Recognition: unknown
Radar-Camera BEV Multi-Task Learning with Cross-Task Attention Bridge for Joint 3D Detection and Segmentation
Pith reviewed 2026-05-10 15:09 UTC · model grok-4.3
The pith
A bidirectional attention bridge in shared BEV space lets detection and segmentation exchange features, raising segmentation accuracy on seven classes while detection stays neutral.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CTAB is a bidirectional module that exchanges features between detection and segmentation branches via multi-scale deformable attention in shared BEV space. Integrated into a radar-camera multi-task framework that also uses an Instance Normalization segmentation decoder and learnable BEV upsampling, the module improves segmentation on seven classes over a joint baseline while detection performance remains essentially unchanged. On a four-class subset the same model delivers both 3D detection and segmentation mIoU comparable to specialized segmentation models.
What carries the argument
CTAB (Cross-Task Attention Bridge), a bidirectional module that applies multi-scale deformable attention to transfer features between detection and segmentation heads inside a common BEV coordinate frame.
If this is right
- Segmentation mIoU rises on seven classes relative to a joint multi-task baseline that lacks the attention bridge.
- 3D detection metrics (NDS, mAP) remain essentially neutral, indicating the feature exchange does not create harmful task interference.
- A single model can output both 3D bounding boxes and dense semantic maps in the same BEV grid from radar-camera inputs.
- Learnable upsampling of the BEV feature map combined with Instance Normalization in the decoder yields a finer-grained representation usable by both heads.
Where Pith is reading between the lines
- The same bidirectional attention pattern could be applied to other BEV pairs such as detection paired with depth estimation or motion forecasting.
- Shared computation between heads may reduce total latency compared with running separate detection and segmentation networks.
- Success of the exchange rests on precise geometric registration in BEV; the benefit may shrink when sensor calibration is noisy or when tasks lack strong spatial overlap.
Load-bearing premise
Detection and segmentation features are complementary enough that attention-based transfer will improve segmentation without introducing noise that harms detection.
What would settle it
Removing the CTAB module from the joint model and measuring segmentation mIoU on the nuScenes validation set; if mIoU does not drop while detection NDS stays the same or rises, the value of the cross-task exchange is called into question.
Figures




read the original abstract
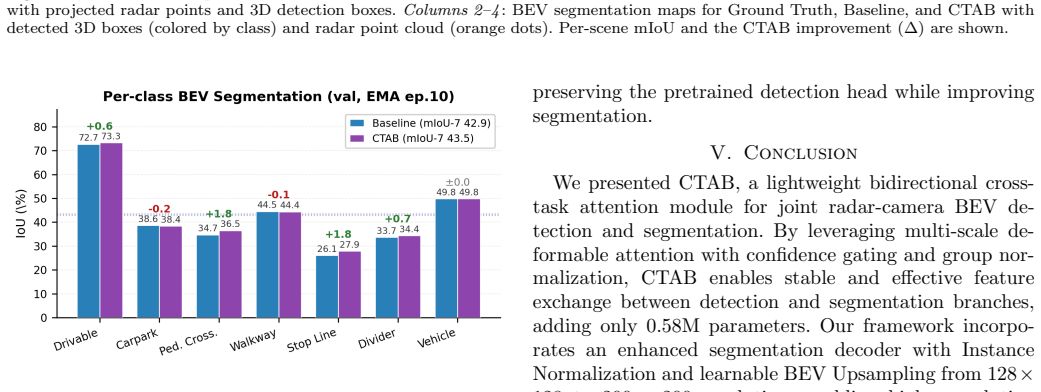
Bird's-eye-view (BEV) representations are the dominant paradigm for 3D perception in autonomous driving, providing a unified spatial canvas where detection and segmentation features are geometrically registered to the same physical coordinate system. However, existing radar-camera fusion methods treat these tasks in isolation, missing the opportunity to share complementary information between them: detection features encode object-level geometry that can sharpen segmentation boundaries, while segmentation features provide dense semantic context that can anchor detection. We propose \textbf{CTAB} (Cross-Task Attention Bridge), a bidirectional module that exchanges features between detection and segmentation branches via multi-scale deformable attention in shared BEV space. CTAB is integrated into a multi-task framework with an Instance Normalization-based segmentation decoder and learnable BEV upsampling to provide a more detailed BEV representation. On nuScenes, CTAB improves segmentation on 7 classes over the joint multi-task baseline at essentially neutral detection. On a 4-class subset (drivable area, pedestrian crossing, walkway, vehicle), our joint multi-task model reaches comparable mIoU on 4 classes while simultaneously providing 3D detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CTAB (Cross-Task Attention Bridge), a bidirectional module using multi-scale deformable attention to exchange features between detection and segmentation branches in shared BEV space for radar-camera fusion. CTAB is integrated into a multi-task framework that also includes an Instance Normalization-based segmentation decoder and learnable BEV upsampling. On nuScenes, the approach is claimed to improve segmentation on 7 classes over a joint multi-task baseline while keeping detection essentially neutral; a 4-class subset (drivable area, pedestrian crossing, walkway, vehicle) reaches comparable mIoU while enabling 3D detection.
Significance. If the segmentation gains can be isolated to CTAB's cross-task attention and the results are supported by proper ablations and metrics, the work would offer a practical demonstration of complementary feature sharing between object-level geometry (detection) and dense semantics (segmentation) in BEV representations. This could be relevant for multi-task radar-camera perception in autonomous driving, where avoiding task interference is a known challenge. The shared-BEV attention design is a natural extension of existing deformable attention techniques, but the current lack of quantitative detail limits evaluation of its broader impact.
major comments (2)
- [Abstract and Experimental Results] The abstract and results description compare CTAB against an unspecified 'joint multi-task baseline' without clarifying whether that baseline includes the Instance Normalization decoder and learnable BEV upsampling. No ablation removing only CTAB (while retaining the other components) is described, so the mIoU gains on 7 classes cannot be attributed specifically to the bidirectional multi-scale deformable attention rather than the decoder/upsampling additions. This directly affects the central empirical claim.
- [Experimental Results] No quantitative tables, exact metric values (mIoU per class, detection mAP/NDS), baseline definitions, or error analysis are supplied to support the stated segmentation improvements and neutral detection. Without these, the soundness of the headline result cannot be verified.
minor comments (1)
- [Abstract] The abstract refers to 'improves segmentation on 7 classes' without naming the classes or providing numerical deltas, reducing clarity.
Simulated Author's Rebuttal
Thank you for your constructive and detailed review. We appreciate the feedback highlighting the need for greater clarity on baselines, explicit ablations, and quantitative reporting. We will revise the manuscript accordingly to strengthen the empirical claims.
read point-by-point responses
-
Referee: [Abstract and Experimental Results] The abstract and results description compare CTAB against an unspecified 'joint multi-task baseline' without clarifying whether that baseline includes the Instance Normalization decoder and learnable BEV upsampling. No ablation removing only CTAB (while retaining the other components) is described, so the mIoU gains on 7 classes cannot be attributed specifically to the bidirectional multi-scale deformable attention rather than the decoder/upsampling additions. This directly affects the central empirical claim.
Authors: We agree that the baseline definition requires explicit clarification. The joint multi-task baseline consists of the shared radar-camera BEV backbone together with the Instance Normalization segmentation decoder and learnable BEV upsampling, but without the CTAB module. The reported gains are intended to stem from CTAB's bidirectional multi-scale deformable attention. To isolate this contribution, the revised manuscript will include a new ablation table that directly compares the full model against the identical multi-task setup with CTAB removed. The abstract and experimental sections will be updated to state the baseline composition unambiguously. revision: yes
-
Referee: [Experimental Results] No quantitative tables, exact metric values (mIoU per class, detection mAP/NDS), baseline definitions, or error analysis are supplied to support the stated segmentation improvements and neutral detection. Without these, the soundness of the headline result cannot be verified.
Authors: We acknowledge that the current version presents only high-level summaries. The revised manuscript will add detailed tables reporting per-class mIoU for all nuScenes segmentation classes, detection mAP and NDS for both the baseline and CTAB model, and the exact numerical differences. A short error analysis subsection will also be included to contextualize the observed segmentation gains on seven classes and the essentially neutral detection performance. revision: yes
Circularity Check
No circularity: empirical architecture proposal with no self-referential derivations or load-bearing self-citations
full rationale
The paper introduces CTAB as a bidirectional cross-task attention module using multi-scale deformable attention in shared BEV space, integrated with an Instance Normalization segmentation decoder and learnable BEV upsampling. All performance claims (improved segmentation on 7 classes with neutral detection on nuScenes) rest on direct empirical comparisons to a joint multi-task baseline. No equations, first-principles derivations, or predictions are presented that reduce by construction to fitted inputs, self-definitions, or self-citation chains. The architecture is described as a novel integration rather than derived from prior results by the same authors. This is a standard empirical CV contribution; the skeptic concern about baseline composition affects experimental isolation but does not constitute circularity in any derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption BEV representation unifies detection and segmentation features in a shared physical coordinate system
invented entities (1)
-
CTAB (Cross-Task Attention Bridge)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
RCBEVDet: Radar-camera fusion in bird’s eye view for 3D object detection,
L. Lin, Z. Kong, et al., “RCBEVDet: Radar-camera fusion in bird’s eye view for 3D object detection,”arXiv preprint arXiv:2407.12622, 2024
-
[2]
S. Ge, et al., “BEVCar: Camera-Radar Fusion for BEV Map and Object Segmentation,”arXiv preprint arXiv:2403.11761, 2024
-
[3]
CRN: Camera Radar Net for Accurate, Robust, Efficient 3D Perception,
S. Kim, et al., “CRN: Camera Radar Net for Accurate, Robust, Efficient 3D Perception,” inICCV, 2023
2023
-
[4]
J. Huang, et al., “BEVDet: High-Performance Multi-Camera 3D Object Detection in Bird-Eye-View,”arXiv preprint arXiv:2112.11790, 2021
-
[5]
BEVDepth: Acquisition of Reliable Depth for Multi-view 3D Object Detection,
Y. Li, et al., “BEVDepth: Acquisition of Reliable Depth for Multi-view 3D Object Detection,” inAAAI, 2023
2023
-
[6]
arXiv preprint arXiv:2205.09743 (2022)
Z. Zhang, et al., “BEVerse: Unified Perception and Prediction in Birds-Eye-View for Vision-Centric Autonomous Driving,”arXiv preprint arXiv:2205.09743, 2022
-
[7]
Planning-oriented Autonomous Driving,
Y. Hu, et al., “Planning-oriented Autonomous Driving,” in CVPR, 2023
2023
-
[8]
MaskBEV: Towards A Unified Framework for BEV Detection and Map Segmentation,
Y. Gao, et al., “MaskBEV: Towards A Unified Framework for BEV Detection and Map Segmentation,” inACM MM, 2024
2024
-
[9]
DriveTransformer: Unified Transformer for Scalable End-to-End Autonomous Driving,
S. Jia, et al., “DriveTransformer: Unified Transformer for Scalable End-to-End Autonomous Driving,”arXiv preprint arXiv:2312.02156, 2023
-
[10]
Deformable DETR: Deformable Transformers for End-to-End Object Detection,
X. Zhu, et al., “Deformable DETR: Deformable Transformers for End-to-End Object Detection,” inICLR, 2021
2021
-
[11]
DAB-DETR: Dynamic Anchor Boxes are Better Queries for DETR,
S. Liu, et al., “DAB-DETR: Dynamic Anchor Boxes are Better Queries for DETR,” inICLR, 2022
2022
-
[12]
Center-based 3D Object Detection and Tracking,
T. Yin, X. Zhou, P. Kr¨ ahenb¨ uhl, “Center-based 3D Object Detection and Tracking,” inCVPR, 2021
2021
-
[13]
Multi-task learning using uncertainty to weigh losses for scene geometry and semantics,
A. Kendall, Y. Gal, R. Cipolla, “Multi-task learning using uncertainty to weigh losses for scene geometry and semantics,” inCVPR, 2018
2018
-
[14]
GradNorm: Gradient Normalization for Adap- tive Loss Balancing in Deep Multitask Networks,
Z. Chen, et al., “GradNorm: Gradient Normalization for Adap- tive Loss Balancing in Deep Multitask Networks,” inICML, 2018
2018
-
[15]
Gradient Surgery for Multi-Task Learning,
T. Yu, et al., “Gradient Surgery for Multi-Task Learning,” in NeurIPS, 2020
2020
-
[16]
nuScenes: A Multimodal Dataset for Au- tonomous Driving,
H. Caesar, et al., “nuScenes: A Multimodal Dataset for Au- tonomous Driving,” inCVPR, 2020
2020
-
[17]
MMDetection3D: OpenMM- Lab next-generation platform for general 3D object detection,
MMDetection3D Contributors, “MMDetection3D: OpenMM- Lab next-generation platform for general 3D object detection,” https://github.com/open-mmlab/mmdetection3d, 2020
2020
-
[18]
CenterFusion: Center-based Radar and Cam- era Fusion for 3D Object Detection,
N. Nabati, H. Qi, “CenterFusion: Center-based Radar and Cam- era Fusion for 3D Object Detection,” inWACV, 2021
2021
-
[19]
CRAFT: Camera-Radar 3D Object Detection with Spatio-Contextual Fusion Transformer,
Y. Kim, et al., “CRAFT: Camera-Radar 3D Object Detection with Spatio-Contextual Fusion Transformer,” inAAAI, 2023
2023
-
[20]
RCBEVDet++: Toward High-Performance Radar-Camera Fusion 3D Perception,
L. Lin, et al., “RCBEVDet++: Toward High-Performance Radar-Camera Fusion 3D Perception,”arXiv preprint arXiv:2409.04979, 2024
-
[21]
BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird’s-Eye View Representation,
Z. Liu, et al., “BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird’s-Eye View Representation,” inICRA, 2023
2023
-
[22]
MetaBEV: Solving Sensor Failures for BEV Detection and Map Segmentation,
C. Ge, et al., “MetaBEV: Solving Sensor Failures for BEV Detection and Map Segmentation,” inICCV, 2023
2023
-
[23]
PAD-Net: Multi-Tasks Guided Prediction-and-Distillation Network for Simultaneous Depth Estimation and Scene Parsing,
D. Xu, W. Ouyang, X. Wang, N. Sebe, “PAD-Net: Multi-Tasks Guided Prediction-and-Distillation Network for Simultaneous Depth Estimation and Scene Parsing,” inCVPR, 2018
2018
-
[24]
MTI-Net: Multi- Scale Task Interaction Networks,
S. Vandenhende, S. Georgoulis, L. Van Gool, “MTI-Net: Multi- Scale Task Interaction Networks,” inECCV, 2020
2020
-
[25]
MTFormer: Multi-Task Learning via Transformer and Cross-Task Reasoning,
K. Xu, et al., “MTFormer: Multi-Task Learning via Transformer and Cross-Task Reasoning,” inECCV, 2022
2022
-
[26]
Inverted Pyramid Multi-task Transformer for Dense Scene Understanding,
H. Ye, D. Xu, “Inverted Pyramid Multi-task Transformer for Dense Scene Understanding,” inECCV, 2022
2022
-
[27]
TaskPrompter: Spatial-Channel Multi-Task Prompting for Dense Scene Understanding,
H. Ye, D. Xu, “TaskPrompter: Spatial-Channel Multi-Task Prompting for Dense Scene Understanding,” inICLR, 2023
2023
-
[28]
Z. Xie, et al., “M 2BEV: Multi-Camera Joint 3D Detection and Segmentation with Unified Bird’s-Eye View Representation,” arXiv preprint arXiv:2204.05088, 2022
-
[29]
PETRv2: A Unified Framework for 3D Percep- tion from Multi-Camera Images,
Y. Liu, et al., “PETRv2: A Unified Framework for 3D Percep- tion from Multi-Camera Images,” inICCV, 2023
2023
-
[30]
W. Sun, et al., “SparseDrive: End-to-End Autonomous Driving via Sparse Scene Representation,”arXiv preprint arXiv:2405.19620, 2024
-
[31]
M 3Net: Multi-Task Multi-Sensor Fusion with Multi-Query Initialization for Autonomous Driving,
Y. Chen, et al., “M 3Net: Multi-Task Multi-Sensor Fusion with Multi-Query Initialization for Autonomous Driving,” inAAAI, 2025
2025
-
[32]
Class-balanced grouping and sampling for point cloud 3d object detection,
C. Zhu, et al., “Class-balanced Grouping and Sampling for Point Cloud 3D Object Detection,”arXiv preprint arXiv:1908.09492, 2019
-
[33]
Feature Pyramid Networks for Object Detec- tion,
T.-Y. Lin, et al., “Feature Pyramid Networks for Object Detec- tion,” inCVPR, 2017
2017
-
[34]
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs,
L.-C. Chen, et al., “DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs,”IEEE TPAMI, vol. 40, no. 4, pp. 834–848, 2018
2018
-
[35]
Group Normalization,
Y. Wu, K. He, “Group Normalization,” inECCV, 2018
2018
-
[36]
HyDRa: End-to-End Multimodal 3D Object Detection with Hybrid Fusion,
L. Li, et al., “HyDRa: End-to-End Multimodal 3D Object Detection with Hybrid Fusion,” inCVPR, 2024
2024
-
[37]
CRT-Fusion: Camera, Radar, Temporal Fu- sion Using Motion Information for 3D Object Detection,
J. Jeon, et al., “CRT-Fusion: Camera, Radar, Temporal Fu- sion Using Motion Information for 3D Object Detection,” in NeurIPS, 2024
2024
-
[38]
RaCFormer: Towards High-Quality 3D Object Detection via Query-based Radar-Camera Fusion,
Z. Chu, et al., “RaCFormer: Towards High-Quality 3D Object Detection via Query-based Radar-Camera Fusion,” inCVPR, 2025
2025
-
[39]
HENet: Hybrid Encoding for End-to-end Multi- task 3D Perception from Multi-Camera Images,
Y. Li, et al., “HENet: Hybrid Encoding for End-to-end Multi- task 3D Perception from Multi-Camera Images,” inECCV, 2024
2024
-
[40]
FULLER: Unified Multi-Task Bird’s Eye View Representation Learning,
S. Borse, et al., “FULLER: Unified Multi-Task Bird’s Eye View Representation Learning,”arXiv preprint arXiv:2308.13961, 2023
-
[41]
Simple-BEV: What Really Matters for Multi-Sensor BEV Perception?,
A. W. Harley, et al., “Simple-BEV: What Really Matters for Multi-Sensor BEV Perception?,” inICRA, 2023
2023
-
[42]
BEVGuide: Radar-Camera Fusion for BEV Map Segmentation,
Y. Man, et al., “BEVGuide: Radar-Camera Fusion for BEV Map Segmentation,”arXiv preprint arXiv:2308.10280, 2023
-
[43]
RESAR-BEV, “An Explainable Progressive Residual Autore- gressive Approach for Camera-Radar Fusion in BEV Segmenta- tion,”arXiv preprint arXiv:2505.06515, 2025
-
[44]
Multi-modal multi-task (3MT) road segmentation,
E. Milli, ¨O. Erkent, A. E. Yılmaz, “Multi-modal multi-task (3MT) road segmentation,”IEEE Robotics and Automation Letters, vol. 8, no. 9, pp. 5408–5415, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.