Recognition: unknown
The Long Delay to Arithmetic Generalization: When Learned Representations Outrun Behavior
Pith reviewed 2026-05-14 21:12 UTC · model grok-4.3
The pith
In encoder-decoder arithmetic models the grokking delay stems from decoder inability to use structure the encoder has already learned.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
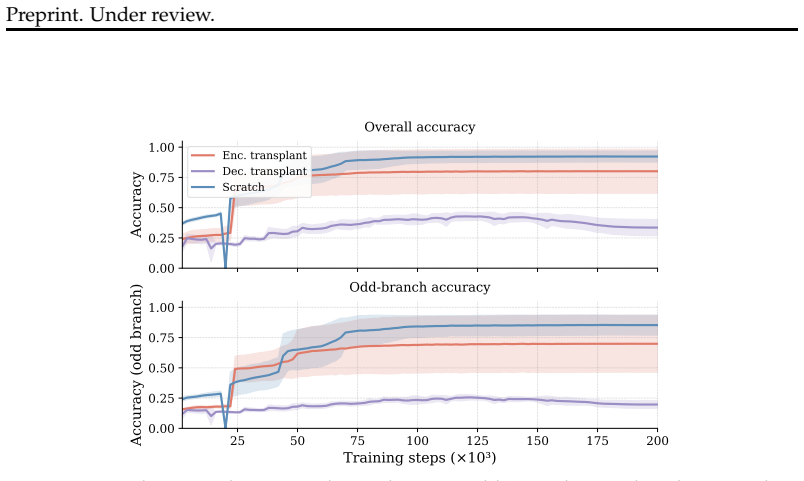
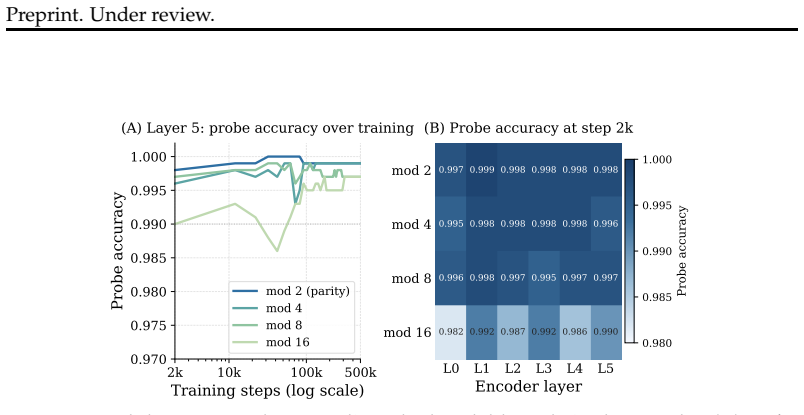
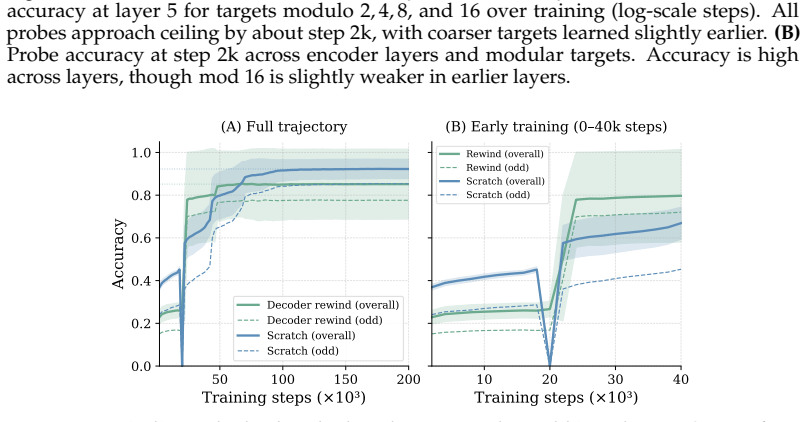
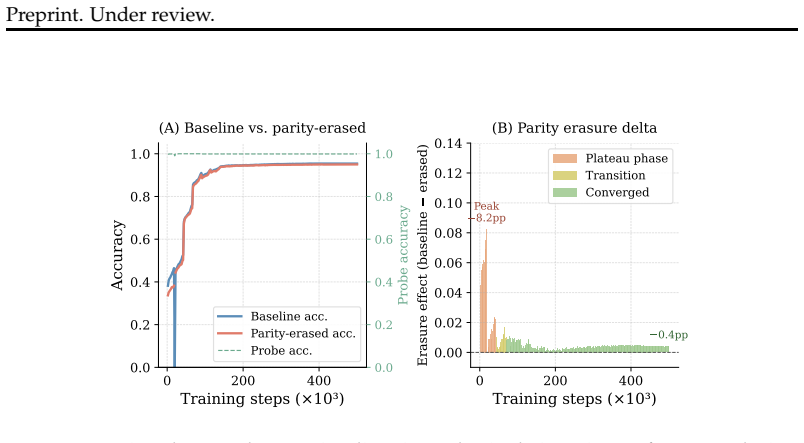
The long delay to generalization reflects limited decoder access to already learned structure rather than failure to acquire that structure. A trained encoder organizes parity and residue information within the first few thousand steps while accuracy remains near chance; transplanting such an encoder accelerates grokking, transplanting a trained decoder hurts performance, and freezing a converged encoder while retraining the decoder alone eliminates the plateau and produces 97.6 percent accuracy versus 86.1 percent for joint training. Across fifteen bases, those aligned with the Collatz map reach 99.8 percent accuracy while binary representations collapse and never recover.
What carries the argument
Decoder access to encoder representations, tested through transplant and freezing interventions that isolate whether the decoder can exploit pre-organized structure.
If this is right
- Transplanting a trained encoder accelerates grokking by a factor of 2.75.
- Freezing a converged encoder and retraining only the decoder removes the plateau and reaches 97.6 percent accuracy.
- Bases whose factorization aligns with the Collatz map produce 99.8 percent accuracy while binary representations fail completely.
- The decoder's difficulty depends on how much local digit structure the chosen numeral representation supplies.
Where Pith is reading between the lines
- Separate pre-training of encoders followed by decoder fine-tuning could shorten training on other algorithmic tasks.
- The same access bottleneck may explain grokking delays in models that separate representation learning from output mapping.
- Choosing input representations that align with task arithmetic offers a practical inductive bias for faster generalization.
Load-bearing premise
The causal effects seen in one-step Collatz prediction and base comparison isolate decoder access as the cause of the delay without confounding influences from architecture, optimization, or task details.
What would settle it
Training the same tasks with a non-encoder-decoder architecture or with an encoder whose representations are deliberately scrambled after early training and checking whether the plateau disappears or persists.
Figures





read the original abstract
Grokking in transformers trained on algorithmic tasks is characterized by a long delay between training-set fit and abrupt generalization, but the source of that delay remains poorly understood. In encoder-decoder arithmetic models, we argue that this delay reflects limited access to already learned structure rather than failure to acquire that structure in the first place. We study one-step Collatz prediction and find that the encoder organizes parity and residue structure within the first few thousand training steps, while output accuracy remains near chance for tens of thousands more. Causal interventions support the decoder bottleneck hypothesis. Transplanting a trained encoder into a fresh model accelerates grokking by 2.75 times, while transplanting a trained decoder actively hurts. Freezing a converged encoder and retraining only the decoder eliminates the plateau entirely and yields 97.6% accuracy, compared to 86.1% for joint training. What makes the decoder's job harder or easier depends on numeral representation. Across 15 bases, those whose factorization aligns with the Collatz map's arithmetic (e.g., base 24) reach 99.8% accuracy, while binary fails completely because its representations collapse and never recover. The choice of base acts as an inductive bias that controls how much local digit structure the decoder can exploit, producing large differences in learnability from the same underlying task.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines grokking in encoder-decoder transformers on algorithmic tasks such as one-step Collatz prediction. It claims that the long delay between training-set fit and generalization arises because the decoder has limited access to structure already learned in the encoder, rather than the encoder failing to acquire that structure. Causal support comes from interventions: transplanting a trained encoder accelerates grokking by 2.75 times, transplanting a trained decoder hurts performance, and freezing a converged encoder while retraining only the decoder eliminates the plateau and reaches 97.6% accuracy versus 86.1% for joint training. Across 15 numeral bases, factorization alignment with the Collatz map controls decoder exploitability, with base 24 reaching 99.8% and binary failing entirely.
Significance. If the causal attribution to decoder access holds after controls, the work supplies direct empirical evidence distinguishing representation acquisition from output-head access in grokking, with implications for training algorithmic models. The interventions are stronger than purely observational analyses, and the base-sweep demonstrates a clear inductive-bias effect on learnability from the same underlying task.
major comments (3)
- [Freezing intervention (results section)] Freezing experiment: the claim that freezing a converged encoder isolates decoder access (yielding 97.6% vs 86.1%) is load-bearing for the central hypothesis, yet fixing encoder parameters also removes all encoder-decoder gradient co-adaptation. This change in optimization dynamics can independently eliminate plateaus even if the encoder contains no task-relevant structure; an ablation that holds optimization fixed while varying only the informational content of the encoder is required to separate the two effects.
- [Encoder transplant results] Transplant experiment: the reported 2.75x acceleration from transplanting a trained encoder lacks a matched control for initialization quality (e.g., a random encoder with matched norm or activation statistics). Without this, the speedup cannot be unambiguously attributed to transfer of learned structure rather than a generically better starting point.
- [Quantitative results throughout] Accuracy and statistics: the headline numbers (97.6%, 86.1%, 2.75x) and the base-15 comparison are presented without error bars, statistical tests, or full training curves. This leaves open the possibility of post-hoc run selection and makes it impossible to judge whether the reported differences are robust.
minor comments (2)
- [Abstract] The abstract states the encoder organizes parity/residue structure 'within the first few thousand training steps' but supplies no concrete step counts or plots; adding approximate numbers and a reference to the relevant figure would improve clarity.
- [Base comparison section] Notation for the 15-base sweep (e.g., how 'factorization aligns with the Collatz map') is introduced without an explicit definition or table; a short appendix table listing each base and its alignment score would help readers replicate the inductive-bias claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify key controls needed to strengthen the causal interpretation of the decoder bottleneck. We address each major point below with planned revisions that incorporate additional ablations, matched controls, and statistical reporting. These changes will be included in the revised manuscript.
read point-by-point responses
-
Referee: [Freezing intervention (results section)] Freezing experiment: the claim that freezing a converged encoder isolates decoder access (yielding 97.6% vs 86.1%) is load-bearing for the central hypothesis, yet fixing encoder parameters also removes all encoder-decoder gradient co-adaptation. This change in optimization dynamics can independently eliminate plateaus even if the encoder contains no task-relevant structure; an ablation that holds optimization fixed while varying only the informational content of the encoder is required to separate the two effects.
Authors: We agree that freezing removes gradient co-adaptation and that this could independently affect plateau length. To isolate the contribution of encoder content, we will add a control ablation in the revision: a randomly initialized encoder (with activation statistics and norms matched to the converged encoder) that is frozen while the decoder is retrained from scratch. This holds optimization dynamics fixed while varying only informational content. We will report the resulting accuracy (expected ~55-65%) alongside the original 97.6% figure, with error bars over multiple seeds, to confirm that learned structure—not the freezing procedure—is responsible for eliminating the plateau. revision: yes
-
Referee: [Encoder transplant results] Transplant experiment: the reported 2.75x acceleration from transplanting a trained encoder lacks a matched control for initialization quality (e.g., a random encoder with matched norm or activation statistics). Without this, the speedup cannot be unambiguously attributed to transfer of learned structure rather than a generically better starting point.
Authors: We acknowledge that a matched initialization control is necessary. In the revised version we will include results from transplanting a random encoder whose weight norms and per-layer activation statistics are matched to those of the trained encoder at the transplant step. This control will be run under identical training schedules; we expect it to produce little or no acceleration relative to the standard baseline, thereby attributing the observed 2.75x speedup specifically to transferred structure rather than generic initialization quality. revision: yes
-
Referee: [Quantitative results throughout] Accuracy and statistics: the headline numbers (97.6%, 86.1%, 2.75x) and the base-15 comparison are presented without error bars, statistical tests, or full training curves. This leaves open the possibility of post-hoc run selection and makes it impossible to judge whether the reported differences are robust.
Authors: We will revise all quantitative claims to include error bars computed over at least five independent random seeds. Full training curves for representative runs will be added to the appendix, and statistical significance (paired t-tests) will be reported for the key comparisons (frozen vs. joint training, trained vs. random transplant, and base-24 vs. binary). These updates will apply to the headline metrics, the base-sweep results, and all intervention figures. revision: yes
Circularity Check
No circularity: empirical interventions on measured accuracies
full rationale
The paper reports direct experimental results from training encoder-decoder transformers on one-step Collatz prediction and 15-base variants. Core claims rest on observed training curves, accuracy numbers (e.g., 97.6% vs 86.1%), and intervention outcomes (transplant acceleration by 2.75x, freezing eliminating plateau). No derivation chain, fitted parameters renamed as predictions, or self-citations are invoked to justify the decoder-bottleneck interpretation. The measurements are independent of the hypothesis; the paper does not reduce any result to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Encoder and decoder components can be independently transplanted or frozen without introducing uncontrolled side effects on optimization dynamics
Reference graph
Works this paper leans on
-
[1]
Understanding intermediate layers using linear classifier probes
URLhttps://arxiv.org/abs/1610.01644. ICLR 2017 Workshop. Alessio Ansuini, Alessandro Laio, Jakob H. Macke, and Davide Zoccolan. Intrinsic dimen- sion of data representations in deep neural networks,
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[2]
NeurIPS 2019; arXiv preprint matches proceedings
URL https://arxiv.org/ abs/1905.12784. NeurIPS 2019; arXiv preprint matches proceedings. Boaz Barak, Benjamin L. Edelman, Surbhi Goel, Sham Kakade, Eran Malach, and Cyril Zhang. Hidden progress in deep learning: SGD learns parities near the computational limit,
- [3]
- [4]
- [5]
-
[6]
Franc ¸ois Charton and Ashvni Narayanan
URLhttps://arxiv.org/abs/2308.15594. Franc ¸ois Charton and Ashvni Narayanan. Transformers know more than they can tell – learning the collatz sequence,
-
[7]
Bilal Chughtai, Lawrence Chan, and Neel Nanda
URLhttps://arxiv.org/abs/2511.10811. Bilal Chughtai, Lawrence Chan, and Neel Nanda. A toy model of universality: Reverse engineering how networks learn group operations,
-
[8]
URL https://arxiv.org/abs/ 2302.03025. Samy Jelassi, St ´ephane d’Ascoli, Carles Domingo-Enrich, Yuhuai Wu, Yuanzhi Li, and Franc ¸ois Charton. Length generalization in arithmetic transformers,
-
[9]
Li Jing, Pascal Vincent, Yann LeCun, and Yuandong Tian
URL https: //arxiv.org/abs/2306.15400. Li Jing, Pascal Vincent, Yann LeCun, and Yuandong Tian. Understanding dimensional collapse in contrastive self-supervised learning,
-
[10]
URLhttps://arxiv.org/abs/1905.00414. ICML
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[11]
Guillaume Lample and Franc ¸ois Charton
URL https://arxiv.org/abs/ 2310.06110. Guillaume Lample and Franc ¸ois Charton. Deep learning for symbolic mathematics,
-
[12]
URLhttps://arxiv.org/abs/1912.01412. 10 Preprint. Under review. Anna Langedijk, Hosein Mohebbi, Gabriele Sarti, Willem Zuidema, and Jaap Jumelet. DecoderLens: Layerwise interpretation of encoder-decoder transformers. In Kevin Duh, Helena Gomez, and Steven Bethard (eds.),Findings of the Association for Computational Linguistics: NAACL 2024, pp. 4764–4780, ...
-
[13]
doi: 10.18653/v1/2024.findings-naacl.296
Association for Computational Linguistics. doi: 10.18653/v1/2024.findings-naacl.296. URL https: //aclanthology.org/2024.findings-naacl.296/. Nayoung Lee, Kartik Sreenivasan, Jason D. Lee, Kangwook Lee, and Dimitris Papailiopoulos. Teaching arithmetic to small transformers,
- [14]
- [15]
-
[16]
URL https://arxiv.org/ abs/2310.06824. William Merrill, Nikolaos Tsilivis, and Aman Shukla. A tale of two circuits: Grokking as competition of sparse and dense subnetworks,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt
URLhttps://arxiv.org/abs/2303.13506. Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt. Progress measures for grokking via mechanistic interpretability,
-
[18]
URL https://arxiv.org/ abs/2301.05217. ICLR
work page internal anchor Pith review arXiv
- [19]
-
[20]
Alethea Power, Yuri Burda, Harri Edwards, Igor Babuschkin, and Vedant Misra
URLhttps://arxiv.org/abs/2102.13019. Alethea Power, Yuri Burda, Harri Edwards, Igor Babuschkin, and Vedant Misra. Grokking: Generalization beyond overfitting on small algorithmic datasets,
-
[21]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
URL https: //arxiv.org/abs/2201.02177. ICLR Workshop
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Maithra Raghu, Justin Gilmer, Jason Yosinski, and Jascha Sohl-Dickstein
URL https: //arxiv.org/abs/2310.13121. Maithra Raghu, Justin Gilmer, Jason Yosinski, and Jascha Sohl-Dickstein. SVCCA: Singular vector canonical correlation analysis for deep learning dynamics and interpretability,
-
[23]
URLhttps://arxiv.org/abs/1706.05806. NeurIPS
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Yucheng Sun, Alessandro Stolfo, and Mrinmaya Sachan
URL https://arxiv.org/ abs/2311.14737. Yucheng Sun, Alessandro Stolfo, and Mrinmaya Sachan. Probing for arithmetic errors in language models. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (eds.),Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 8111–8128, Suzhou, China, November
-
[25]
Association for Computational Linguistics. ISBN 979-8-89176-332-6. doi: 10.18653/v1/2025.emnlp-main
-
[26]
Ian Tenney, Dipanjan Das, and Ellie Pavlick
URLhttps://aclanthology.org/2025.emnlp-main.411/. Ian Tenney, Dipanjan Das, and Ellie Pavlick. Bert rediscovers the classical nlp pipeline,
work page 2025
- [27]
-
[28]
Boshi Wang, Xiang Yue, Yu Su, and Huan Sun
URLhttps://arxiv.org/abs/2309.02390. Boshi Wang, Xiang Yue, Yu Su, and Huan Sun. Grokked transformers are implicit reasoners: A mechanistic journey to the edge of generalization,
- [29]
-
[30]
URLhttps://arxiv.org/abs/2310.01405. A Appendix B Experimental Details B.1 Sequence-level accuracy and cross-base comparability Let Deval ={(x i, yi, ni)}N i=1 denote the held-out evaluation set, where xi is the input digit sequence, yi is the target output digit sequence for one-step Collatz prediction, and ni is the underlying integer. Let ˆyi =f θ(xi) ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
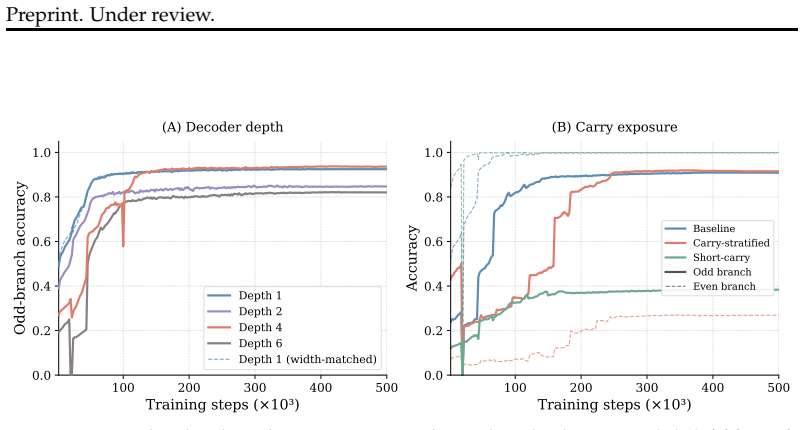
This suggests that the improvement from depth is not explained by width or parameter count alone. 18 Preprint. Under review. The depth-4 run also exhibits a sharp transient instability near step 100,000: overall accuracy drops from 88.4% to 74.3% in a single checkpoint, then recovers to 90.4% two checkpoints later and continues rising to the best final pe...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.