Recognition: unknown
Direct Discrepancy Replay: Distribution-Discrepancy Condensation and Manifold-Consistent Replay for Continual Face Forgery Detection
Pith reviewed 2026-05-10 14:46 UTC · model grok-4.3
The pith
By condensing real-to-fake discrepancies into a small map bank and composing them with new real faces, a detector can replay prior forgery distributions without storing old images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the real-to-fake discrepancy can be directly condensed via a surrogate factorization in characteristic-function space into a tiny bank of distribution discrepancy maps; these maps can then be recombined, variance-preservingly, with real faces from the current training stage to synthesize replay samples that reinstate the distributions of previous forgery tasks, thereby enabling continual learning without storing raw historical images or relying on detector-dependent perturbations.
What carries the argument
Distribution-Discrepancy Condensation (DDC), which factors the real-to-fake gap in characteristic-function space and stores the result as compact maps, paired with Manifold-Consistent Replay (MCR), which performs variance-preserving composition of those maps with current real faces to generate compatible replay samples.
If this is right
- Detectors can acquire new forgery paradigms while retaining performance on earlier ones under extremely limited memory.
- Raw historical face images no longer need to be stored, lowering both storage cost and identity exposure.
- Replay operates at the distribution level rather than depending on past decision boundaries or individual samples.
- The method yields higher overall detection accuracy than prior continual face forgery baselines across multiple task sequences.
Where Pith is reading between the lines
- The same condensation-plus-composition pattern could be tested in other continual image-classification settings where the key shift is between real and manipulated distributions.
- If the characteristic-function factorization captures forgery invariants that are independent of face identity, the maps might transfer across different face datasets without retraining.
- Applying the variance-preserving composition step to non-face domains such as document or medical-image forgery would test whether the manifold-consistency property holds beyond faces.
Load-bearing premise
The surrogate factorization of the real-to-fake discrepancy in characteristic-function space, when composed variance-preservingly with current real faces, sufficiently recreates previous forgery distributions without introducing harmful artifacts or losing critical cues.
What would settle it
A controlled sequence of forgery tasks in which accuracy on the earliest tasks falls below that of an equal-memory baseline that stores raw historical samples would show the claim fails.
Figures



read the original abstract
Continual face forgery detection (CFFD) requires detectors to learn emerging forgery paradigms without forgetting previously seen manipulations. Existing CFFD methods commonly rely on replaying a small amount of past data to mitigate forgetting. Such replay is typically implemented either by storing a few historical samples or by synthesizing pseudo-forgeries from detector-dependent perturbations. Under strict memory budgets, the former cannot adequately cover diverse forgery cues and may expose facial identities, while the latter remains strongly tied to past decision boundaries. We argue that the core role of replay in CFFD is to reinstate the distributions of previous forgery tasks during subsequent training. To this end, we directly condense the discrepancy between real and fake distributions and leverage real faces from the current stage to perform distribution-level replay. Specifically, we introduce Distribution-Discrepancy Condensation (DDC), which models the real-to-fake discrepancy via a surrogate factorization in characteristic-function space and condenses it into a tiny bank of distribution discrepancy maps. We further propose Manifold-Consistent Replay (MCR), which synthesizes replay samples through variance-preserving composition of these maps with current-stage real faces, yielding samples that reflect previous-task forgery cues while remaining compatible with current real-face statistics. Operating under an extremely small memory budget and without directly storing raw historical face images, our framework consistently outperforms prior CFFD baselines and significantly mitigates catastrophic forgetting. Replay-level privacy analysis further suggests reduced identity leakage risk relative to selection-based replay.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Direct Discrepancy Replay for continual face forgery detection (CFFD). It introduces Distribution-Discrepancy Condensation (DDC) to model the real-to-fake discrepancy via surrogate factorization in characteristic-function space and condense it into a tiny bank of distribution discrepancy maps, together with Manifold-Consistent Replay (MCR) that synthesizes replay samples through variance-preserving composition of these maps with current-stage real faces. The framework operates without storing raw historical images, claims consistent outperformance over prior CFFD baselines, significant mitigation of catastrophic forgetting, and reduced identity leakage under strict memory budgets.
Significance. If the central mechanism holds, the work offers a memory-efficient and privacy-preserving alternative to sample-replay or perturbation-based methods in continual forgery detection by directly replaying condensed distribution discrepancies. The characteristic-function approach to discrepancy modeling is a distinctive technical choice that avoids direct data storage. Credit is due for the explicit privacy analysis and the attempt to ground replay in distribution reinstatement rather than decision-boundary perturbations.
major comments (2)
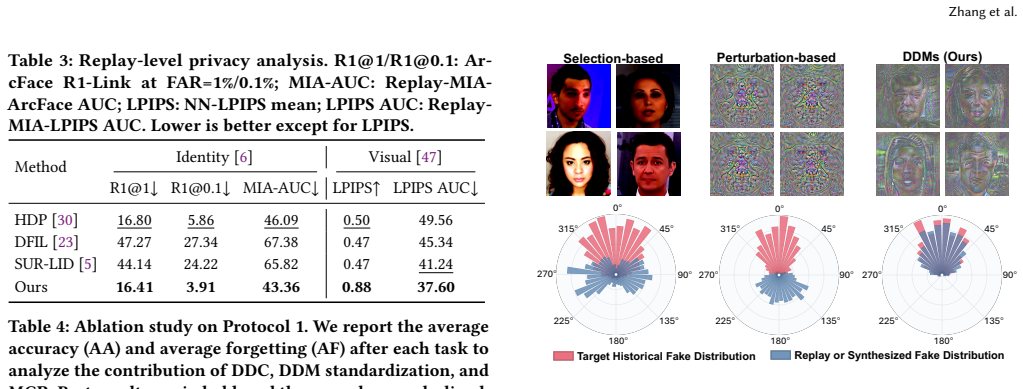
- [DDC and MCR descriptions] The load-bearing assumption of the framework is that the surrogate factorization in characteristic-function space (DDC) followed by variance-preserving composition (MCR) reinstates historical real-to-fake discrepancy distributions closely enough to prevent forgetting. Characteristic functions encode global moment information; the manuscript must demonstrate that localized, high-frequency forgery cues (e.g., blending boundaries, frequency inconsistencies) are not smoothed or omitted in the condensed maps and composed samples. Without such verification the outperformance could arise from regularization rather than true distribution replay.
- [Experimental evaluation] The strongest claim (consistent outperformance and forgetting mitigation under extremely small memory budgets) requires quantitative support that the replay samples induce detector behavior comparable to historical data. The manuscript should report distribution-distance metrics or ablation results comparing replay-induced performance against both stored-sample baselines and current-task-only training to isolate the contribution of the condensed discrepancy maps.
minor comments (2)
- The abstract asserts quantitative superiority yet supplies no numerical results, dataset sizes, or memory budgets; including at least headline numbers would strengthen the summary.
- Notation for the characteristic-function factorization and the variance-preserving operator should be introduced with explicit equations to allow readers to verify the claimed parameter-free nature of the condensation step.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the privacy-preserving and memory-efficient aspects of our framework. We address each major comment below with clarifications and commitments to strengthen the manuscript.
read point-by-point responses
-
Referee: The load-bearing assumption of the framework is that the surrogate factorization in characteristic-function space (DDC) followed by variance-preserving composition (MCR) reinstates historical real-to-fake discrepancy distributions closely enough to prevent forgetting. Characteristic functions encode global moment information; the manuscript must demonstrate that localized, high-frequency forgery cues (e.g., blending boundaries, frequency inconsistencies) are not smoothed or omitted in the condensed maps and composed samples. Without such verification the outperformance could arise from regularization rather than true distribution replay.
Authors: We agree that explicit verification is needed to confirm that localized cues are retained rather than the gains arising solely from regularization. The surrogate factorization operates on the characteristic function to isolate discrepancy components, and the variance-preserving composition in MCR is explicitly designed to maintain statistical compatibility while transferring forgery-specific patterns. The manuscript already presents qualitative evidence through sample visualizations showing preservation of blending boundaries and frequency artifacts in the replayed images. To directly address the concern, we will add quantitative frequency-domain analysis (e.g., power spectrum comparisons) and additional ablations in the revised version. revision: partial
-
Referee: The strongest claim (consistent outperformance and forgetting mitigation under extremely small memory budgets) requires quantitative support that the replay samples induce detector behavior comparable to historical data. The manuscript should report distribution-distance metrics or ablation results comparing replay-induced performance against both stored-sample baselines and current-task-only training to isolate the contribution of the condensed discrepancy maps.
Authors: We acknowledge that stronger isolation of the replay contribution would bolster the claims. Our current evaluation already demonstrates consistent outperformance over stored-sample replay baselines under identical memory budgets and reports standard forgetting metrics across sequential tasks. To provide the requested quantitative support, we will incorporate distribution-distance metrics (such as MMD between replay samples and historical distributions) and explicit ablations contrasting DDC+MCR replay against current-task-only training in the revised manuscript. revision: yes
Circularity Check
No circularity: method introduced as independent proposal
full rationale
The paper proposes DDC (surrogate factorization of real-to-fake discrepancy in characteristic-function space, condensed to maps) and MCR (variance-preserving composition with current real faces) as new techniques for replay in CFFD. These are defined and motivated directly from the problem of reinstating prior distributions without storing raw images, without any equations or claims reducing the central result to a fitted parameter, self-referential definition, or load-bearing self-citation. The derivation chain is self-contained as an engineering proposal grounded in distribution modeling, with performance claims left to empirical validation rather than constructed equivalence.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2017.Probability and measure
Patrick Billingsley. 2017.Probability and measure. John Wiley & Sons
2017
-
[2]
Stella Bounareli, Christos Tzelepis, Vasileios Argyriou, Ioannis Patras, and Geor- gios Tzimiropoulos. 2023. Stylemask: Disentangling the style space of stylegan2 for neural face reenactment. In2023 IEEE 17th international conference on auto- matic face and gesture recognition (FG). IEEE, 1–8
2023
-
[3]
George Cazenavette, Tongzhou Wang, Antonio Torralba, Alexei A Efros, and Jun-Yan Zhu. 2022. Dataset distillation by matching training trajectories. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 4750–4759
2022
-
[4]
Arslan Chaudhry, Marcus Rohrbach, Mohamed Elhoseiny, Thalaiyasingam Ajan- than, Puneet K Dokania, Philip HS Torr, and Marc’Aurelio Ranzato. 2019. On tiny episodic memories in continual learning.arXiv preprint arXiv:1902.10486 (2019)
work page Pith review arXiv 2019
-
[5]
Jikang Cheng, Zhiyuan Yan, Ying Zhang, Li Hao, Jiaxin Ai, Qin Zou, Chen Li, and Zhongyuan Wang. 2025. Stacking brick by brick: Aligned feature isolation for incremental face forgery detection. InProceedings of the Computer Vision and Pattern Recognition Conference. 13927–13936
2025
-
[6]
Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. 2019. Arcface: Additive angular margin loss for deep face recognition. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 4690–4699
2019
-
[7]
Brian Dolhansky, Joanna Bitton, Ben Pflaum, Jikuo Lu, Russ Howes, Menglin Wang, and Cristian Canton Ferrer. 2020. The deepfake detection challenge (dfdc) dataset.arXiv preprint arXiv:2006.07397(2020)
work page internal anchor Pith review arXiv 2020
-
[8]
Nick Dufour and Andrew Gully. 2019. Contributing data to deepfake detection research.Google AI Blog1, 2 (2019), 3
2019
- [9]
-
[10]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models.Advances in neural information processing systems33 (2020), 6840–6851
2020
-
[11]
Fa-Ting Hong and Dan Xu. 2023. Implicit identity representation conditioned memory compensation network for talking head video generation. InProceedings of the IEEE/CVF international conference on computer vision. 23062–23072
2023
-
[12]
Tero Karras, Miika Aittala, Samuli Laine, Erik Härkönen, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. 2021. Alias-free generative adversarial networks. Advances in neural information processing systems34 (2021), 852–863
2021
-
[13]
Gyeongman Kim, Hajin Shim, Hyunsu Kim, Yunjey Choi, Junho Kim, and Eunho Yang. 2023. Diffusion video autoencoders: Toward temporally consistent face video editing via disentangled video encoding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 6091–6100
2023
-
[14]
Minha Kim, Shahroz Tariq, and Simon S Woo. 2021. Cored: Generalizing fake media detection with continual representation using distillation. InProceedings of the 29th ACM International Conference on Multimedia. 337–346
2021
-
[15]
Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic opti- mization.arXiv preprint arXiv:1412.6980(2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[16]
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. 2017. Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences114, 13 (2017), 3521– 3526
2017
- [17]
-
[18]
Yuezun Li, Xin Yang, Pu Sun, Honggang Qi, and Siwei Lyu. 2020. Celeb-df: A large-scale challenging dataset for deepfake forensics. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 3207–3216
2020
-
[19]
Zhizhong Li and Derek Hoiem. 2017. Learning without forgetting.IEEE transac- tions on pattern analysis and machine intelligence40, 12 (2017), 2935–2947
2017
-
[20]
David Lopez-Paz and Marc’Aurelio Ranzato. 2017. Gradient episodic memory for continual learning.Advances in neural information processing systems30 (2017)
2017
-
[21]
Seyed-Mohsen Moosavi-Dezfooli, Alhussein Fawzi, Omar Fawzi, and Pascal Frossard. 2017. Universal adversarial perturbations. InProceedings of the IEEE conference on computer vision and pattern recognition. 1765–1773
2017
-
[22]
Alexander Quinn Nichol and Prafulla Dhariwal. 2021. Improved denoising diffusion probabilistic models. InInternational conference on machine learning. PMLR, 8162–8171
2021
-
[23]
Kun Pan, Yifang Yin, Yao Wei, Feng Lin, Zhongjie Ba, Zhenguang Liu, Zhibo Wang, Lorenzo Cavallaro, and Kui Ren. 2023. Dfil: Deepfake incremental learning by exploiting domain-invariant forgery clues. InProceedings of the 31st ACM International Conference on Multimedia. 8035–8046
2023
-
[24]
Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H Lampert. 2017. icarl: Incremental classifier and representation learning. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 2001–2010
2017
-
[25]
Anthony Robins. 1995. Catastrophic forgetting, rehearsal and pseudorehearsal. Connection Science7, 2 (1995), 123–146
1995
-
[26]
Andreas Rossler, Davide Cozzolino, Luisa Verdoliva, Christian Riess, Justus Thies, and Matthias Nießner. 2019. Faceforensics++: Learning to detect manipulated facial images. InProceedings of the IEEE/CVF international conference on computer vision. 1–11
2019
-
[27]
Hanul Shin, Jung Kwon Lee, Jaehong Kim, and Jiwon Kim. 2017. Continual learning with deep generative replay.Advances in neural information processing systems30 (2017)
2017
-
[28]
Kaede Shiohara and Toshihiko Yamasaki. 2022. Detecting deepfakes with self- blended images. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 18720–18729
2022
-
[29]
Kaede Shiohara, Xingchao Yang, and Takafumi Taketomi. 2023. Blendface: Re- designing identity encoders for face-swapping. InProceedings of the IEEE/CVF international conference on computer vision. 7634–7644
2023
-
[30]
Ke Sun, Shen Chen, Taiping Yao, Xiaoshuai Sun, Shouhong Ding, and Rongrong Ji. 2025. Continual face forgery detection via historical distribution preserving. International Journal of Computer Vision133, 3 (2025), 1067–1084
2025
-
[31]
Mingxing Tan and Quoc Le. 2019. Efficientnet: Rethinking model scaling for convolutional neural networks. InInternational conference on machine learning. PMLR, 6105–6114
2019
-
[32]
Justus Thies, Michael Zollhöfer, and Matthias Nießner. 2019. Deferred neural rendering: Image synthesis using neural textures.ACM Transactions on Graphics (TOG)38, 4 (2019), 1–12
2019
-
[33]
Justus Thies, Michael Zollhofer, Marc Stamminger, Christian Theobalt, and Matthias Nießner. 2016. Face2face: Real-time face capture and reenactment of rgb videos. InProceedings of the IEEE conference on computer vision and pattern recognition. 2387–2395
2016
-
[34]
Jiahe Tian, Cai Yu, Xi Wang, Peng Chen, Zihao Xiao, Jizhong Han, and Yesheng Chai. 2024. Dynamic Mixed-Prototype Model for Incremental Deepfake Detec- tion. InProceedings of the 32nd ACM International Conference on Multimedia. 8129–8138
2024
-
[35]
Vikas Verma, Alex Lamb, Christopher Beckham, Amir Najafi, Ioannis Mitliagkas, David Lopez-Paz, and Yoshua Bengio. 2019. Manifold mixup: Better represen- tations by interpolating hidden states. InInternational conference on machine learning. PMLR, 6438–6447
2019
-
[36]
Kai Wang, Bo Zhao, Xiangyu Peng, Zheng Zhu, Shuo Yang, Shuo Wang, Guan Huang, Hakan Bilen, Xinchao Wang, and Yang You. 2022. Cafe: Learning to condense dataset by aligning features. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 12196–12205
2022
-
[37]
Shaobo Wang, Yicun Yang, Zhiyuan Liu, Chenghao Sun, Xuming Hu, Conghui He, and Linfeng Zhang. 2025. Dataset distillation with neural characteristic function: A minmax perspective. InProceedings of the Computer Vision and Pattern Recognition Conference. 25570–25580
2025
- [38]
- [39]
-
[40]
Zhiliang Xu, Hang Zhou, Zhibin Hong, Ziwei Liu, Jiaming Liu, Zhizhi Guo, Junyu Han, Jingtuo Liu, Errui Ding, and Jingdong Wang. 2022. Styleswap: Style-based generator empowers robust face swapping. InEuropean Conference on Computer Vision. Springer, 661–677
2022
-
[41]
Shipeng Yan, Jiangwei Xie, and Xuming He. 2021. Der: Dynamically expandable representation for class incremental learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 3014–3023
2021
- [42]
-
[43]
Zhiyuan Yan, Yong Zhang, Xinhang Yuan, Siwei Lyu, and Baoyuan Wu. 2023. DeepfakeBench: A Comprehensive Benchmark of Deepfake Detection. InAd- vances in Neural Information Processing Systems, A. Oh, T. Neumann, A. Glober- son, K. Saenko, M. Hardt, and S. Levine (Eds.), Vol. 36. Curran Associates, Inc., 4534–4565. https://proceedings.neurips.cc/paper_files/...
2023
-
[44]
Friedemann Zenke, Ben Poole, and Surya Ganguli. 2017. Continual learning through synaptic intelligence. InInternational conference on machine learning. PMLR, 3987–3995
2017
-
[45]
Hongyi Zhang, Moustapha Cisse, Yann N Dauphin, and David Lopez-Paz. 2017. mixup: Beyond empirical risk minimization.arXiv preprint arXiv:1710.09412 (2017)
work page internal anchor Pith review arXiv 2017
-
[46]
Hansong Zhang, Shikun Li, Pengju Wang, Dan Zeng, and Shiming Ge. 2024. M3d: Dataset condensation by minimizing maximum mean discrepancy. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 9314–9322
2024
-
[47]
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang
-
[48]
InProceedings of the IEEE conference on computer vision and pattern recognition
The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition. 586–595. 9 Zhang et al
-
[49]
Tianshuo Zhang, Siran Peng, Li Gao, Haoyuan Zhang, Xiangyu Zhu, and Zhen Lei. 2026. Unifying Locality of KANs and Feature Drift Compensation Projection for Data-free Replay based Continual Face Forgery Detection. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 12771–12779
2026
-
[50]
Bo Zhao and Hakan Bilen. 2021. Dataset condensation with differentiable siamese augmentation. InInternational Conference on Machine Learning. PMLR, 12674– 12685
2021
-
[51]
Bo Zhao and Hakan Bilen. 2023. Dataset condensation with distribution matching. InProceedings of the IEEE/CVF winter conference on applications of computer vision. 6514–6523
2023
- [52]
-
[53]
Ganlong Zhao, Guanbin Li, Yipeng Qin, and Yizhou Yu. 2023. Improved distribu- tion matching for dataset condensation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 7856–7865. 10
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.