Recognition: 1 theorem link
· Lean TheoremPi-HOC: Pairwise 3D Human-Object Contact Estimation
Pith reviewed 2026-05-13 00:49 UTC · model grok-4.3
The pith
Pi-HOC estimates dense 3D contacts between all humans and objects in a scene using pairwise tokens and an InteractionFormer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
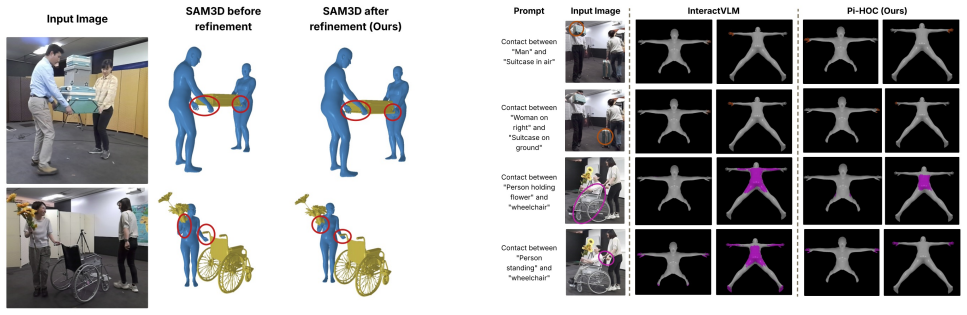
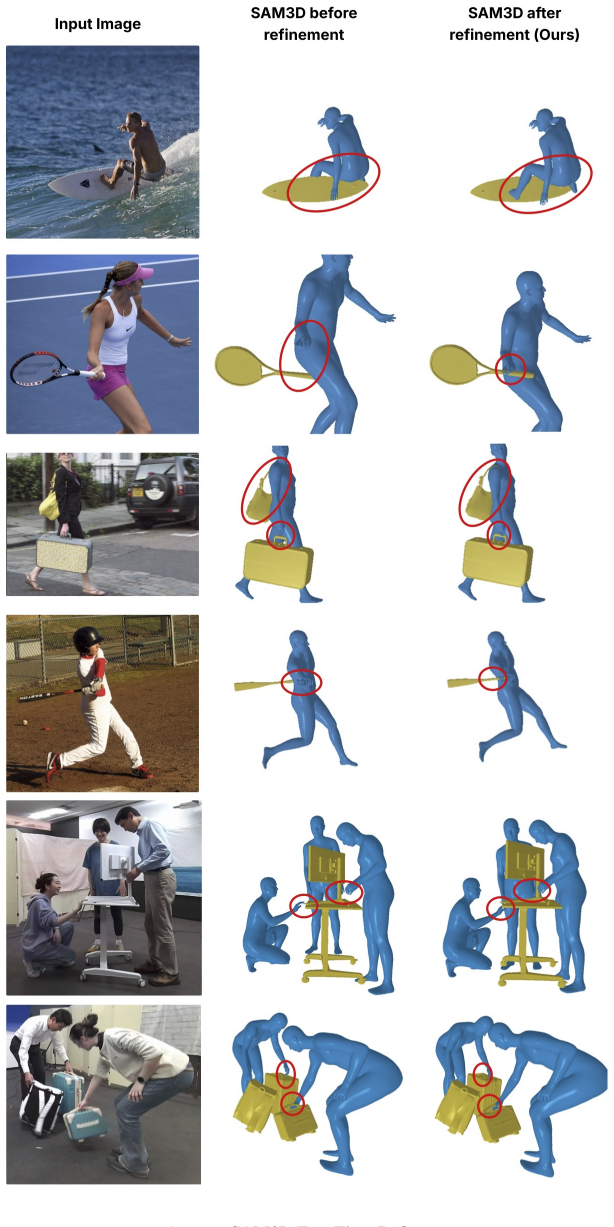
Pi-HOC is a single-pass, instance-aware framework for dense 3D semantic contact prediction of all human-object pairs. It detects instances, creates dedicated human-object (HO) tokens for each pair, refines them using an InteractionFormer, and applies a SAM-based decoder to predict dense contact on SMPL human meshes for each pair. On the MMHOI and DAMON datasets, Pi-HOC significantly improves accuracy and localization over state-of-the-art methods while achieving 20x higher throughput. Predicted contacts also improve SAM-3D image-to-mesh reconstruction via test-time optimization and support referential contact prediction from language queries without additional training.
What carries the argument
Dedicated human-object (HO) tokens for each instance pair, refined by the InteractionFormer to handle concurrent contacts in multi-human scenes.
Load-bearing premise
Dedicated HO tokens and the InteractionFormer can reliably disentangle fine-grained concurrent contacts in multi-human scenes without object meshes or additional geometric inputs.
What would settle it
Running Pi-HOC on a test set of multi-human scenes with annotated ground-truth 3D contacts and observing whether the reported gains in accuracy and speed persist when no object meshes are supplied as input.
Figures









read the original abstract
Resolving real-world human-object interactions in images is a many-to-many challenge, in which disentangling fine-grained concurrent physical contact is particularly difficult. Existing semantic contact estimation methods are either limited to single-human settings or require object geometries (e.g., meshes) in addition to the input image. Current state-of-the-art leverages powerful VLM for category-level semantics but struggles with multi-human scenarios and scales poorly in inference. We introduce Pi-HOC, a single-pass, instance-aware framework for dense 3D semantic contact prediction of all human-object pairs. Pi-HOC detects instances, creates dedicated human-object (HO) tokens for each pair, and refines them using an InteractionFormer. A SAM-based decoder then predicts dense contact on SMPL human meshes for each human-object pair. On the MMHOI and DAMON datasets, Pi-HOC significantly improves accuracy and localization over state-of-the-art methods while achieving 20x higher throughput. We further demonstrate that predicted contacts improve SAM-3D image-to-mesh reconstruction via a test-time optimization algorithm and enable referential contact prediction from language queries without additional training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Pi-HOC, a single-pass instance-aware framework for dense 3D semantic contact prediction of all human-object pairs. It detects instances, creates dedicated human-object (HO) tokens for each pair, refines them using an InteractionFormer, and applies a SAM-based decoder to predict dense contacts on SMPL human meshes. The approach avoids object meshes or additional geometric inputs. On the MMHOI and DAMON datasets, it claims significant accuracy and localization improvements over state-of-the-art methods along with 20x higher throughput. Additional results show utility for test-time optimization in SAM-3D reconstruction and referential contact prediction from language queries without retraining.
Significance. If the performance and efficiency claims hold, Pi-HOC would advance human-object interaction modeling in computer vision by enabling scalable, mesh-free contact estimation in multi-human scenes. The single-pass design and downstream applications to reconstruction and language-driven prediction add practical value for robotics, AR, and scene understanding tasks.
major comments (2)
- Abstract: the claim of significant accuracy improvements and 20x throughput is stated without any quantitative numbers, error bars, ablation studies, or comparison tables, preventing evaluation of the central performance claim from the provided text.
- Method section (HO token and InteractionFormer construction): the mechanism for creating and refining dedicated HO tokens to disentangle fine-grained concurrent contacts in multi-human scenes without object meshes requires explicit equations or algorithmic details to confirm it avoids circularity or reliance on unstated priors.
minor comments (2)
- Ensure all acronyms (VLM, SAM, SMPL, MMHOI, DAMON) are defined at first use in the introduction and method sections.
- The related work section should include more recent baselines for pairwise contact estimation to strengthen the positioning of Pi-HOC.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each major comment point by point below.
read point-by-point responses
-
Referee: Abstract: the claim of significant accuracy improvements and 20x throughput is stated without any quantitative numbers, error bars, ablation studies, or comparison tables, preventing evaluation of the central performance claim from the provided text.
Authors: We agree that the abstract would benefit from including specific quantitative highlights to support the performance claims more directly. In the revised manuscript, we will update the abstract to incorporate key metrics from our experiments, such as the accuracy and localization improvements on MMHOI and DAMON along with the measured 20x throughput gain. The full quantitative results, including tables, error bars, ablations, and comparisons, are already detailed in Sections 4 and 5. revision: yes
-
Referee: Method section (HO token and InteractionFormer construction): the mechanism for creating and refining dedicated HO tokens to disentangle fine-grained concurrent contacts in multi-human scenes without object meshes requires explicit equations or algorithmic details to confirm it avoids circularity or reliance on unstated priors.
Authors: Section 3 of the manuscript describes the HO token construction and InteractionFormer in detail: instance features from the detector are paired to form dedicated HO tokens for each human-object combination, which are then refined through the InteractionFormer's attention layers to model concurrent contacts in multi-human scenes. This operates exclusively on image-based instance features and does not use object meshes or introduce circular dependencies. To further strengthen clarity, we will add explicit equations for token creation and refinement along with pseudocode in the revised method section. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents Pi-HOC as a forward neural architecture: instance detection followed by creation of dedicated HO tokens per human-object pair, refinement via InteractionFormer, and dense contact prediction via SAM-based decoder on SMPL meshes. No equations, self-definitional loops, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described pipeline. Performance claims rest on empirical results over external datasets (MMHOI, DAMON) rather than any reduction of outputs to inputs by construction. The derivation is therefore self-contained as a standard end-to-end model without circular steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption SMPL body model provides accurate 3D human surface for contact mapping
- domain assumption SAM decoder can be repurposed for dense contact prediction without retraining from scratch
invented entities (1)
-
Human-object (HO) tokens
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Pi-HOC detects instances, creates dedicated human-object (HO) tokens for each pair, and refines them using an InteractionFormer. A SAM-based decoder then predicts dense contact on SMPL human meshes
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Yu Cao, Yang Li, Ke Zhang, Ziwei Liu, Yaojie Chen, Jian- feng Gao, and Hao Li. Unihoi: Detecting any human-object interaction relationship: Universal hoi detector with spatial prompt learning on foundation models. InAdvances in Neu- ral Information Processing Systems (NeurIPS), 2023. 2
work page 2023
-
[2]
End-to- end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to- end object detection with transformers. InEuropean Confer- ence on Computer Vision (ECCV), 2020. 2, 3, 11
work page 2020
-
[3]
Detecting human-object contact in im- ages
Weitong Chen et al. Detecting human-object contact in im- ages. InarXiv preprint arXiv:2303.03373, 2023. 2
-
[4]
Lakshmipathy, Agniv Chatterjee, Michael J
Alp ´ar Cseke, Shashank Tripathi, Sai Kumar Dwivedi, Ar- jun S. Lakshmipathy, Agniv Chatterjee, Michael J. Black, and Dimitrios Tzionas. Pico: Reconstructing 3d people in contact with objects. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1783–1794, 2025. 1
work page 2025
-
[5]
A. Dwivedi et al. Interactvlm: Multi-object human contact reasoning with vision-language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 1, 2, 3, 4, 5, 8, 11, 12, 13, 14
work page 2025
-
[6]
Learning complex 3d human self-contact
Mihai Fieraru, Mihai Zanfir, Elisabeta Oneata, Alin-Ionut Popa, Vlad Olaru, and Cristian Sminchisescu. Learning complex 3d human self-contact. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), pages 1343– 1351, 2021. 2
work page 2021
-
[7]
Mohamed Hassan, Vasileios Choutas, Dimitrios Tzionas, and Michael J. Black. Resolving 3d human pose ambiguities with 3d scene constraints. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019. 1
work page 2019
-
[8]
Learning to dress: Pose and shape awareness for 3d human-scene contact
Mohamed Hassan et al. Learning to dress: Pose and shape awareness for 3d human-scene contact. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021. 2
work page 2021
-
[9]
Chun-Hao P. Huang et al. Capturing and inferring dense full- body human-scene contact. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022. 2, 5
work page 2022
-
[10]
Hotr: End-to-end human-object interaction detection with transformers
Bumsoo Kim, Jaeho Lee, Jaeho Jeong, and Gunhee Lee. Hotr: End-to-end human-object interaction detection with transformers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021. 2
work page 2021
-
[11]
Lain: Locality-aware interaction net- work for human-object interaction detection
Hyunwoo Kim, Jangho Jeong, Bumsoo Kim, Jaeho Jeong, and Gunhee Lee. Lain: Locality-aware interaction net- work for human-object interaction detection. arXiv preprint arXiv:2505.19503, 2025. 2
-
[12]
Berg, Wan-Yen Lo, Piotr Doll ´ar, and Ross Girshick
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C. Berg, Wan-Yen Lo, Piotr Doll ´ar, and Ross Girshick. Segment anything. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023. 11
work page 2023
-
[13]
Mmhoi: Modeling complex 3d multi-human multi-object in- teractions, 2025
Kaen Kogashi, Anoop Cherian, and Meng-Yu Jennifer Kuo. Mmhoi: Modeling complex 3d multi-human multi-object in- teractions, 2025. 1, 5, 11
work page 2025
-
[14]
Efficient adaptive human-object inter- action detection with concept-guided memory, 2023
Ting Lei, Fabian Caba, Qingchao Chen, Hailin Ji, Yuxin Peng, and Yang Liu. Efficient adaptive human-object inter- action detection with concept-guided memory, 2023. 2
work page 2023
-
[15]
Bilateral adaptation for human-object interac- tion detection with occlusion-robustness
Yu Li, Kang Li, Qian Wang, Wen Liu, Huazhu Xu, and Lingxi Xie. Bilateral adaptation for human-object interac- tion detection with occlusion-robustness. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 2
work page 2024
-
[16]
Focal loss for dense object detection
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Doll´ar. Focal loss for dense object detection. InPro- ceedings of the IEEE International Conference on Computer Vision (ICCV), 2017. 12
work page 2017
-
[17]
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection.arXiv preprint arXiv:2303.05499, 2023. 8
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Yumeng Liu, Xiaoxiao Long, Zemin Yang, Yuan Liu, Marc Habermann, Christian Theobalt, Yuexin Ma, and Wenping Wang. Easyhoi: Unleashing the power of large models for reconstructing hand-object interactions in the wild.arXiv preprint arXiv:2411.14280, 2024. 2
-
[19]
Joint optimization for 4d human-scene reconstruction in the wild
Zhizheng Liu, Joe Lin, Wayne Wu, and Bolei Zhou. Joint optimization for 4d human-scene reconstruction in the wild. The Fourteenth International Conference on Learning Rep- resentations, 2026. 1
work page 2026
-
[20]
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J. Black. Smpl: A skinned multi- person linear model.ACM Transactions on Graphics, 34(6): 248:1–248:16, 2015. 1, 2, 3, 11
work page 2015
-
[21]
Lea M ¨uller, Ahmed A. A. Osman, Siyu Tang, Chun-Hao P. Huang, and Michael J. Black. On self-contact and human pose. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 9990– 9999, 2021. 2
work page 2021
-
[22]
Contho: Contact-aware 3d reconstruc- tion of interacting hands and objects from monocular rgb
Jaehyun Nam et al. Contho: Contact-aware 3d reconstruc- tion of interacting hands and objects from monocular rgb. In arXiv preprint arXiv:2404.04819, 2024. 1, 2
-
[23]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaa El-Nouby, et al. Di- nov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 3, 11
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine Learning,
-
[25]
Hulc: 3d human mo- 9 tion capture with pose manifold sampling and dense con- tact guidance
Soshi Shimada, Vladislav Golyanik, Zhi Li, Patrick P ´erez, Weipeng Xu, and Christian Theobalt. Hulc: 3d human mo- 9 tion capture with pose manifold sampling and dense con- tact guidance. InEuropean Conference on Computer Vision (ECCV), pages 516–533, 2022. 2
work page 2022
-
[26]
Carole Helene Sudre, Wenqi Li, Tom Kamiel Magda Ver- cauteren, S´ebastien Ourselin, and M. Jorge Cardoso. Gener- alised dice overlap as a deep learning loss function for highly unbalanced segmentations.Deep learning in medical im- age analysis and multimodal learning for clinical decision support : Third International Workshop, DLMIA 2017, and 7th Interna...
work page 2017
-
[27]
Sam 3d: 3dfy anything in images
SAM 3D Team, Xingyu Chen, Fu-Jen Chu, Pierre Gleize, Kevin J Liang, Alexander Sax, Hao Tang, Weiyao Wang, Michelle Guo, Thibaut Hardin, Xiang Li, Aohan Lin, Jiawei Liu, Ziqi Ma, Anushka Sagar, Bowen Song, Xiaodong Wang, Jianing Yang, Bowen Zhang, Piotr Doll´ar, Georgia Gkioxari, Matt Feiszli, and Jitendra Malik. Sam 3d: 3dfy anything in images. 2025. 1, 7, 12
work page 2025
-
[28]
Shashank Tripathi, Agniv Chatterjee, Jean-Claude Passy, Hongwei Yi, Dimitrios Tzionas, and Michael J. Black. DECO: Dense estimation of 3D human-scene contact in the wild. InProceedings of the IEEE/CVF International Confer- ence on Computer Vision (ICCV), pages 8001–8013, 2023. 1, 2, 5, 7, 11, 12, 14
work page 2023
-
[29]
Clipself: Vision trans- former distills itself for open-vocabulary dense prediction
Size Wu, Wenwei Zhang, Lumin Xu, Sheng Jin, Xiangtai Li, Wentao Liu, and Chen Change Loy. Clipself: Vision trans- former distills itself for open-vocabulary dense prediction. arXiv preprint arXiv:2310.01403, 2023. 7
-
[30]
Chore: Contact, human and object reconstruction from a sin- gle rgb image
Xianghui Xie, Bharat Lal Bhatnagar, and Gerard Pons-Moll. Chore: Contact, human and object reconstruction from a sin- gle rgb image. InEuropean Conference on Computer Vision (ECCV). Springer, 2022. 1
work page 2022
-
[31]
Physic: Physically plausible 3d human-scene interaction and contact from a single image
Pradyumna Yalandur Muralidhar, Yuxuan Xue, Xianghui Xie, Margaret Kostyrko, and Gerard Pons-Moll. Physic: Physically plausible 3d human-scene interaction and contact from a single image. 2025. 1
work page 2025
-
[32]
Sam 3d body: Robust full-body human mesh recovery.arXiv preprint arXiv:2602.15989,
Xitong Yang, Devansh Kukreja, Don Pinkus, Anushka Sagar, Taosha Fan, Jinhyung Park, Soyong Shin, Jinkun Cao, Jiawei Liu, Nicolas Ugrinovic, Matt Feiszli, Jitendra Malik, Piotr Dollar, and Kris Kitani. Sam 3d body: Robust full-body hu- man mesh recovery.arXiv preprint arXiv:2602.15989, 2026. 1, 7, 12
-
[33]
Lemon: Learning 3d human-object in- teraction relation from 2d images
Yuhang Yang, Wei Zhai, Hongchen Luo, Yang Cao, and Zheng-Jun Zha. Lemon: Learning 3d human-object in- teraction relation from 2d images. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16284–16295, 2024. 2
work page 2024
-
[34]
Unary-pairwise transformer for human-object interaction detection
Aixin Zhang, Yi Wang, Guoliang Cai, Xinyu Ding, Jian Jin, Bin Wang, and Yuxin Wu. Unary-pairwise transformer for human-object interaction detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022. 2
work page 2022
-
[35]
COINS: Compositional human-scene interaction synthesis with semantic control
Kaifeng Zhao, Shaofei Wang, Yan Zhang, Thabo Beeler, and Siyu Tang. COINS: Compositional human-scene interaction synthesis with semantic control. InEuropean conference on computer vision (ECCV), 2022. 1
work page 2022
-
[36]
Regionclip: Region- based language-image pretraining
Yiwu Zhong, Jianwei Yang, Pengchuan Zhang, Chun- yuan Li, Noel Codella, Liunian Harold Li, Luowei Zhou, Xiyang Dai, Lu Yuan, Yin Li, et al. Regionclip: Region- based language-image pretraining. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16793–16803, 2022. 7 10 Appendix Table 5.DAMON Semantic Contact Results....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.