-
[20]
Emergent correspondence from image diffusion.Advances in Neural Information Processing Systems, 36:1363–1389, 2023
Luming Tang, Menglin Jia, Qianqian Wang, Cheng Perng Phoo, and Bharath Hariharan. Emergent correspondence from image diffusion.Advances in Neural Information Processing Systems, 36:1363–1389, 2023. 5
2023
-
[21]
Tulip: Contrastive image-text learning with richer vision understanding
Zineng Tang, Long Lian, Seun Eisape, Xudong Wang, Roei Herzig, Adam Yala, Alane Suhr, Trevor Darrell, and David M Chan. Tulip: Contrastive image-text learning with richer vision understanding. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pages 4267–4277,
-
[22]
Qwen3 technical report, 2025
Qwen Team. Qwen3 technical report, 2025. 5, 6
2025
-
[23]
Raft: Recurrent all-pairs field transforms for optical flow
Zachary Teed and Jia Deng. Raft: Recurrent all-pairs field transforms for optical flow. InEuropean conference on com- puter vision, pages 402–419. Springer, 2020. 5
2020
-
[24]
Eyes wide shut? exploring the visual shortcomings of multimodal llms
Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie. Eyes wide shut? exploring the visual shortcomings of multimodal llms. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9568–9578, 2024. 3
2024
-
[25]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265, 2025. 5, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004. 5
2004
-
[27]
Yana Wei, Liang Zhao, Jianjian Sun, Kangheng Lin, Jisheng Yin, Jingcheng Hu, Yinmin Zhang, En Yu, Haoran Lv, Zejia Weng, et al. Open vision reasoner: Transferring linguis- tic cognitive behavior for visual reasoning.arXiv preprint arXiv:2507.05255, 2025. 5, 6, 2
-
[28]
Depth anything: Unleashing the power of large-scale unlabeled data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything: Unleashing the power of large-scale unlabeled data. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10371–10381, 2024. 5, 8
2024
-
[29]
Zeyuan Yang, Xueyang Yu, Delin Chen, Maohao Shen, and Chuang Gan. Machine mental imagery: Empower multi- modal reasoning with latent visual tokens.arXiv preprint arXiv:2506.17218, 2025. 1, 2, 3, 5, 6, 7
-
[30]
Introducingvi- sual perception token into multimodal large language model
Runpeng Yu, Xinyin Ma, and Xinchao Wang. Introducing visual perception token into multimodal large language model. arXiv preprint arXiv:2502.17425, 2025. 2
-
[31]
Socratic models: Composing zero-shot multimodal reasoning with language,
Andy Zeng, Maria Attarian, Brian Ichter, Krzysztof Choro- manski, Adrian Wong, Stefan Welker, Federico Tombari, Aveek Purohit, Michael Ryoo, Vikas Sindhwani, et al. So- cratic models: Composing zero-shot multimodal reasoning with language.arXiv preprint arXiv:2204.00598, 2022. 1
-
[32]
Improving the Reasoning of Multi-Image Grounding in MLLMs via Reinforcement Learning
Bob Zhang, Haoran Li, Tao Zhang, Cilin Yan, Jiayin Cai, and Yanbin Hao. Improving the reasoning of multi-image grounding in mllms via reinforcement learning.arXiv preprint arXiv:2507.00748, 2025. 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Yi-Fan Zhang, Xingyu Lu, Shukang Yin, Chaoyou Fu, Wei Chen, Xiao Hu, Bin Wen, Kaiyu Jiang, Changyi Liu, Tianke Zhang, et al. Thyme: Think beyond images.arXiv preprint arXiv:2508.11630, 2025. 2, 3, 5, 6
work page internal anchor Pith review arXiv 2025
-
[34]
Zhehao Zhang, Ryan Rossi, Tong Yu, Franck Dernoncourt, Ruiyi Zhang, Jiuxiang Gu, Sungchul Kim, Xiang Chen, Zichao Wang, and Nedim Lipka. Vipact: Visual-perception enhancement via specialized vlm agent collaboration and tool-use.arXiv preprint arXiv:2410.16400, 2024. 3
-
[35]
disable” ( −5.24 on V*) and “replace with placeholders
Zetong Zhou, Dongping Chen, Zixian Ma, Zhihan Hu, Mingyang Fu, Sinan Wang, Yao Wan, Zhou Zhao, and Ran- jay Krishna. Reinforced visual perception with tools.arXiv preprint arXiv:2509.01656, 2025. 2, 5, 6, 1, 4 Don’t Show Pixels, Show Cues: Unlocking Visual Tool Reasoning in Language Models via Perception Programs Supplementary Material Methods HardBLINK 3...
-
[36]
Mainly, we provide samples of prompts for both frontier and open-source MLLMs
Perception Program Details In this section, we discuss additional details about Perception Programs. Mainly, we provide samples of prompts for both frontier and open-source MLLMs. We also detail in-context (ICL) example that we use to query the open-source MLLMs. Recall that frontier models, GPT-5 Mini and Gemini 2.5 Pro, work as is and do not require any...
-
[37]
left" or
Additional Related Work In this section, we give a non-comprehensive summary of methods from the related work, expanding on some that were briefly mentioned while also introducing additional ones. We additionally note that several prior state-of-the-art BLINK results were obtained by methods that do not rely on tools, which we also include here. 8.1. Tool...
-
[38]
5.1 we discussed the quality of visual interpretation of current MLLMs
Additional Experimental Details In Sec. 5.1 we discussed the quality of visual interpretation of current MLLMs. We expand the discussion on on vi- <system>...</system> <icl>You're given two frames from a static scene and an optical flow map between them. Decide the global camera motion: (A) left (B) right Interpret horizontal motion from the flow: rightwa...
-
[39]
LLM Usage Statement In this manuscript, we used several MLLMs as part of our experimental setup and we have described the necessary details in Secs. 4 and 7. Other than that, we also used LLMs (ChatGPT) to help with refining the manuscript in terms of fixing grammatical errors in writing and with plotting codes for various figures. The authors did not use...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.