Recognition: unknown
Personalizing LLM-Based Conversational Programming Assistants
Pith reviewed 2026-05-10 14:30 UTC · model grok-4.3
The pith
Characterizing diversity in cognition and organizational context among developers can guide personalization of LLM-based conversational programming assistants to improve inclusivity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By characterizing the impact of diversity in cognition and organizational context on developers' needs, personalization strategies can be developed that increase the inclusivity of LLM-based conversational programming assistants and better accommodate the ambiguous and unbounded character of conversational interactions in software engineering.
What carries the argument
Personalization strategies informed by characterizations of cognitive and organizational diversity in developers' needs.
If this is right
- Assistants will more reliably support multiple software engineering activities at once for users whose needs differ from the average.
- Conversational ambiguity will be managed better when the system adapts to the user's specific cognitive approach and work environment.
- Inclusivity gains will come from reducing the mismatch between a fixed tool and the unbounded variety of real developer requirements.
- Future designs can prioritize adaptation mechanisms rather than assuming uniform interaction patterns.
Where Pith is reading between the lines
- Early prototypes could test lightweight ways to capture relevant diversity factors during initial interactions without disrupting workflow.
- The same characterization approach might apply to non-conversational SE tools that also rely on natural language input.
- Empirical validation would require longitudinal studies tracking whether personalization reduces exclusion over repeated use sessions.
- This line of work connects to questions of how AI systems in software engineering can avoid embedding assumptions about a single type of user.
Load-bearing premise
Differences in how developers think and the contexts they work within are both identifiable and influential enough that targeted personalization will produce assistants that serve a broader range of users more effectively than generic versions.
What would settle it
A study that finds no measurable improvement in task completion rates, satisfaction, or perceived helpfulness when developers from varied cognitive styles and organizational settings use assistants personalized on those factors versus a single non-personalized baseline.
Figures

read the original abstract
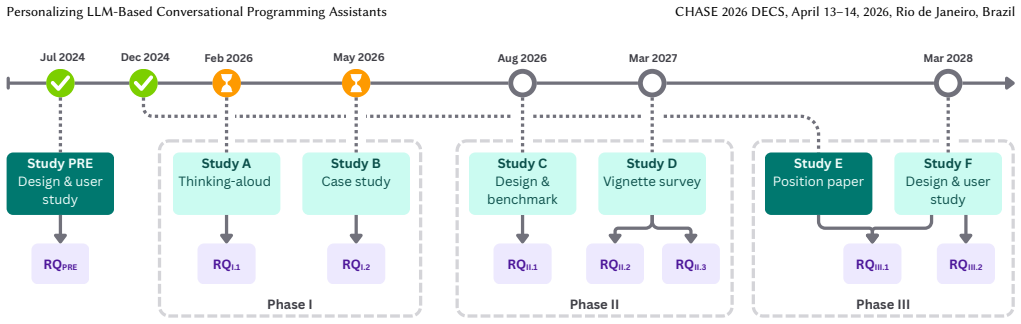
Large Language Models (LLMs) have shown much promise in powering a variety of software engineering (SE) tools. Offering natural language as an intuitive interaction mechanism, LLMs have recently been employed as conversational ``programming assistants'' capable of supporting several SE activities simultaneously. As with any SE tool, it is crucial that these assistants effectively meet developers' needs. Recent studies have shown addressing this challenge is complicated by the variety in developers' needs, and the ambiguous and unbounded nature of conversational interaction. This paper discusses our current and future work towards characterizing how diversity in cognition and organizational context impacts developers' needs, and exploring personalization as a means of improving the inclusivity of LLM-based conversational programming assistants.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This position paper argues that diversity in developers' cognitive styles and organizational contexts complicates the use of LLM-based conversational programming assistants, due to the ambiguous and unbounded nature of such interactions. It outlines planned research to characterize this diversity and then explore personalization strategies as a way to improve the inclusivity of these tools, without presenting any completed studies, empirical data, methods, or concrete mechanisms.
Significance. The topic addresses a timely gap in SE tool design as LLMs become more prevalent. If the proposed characterization and personalization work is executed with rigorous methods, it could yield more effective, inclusive assistants that accommodate varied developer needs and advance human-AI collaboration in software engineering.
major comments (2)
- [Abstract] Abstract: the statement that the paper 'discusses our current and future work' is unsupported, as the text provides only high-level future plans with no description of any ongoing characterization efforts, preliminary data, or specific research activities already underway.
- [Full manuscript (planned research discussion)] The manuscript offers no concrete study designs, metrics for cognitive/organizational diversity, or personalization techniques (e.g., no proposed user studies, data collection protocols, or adaptation algorithms), which is load-bearing because the central claim rests on the feasibility and value of this planned exploration.
minor comments (1)
- [Abstract] The abstract and text use 'inclusivity' without defining it operationally in the context of conversational SE assistants; adding a short clarification would improve precision.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for acknowledging the timeliness of addressing developer diversity in LLM-based conversational assistants. We will revise the manuscript to improve precision in describing the nature of our work and to provide additional high-level details on planned approaches, consistent with its status as a position paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statement that the paper 'discusses our current and future work' is unsupported, as the text provides only high-level future plans with no description of any ongoing characterization efforts, preliminary data, or specific research activities already underway.
Authors: We agree that the abstract phrasing could be more precise. The paper is a position paper that articulates a research vision and agenda. We will revise the abstract to state that it 'outlines our planned research directions toward characterizing developer diversity and exploring personalization' rather than claiming to discuss 'current and future work' in a way that implies detailed ongoing activities are presented. This change will be incorporated in the revised version. revision: yes
-
Referee: [Full manuscript (planned research discussion)] The manuscript offers no concrete study designs, metrics for cognitive/organizational diversity, or personalization techniques (e.g., no proposed user studies, data collection protocols, or adaptation algorithms), which is load-bearing because the central claim rests on the feasibility and value of this planned exploration.
Authors: We acknowledge that greater specificity on planned methods would strengthen the argument for feasibility. As this is a position paper, the focus is on identifying the problem space and high-level research direction rather than fully specified protocols. In the revision, we will add a dedicated subsection with example metrics (e.g., references to established cognitive style inventories and organizational context factors from SE literature), high-level study designs (e.g., mixed-methods user studies involving surveys and interviews), and illustrative personalization strategies (e.g., profile-based prompt adaptation). These additions will demonstrate the intended path forward without presenting unexecuted details as completed work. revision: yes
Circularity Check
No significant circularity
full rationale
This is a position paper that outlines planned future research on characterizing diversity in cognition and organizational context among developers, then exploring personalization to improve inclusivity of LLM-based conversational assistants. No derivations, equations, empirical results, predictions, or concrete mechanisms are presented. The text contains no load-bearing steps that reduce by construction to fitted parameters, self-citations, or renamed inputs; all claims are forward-looking descriptions of intended work rather than completed technical arguments.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. 2021. Program Synthesis with Large Language Models. arXiv:2108.07732. arXiv:2108.07732 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
2019.Designing User Experience: A Guide to HCI, UX and Interaction Design(fourth edition ed.)
David Benyon. 2019.Designing User Experience: A Guide to HCI, UX and Interaction Design(fourth edition ed.). Pearson, Harlow New York Toronto
2019
-
[3]
Margaret Burnett, Simone Stumpf, Jamie Macbeth, Stephann Makri, Laura Beck- with, Irwin Kwan, Anicia Peters, and William Jernigan. 2016. GenderMag: A Method for Evaluating Software’s Gender Inclusiveness.Interacting with Com- puters28, 6 (Nov. 2016), 760–787. doi:10.1093/iwc/iwv046
-
[4]
Ruijia Cheng, Ruotong Wang, Thomas Zimmermann, and Denae Ford. 2024. “It Would Work for Me Too”: How Online Communities Shape Software Developers’ Trust in AI-powered Code Generation Tools.ACM Transactions on Interactive Intelligent Systems14, 2, Article 11 (May 2024), 39 pages. doi:10.1145/3651990
-
[5]
Rudrajit Choudhuri, Dylan Liu, Igor Steinmacher, Marco Gerosa, and Anita Sarma. 2024. How Far Are We? The Triumphs and Trials of Generative AI in Learning Software Engineering. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering. ACM, Lisbon Portugal, 1–13. doi:10.1145/ 3597503.3639201
-
[6]
Fiona Draxler, Daniel Buschek, Mikke Tavast, Perttu Hämäläinen, Albrecht Schmidt, Juhi Kulshrestha, and Robin Welsch. 2023. Gender, Age, and Technology Education Influence the Adoption and Appropriation of LLMs. arXiv:2310.06556. arXiv:2310.06556 [cs] doi:10.48550/arXiv.2310.06556
-
[7]
Haiyan Fan and Marshall Scott Poole. 2006. What Is Personalization? Perspectives on the Design and Implementation of Personalization in Information Systems. Journal of Organizational Computing and Electronic Commerce16, 3-4 (Jan. 2006), 179–202. doi:10.1080/10919392.2006.9681199
-
[8]
Marc Hassenzahl. 2003. The Thing and I: Understanding the Relationship Between User and Product. InFunology: From Usability to Enjoyment, Mark A. Blythe, Andrew F. Monk, Kees Overbeeke, and Peter C. Wright (Eds.). Kluwers, Dordrecht, 31–42
2003
-
[9]
Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. 2024. Large Language Models for Software Engineering: A Systematic Literature Review.ACM Trans. Softw. Eng. Methodol.33, 8, Article 220 (Dec. 2024), 79 pages. doi:10.1145/3695988
-
[10]
Ranim Khojah, Mazen Mohamad, Philipp Leitner, and Francisco Gomes De Oliveira Neto. 2024. Beyond Code Generation: An Observational Study of ChatGPT Usage in Software Engineering Practice.Proceedings of the ACM on Software Engineering1, FSE (July 2024), 1819–1840. doi:10.1145/3660788
-
[11]
Hannah Rose Kirk, Bertie Vidgen, Paul Röttger, and Scott A. Hale. 2024. The Benefits, Risks and Bounds of Personalizing the Alignment of Large Language Models to Individuals.Nature Machine Intelligence6, 4 (April 2024), 383–392. doi:10.1038/s42256-024-00820-y
-
[12]
Stefano Lambiase, Gemma Catolino, Fabio Palomba, Filomena Ferrucci, and Daniel Russo. 2026. Investigating the Role of Cultural Values in Adopting Large Language Models for Software Engineering.ACM Transactions on Software Engineering and Methodology35, 1 (Jan. 2026), 1–43. doi:10.1145/3725529
-
[13]
Liang, Chenyang Yang, and Brad A
Jenny T. Liang, Chenyang Yang, and Brad A. Myers. 2024. A Large-Scale Survey on the Usability of AI Programming Assistants: Successes and Challenges. In Proceedings of the IEEE/ACM 46th International Conference on Software Engineering (ICSE ’24). Association for Computing Machinery, New York, NY, USA, 1–13. doi:10.1145/3597503.3608128
-
[14]
Daye Nam, Andrew Macvean, Vincent Hellendoorn, Bogdan Vasilescu, and Brad Myers. 2024. Using an LLM to Help With Code Understanding. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering. ACM, Lisbon Portugal, 1–13. doi:10.1145/3597503.3639187
-
[15]
Sydney Nguyen, Hannah McLean Babe, Yangtian Zi, Arjun Guha, Carolyn Jane Anderson, and Molly Q Feldman. 2024. How Beginning Programmers and Code LLMs (Mis)Read Each Other. InProceedings of the CHI Conference on Human Factors in Computing Systems. ACM, Honolulu HI USA, 1–26. doi:10.1145/3613904. 3642706
-
[16]
Donald Norman. 1986. Cognitive Engineering. InUser Centered System Design: New Perspectives on Human-Computer Interaction. CRC Press, 31–61. doi:10.1201/ b15703-3
1986
-
[17]
Sebastian A. C. Perrig, Lena Fanya Aeschbach, Nicolas Scharowski, Nick von Felten, Klaus Opwis, and Florian Brühlmann. 2024. Measurement Practices in User Experience (UX) Research: A Systematic Quantitative Literature Review.Frontiers in Computer Science6 (March 2024), 1368860. doi:10.3389/fcomp.2024.1368860
-
[18]
Jonan Richards and Mairieli Wessel. 2024. What You Need Is What You Get: Theory of Mind for an LLM-Based Code Understanding Assistant. In2024 IEEE International Conference on Software Maintenance and Evolution (ICSME). IEEE, Flagstaff, AZ, USA, 666–671. doi:10.1109/ICSME58944.2024.00070
-
[19]
Jonan Richards and Mairieli Wessel. 2025. Bridging HCI and AI Re- search for the Evaluation of Conversational SE Assistants. arXiv:2502.07956. arXiv:2502.07956 [cs] doi:10.48550/arXiv.2502.07956
-
[20]
Ross, Fernando Martinez, Stephanie Houde, Michael Muller, and Justin D
Steven I. Ross, Fernando Martinez, Stephanie Houde, Michael Muller, and Justin D. Weisz. 2023. The Programmer’s Assistant: Conversational Interaction with a Large Language Model for Software Development. InProceedings of the 28th In- ternational Conference on Intelligent User Interfaces. ACM, Sydney NSW Australia, 491–514. doi:10.1145/3581641.3584037
-
[21]
Daniel Russo. 2024. Navigating the Complexity of Generative AI Adoption in Software Engineering.ACM Trans. Softw. Eng. Methodol.33, 5 (June 2024), 135:1–135:50. doi:10.1145/3652154
-
[22]
Hariharan Subramonyam, Roy Pea, Christopher Lawrence Pondoc, Maneesh Agrawala, and Colleen Seifert. 2024. Bridging the Gulf of Envisioning: Cognitive Design Challenges in LLM Interfaces. arXiv:2309.14459. arXiv:2309.14459 [cs] doi:10.48550/arXiv.2309.14459
-
[23]
Tao Xiao, Christoph Treude, Hideaki Hata, and Kenichi Matsumoto. 2024. De- vGPT: Studying Developer-ChatGPT Conversations. InProceedings of the 21st International Conference on Mining Software Repositories (Msr ’24). Association for Computing Machinery, New York, NY, USA, 227–230. doi:10.1145/3643991. 3648400
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.